Opções de Big Data na plataforma do Microsoft SQL Server
Aplica-se a:![]() SQL Server 2019 (15.x) e versões posteriores
SQL Server 2019 (15.x) e versões posteriores
O Microsoft SQL Server 2019 Big Clusters é um complemento para a plataforma SQL Server que permite implantar clusters escalonáveis de contêineres SQL Server, Spark e HDFS em execução no Kubernetes. Esses componentes são executados lado a lado para permitir que você leia, grave e processe Big Data usando bibliotecas do Transact-SQL ou do Spark, permitindo combinar e analisar facilmente seus dados relacionais de alto valor com Big Data de alto volume não relacionais. Os clusters de Big Data também permitem virtualizar dados com o PolyBase, para que você possa consultar dados de SQL Server externos, Oracle, Teradata, MongoDB e outras fontes de dados usando tabelas externas. O complemento Microsoft SQL Server 2019 Big Clusters fornece alta disponibilidade para a instância mestra SQL Server e todos os bancos de dados usando a tecnologia de grupo de disponibilidade Always On.
O complemento Clusters de Big Data do SQL Server 2019 é executado no local e na nuvem usando a plataforma Kubernetes, para qualquer implantação padrão de Kubernetes. Além disso, o complemento Clusters de Big Data do SQL Server 2019 se integra ao Active Directory e inclui controle de acesso baseado em função para atender às necessidades de segurança e conformidade de sua empresa.
Desativação do complemento Clusters de Big Data do SQL Server 2019
Em 28 de fevereiro de 2025, vamos desativar os Clusters de Big Data do SQL Server 2019. Todos os usuários existentes do SQL Server 2019 com Software Assurance terão suporte total na plataforma e o software continuará a ser mantido por meio de atualizações cumulativas do SQL Server até esse momento. Para saber mais, confira a postagem no blog sobre o anúncio.
Alterações no suporte ao PolyBase no SQL Server
Relacionados à aposentadoria dos Clusters de Big Data do SQL Server de 2019 estão alguns recursos das consultas de expansão.
O recurso de grupos de escala horizontal do PolyBase do Microsoft SQL Server foi desativado. A funcionalidade de grupo de escala horizontal foi removida do produto no SQL Server 2022 (16.x). As versões do SQL Server 2019, SQL Server 2017 e SQL Server 2016 que estão no mercado continuarão a dar suporte à funcionalidade até o fim da vida útil desses produtos. A virtualização de dados do PolyBase continua com suporte total como um recurso de expansão no SQL Server.
As fontes de dados externas do Hadoop Cloudera (CDP) e do Hortonworks (HDP) também serão desativadas para todas as versões comercializadas do SQL Server e não estão incluídas no SQL Server 2022. O suporte a fontes de dados externas está limitado às versões do produto no suporte base do respectivo fornecedor. Recomendamos que você use a nova integração de armazenamento de objetos disponível no SQL Server 2022 (16.x).
No SQL Server 2022 (16.x) e versões posteriores, os usuários devem configurar as fontes de dados externas para usar os novos conectores ao se conectarem ao Armazenamento do Azure. A tabela a seguir resume a mudança:
| Fonte de dados externa | De | Para |
|---|---|---|
| Armazenamento do Blobs do Azure | wasb[s] |
abs |
| ADLS Gen 2 | abfs[s] |
adls |
Observação
O Armazenamento de Blobs do Azure (abs) exigirá o uso da SAS (Assinatura de Acesso Compartilhado) para o SECRET na credencial com escopo de banco de dados. No SQL Server 2019 e anteriores, o conector wasb[s] usava a Chave da Conta de Armazenamento com a credencial com escopo de banco de dados ao realizar a autenticação na conta de Armazenamento do Azure.
Noções básicas sobre a arquitetura de Clusters de Big Data para opções de substituição e migração
Para criar sua solução de substituição para um sistema de processamento e armazenamento de Big Data, será importante entender o que os Clusters de Big Data do SQL Server 2019 fornece e sua arquitetura pode ajudar você a fazer escolhas informadas. A arquitetura de um cluster de Big Data é a seguinte:

Essa arquitetura oferece o seguinte mapeamento de funcionalidade:
| Componente | Benefício |
|---|---|
| Kubernetes | Orquestrador de código aberto para implantar e gerenciar aplicativos baseados em contêiner em escala. Fornece um método declarativo para criar e controlar a resiliência, redundância e portabilidade para todo o ambiente com escala elástica. |
| Controlador de Clusters de Big Data | O controlador fornece gerenciamento e segurança para o cluster. Ele contém o serviço de controle, o repositório de configurações e outros serviços no nível do cluster, como Kibana, Grafana e Pesquisa Elástica. |
| Pool de computação | Fornece recursos computacionais para o cluster. Ele contém nós que executam pods do SQL Server em Linux. Os pods no pool de computação são divididos em instâncias de computação do SQL para tarefas de processamento específicas. Esse componente também fornece a Virtualização de Dados usando o PolyBase para consultar fontes de dados externas sem mover ou copiar os dados. |
| Pool de dados | Fornece persistência de dados para o cluster. O pool de dados é composto por um ou mais pods em execução no SQL Server em Linux. Ele é usado para ingerir dados de consultas SQL ou de trabalhos do Spark. |
| Pool de armazenamento | O pool de armazenamento é composto por pods do pool de armazenamento compostos pelo SQL Server em Linux, pelo Spark e pelo HDFS. Todos os nós de armazenamento em um cluster de Big Data são membros de um cluster HDFS. |
| Pool de Aplicativos | Permite a implantação de aplicativos em um cluster de Big Data ao fornecer interfaces para criar, gerenciar e executar aplicativos. |
Para saber mais sobre essas funções, confira Introdução a Clusters de Big Data do SQL Server.
Opções de substituição de funcionalidade para Big Data e SQL Server
A função de dados operacionais facilitada pelo SQL Server dentro dos Clusters de Big Data pode ser substituída pelo SQL Server local em uma configuração híbrida ou usando a plataforma do Microsoft Azure. O Microsoft Azure oferece uma opção de bancos de dados relacionais, NoSQL e na memória totalmente gerenciados, abrangendo mecanismos proprietários e de código-fonte aberto, para atender às necessidades dos desenvolvedores de aplicativos modernos. O gerenciamento de infraestrutura — incluindo escalabilidade, disponibilidade e segurança — é automatizado, economizando tempo e dinheiro, e permite que você se concentre na criação de aplicativos enquanto os bancos de dados gerenciados pelo Azure tornam seu trabalho mais simples, identificando o desempenho de informações por meio de inteligência incorporada, dimensionamento sem limites e gerenciamento de ameaças à segurança. Para saber mais, confira Bancos de dados do Azure.
O próximo ponto de decisão são os locais de computação e armazenamento de dados para análise. As duas opções de arquitetura são implantações híbridas e na nuvem. A maioria das cargas de trabalho analíticas pode ser migrada para a plataforma do Microsoft Azure. Os dados "nascidos na nuvem" (originados em aplicativos baseados na nuvem) são os principais candidatos a essas tecnologias, e os serviços de movimentação de dados podem migrar dados locais de grande escala com segurança e rapidez. Para saber mais sobre opções de movimentação de dados, confira Soluções de transferência de dados.
O Microsoft Azure tem sistemas e certificações que permitem processamento de dados e dados seguros em diversas ferramentas. Para saber mais sobre as certificações da Microsoft, confira a Central de Confiabilidade.
Observação
A plataforma do Microsoft Azure fornece um nível muito alto de segurança, várias certificações para vários setores e honra a soberania de dados para os requisitos governamentais. O Microsoft Azure também tem uma plataforma de nuvem dedicada para cargas de trabalho do governo. A segurança sozinha não deve ser o ponto de decisão principal para sistemas locais. Você deve avaliar cuidadosamente o nível de segurança fornecido por Microsoft Azure antes de decidir manter suas soluções de Big Data no local.
Na opção arquitetura na nuvem, todos os componentes residem no Microsoft Azure. Sua responsabilidade está com os dados e o código que você cria para armazenamento e processamento de suas cargas de trabalho. Esses tópicos serão abordados em mais detalhes mais adiante neste artigo.
- Essa opção funciona melhor em uma ampla variedade de componentes para armazenamento e processamento de dados e quando você deseja se concentrar em construções de dados e processamento em vez de infraestrutura.
Nas opções de arquitetura híbrida, alguns componentes são mantidos no local e outros são colocados em um Provedor de Nuvem. A conectividade entre os dois foi projetada para o melhor posicionamento do processamento sobre dados.
- Essa opção funciona melhor quando você tem um investimento considerável em tecnologias e arquiteturas locais, mas deseja usar as ofertas de Microsoft Azure, ou quando você tem os destinos de processamento e de aplicativo residindo localmente ou para um público-alvo mundial.
Para saber mais sobre a criação de arquiteturas escalonáveis, confira Criar um sistema escalonável para grandes quantidades de dados.
Na nuvem
SQL do Azure com Synapse
Você pode substituir a funcionalidade Clusters de Big Data do SQL Server usando uma ou mais opções de banco de dados SQL do Azure para os dados operacionais e o Microsoft Azure Synapse para suas cargas de trabalho analíticas.
O Microsoft Azure Synapse é um serviço de análise empresarial que acelera o tempo de descoberta de insights entre data warehouses e sistemas de Big Data usando processamento distribuído e constructos de dados. O Azure Synapse reúne o melhor das tecnologias de SQL usadas em data warehousing corporativo, tecnologias Spark usadas para Big Data, Pipelines para integração de dados e ETL/ELT e integração profunda com outros serviços do Azure, como Power BI, Cosmos DB e Azure Machine Learning.
Use Microsoft Azure Synapse como uma substituição para Clusters de Big Data do SQL Server 2019 quando precisar:
- Use os modelos de recursos sem servidor e dedicados. Para obter desempenho e custo previsíveis, crie pools de SQL dedicados para reservar a capacidade de processamento para os dados armazenados em tabelas SQL.
- Processe cargas de trabalho não planejadas ou "intermitentes", acesse um ponto de extremidade de SQL sem servidor e sempre disponível.
- Use funcionalidades internas de streaming para enviar dados de fontes de dados na nuvem para tabelas SQL.
- Integre a IA ao SQL usando modelos de aprendizado de máquina para pontuar dados empregando a função T-SQL PREDICT.
- Use os modelos de ML com algoritmos do SparkML e integração do Azure Machine Learning para Apache Spark 2.4 com suporte interno para o Linux Foundation Delta Lake.
- Use um modelo de recurso simplificado que libera você das preocupações com o gerenciamento de clusters.
- Processe dados que exigem inicialização rápida do Spark e dimensionamento automático agressivo.
- Processe os dados usando .NET para Spark, o que permite a você reutilizar sua experiência em C# e o código .NET existente em um aplicativo Spark.
- As tabelas definidas em arquivos no data lake são consumidas continuamente pelo Spark ou Hive.
- O SQL e o Spark podem explorar e analisar diretamente arquivos Parquet, CSV, TSV e JSON armazenados no data lake.
- Habilite o carregamento de dados rápido e escalonável entre bancos de dados SQL e do Spark.
- Ingira dados de mais de 90 fontes de dados.
- Habilite o ETL "Sem Código" com atividades de Fluxo de dados.
- Orquestre notebooks, trabalhos do Spark, procedimentos armazenados, scripts SQL e muito mais.
- Monitore recursos, uso e usuários no SQL e no Spark.
- Use o controle de acesso baseado em função para simplificar o acesso aos recursos de análise.
- Escreva um código SQL ou Spark e integrá-lo aos processos empresariais da CI/CD.
A arquitetura do Microsoft Azure Synapse é a seguinte:

Para saber mais sobre o Microsoft Azure Synapse, confira O que é o Azure Synapse Analytics?
SQL do Azure mais Azure Machine Learning
Você pode substituir a funcionalidade de Clusters de Big Data do SQL Server usando uma ou mais opções de banco de dados SQL do Azure para os dados operacionais e Microsoft Azure Machine Learning para suas cargas de trabalho preditivas.
O Azure Machine Learning é um serviço baseado na nuvem que pode ser usado para qualquer tipo de aprendizado de máquina, desde o ML clássico até o aprendizado profundo e o aprendizado supervisionado e não supervisionado. Se você preferir escrever o código Python ou R com o SDK ou trabalhar com as opções sem código/com pouco código no estúdio, poderá criar, treinar e acompanhar modelos de machine learning e aprendizado profundo em um Workspace do Azure Machine Learning. Com o Azure Machine Learning, você pode começar a treinar em seu computador local e, em seguida, escalar horizontalmente para a nuvem. O serviço também interopera com ferramentas populares de software livre de aprendizado profundo e reforço como o PyTorch, TensorFlow, scikit-learn e Ray RLlib.
Use Microsoft Azure Machine Learning como uma substituição para Clusters de Big Data do SQL Server 2019 quando precisar:
- Um ambiente da Web baseado em designer para o Machine Learning: arraste e solte os módulos para criar seus experimentos e implante pipelines em um ambiente com pouco código.
- Notebooks Jupyter: use nossos notebooks de exemplo ou crie seus próprios notebooks para usar nossas amostras de SDK para Python em seu aprendizado de máquina.
- Scripts R ou notebooks nos quais você usa o SDK para R para escrever seu próprio código ou usar os módulos do R no designer.
- O Acelerador de Solução de Muitos Modelos é baseado no Azure Machine Learning e permite treinar, operar e gerenciar centenas ou até milhares de modelos de aprendizado de máquina.
- As extensões de aprendizado de máquina para o Visual Studio Code (versão preliminar) fornece um ambiente de desenvolvimento completo para criar e gerenciar seus projetos de aprendizado de máquina.
- A CLI (interface de linha de comando) do Machine Learning, Azure Machine Learning, inclui uma extensão da CLI do Azure que fornece comandos para gerenciar recursos com o Azure Machine Learning usando a linha de comando.
- Integração com estruturas de software livre, como PyTorch, TensorFlow e scikit-learn, entre muitos outros, para treinamento, implantação e gerenciamento do processo de machine learning de ponta a ponta.
- Aprendizado de reforço com o Ray Llib.
- MLflow para controlar as métricas e implantar modelos ou Kubeflow para compilar pipelines de fluxo de trabalho de ponta a ponta.
A arquitetura de uma implantação do Microsoft Azure Machine Learning é a seguinte:

Para saber mais sobre o Microsoft Azure Machine Learning, confira Como o Azure Machine Learning funciona.
SQL do Azure do Databricks
Você pode substituir a funcionalidade Clusters de Big Data do SQL Server usando uma ou mais opções de banco de dados SQL do Azure para os dados operacionais e o Microsoft Azure Databricks para suas cargas de trabalho analíticas.
O Azure Databricks é uma plataforma de análise de dados otimizada para a plataforma de Serviços de Nuvem do Microsoft Azure. Ele oferece dois ambientes para o desenvolvimento de aplicativos com uso intensivo de dados: a Análise de SQL e o Workspace do Azure Databricks.
A Análise de SQL do Azure Databricks fornece uma plataforma fácil de usar para analistas que desejam executar consultas SQL em data lakes, criar vários tipos de visualização para explorar os resultados da consulta de diferentes perspectivas, bem como criar e compartilhar painéis.
O Workspace do Azure Databricks fornece um workspace interativo que permite a colaboração entre engenheiros de dados, cientistas de dados e engenheiros de machine learning. Para um pipeline de Big Data, os dados (brutos ou estruturados) são ingeridos no Azure por meio do Azure Data Factory em lotes ou transmitidos quase em tempo real usando o Apache Kafka, o Hub de Eventos ou o Hub IoT. Esses dados chegam em um data lake para armazenamento persistente de longo prazo, no Armazenamento de Blobs do Azure ou no Azure Data Lake Storage. Como parte do seu fluxo de trabalho de análise, use o Azure Databricks para ler dados de várias fontes de dados e transformá-los em insights inovadores usando o Spark.
Use Microsoft Azure Databricks como uma substituição para Clusters de Big Data do SQL Server 2019 quando precisar:
- Clusters Spark totalmente gerenciados com Spark SQL e DataFrames.
- Streaming para processamento de dados em tempo real e análise para aplicativos analíticos e interativos, integração com HDFS, Flume e Kafka.
- Acesso à biblioteca MLlib, que consiste em algoritmos e utilitários de aprendizado comuns, incluindo classificação, regressão, clustering, filtragem colaborativa, redução de dimensionalidade e primitivos de otimização subjacente.
- Documentação do seu progresso em notebooks em R, Python, Scala ou SQL.
- Visualização de dados em algumas etapas, usando ferramentas familiares como Matplotlib, ggplot ou d3.
- Use painéis interativos para criar relatórios dinâmicos.
- GraphX, para Grafos e computação de grafos para um amplo escopo de casos de uso desde análise cognitiva até exploração de dados.
- Criação de cluster em segundos, com clusters dinâmicos de dimensionamento automático, compartilhando-os entre equipes.
- Acesso de cluster programático usando APIs REST.
- Acesso instantâneo para os recursos mais recentes do Apache Spark com cada versão.
- API Principal do Spark: inclui suporte para R, SQL, Python, Scala e Java.
- Um espaço de trabalho interativo para exploração e visualização.
- Pontos de extremidade SQL totalmente gerenciados na nuvem.
- As consultas SQL que são executadas em pontos de extremidade SQL totalmente gerenciados dimensionados de acordo com a latência da consulta e o número de usuários simultâneos.
- Microsoft Entra ID (antigo Azure Active Directory).
- O acesso baseado em funções para permissões refinadas de usuário para blocos de notas, clusters, trabalhos e dados.
- SLAs de nível empresarial.
- Painéis permitem compartilhar insights, combinar visualizações e texto para compartilhar insights extraídos de suas consultas.
- Os alertas ajudam você a monitorar e integrar e a notificar quando um campo retornado por uma consulta atender a um limite. Use alertas para monitorar seus negócios ou integre-os a ferramentas para iniciar fluxos de trabalho, como tíquetes de suporte ou integração de usuários.
- Segurança de classe empresarial, incluindo integração do Microsoft Entra ID, controles baseados em função e SLAs que protegem seus dados e seus negócios.
- Integração com serviços do Azure e bancos de dados e armazenamentos do Azure, incluindo Synapse Analytics, Cosmos DB, Data Lake Store e Armazenamento de Blobs.
- Integração com o Power BI e outras ferramentas de BI, como o Tableau Software.
A arquitetura de uma implantação do Microsoft Azure Databricks é a seguinte:
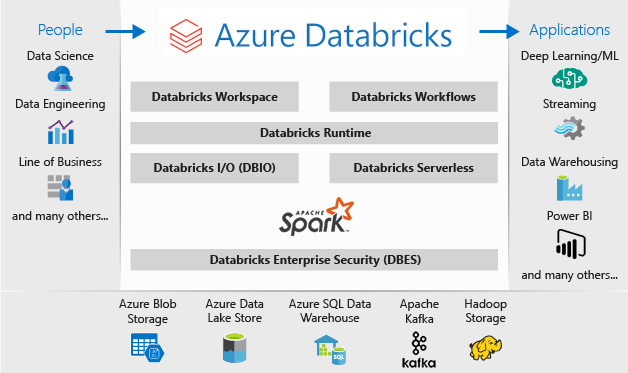
Para saber mais sobre o Microsoft Azure Databricks, confira O que é o Databricks Data Science & Engineering?
Híbrido
Banco de dados espelhado do Fabric
Como uma experiência de replicação de dados, o Espelhamento de Banco de Dados no Fabric (Versão Preliminar) é uma solução de baixo custo e baixa latência para reunir dados de vários sistemas em uma única plataforma de análise. Você pode replicar continuamente seu patrimônio de dados existente diretamente no OneLake do Fabric, inclusive dados do Banco de Dados SQL do Azure, Snowflake e Cosmos DB.
Com os dados mais atualizados em formato consultável no OneLake, agora você pode usar todos os diferentes serviços do Fabric, como execução de análises com Spark, execução de notebooks, engenharia de dados, visualização por meio de relatórios do Power BI e muito mais.
O espelhamento no Fabric oferece uma experiência fácil para acelerar o tempo de obtenção de valor para insights e decisões e para eliminar silos de dados entre soluções de tecnologia, sem desenvolver processos caros de ETL (Extração, Transformação e Carregamento) para mover dados.
Com o Espelhamento in Fabric, você não precisa reunir diferentes serviços de vários fornecedores. Em vez disso, você pode desfrutar de um produto altamente integrado, de ponta a ponta e fácil de usar, projetado para simplificar suas necessidades analíticas e desenvolvido para abertura e colaboração entre soluções de tecnologia que podem ler o formato de tabela de código aberto do Delta Lake.
Para saber mais, veja:
- Bancos de dados espelhados do Microsoft Fabric (Versão Preliminar)
- Monitoramento de bancos de dados espelhados do Microsoft Fabric
- Explorar dados em seu banco de dados espelhado usando o Microsoft Fabric
- O que é o Microsoft Fabric?
- Modelar dados no modelo semântico padrão do Power BI no Microsoft Fabric
- Qual é o ponto de extremidade de análise SQL para um Lakehouse?
- Direct Lake
Usar o SQL Server 2022 com o Link do Azure Synapse para SQL
O SQL Server 2022 (16.x) contém um novo recurso que permite a conectividade entre as tabelas do SQL Server e a plataforma Microsoft Azure Synapse, que é o Link do Azure Synapse para SQL. O Link do Azure Synapse para o SQL Server 2022 (16.x) fornece feeds de alterações automáticos que capturam as alterações no SQL Server e as carregam no Azure Synapse Analytics. Ele fornece análise quase em tempo real e processamento analítico e transacional híbrido com impacto mínimo sobre os sistemas operacionais. Depois que os dados estiverem em Synapse, você poderá combiná-los com muitas fontes de dados diferentes, independentemente de seu tamanho, escala ou formato e executar uma análise eficiente em todas elas usando sua escolha de Azure Machine Learning, Spark ou Power BI. Como os feeds de alterações automatizados só efetuam push do que há de novo ou diferente, a transferência de dados ocorre muito mais rápido e já permite insights quase em tempo real, com impacto mínimo sobre o desempenho do banco de dados de origem no SQL Server 2022 (16.x).
Para as cargas de trabalho de operações e muitas das analíticas, o SQL Server pode lidar com tamanhos de banco de dados muito grandes. Para saber mais sobre as especificações de capacidade máxima do SQL Server, confira Calcular os limites de capacidade por edição do SQL Server. O uso de várias instâncias de SQL Server em computadores separados com solicitações de T-SQL particionadas permite um ambiente de expansão para aplicativos.
O uso do PolyBase permite que sua instância do SQL Server consulte dados com o T-SQL diretamente do SQL Server, Oracle, Teradata, MongoDB e Cosmos DB sem instalar separadamente o software de conexão cliente. Você também pode usar o conector ODBC genérico em uma instância baseada no Microsoft Windows para se conectar a provedores adicionais usando drivers ODBC de terceiros. O PolyBase permite que as consultas T-SQL ingressem os dados de fontes externas em tabelas relacionais em uma instância do SQL Server. Isso permite que os dados se mantenham em sua localização e formato original. É possível virtualizar os dados em uma instância do SQL Server para que ela possa ser consultada no local como qualquer outra tabela no SQL Server. O SQL Server 2022 (16.x) também permite consultas ad hoc e backup/restauração no Repositório de Objetos (usando as opções de armazenamento de hardware ou software da API do S3).
Duas arquiteturas de referência gerais são usar SQL Server em um servidor autônomo para consultas de dados estruturadas e uma instalação separada de um sistema não relacional de expansão (como Apache Hadoop ou Apache Spark) para o Link para Synapse local e a outra opção é usar um conjunto de contêineres em um cluster Kubernetes com todos os componentes para sua solução.
O Microsoft SQL Server no Windows, Apache Spark e armazenamento de objetos local
Você pode instalar o SQL Server no Windows ou no Linux e escalar verticalmente a arquitetura de hardware, usando o recurso de consulta do armazenamento de objetos do SQL Server 2022 (16.x) e o recurso PolyBase para habilitar as consultas em todos os dados no seu sistema.
Instalar e configurar uma plataforma de expansão, como Apache Hadoop ou Apache Spark, permite consultar dados não relacionais em escala. O uso de um conjunto central de sistemas de Armazenamento de Objetos que dê suporte à API do S3 permite que o SQL Server 2022 (16.x) e o Spark acessem o mesmo conjunto de dados em todos os sistemas.
O conector Microsoft Apache Spark para SQL Server e SQL do Azure também permite que você consulte dados diretamente do SQL Server usando Trabalhos do Spark. Para saber mais sobre o conector Apache Spark para SQL Server e SQL do Azure, confira Conector Apache Spark: SQL Server e SQL do Azure.
Você também pode usar o sistema de orquestração de contêiner Kubernetes para sua implantação. Isso permite uma arquitetura declarativa que pode ser executada localmente ou em qualquer Nuvem que dê suporte a Kubernetes ou à plataforma Red Hat OpenShift. Para saber mais sobre como implantar o SQL Server em um ambiente Kubernetes, confira Implantar um cluster de contêiner SQL Server no Azure ou assista a Implantação do SQL Server 2019 no Kubernetes.
Use SQL Server e Hadoop/Spark local como uma substituição aos Clusters de Big Data do SQL Server 2019 quando precisar:
- Manter toda a solução no local
- Usar hardware dedicado para todas as partes da solução
- Acessar dados relacionais e não relacionais da mesma arquitetura, em ambas as direções
- Compartilhar um único conjunto de dados não relacionais entre o SQL Server e o sistema não relacional de expansão
Realizar a migração
Depois de escolher um local (na Nuvem ou Híbrido) para sua migração, você deverá avaliar o tempo de inatividade e os vetores de custo para determinar se você executará um novo sistema e moverá os dados do sistema anterior para o novo em tempo real (migração lado a lado) ou um backup e uma restauração, ou um novo início do sistema de fontes de dados existentes (migração in-loco).
Sua próxima decisão será reescrever a funcionalidade atual no seu sistema usando a nova opção de arquitetura ou mover o máximo possível do código para o novo sistema. Embora a escolha anterior possa levar mais tempo, ela permitirá que você use os novos métodos, conceitos e vantagens que a nova arquitetura fornece. Nesse caso, o acesso a dados e os mapas de funcionalidade são os principais esforços de planejamento nos quais você deve se concentrar.
Se você planeja migrar o sistema atual com o mínimo de alteração de código possível, a compatibilidade de idioma é seu foco principal para o planejamento.
Migração de código
A próxima etapa é auditar o código que o sistema atual usa e saber quais alterações precisam ser executadas no novo ambiente.
Há dois vetores principais para a migração de código a considerar:
- Fontes e coletores
- Migração de funcionalidade
Fontes e coletores
A primeira tarefa na migração de código é identificar os métodos de conexão de fonte de dados, cadeias de caracteres ou APIs que o código usa para acessar os dados que são importados, seu caminho e seu destino final. Documente essas fontes e crie um mapa para os locais da nova arquitetura.
- Se a solução atual estiver usando um sistema de pipeline para mover os dados por meio do sistema, mapeie as novas fontes, etapas e coletores de arquitetura para os componentes do pipeline.
- Se a nova solução também estiver substituindo a arquitetura do pipeline, trate o sistema como uma nova instalação para fins de planejamento, mesmo se você estiver reutilizando o hardware ou a plataforma de nuvem como a substituição.
Migração de funcionalidade
O trabalho mais complexo necessário em uma migração é fazer referência, atualizar ou criar a documentação da funcionalidade do sistema atual. Se você estiver planejando uma atualização in-loco e tentar reduzir a quantidade de regravação de código o máximo possível, essa etapa levará mais tempo.
No entanto, uma migração de uma tecnologia anterior geralmente é um momento ideal para se atualizar para os avanços mais recentes em tecnologia e aproveitar as construções que ele fornece. Muitas vezes, você pode obter mais segurança, desempenho, opções de recursos e até mesmo otimizações de custo por uma regravação do seu sistema atual.
Em ambos os casos, você tem dois fatores principais envolvidos na migração: o código e os idiomas aos quais o novo sistema dá suporte e as escolhas em relação à movimentação de dados. Normalmente, você deve ser capaz de alterar as cadeias de conexão do cluster de Big Data atual para a instância do SQL Server e o ambiente do Spark. Todas as informações de conexão de dados e a transferência de código devem ser mínimas.
Se você estiver prevendo uma regravação de sua funcionalidade atual, mapeie as novas bibliotecas, pacotes e DLLs para a arquitetura escolhida para a sua migração. Você encontrará uma lista de cada uma das bibliotecas, linguagens e funções que cada solução oferece nas referências de documentação mostradas nas seções anteriores. Mapeie quaisquer idiomas suspeitos ou sem suporte e planeje a substituição com a arquitetura escolhida.
Opções de migração de dados
Há duas abordagens comuns para a movimentação de dados em um sistema analítico em larga escala. A primeira é criar um processo de "transferência" onde o sistema original continua processando dados e esses dados são acumulados em um conjunto menor de fontes de dados de relatório agregadas. O novo sistema é iniciado com dados atualizados e é usado da data da migração em diante.
Em alguns casos, todos os dados precisam ser movidos do sistema herdado para o novo sistema. Nesse caso, você poderá montar os armazenamentos de arquivos originais de Clusters de Big Data do SQL Server se o novo sistema der suporte a ele e, em seguida, copiar os dados em trechos para o novo sistema, ou você pode criar uma movimentação física.
Migrar seus dados atuais dos Clusters de Big Data do SQL Server 2019 para outro sistema é altamente dependente de dois fatores: o local dos dados atuais e o destino que está no local ou para a nuvem.
Migração de dados local
Para migrações locais para locais, você pode migrar os dados do SQL Server com uma estratégia de backup e restauração ou pode configurar a replicação para mover alguns ou todos os dados relacionais. O SQL Server Integration Services também pode ser usado para copiar dados de SQL Server para outro local. Para saber mais sobre como mover dados com SSIS, confira SQL Server Integration Services.
Para os dados do HDFS no atual ambiente do Cluster de Big Data do SQL Server, a abordagem padrão é montar os dados em um Cluster do Spark autônomo e usar o processo do Armazenamento de Objetos para mover os dados para que uma instância do SQL Server 2022 (16.x) possa acessá-lo ou deixá-lo como está e continuar processando-o com os Trabalhos do Spark.
Migração de dados na nuvem
Para dados localizados no armazenamento em nuvem ou no local, você pode usar o Azure Data Factory, que tem mais de 90 conectores para um pipeline completo de transferência, com agendamento, monitoramento, alertas e outros serviços. Para saber mais sobre o Azure Data Factory, confira O que é o Azure Data Factory?
Se você quiser mover grandes quantidades de dados com segurança e rapidez do seu estado de dados local para o Microsoft Azure, poderá usar o serviço de Importação/Exportação do Azure. O serviço de Importação/Exportação do Azure permite transferir com segurança grandes quantidades de dados para o armazenamento de blobs do Azure e Arquivos do Azure por meio do envio de unidades de disco rígido para um data center do Azure. Este serviço também pode ser usado para transferir dados do armazenamento de Blobs do Azure para as unidades de disco e enviar para seu site local. Os dados de uma ou mais unidades de disco podem ser importados para o armazenamento de Blobs do Azure ou para os Arquivos do Azure. Para quantidades muito grandes de dados, o uso desse serviço pode ser o caminho mais rápido.
Se você quiser transferir dados usando unidades de disco fornecidas pela Microsoft, é possível usar o Azure Data Box Disk para importar dados para o Azure. Para saber mais, confira O que é o serviço de Importação/Exportação do Azure?
Para saber mais sobre essas opções e as decisões que as acompanham, confira Uso do Azure Data Lake Storage Gen1 para requisitos de Big Data.
Conteúdo relacionado
Comentários
Brevemente: Ao longo de 2024, vamos descontinuar progressivamente o GitHub Issues como mecanismo de feedback para conteúdos e substituí-lo por um novo sistema de feedback. Para obter mais informações, veja: https://aka.ms/ContentUserFeedback.
Submeter e ver comentários