Учебник. Начало работы со скриптом Python в Машинном обучении Azure (SDK версии 1, часть 1 из 3)
ОБЛАСТЬ ПРИМЕНЕНИЯ: Пакет SDK для Python для ML Azure версии 1
Пакет SDK для Python для ML Azure версии 1
Изучив этот учебник, вы научитесь запускать первый скрипт Python в облаке с помощью Машинного обучения Azure. Это руководство является частью 1 серии учебников с двумя частью.
В этом учебнике устранены сложности обучения модели машинного обучения. Вы запустите скрипт Python Hello World в облаке. Вы узнаете, как используется скрипт элемента управления для настройки и создания запуска в Машинное обучение Azure.
При работе с этим руководством вы сделаете следующее:
- Создадите и запустите скрипт "Hello World!" на Python.
- Создадите скрипт управления на Python для отправки "Hello World!" в Машинное обучение Azure.
- Примените концепции Машинного обучения Azure в сценарии элемента управления.
- Отправите и запустите скрипт "Hello World!".
- просмотрите выходные данные кода в облаке;
Необходимые компоненты
- Выполните инструкции по созданию ресурсов , необходимых для создания рабочей области и вычислительного экземпляра для использования в этом руководстве.
-
- Создайте облачный вычислительный кластер. Присвойт ему имя cpu-cluster, чтобы соответствовать коду в этом руководстве.
Создание и запуск скрипта Python
В этом руководстве в качестве компьютера разработки используется вычислительный экземпляр. Сначала создайте несколько папок и скрипт.
- Войдите в Студию машинного обучения Azure и, если потребуется, выберите свою рабочую область.
- Выберите Записные книжки слева.
- На панели инструментов Файлы выберите +, а затем выберите Создать папку.
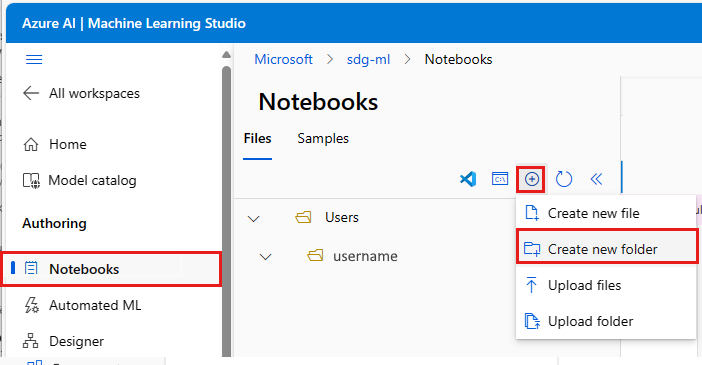
- Назовите папку get-started.
- Справа от имени папки нажмите ..., чтобы создать другую папку в каталоге get-started.
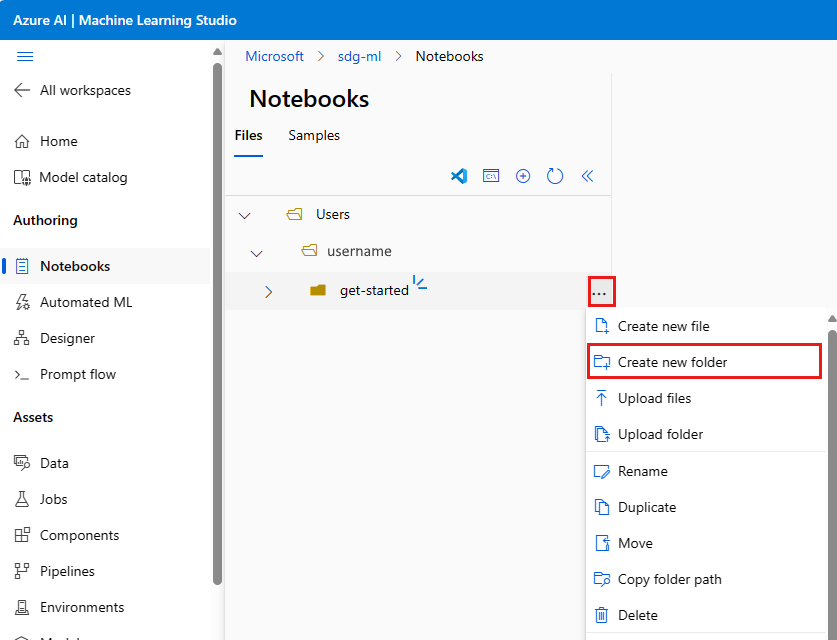
- Назовите новую папку src. Используйте ссылку "Изменить расположение", если расположение файла неправильно.
- Справа от папки src нажмите ..., чтобы создать файл в папке src.
- Назовите файл hello.py. Смените тип файла на Python (.py)*.
Скопируйте в файл этот код:
# src/hello.py
print("Hello world!")
Теперь структура каталогов проекта будет выглядеть следующим образом:
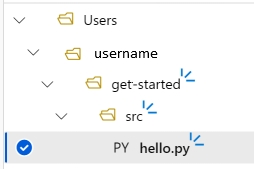
Тестирование скрипта
Код можно запускать локально, что в данном случае означает запуск на вычислительном экземпляре. Выполнение кода в локальной среде предоставляет преимущество в виде интерактивной отладки кода.
Если вы ранее остановили вычислительный экземпляр, запустите его с помощью инструмента Запуск вычислений справа от раскрывающегося списка вычислений. Подождите около минуты, пока состояние не изменится на Выполняется.

Выберите Сохранить и запустить скрипт в терминале, чтобы запустить скрипт.
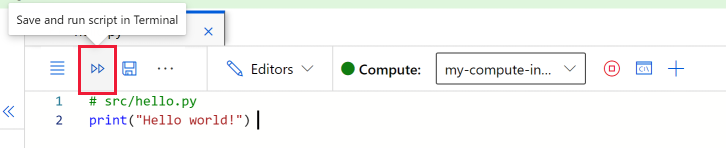
Выходные данные скрипта отображаются в открываемом окне терминала. Закройте вкладку и выберите Завершить, чтобы закрыть сеанс.
Создание скрипта элемента управления
Скрипт элемента управления позволяет запускать скрипт hello.py на различных вычислительных ресурсах. Сценарий элемента управления используется, чтобы контролировать, как и где выполняется код машинного обучения.
Выберите ... справа от папки get-started, чтобы создать новый файл. Создайте новый файл Python под названием run-hello.py. Затем скопируйте и вставьте в этот файл следующий код:
# get-started/run-hello.py
from azureml.core import Workspace, Experiment, Environment, ScriptRunConfig
ws = Workspace.from_config()
experiment = Experiment(workspace=ws, name='day1-experiment-hello')
config = ScriptRunConfig(source_directory='./src', script='hello.py', compute_target='cpu-cluster')
run = experiment.submit(config)
aml_url = run.get_portal_url()
print(aml_url)
Совет
Если при создании кластера вычислений вы использовали другое имя, обязательно измените его в коде compute_target='cpu-cluster'.
Изучение кода
Ниже приведено описание функционирования скрипта элемента управления.
ws = Workspace.from_config()
Workspace подключается к рабочей области Машинного обучения Azure, чтобы можно было взаимодействовать с ресурсами Машинного обучения Azure.
experiment = Experiment( ... )
Experiment предоставляет простой способ организации нескольких заданий с одним именем. В дальнейшем можно увидеть, как эксперименты упрощают сравнение метрик множества заданий.
config = ScriptRunConfig( ... )
ScriptRunConfig создает оболочку для кода hello.py и передает его в рабочую область. Как следует из названия, этот класс можно использовать для настройкизапускаскрипта в Машинном обучении Azure. Он также указывает, в каком целевом объекте вычислений выполняется скрипт. В этом коде целевым объектом является вычислительный кластер, созданный в рамках учебника по настройке.
run = experiment.submit(config)
Отправляет скрипт. Эта отправка называется запуском. В версии 2 она была переименована в задание. Запуск/задание инкапсулирует одно выполнение кода. Используйте задание, чтобы отслеживать ход выполнения скрипта, записывать выходные данные, анализировать результаты, визуализировать метрики и многое другое.
aml_url = run.get_portal_url()
Объект run предоставляет дескриптор для выполнения кода. Отслеживайте ход выполнения из Студия машинного обучения Azure с URL-адресом, который выводится из скрипта Python.
Отправка и выполнение кода в облаке
Выберите Сохранить и запустить скрипт в терминале, чтобы запустить скрипт управления, который, в свою очередь, выполняется в кластере вычислений
hello.py, созданном в руководстве по установке.В терминале может появиться запрос на вход для проверки подлинности. Скопируйте код и перейдите по ссылке, чтобы выполнить этот шаг.
После проверки подлинности вы увидите ссылку в терминале. Щелкните ссылку, чтобы просмотреть задание.
Мониторинг кода в облаке с помощью Студии
Выходные данные из скрипта содержат ссылку на студию, которая выглядит примерно так: https://ml.azure.com/experiments/hello-world/runs/<run-id>?wsid=/subscriptions/<subscription-id>/resourcegroups/<resource-group>/workspaces/<workspace-name>
Перейдите по ссылке. Сначала отображается состояние очереди или подготовки. Первый запуск занимает 5–10 минут. Это происходит по следующей причине:
- в облаке создается образ Docker;
- размер вычислительного кластера изменяется с 0 на 1 узел;
- Образ Docker загружается в вычислительный кластер.
Последующие задания быстрее (около 15 секунд), так как образ Docker кэшируется в вычислительных ресурсах. Это можно проверить, повторно отправив приведенный ниже код после завершения первого задания.
Подождите около 10 минут. Появится сообщение о завершении задания. Затем нажмите Обновить, чтобы увидеть, что состояние изменилось на Завершено. После завершения задания перейдите на вкладку "Выходные данные и журналы ". Там можно увидеть std_log.txt файл в папке user_logs . Выходные данные скрипта приведены в этом файле.
system-logs Папки azureml-logs содержат файлы, которые могут быть полезны при отладке удаленных заданий в облаке.
Следующий шаг
В рамках этого учебника вы выполнили простой скрипт "Hello World!" и запустили его в Azure. Вы узнали, как подключиться к рабочей области Машинного обучения Azure, создать эксперимент и отправить свой код hello.py в облако.
В следующем учебнике, основываясь на этих сведениях, вы запустите скрипт более интересный, чем print("Hello world!").
Примечание.
Если вы хотите на этом завершить серию учебников, не переходя к следующему шагу, очистите ресурсы.