Формат текста с разделителями в Фабрике данных Azure и Azure Synapse Analytics
Область применения: Фабрика данных Azure Azure Synapse Analytics
Фабрика данных Azure Azure Synapse Analytics
Совет
Попробуйте использовать фабрику данных в Microsoft Fabric, решение для аналитики с одним интерфейсом для предприятий. Microsoft Fabric охватывает все, от перемещения данных до обработки и анализа данных в режиме реального времени, бизнес-аналитики и отчетности. Узнайте, как бесплатно запустить новую пробную версию !
Если вам нужно проанализировать текстовые файлы с разделителями или записать данные в формате текста с разделителями, следуйте инструкциям в этой статье.
Для приведенных ниже соединителей поддерживается формат текста с разделителями:
- Amazon S3
- Совместимая служба хранилища Amazon S3
- Хранилище BLOB-объектов Azure
- Azure Data Lake Storage 1-го поколения
- Azure Data Lake Storage 2-го поколения
- Файлы Azure
- Файловая система
- FTP
- Google Cloud Storage
- HDFS
- HTTP
- Oracle Cloud служба хранилища
- SFTP
Свойства набора данных
Полный список разделов и свойств, доступных для определения наборов данных, см. в статье о наборах данных. В этом разделе содержится список свойств, поддерживаемых набором данных текста с разделителями.
| Свойство | Описание: | Обязательное поле |
|---|---|---|
| type | Свойство type (Тип) для набора данных должно иметь значение DelimitedText. | Да |
| Расположение | Параметры расположения файлов. Каждый файловый соединитель имеет собственный тип расположения и поддерживает собственный набор свойств в разделе location. |
Да |
| columnDelimiter | Знаки, используемые для разделения столбцов в файле. Значение по умолчанию — запятая ( ,). Если разделитель столбцов определен как пустая строка, что означает отсутствие разделителя, то вся строка принимается за один столбец.В настоящее время разделитель столбцов в виде пустой строки поддерживается только для потока данных для сопоставления, но не для действия Copy. |
No |
| rowDelimiter | В действии Copy — один знак или строка "\r\n", которая используется для разделения строк в файле. По умолчанию используется одно из следующих значений: для чтения — "\r\n", "\r", "\n", для записи — "\r\n". Разделитель "\r\n" поддерживается только в команде Copy. В потоке данных для сопоставления — один или два знака, которые используются для разделения строк в файле. По умолчанию используется одно из следующих значений: для чтения — "\r\n", "\r", "\n", для записи — "\n". Если для разделителя строк указана пустая строка (т. е. он не задан), то разделитель столбцов также должен отсутствовать (для него также должна быть указана пустая строка), что означает, что все содержимое обрабатывается как одно значение. В настоящее время разделитель строк в виде пустой строки поддерживается только для потока данных для сопоставления, но не для действия Copy. |
No |
| quoteChar | Один знак для заключения в кавычки значения столбца, если оно содержит разделитель столбцов. Значение по умолчанию — двойные кавычки ( "). Если параметр quoteChar определен как пустая строка, это означает, что кавычки не используются, значение столбца не заключается в кавычки, а знак escapeChar используется для экранирования разделителя столбцов и самого себя. |
No |
| escapeChar | Один знак для экранирования кавычек внутри значения в кавычках. Значение по умолчанию — обратная косая черта ( \). Если параметр escapeChar определен как пустая строка, то параметр quoteChar также должен быть задан как пустая строка. В этом случае убедитесь в том, что ни одно значение столбца не содержат разделителей. |
No |
| firstRowAsHeader | Указывает, следует ли интерпретировать первую строку как строку заголовка с именами столбцов. Допустимые значения: true и false (по умолчанию). Если для использования первой строки в качестве заголовка задано значение false, то необходимо учесть следующее: действия предварительного просмотра и поиска данных пользовательского интерфейса автоматически создают имена столбцов вида Prop_{n} (начиная с 0), действие копирования требует явного сопоставления источника и приемника и находит столбцы по порядковому номеру (начиная с 1), а поток данных для сопоставления перечисляет и находит столбцы с именами вида Column_{n} (начиная с 1). |
No |
| nullValue | Задает строковое представление значения NULL. Значение по умолчанию — пустая строка. |
No |
| encodingName | Тип кодировки, используемый для чтения и записи тестовых файлов. Допустимые значения: "UTF-8","UTF-8 without BOM", "UTF-16", "UTF-16BE", "UTF-32", "UTF-32BE", "US-ASCII", "UTF-7", "BIG5", "EUC-JP", "EUC-KR", "GB2312", "GB18030", "JOHAB", "SHIFT-JIS", "CP875", "CP866", "IBM00858", "IBM037", "IBM273", "IBM437", "IBM500", "IBM737", "IBM775", "IBM850", "IBM852", "IBM855", "IBM857", "IBM860", "IBM861", "IBM863", "IBM864", "IBM865", "IBM869", "IBM870", "IBM01140", "IBM01141", "IBM01142", "IBM01143", "IBM01144", "IBM01145", "IBM01146", "IBM01147", "IBM01148", "IBM01149", "ISO-2022-JP", "ISO-2022-KR", "ISO-8859-1", "ISO-8859-2", "ISO-8859-3", "ISO-8859-4", "ISO-8859-5", "ISO-8859-6", "ISO-8859-7", "ISO-8859-8", "ISO-8859-9", "ISO-8859-13", "ISO-8859-15", "WINDOWS-874", "WINDOWS-1250", "WINDOWS-1251", "WINDOWS-1252", "WINDOWS-1253", "WINDOWS-1254", "WINDOWS-1255", "WINDOWS-1256", "WINDOWS-1257", "WINDOWS-1258". Обратите внимание: поток данных для сопоставления не поддерживает кодировку UTF-7. Поток данных сопоставления заметок не поддерживает кодировку UTF-8 с меткой порядка байтов (BOM). |
No |
| compressionCodec | Кодек сжатия, используемый для чтения и записи текстовых файлов. Допустимые значения: bzip2, gzip, deflate, ZipDeflate, TarGzip, Tar, snappy, lz4. Значение по умолчанию — без сжатия. Примечание. В настоящее время действие Copy не поддерживает кодек "snappy" и "lz4", а поток данных сопоставления не поддерживает кодеки "ZipDeflate", "TarGzip"и"Tar". Обратите внимание, что при использовании действия копирования для распаковки файлов ZipDeflate/TarGzip/tar и записи в файловое хранилище данных приемника по умолчанию файлы распаковываются в папку: <path specified in dataset>/<folder named as source compressed file>/, используйте preserveZipFileNameAsFolder/preserveCompressionFileNameAsFolder в источнике действия копирования, чтобы использовать имя сжатого (-ых) файла (-ов) для названия структуры папок. |
No |
| compressionLevel | Коэффициент сжатия. Допустимые значения: оптимальный или самый быстрый. - Fastest: операция сжатия должна выполняться как можно быстрее, даже если итоговый файл будет сжат не оптимально. - Optimal: операция сжатия должна выполняться оптимально, даже если для ее завершения требуется больше времени. Дополнительные сведения см. в разделе Уровень сжатия. |
No |
Это пример набора данных текста с разделителями в Хранилище BLOB-объектов Azure:
{
"name": "DelimitedTextDataset",
"properties": {
"type": "DelimitedText",
"linkedServiceName": {
"referenceName": "<Azure Blob Storage linked service name>",
"type": "LinkedServiceReference"
},
"schema": [ < physical schema, optional, retrievable during authoring > ],
"typeProperties": {
"location": {
"type": "AzureBlobStorageLocation",
"container": "containername",
"folderPath": "folder/subfolder",
},
"columnDelimiter": ",",
"quoteChar": "\"",
"escapeChar": "\"",
"firstRowAsHeader": true,
"compressionCodec": "gzip"
}
}
}
Свойства действия копирования
Полный список разделов и свойств, используемых для определения действий, см. в статье Конвейеры и действия в фабрике данных Azure. В этом разделе содержится список свойств, поддерживаемых источником и приемником текста с разделителями.
Текст с разделителями в качестве источника
В разделе источника *source* действия копирования поддерживаются указанные ниже свойства.
| Свойство | Описание: | Обязательное поле |
|---|---|---|
| type | Свойство type источника действия копирования должно иметь значение DelimitedTextSource. | Да |
| formatSettings | Группа свойств. См. ниже таблицу параметров чтения текста с разделителями. | No |
| storeSettings | Группа свойств, определяющих способ чтения данных из хранилища данных. Каждый файловый соединитель поддерживает собственный набор параметров чтения в разделе storeSettings. |
No |
Поддерживаемые параметры чтения текста с разделителями в разделе formatSettings:
| Свойство | Описание: | Обязательное поле |
|---|---|---|
| type | Для свойства type в formatSettings должно быть задано значение DelimitedTextReadSettings. | Да |
| skipLineCount | Указывает количество непустых строк, которые нужно пропустить при чтении данных из входных файлов. Если указаны skipLineCount и firstRowAsHeader, то сначала пропускаются строки, а затем считываются данные заголовка из входного файла. |
No |
| compressionProperties | Группа свойств для распаковки данных для данного кодека сжатия. | No |
| preserveZipFileNameAsFolder (в разделе compressionProperties->type как ZipDeflateReadSettings) |
Применяется, когда для входного набора данных настроено сжатие ZipDeflate. Указывает, следует ли использовать имя исходного ZIP-файла в качестве имени структуры папок во время копирования. — Если задано значение true (по умолчанию), служба записывает разархивированные файлы в <path specified in dataset>/<folder named as source zip file>/.— Если задано значение false, служба записывает разархивированные файлы непосредственно в <path specified in dataset>. Чтобы избежать непредвиденных ситуаций, убедитесь в том, что в разных исходных ZIP-файлах нет файлов с одинаковыми именами. |
No |
| preserveCompressionFileNameAsFolder (в разделе compressionProperties->type как TarGZipReadSettings или TarReadSettings) |
Применяется, когда для входного набора данных настроено сжатие TarGzip/Tar. Указывает, следует ли сохранять имя исходного сжатого файла в качестве имени структуры папок во время копирования. — Если задано значение true (по умолчанию), служба записывает распакованные файлы в <path specified in dataset>/<folder named as source compressed file>/. — Если задано значение false, служба записывает распакованные файлы непосредственно в <path specified in dataset>. Чтобы избежать непредвиденных ситуаций, убедитесь в том, что в разных исходных файлах нет файлов с одинаковыми именами. |
No |
"activities": [
{
"name": "CopyFromDelimitedText",
"type": "Copy",
"typeProperties": {
"source": {
"type": "DelimitedTextSource",
"storeSettings": {
"type": "AzureBlobStorageReadSettings",
"recursive": true
},
"formatSettings": {
"type": "DelimitedTextReadSettings",
"skipLineCount": 3,
"compressionProperties": {
"type": "ZipDeflateReadSettings",
"preserveZipFileNameAsFolder": false
}
}
},
...
}
...
}
]
Текст с разделителями в качестве приемника
В разделе *sink* действия Copy поддерживаются следующие свойства.
| Свойство | Описание: | Обязательное поле |
|---|---|---|
| type | Свойство type источника действия копирования должно иметь значение DelimitedTextSink. | Да |
| formatSettings | Группа свойств. См. ниже таблицу параметров записи текста с разделителями. | No |
| storeSettings | Группа свойств, определяющих способы записи данных в хранилище данных. Каждый файловый соединитель поддерживает собственный набор параметров записи в разделе storeSettings. |
No |
Поддерживаемые параметры записи текста с разделителями в разделе formatSettings:
| Свойство | Описание: | Обязательное поле |
|---|---|---|
| type | Для свойства type в formatSettings должно быть задано значение DelimitedTextWriteSettings. | Да |
| fileExtension | Расширение файла, которое используется для именования выходных файлов, например .csv или .txt. Оно должно быть указано, если в выходном наборе данных DelimitedText не задано значение fileName. Если имя файла настроено в выходном наборе данных, оно будет использоваться в качестве имени файла приемника, а параметр расширения файла будет проигнорирован. |
Да, если в выходном наборе данных не указано имя файла |
| maxRowsPerFile | Можно выбрать режим записи данных в папку с разбиением на несколько файлов и указать максимальное число строк в одном таком файле. | No |
| fileNamePrefix | Это свойство применимо, если задано свойство maxRowsPerFile.Оно задает префикс, добавляемый к имени файла при записи данных с разбиением на несколько файлов. Имя присваивается по следующему шаблону: <fileNamePrefix>_00000.<fileExtension>. Если это свойство не задано, то префикс имени файла будет создан автоматически. Это свойство не применяется, если источником является файловое хранилище или хранилище данных с поддержкой разделов. |
No |
Свойства потока данных для сопоставления
В потоках данных для сопоставления можно читать и записывать данные в виде текста с разделителями в следующих хранилищах данных: Хранилище BLOB-объектов Azure, Azure Data Lake Storage 1-го поколения, Azure Data Lake Storage 2-го поколения и SFTP; также чтение текста с разделителями поддерживается Amazon S3.
Встроенный набор данных
Сопоставление потоков данных поддерживает встроенные наборы данных в качестве варианта определения источника и приемника. Встроенный набор данных с разделителями определяется непосредственно внутри преобразования источника и приемника и не предоставляет общий доступ за пределами определенного потока данных. Это полезно для параметризации свойств набора данных непосредственно внутри потока данных и может повысить производительность общих наборов данных ADF.
При чтении большого количества исходных папок и файлов можно повысить производительность обнаружения файлов потока данных, задав параметр "Проецированная пользователем схема" в проекции | Диалоговое окно параметров схемы. Этот параметр отключает автоматическое обнаружение схемы ADF по умолчанию и значительно повышает производительность обнаружения файлов. Перед настройкой этого параметра обязательно импортируйте проекцию, чтобы ADF имеет существующую схему для проекции. Этот параметр не работает с смещением схемы.
Свойства источника
В таблице ниже указаны свойства, поддерживаемые источником текста с разделителями. Изменить эти свойства можно на вкладке Source options (Параметры источника).
| Имя | Описание | Обязательное поле | Допустимые значения | Свойство скрипта для потока данных |
|---|---|---|---|---|
| Пути с подстановочными знаками | Будут обработаны все файлы, соответствующие пути с подстановочными знаками. Переопределяет папку и путь к файлу, заданные в наборе данных. | no | String[] | wildcardPaths |
| Корневой путь раздела | Для секционированных файловых данных можно ввести корневой путь к секции, чтобы считывать секционированные папки как столбцы | no | Строка | partitionRootPath |
| Список файлов | Сообщает о том, указывает ли источник на текстовый файл, в котором перечислены файлы для обработки. | no | true или false |
fileList |
| Строки с подстроками | Указывает, содержит ли исходный файл строки, охватывающие несколько строк. Многострочные значения должны быть заключены в кавычки. | Ни true, ни false |
multiLineRow | |
| Столбец для хранения имени файла | Предписывает создать столбец с именем и путем исходного файла. | no | Строка | rowUrlColumn |
| After completion (После завершения) | Инструкции в отношении удаления или перемещения файлов после обработки. Путь к файлу начинается с корня контейнера. | no | Удаление: true или false Перемещение: ['<from>', '<to>'] |
Очистка файлов moveFiles |
| Фильтр по последнему изменению | Задает фильтр для файлов по времени последнего изменения | no | Метка времени | modifiedAfter modifiedBefore |
| Allow no files found (Разрешить ненайденные файлы) | Когда задано значение true, ошибка не возникает, если файлы не найдены | no | true или false |
ignoreNoFilesFound |
| Максимальное число столбцов | Значение по умолчанию — 20480. Настройте это значение, если число столбцов больше 20480 | no | Целое | maxColumns |
Примечание.
Поддержка источников потока данных для списка файлов ограничена 1024 записями в файле. Чтобы включить дополнительные файлы, используйте подстановочные знаки в списке файлов.
Пример источника
На этом изображении показан пример конфигурации источника текста с разделителями в потоках данных для сопоставления:

Связанный скрипта потока данных:
source(
allowSchemaDrift: true,
validateSchema: false,
ignoreNoFilesFound: false,
multiLineRow: true,
wildcardPaths:['*.csv']) ~> CSVSource
Примечание.
Источники потока данных поддерживают ограниченный набор globbing Linux, поддерживаемый файловыми системами Hadoop.
Свойства приемника
В таблице ниже указаны свойства, поддерживаемые приемником текста с разделителями. Эти свойства можно изменить на вкладке Параметры.
| Имя | Описание | Обязательное поле | Допустимые значения | Свойство скрипта для потока данных |
|---|---|---|---|---|
| Clear the folder (Очистить папку) | Указывает, очищается ли конечная папка перед записью | no | true или false |
truncate |
| File name option (Параметр имени файла) | Формат именования записываемого файла данных. По умолчанию — по одному файлу на секцию в формате part-#####-tid-<guid> |
no | Шаблон: строка На секцию: String[] Имя файла в виде данных столбца: Строка Вывод в один файл: ['<fileName>'] Именование папки как данных столбца: String |
filePattern partitionFileNames rowUrlColumn partitionFileNames rowFolderUrlColumn |
| Заключать все в кавычки | Предписывает заключать все значения в кавычки. | no | true или false |
quoteAll |
| Верхний колонтитул | Добавление пользовательских заголовков в выходные файлы | no | [<string array>] |
авторизации |
Пример приемника
На этом изображении показан пример конфигурации приемника текста с разделителями в потоках данных для сопоставления:
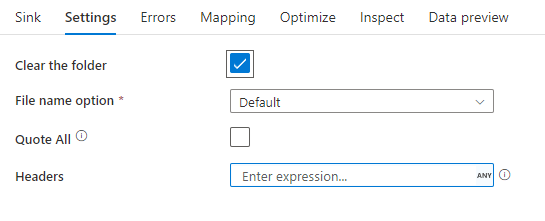
Связанный скрипта потока данных:
CSVSource sink(allowSchemaDrift: true,
validateSchema: false,
truncate: true,
skipDuplicateMapInputs: true,
skipDuplicateMapOutputs: true) ~> CSVSink
Связанные соединители и форматы
Ниже приведены некоторые распространенные соединители и форматы, связанные с форматом текста с разделителями:
- Хранилище BLOB-объектов Azure (connector-azure-blob-storage.md);
- двоичный формат (format-binary.md);
- Dataverse (connector-dynamics-crm-office-365.md);
- формат Delta (format-delta.md);
- формат Excel (format-excel.md);
- файловая система (connector-file-system.md);
- FTP (connector-ftp.md);
- HTTP (connector-http.md);
- формат JSON (format-json.md);
- формат Parquet (format-parquet.md).