Учебник по началу работы с обучением моделей машинного обучения (пакет SDK версии 1, часть 2 из 3)
ОБЛАСТЬ ПРИМЕНЕНИЯ: Пакет SDK для Python для ML Azure версии 1
Пакет SDK для Python для ML Azure версии 1
В этом учебнике описано, как обучить модель машинного обучения в Машинном обучении Azure. Это руководство является частью 2 серии учебников с двумя частью.
Из части 1 "Запуск "Hello world!" вы узнали, как использовать сценарий управления для запуска задания в облаке.
В рамках этого учебника вы выполните следующий шаг, отправив сценарий, который обучает модель машинного обучения. В этом примере показано, как Машинное обучение Azure упрощает согласованное поведение между локальным отладкой и удаленными запусками.
Изучив это руководство, вы:
- Создайте сценарий обучения.
- используете Conda для определения среды Машинного обучения Azure;
- Создание скрипта элемента управления
- Общие сведения о классах Машинного обучения Azure (
Environment,Run,Metrics). - отправите и запустите свой сценарий обучения;
- просмотрите выходные данные кода в облаке;
- научитесь вести журнал метрик в Машинном обучении Azure;
- просмотрите свои метрики в облаке.
Необходимые компоненты
- Завершение части 1 в серии.
Создание сценариев обучения
Сначала определите архитектуру нейронной сети в файле model.py. Весь код обучения переходит в src подкаталог, включая model.py.
Обучающий код взят из этого вводного примера из PyTorch. Основные понятия Машинное обучение Azure применяются к любому коду машинного обучения, а не только PyTorch.
Создайте файл model.py во вложенной папке src. Скопируйте следующий код в файл:
import torch.nn as nn import torch.nn.functional as F class Net(nn.Module): def __init__(self): super(Net, self).__init__() self.conv1 = nn.Conv2d(3, 6, 5) self.pool = nn.MaxPool2d(2, 2) self.conv2 = nn.Conv2d(6, 16, 5) self.fc1 = nn.Linear(16 * 5 * 5, 120) self.fc2 = nn.Linear(120, 84) self.fc3 = nn.Linear(84, 10) def forward(self, x): x = self.pool(F.relu(self.conv1(x))) x = self.pool(F.relu(self.conv2(x))) x = x.view(-1, 16 * 5 * 5) x = F.relu(self.fc1(x)) x = F.relu(self.fc2(x)) x = self.fc3(x) return xНа панели инструментов нажмите кнопку Сохранить, чтобы сохранить файл. При необходимости закройте вкладку.
Затем определите скрипт обучения, который также находится во вложенной папке src. Этот скрипт скачивает набор данных CIFAR10 с помощью API-интерфейсов PyTorch
torchvision.dataset, настраивает сеть, определенную в файле model.py, и обучает ее для двух эпох, используя стандартный SGD и потери с перекрестной энтропией.Создайте скрипт train.py во вложенной папке src:
import torch import torch.optim as optim import torchvision import torchvision.transforms as transforms from model import Net # download CIFAR 10 data trainset = torchvision.datasets.CIFAR10( root="../data", train=True, download=True, transform=torchvision.transforms.ToTensor(), ) trainloader = torch.utils.data.DataLoader( trainset, batch_size=4, shuffle=True, num_workers=2 ) if __name__ == "__main__": # define convolutional network net = Net() # set up pytorch loss / optimizer criterion = torch.nn.CrossEntropyLoss() optimizer = optim.SGD(net.parameters(), lr=0.001, momentum=0.9) # train the network for epoch in range(2): running_loss = 0.0 for i, data in enumerate(trainloader, 0): # unpack the data inputs, labels = data # zero the parameter gradients optimizer.zero_grad() # forward + backward + optimize outputs = net(inputs) loss = criterion(outputs, labels) loss.backward() optimizer.step() # print statistics running_loss += loss.item() if i % 2000 == 1999: loss = running_loss / 2000 print(f"epoch={epoch + 1}, batch={i + 1:5}: loss {loss:.2f}") running_loss = 0.0 print("Finished Training")Теперь у вас есть следующая структура папок:
Локальное тестирование.
Выберите Save and run script in terminal (Сохранить и запустить скрипт в терминале), чтобы запустить скрипт train.py непосредственно на вычислительном экземпляре.
После выполнения скрипта нажмите кнопку Обновить над папками файлов. Вы увидите новую папку данных с именем get-started/data Expand this folder, чтобы просмотреть скачанные данные.
Создание среды Python
Машинное обучение Azure реализует концепцию среды, чтобы представить воспроизводимую версионную среду Python для выполнения экспериментов. Вы можете легко создать среду из локальной среды Conda или PIP.
Сначала вы создадите файл с зависимостями пакета.
Создайте новый файл в папке get-started с именем
pytorch-env.yml:name: pytorch-env channels: - defaults - pytorch dependencies: - python=3.7 - pytorch - torchvisionНа панели инструментов нажмите кнопку Сохранить, чтобы сохранить файл. При необходимости закройте вкладку.
Создание сценария элемента управления
Разница между следующим скриптом элемента управления и скриптом, который использовался для отправки "Hello World", заключается в том, что вы добавляете несколько дополнительных строк для задания среды.
Создайте файл Python в папке get-started с именем run-pytorch.py:
# run-pytorch.py
from azureml.core import Workspace
from azureml.core import Experiment
from azureml.core import Environment
from azureml.core import ScriptRunConfig
if __name__ == "__main__":
ws = Workspace.from_config()
experiment = Experiment(workspace=ws, name='day1-experiment-train')
config = ScriptRunConfig(source_directory='./src',
script='train.py',
compute_target='cpu-cluster')
# set up pytorch environment
env = Environment.from_conda_specification(
name='pytorch-env',
file_path='pytorch-env.yml'
)
config.run_config.environment = env
run = experiment.submit(config)
aml_url = run.get_portal_url()
print(aml_url)
Совет
Если при создании кластера вычислений вы использовали другое имя, обязательно измените его в коде compute_target='cpu-cluster'.
Изучение изменений кода
env = ...
Ссылки на файл зависимостей, который вы создали выше.
config.run_config.environment = env
Добавление среды в ScriptRunConfig.
Отправка выполнения в Машинное обучение Azure
Выберите Save and run script in terminal (Сохранить и запустить скрипт в терминале), чтобы запустить скрипт run-pytorch.py.
Вы увидите ссылку в открываемом окне терминала. Щелкните ссылку, чтобы просмотреть задание.
Примечание.
Может появиться предупреждение с текстом Сбой при загрузке azureml_run_type_providers.... Такие предупреждения можно игнорировать. Воспользуйтесь ссылкой в нижней части этих предупреждений, чтобы просмотреть выходные данные.
Просмотр результатов
- На открывающейся странице отображается состояние задания. При первом запуске этого скрипта Машинное обучение Azure создает новый образ Docker из среды PyTorch. Выполнение всего задания может занять до 10 минут. Этот образ будет повторно применяться в будущих заданиях для их ускорения.
- Журналы сборки Docker можно просмотреть в Студии машинного обучения Azure. чтобы просмотреть журналы сборки:
- Откройте вкладку Выходные данные и журналы.
- Выберите папку azureml-logs .
- Выберите 20_image_build_log.txt.
- Если задание имеет состояние Завершено, выберите Выходные данные и журналы.
- Выберите user_logs, а затем std_log.txt , чтобы просмотреть выходные данные задания.
Downloading https://www.cs.toronto.edu/~kriz/cifar-10-python.tar.gz to ../data/cifar-10-python.tar.gz
Extracting ../data/cifar-10-python.tar.gz to ../data
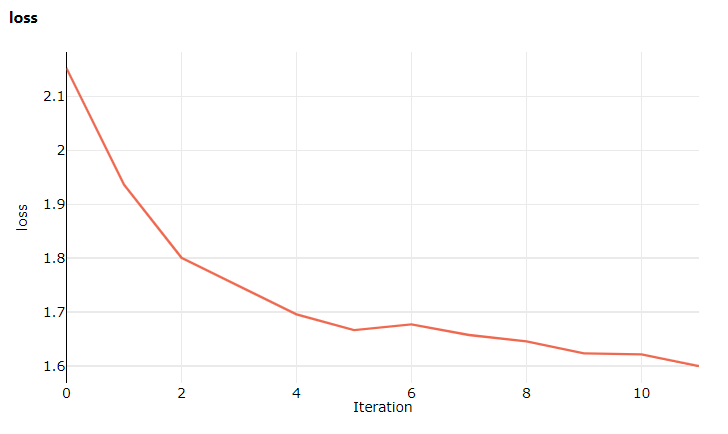
epoch=1, batch= 2000: loss 2.19
epoch=1, batch= 4000: loss 1.82
epoch=1, batch= 6000: loss 1.66
...
epoch=2, batch= 8000: loss 1.51
epoch=2, batch=10000: loss 1.49
epoch=2, batch=12000: loss 1.46
Finished Training
Если отображается сообщение об ошибке Your total snapshot size exceeds the limit, папка data указана в значении source_directory, используемом в ScriptRunConfig.
Щелкните … в конце папки, а затем выберите Переместить, чтобы переместить папку data в папку get-started.
Ведение журнала метрик обучения
Теперь, настроив обучение модели в Машинном обучении Azure, начните отслеживать некоторые метрики производительности.
Текущий сценарий обучения выводит метрики в терминал. Машинное обучение Azure предоставляет механизм для ведения журнала метрик с дополнительными функциональными возможностями. Добавив несколько строк кода, вы получаете возможность визуализировать метрики в студии и сравнивать метрики из нескольких заданий.
Изменение скрипта train.py для ведения журнала
Измените скрипт train.py, чтобы добавить еще две строки кода:
import torch import torch.optim as optim import torchvision import torchvision.transforms as transforms from model import Net from azureml.core import Run # ADDITIONAL CODE: get run from the current context run = Run.get_context() # download CIFAR 10 data trainset = torchvision.datasets.CIFAR10( root='./data', train=True, download=True, transform=torchvision.transforms.ToTensor() ) trainloader = torch.utils.data.DataLoader( trainset, batch_size=4, shuffle=True, num_workers=2 ) if __name__ == "__main__": # define convolutional network net = Net() # set up pytorch loss / optimizer criterion = torch.nn.CrossEntropyLoss() optimizer = optim.SGD(net.parameters(), lr=0.001, momentum=0.9) # train the network for epoch in range(2): running_loss = 0.0 for i, data in enumerate(trainloader, 0): # unpack the data inputs, labels = data # zero the parameter gradients optimizer.zero_grad() # forward + backward + optimize outputs = net(inputs) loss = criterion(outputs, labels) loss.backward() optimizer.step() # print statistics running_loss += loss.item() if i % 2000 == 1999: loss = running_loss / 2000 # ADDITIONAL CODE: log loss metric to AML run.log('loss', loss) print(f'epoch={epoch + 1}, batch={i + 1:5}: loss {loss:.2f}') running_loss = 0.0 print('Finished Training')Сохраните этот файл, а затем при необходимости закройте вкладку.
Сведения о дополнительных двух строках кода
В скрипте train.py вы обращаетесь к объекту run из самого скрипта обучения с помощью метода Run.get_context() и используете его для ведения журнала метрик:
# ADDITIONAL CODE: get run from the current context
run = Run.get_context()
...
# ADDITIONAL CODE: log loss metric to AML
run.log('loss', loss)
Метрики в Машинном обучении Azure:
- Организованы по экспериментам и выполняются так, чтобы можно было легко отследить и сравнить метрики.
- Оснащены пользовательским интерфейсом, что позволяет визуализировать эффективность обучения в студии.
- Предназначены для масштабирования, поэтому вы можете использовать эти преимущества даже при выполнении сотен экспериментов.
Обновление файла среды Conda
Сценарий train.py только что принял новую зависимость от azureml.core. Обновите pytorch-env.yml, чтобы отразить это изменение:
name: pytorch-env
channels:
- defaults
- pytorch
dependencies:
- python=3.7
- pytorch
- torchvision
- pip
- pip:
- azureml-sdk
Обязательно сохраните этот файл перед отправкой выполнения.
Отправка выполнения в Машинное обучение Azure
Выберите вкладку для скрипта run-pytorch.py, а затем нажмите кнопку "Сохранить и запустить скрипт" в терминале, чтобы повторно запустить скрипт run-pytorch.py. Сначала сохраните изменения pytorch-env.yml .
На этот раз при посещении студии перейдите на вкладку Метрики, на которой теперь можно увидеть обновления в реальном времени для потерь обучения модели. Обучение начнется через 1–2 минуты.
Очистка ресурсов
Если вы планируете перейти к другому руководству или начать собственные задания обучения, перейдите к связанным ресурсам.
Остановка вычислительного экземпляра
Если вы сейчас не планируете использовать вычислительный экземпляр, остановите его, выполнив следующие действия:
- В левой части окна студии выберите Вычисления.
- Из вкладок вверху выберите Вычислительные экземпляры.
- Выберите вычислительный экземпляр из списка.
- В верхней панели инструментов выберите Остановить.
Удаление всех ресурсов
Внимание
Созданные вами ресурсы могут использоваться в качестве необходимых компонентов при работе с другими руководствами по Машинному обучению Azure.
Если вы не планируете использовать созданные вами ресурсы, удалите их, чтобы с вас не взималась плата:
На портале Azure выберите Группы ресурсов в левой части окна.
Выберите созданную группу ресурсов из списка.
Выберите команду Удалить группу ресурсов.
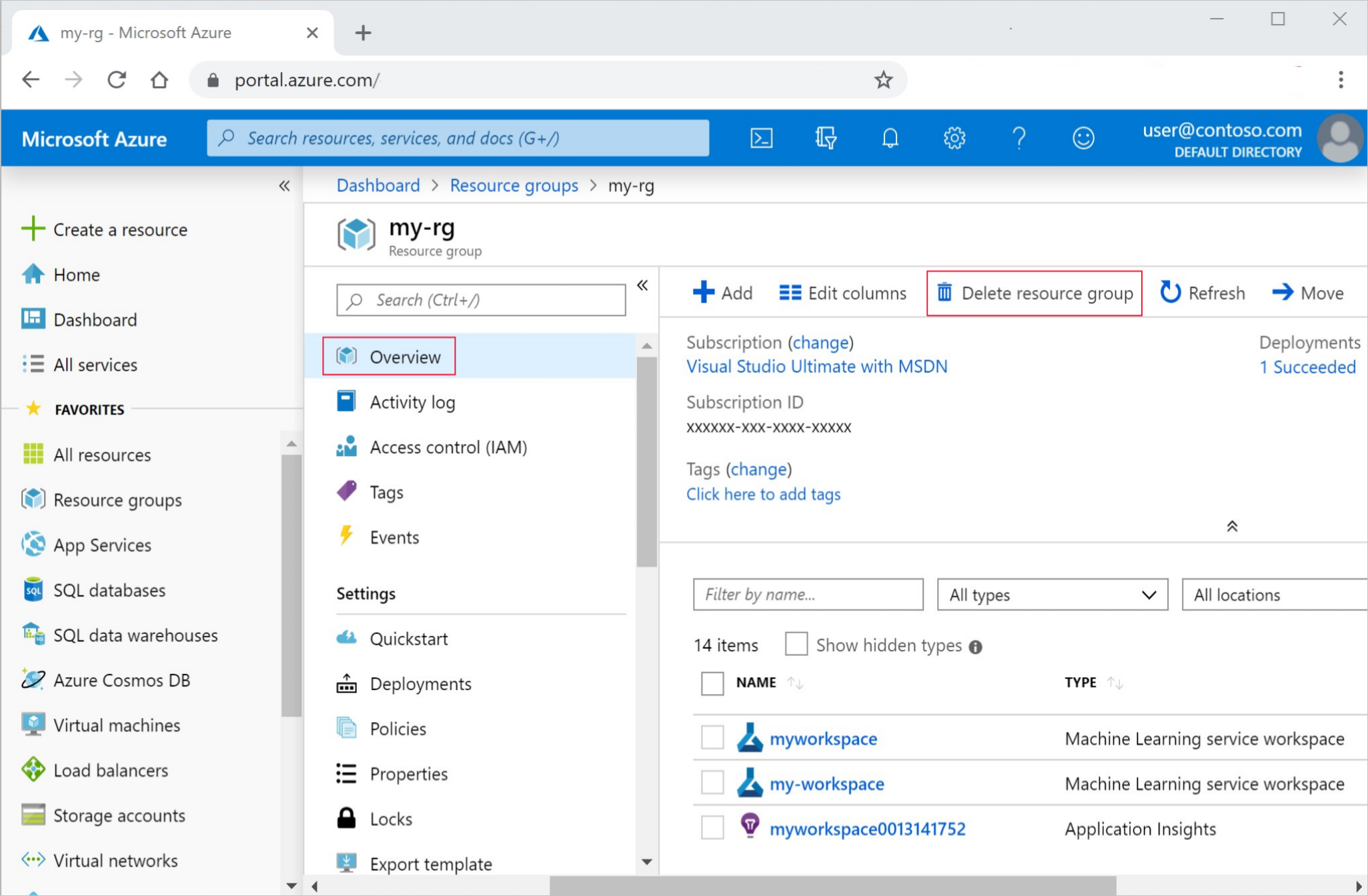
Введите имя группы ресурсов. Затем выберите Удалить.
Вы также можете сохранить группу ресурсов, но удалить одну рабочую область. Отобразите свойства рабочей области и нажмите кнопку Удалить.
Связанные ресурсы
В этом сеансе вы перешли с обычного скрипта "Hello world!" на более реалистичный сценарий обучения, который требует выполнения конкретной среды Python. Вы узнали, как использовать курированные среды Машинного обучения Azure. И наконец, вы узнали, как с помощью нескольких строк кода можно вести журнал метрик в Машинном обучении Azure.
Существуют и другие способы создания сред Машинного обучения Azure, в том числе из файла requirements.txt для pip или даже из имеющейся локальной среды Conda.