Создание и обучение пользовательской модели классификации
Это содержимое относится к:v4.0 (предварительная версия) | Предыдущие версии:![]()
![]() v3.1 (GA)
v3.1 (GA)![]() v3.0 (GA)
v3.0 (GA)
Внимание
Пользовательская модель классификации в настоящее время находится в общедоступной предварительной версии. Функции, подходы и процессы могут изменяться до общедоступной доступности на основе отзывов пользователей.
Пользовательские модели классификации могут классифицировать каждую страницу в входном файле, чтобы определить документы внутри. Модели классификатора также могут определять несколько документов или несколько экземпляров одного документа в входном файле. Для начала работы с пользовательскими моделями аналитики документов требуется всего пять обучающих документов для каждого класса документов. Чтобы приступить к обучению пользовательской модели классификации, вам потребуется по крайней мере пять документов для каждого класса и двух классов документов.
Требования к входным данным модели пользовательской классификации
Убедитесь, что набор обучающих данных соответствует требованиям к входным данным для аналитики документов.
Для получения наилучших результатов предоставьте одну четкую фотографию или скан-копию документа высокого качества.
Поддерживаемые форматы файлов:
Модель PDF Изображение:
JPEG/JPG, PNG, BMP, TIFF, HEIFMicrosoft Office:
Word (DOCX), Excel (XLSX), PowerPoint (PPTX) и HTMLЧитать ✔ ✔ ✔ Макет ✔ ✔ ✔ (2024-02-29-preview, 2023-10-31-preview) Документ общего назначения ✔ ✔ Готовое ✔ ✔ Настраиваемая функция извлечения ✔ ✔ Настраиваемая классификация ✔ ✔ ✔ (2024-02-29-preview) В файлах формата PDF и TIFF обрабатывается до 2000 страниц (с подпиской уровня "Бесплатный" обрабатываются только первые две страницы).
Размер файла для анализа документов составляет 500 МБ для платного уровня (S0) и 4 МБ бесплатного уровня (F0).
Изображения должны иметь размеры в пределах от 50 x 50 до 10 000 x 10 000 пикселей.
Если PDF-файлы заблокированы паролем, перед отправкой необходимо снять блокировку.
Минимальная высота извлекаемого текста составляет 12 пикселей для изображения размером 1024 x 768 пикселей. Это измерение соответствует тексту о
8точке в 150 точек на дюйм (DPI).Для обучения пользовательской модели максимальный объем обучающих данных составляет 500 страниц для пользовательской модели шаблона и 50 000 страниц для пользовательской нейронной модели.
Для обучения пользовательской модели извлечения общий размер обучающих данных составляет 50 МБ для модели шаблона и 1G-МБ для нейронной модели.
Для обучения пользовательской модели классификации общий размер обучающих данных составляет
1GBне более 10 000 страниц.
Советы касательно данных для обучения
Ниже приведены советы по дополнительной оптимизации набора данных для обучения:
По возможности используйте текстовый PDF-документ вместо документов на основе изображений. Отсканированные PDF-файлы обрабатываются как изображения.
Если ваши изображения формы имеют более низкое качество, используйте набор данных большего размера (например, 10–15 изображений).
Отправка данных для обучения
После объединения набора форм или документов для обучения необходимо отправить его в контейнер хранилища BLOB-объектов Azure. Если вы не знаете, как создать учетную запись хранения Azure с контейнером, обратитесь к краткому руководству по работе со службой хранилища Azure на портале Azure. Используйте бесплатную ценовую категорию (F0), чтобы опробовать службу, а затем выполните обновление до платного уровня для рабочей среды. Если набор данных упорядочен как папки, сохраните такую структуру, так как Студия может использовать имена папок для меток, чтобы упростить процесс маркировки.
Создание проекта классификации в Студии аналитики документов
Document Intelligence Studio предоставляет и оркестрирует все вызовы API, необходимые для завершения набора данных и обучения модели.
Начните с перехода к Студии аналитики документов. При первом использовании Студии необходимо инициализировать подписку, группу ресурсов и ресурс. Затем следуйте предварительным требованиям для пользовательских проектов , чтобы настроить Студию для доступа к набору данных для обучения.
В Студии выберите плитку "Пользовательская модель классификации" в разделе пользовательских моделей страницы и нажмите кнопку "Создать проект ".

В диалоговом окне "Создание проекта" укажите имя проекта, при необходимости введите его описание и нажмите кнопку "Продолжить".
Затем выберите или создайте ресурс аналитики документов перед тем, как продолжить.
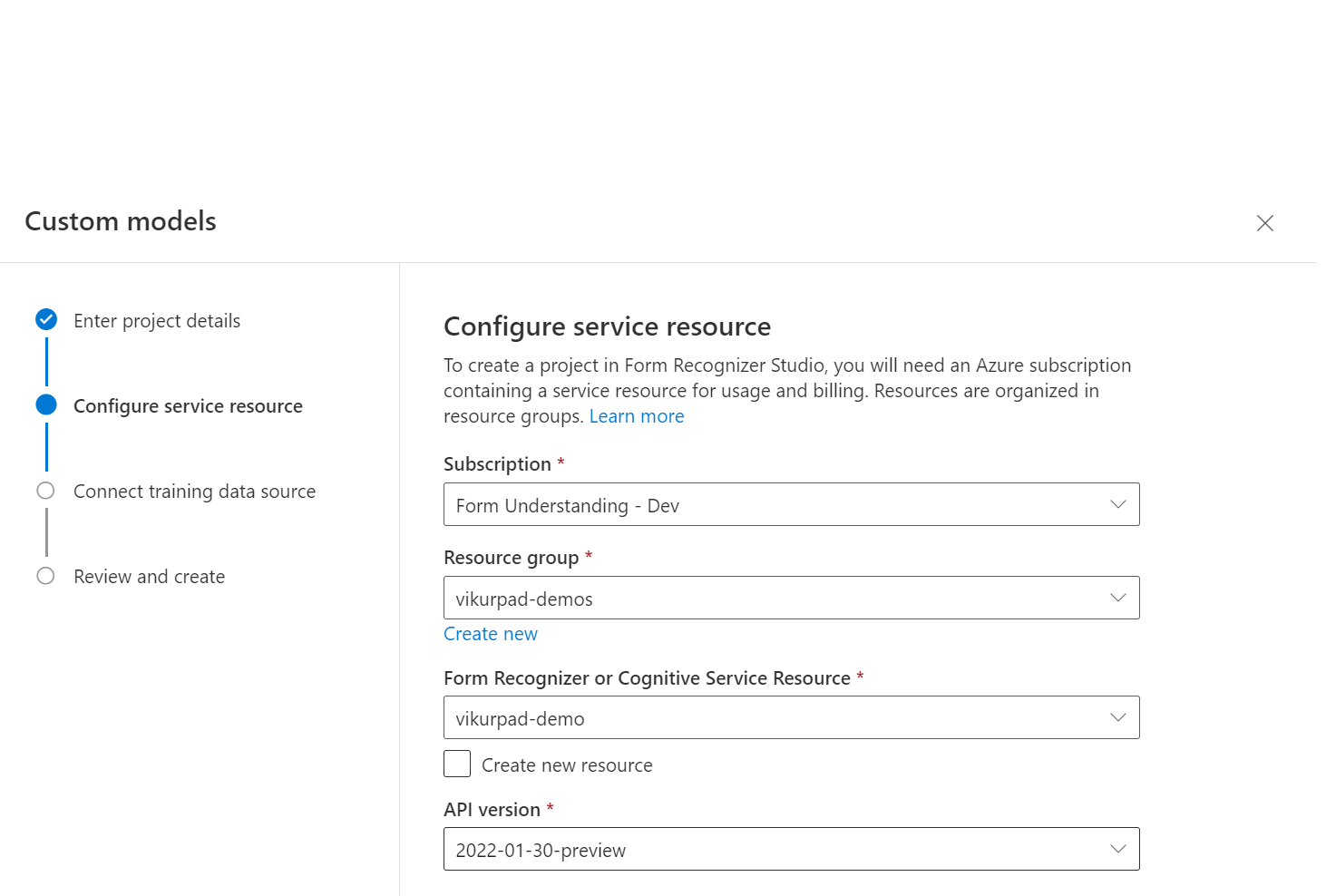
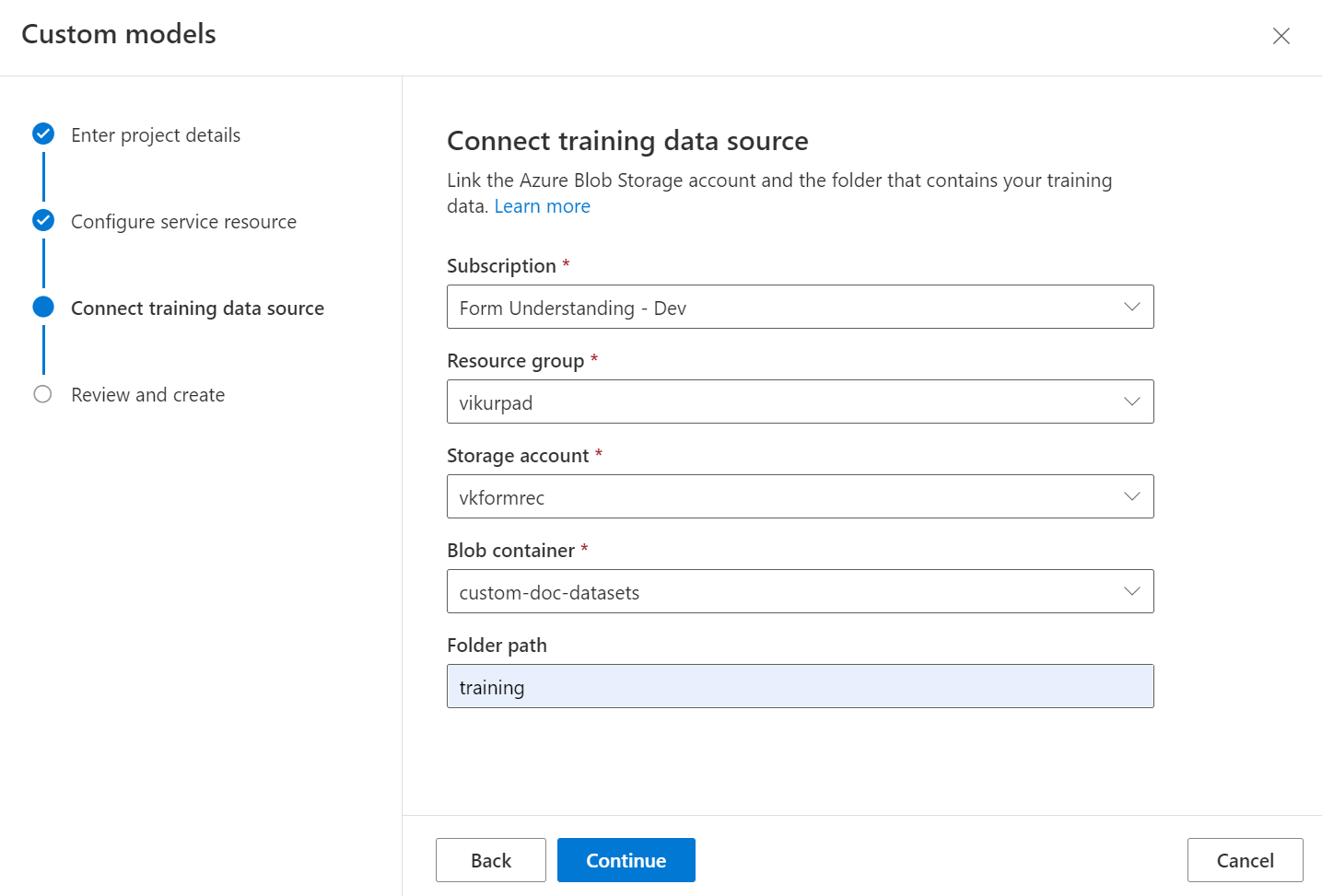
Затем выберите учетную запись хранения, используемую для отправки набора данных обучения пользовательской модели. Если документы для обучения находятся в корне контейнера, поле Путь к папке необходимо оставить пустым. Если документы находятся во вложенной папке, введите в поле Путь к папке относительный путь из корня контейнера. После настройки учетной записи хранения нажмите кнопку "Продолжить".
Внимание
Набор данных обучения можно упорядочить по папкам, в которых имя папки — метка или класс для документов, или создать неструктурированный список документов, которыми можно назначить метку в Студии.
Для обучения пользовательского классификатора требуются выходные данные модели макета для каждого документа в наборе данных. Запустите макет для всех документов до процесса обучения модели.
Наконец, проверьте параметры проекта и выберите Создать проект, чтобы создать новый проект. Далее должно открыться окно добавления меток, где можно просмотреть список файлов в наборе данных.
Добавление меток к данным
В проекте необходимо только пометить каждый документ с соответствующей меткой класса.

Вы увидите файлы, отправленные в хранилище в списке файлов, готовых к добавлению метки. У вас есть несколько вариантов метки набора данных.
Если документы упорядочены в папках, студия предложит использовать имена папок в качестве меток. Этот шаг упрощает добавление меток к одному выбору.
Чтобы назначить метку документу, выберите метку выбора метки добавления, чтобы назначить метку.
Элемент управления для назначения метки с несколькими выборами документов
Теперь в наборе данных должны быть помечены все документы. При просмотре учетной записи хранения вы найдете .ocr.json файлы, соответствующие каждому документу в наборе данных обучения, и новый файл class-name.jsonl для каждого класса с метками. Этот набор данных обучения отправляется для обучения модели.
Обучение модели
После добавления меток для набора данных можно приступать к обучению модели. Нажмите кнопку "Обучить" в правом верхнем углу экрана.
В диалоговом окне обучения модели укажите уникальный идентификатор классификатора и, при необходимости, описание. Идентификатор классификатора принимает строковый тип данных.
Выберите Обучить, чтобы запустить процесс обучения.
Модели классификатора обучают несколько минут.
Состояние процесса обучения можно просмотреть в меню Модели.
Тестирование модели
После завершения обучения можно протестировать модель, выбрав ее на странице со списком моделей.
Выберите модель и нажмите кнопку Тест.
Добавьте новый файл, просматривая файл или убирая файл в селектор документов.
После выбора файла нажмите кнопку Анализ, чтобы проверить модель.
Результаты модели отображаются со списком идентифицированных документов, оценкой достоверности для каждого документа, определяемого и диапазоном страниц для каждого из документов, определенных.
Проверьте модель, оценив результаты для каждого документа, определенного.
Обучение пользовательского классификатора с помощью пакета SDK или API
Студия управляет вызовами API для обучения пользовательского классификатора. Набор данных для обучения классификатора требует выходных данных из API макета, который соответствует версии API для модели обучения. Использование результатов макета из более старой версии API может привести к снижению точности модели.
Студия создает результаты макета для обучаемого набора данных, если набор данных не содержит результатов макета. При использовании API или пакета SDK для обучения классификатора необходимо добавить результаты макета в папки, содержащие отдельные документы. Результаты макета должны быть в формате ответа API при вызове макета напрямую. Объектная модель ПАКЕТА SDK отличается, убедитесь, что layout results результаты API и не являются SDK response.
Устранение неполадок
Модель классификации требует результатов из модели макета для каждого учебного документа. Если вы не предоставляете результаты макета, студия пытается запустить модель макета для каждого документа перед обучением классификатора. Этот процесс регулируется и может привести к ответу 429.
Перед обучением с помощью модели классификации запустите модель макета в каждом документе и отправьте его в то же расположение, что и исходный документ. После добавления результатов макета можно обучить модель классификатора своими документами.