Рекомендации по реагированию на инциденты безопасности
Применяется к рекомендации по контрольным спискам безопасности Azure Well-Architected Framework:
| SE:12 | Определите и протестируйте эффективные процедуры реагирования на инциденты, охватывающие широкий спектр инцидентов, от локализованных проблем до аварийного восстановления. Четко определите, какая команда или отдельный пользователь выполняет процедуру. |
|---|
В этом руководстве описываются рекомендации по реализации реагирования на инциденты безопасности для рабочей нагрузки. Если система нарушает безопасность, систематический подход к реагированию на инциденты помогает сократить время, необходимое для выявления, управления и устранения инцидентов безопасности. Эти инциденты могут угрожать конфиденциальности, целостности и доступности программных систем и данных.
Большинство предприятий имеют центральную группу операций по обеспечению безопасности (также известную как Центр операций безопасности (SOC) или SecOps). Команда по обеспечению безопасности отвечает за быстрое обнаружение, определение приоритетов и рассмотрение потенциальных атак. Команда также отслеживает данные телеметрии, связанные с безопасностью, и исследует нарушения безопасности.
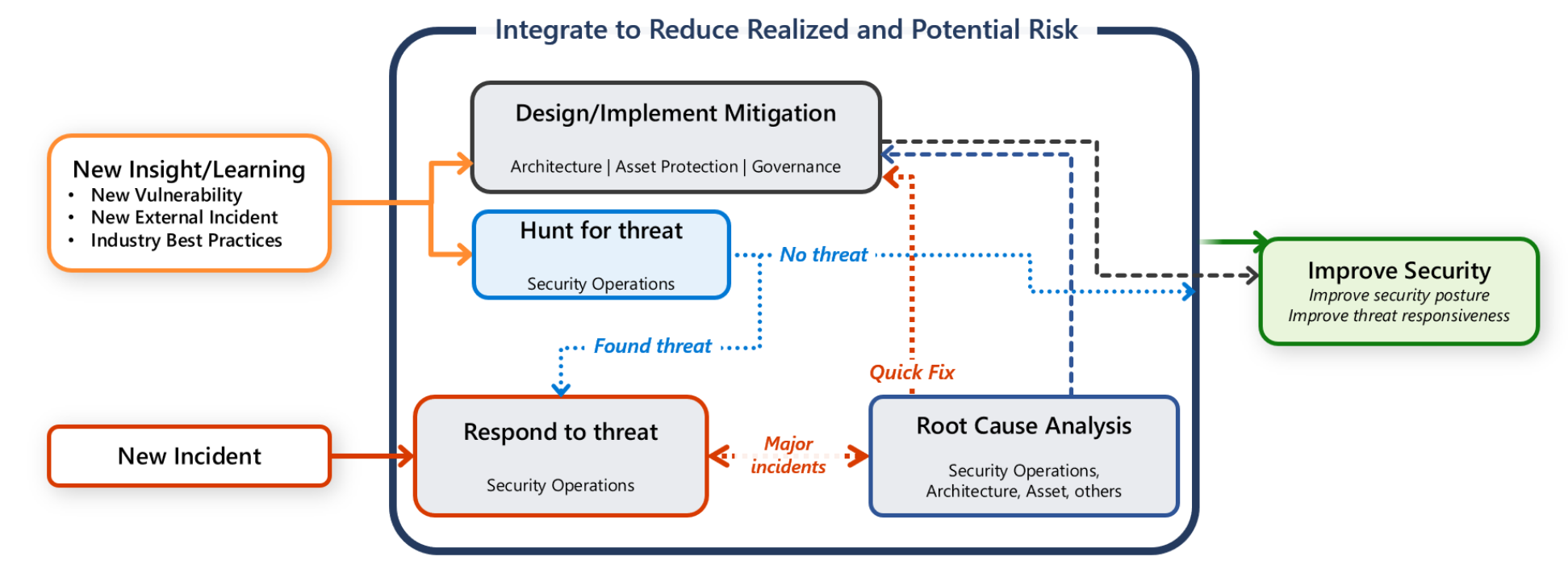
Однако вы также несете ответственность за защиту рабочей нагрузки. Важно, чтобы любые действия по обмену данными, исследованиями и охотой были совместными усилиями между командой рабочей нагрузки и командой SecOps.
В этом руководстве содержатся рекомендации для вас и команды рабочей нагрузки, которые помогут вам быстро обнаруживать, рассматривать и исследовать атаки.
Определения
| Термин | Определение |
|---|---|
| Предупреждение | Уведомление, содержащее сведения об инциденте. |
| Точность оповещений | Точность данных, определяющих оповещение. Оповещения с высоким уровнем точности содержат контекст безопасности, необходимый для принятия незамедлительных действий. Оповещения о низкой точности не содержат информации или содержат шум. |
| Ложный положительный результат | Оповещение, указывающее на инцидент, который не произошел. |
| Инцидент | Событие, указывающее на несанкционированный доступ к системе. |
| Реагирование на инциденты | Процесс, который обнаруживает риски, связанные с инцидентом, реагирует на них и снижает их. |
| Рассмотрение | Операция реагирования на инциденты, которая анализирует проблемы безопасности и определяет приоритеты их устранения. |
Ключевые стратегии проектирования
Вы и ваша команда выполняете операции реагирования на инциденты, когда есть сигнал или оповещение о потенциальной компрометации. Оповещения с высоким уровнем точности содержат достаточно контекста безопасности, который упрощает для аналитиков принятие решений. Оповещения с высокой точностью приводят к низкому количеству ложноположительных результатов. В этом руководстве предполагается, что система оповещений фильтрует сигналы с низкой точностью и фокусируется на оповещениях с высокой точностью, которые могут указывать на реальный инцидент.
Назначение уведомления об инциденте
Оповещения системы безопасности должны охватывать соответствующих сотрудников вашей команды и организации. Создайте назначенную контактную точку в группе рабочей нагрузки, чтобы получать уведомления об инцидентах. Эти уведомления должны содержать как можно больше сведений о скомпрометированном ресурсе и системе. Оповещение должно включать в себя следующие шаги, чтобы ваша команда ела ускорить действия.
Рекомендуется регистрирование уведомлений об инцидентах и действий и управление ими с помощью специализированных средств, которые сохраняют журнал аудита. С помощью стандартных средств можно сохранить доказательства, которые могут потребоваться для потенциальных юридических расследований. Ищите возможности для реализации автоматизации, которая может отправлять уведомления на основе обязанностей подотчетных сторон. Следите за четкой цепочкой общения и отчетности во время инцидента.
Воспользуйтесь преимуществами решений для управления информационными событиями безопасности (SIEM) и решений soar, которые предоставляет ваша организация. Кроме того, вы можете приобрести средства управления инцидентами и побудить свою организацию стандартизировать их для всех команд рабочей нагрузки.
Исследование с помощью команды рассмотрения
Участник группы, получающий уведомление об инциденте, отвечает за настройку процесса рассмотрения, включающего соответствующих людей на основе доступных данных. Команда рассмотрения, которую часто называют мостовой командой, должна договориться о режиме и процессе общения. Требуется ли для этого инцидента асинхронное обсуждение или мостовые вызовы? Как команда должна отслеживать ход расследования и сообщать о ней? Где команда может получить доступ к ресурсам инцидентов?
Реагирование на инциденты является важной причиной для поддержания актуальности документации, например архитектурного макета системы, информации на уровне компонентов, конфиденциальности или классификации безопасности, владельцев и ключевых точек контакта. Если информация неточна или устарела, команда моста тратит ценное время, пытаясь понять, как работает система, кто несет ответственность за каждую область и каковы последствия этого события.
Для дальнейшего расследования привлеките соответствующих людей. Вы можете включить руководителя инцидентов, сотрудника по безопасности или потенциальных клиентов, ориентированных на рабочую нагрузку. Чтобы сохранить фокус на рассмотрении, исключите людей, которые находятся вне область проблемы. Иногда отдельные команды расследуют инцидент. Может существовать группа, которая сначала изучает проблему и пытается устранить инцидент, и другая специализированная группа, которая может выполнять судебно-медицинскую экспертизу для глубокого расследования для выявления широких проблем. Вы можете поместить среду рабочей нагрузки в карантин, чтобы группа экспертов могла проводить расследования. В некоторых случаях все исследование может выполняться одной и той же командой.
На начальном этапе группа рассмотрения отвечает за определение потенциального вектора и его влияния на конфиденциальность, целостность и доступность (также называется ЦРУ) системы.
В категориях ЦРУ назначьте начальный уровень серьезности, который указывает на глубину ущерба и срочность исправления. Ожидается, что этот уровень будет меняться со временем по мере обнаружения дополнительных сведений в уровнях рассмотрения.
На этапе обнаружения важно определить немедленный курс действий и планы общения. Были ли изменения в состоянии работы системы? Как сдержать атаку, чтобы остановить дальнейшее использование? Нужно ли команде отправлять внутренние или внешние сообщения, например ответственное раскрытие информации? Рассмотрите возможность обнаружения и времени отклика. Вы можете быть юридически обязаны сообщать о некоторых типах нарушений в регулирующий орган в течение определенного периода времени, который часто составляет часы или дни.
Если вы решите завершить работу системы, следующие шаги приведут к процессу аварийного восстановления (DR) рабочей нагрузки.
Если вы не завершите работу системы, определите, как устранить инцидент, не влияя на функциональность системы.
Восстановление после инцидента
Относиться к инциденту безопасности как к катастрофе. Если исправление требует полного восстановления, используйте соответствующие механизмы аварийного восстановления с точки зрения безопасности. Процесс восстановления должен предотвращать вероятность повторения. В противном случае восстановление из поврежденной резервной копии снова создает проблему. Повторное развертывание системы с той же уязвимостью приводит к тому же инциденту. Проверка шагов и процессов отработки отказа и восстановления размещения.
Если система продолжает функционировать, оцените влияние на работающие части системы. Продолжайте следить за системой, чтобы обеспечить достижение других целевых показателей надежности и производительности путем реализации соответствующих процессов снижения производительности. Не нарушайте конфиденциальность из-за устранения рисков.
Диагностика — это интерактивный процесс, пока не будет определен вектор, а также возможные исправления и отката. После диагностики команда работает над исправлением, которое определяет и применяет необходимое исправление в течение приемлемого периода.
Метрики восстановления измеряют время, необходимое для устранения проблемы. В случае завершения работы может возникнуть необходимость в срочном выполнении исправлений. Чтобы стабилизировать систему, требуется время для применения исправлений, исправлений и тестов, а также для развертывания обновлений. Определите стратегии сдерживания для предотвращения дальнейшего ущерба и распространения инцидента. Разработать процедуры ликвидации, чтобы полностью исключить угрозу из окружающей среды.
Компромисс. Существует компромисс между целевыми показателями надежности и временем исправления. Во время инцидента, скорее всего, вы не соответствуете другим нефункциональным или функциональным требованиям. Например, может потребоваться отключить части системы во время расследования инцидента или даже перевести всю систему в автономный режим, пока вы не определите область инцидента. Лица, принимающие бизнес-решения, должны явно решить, какие приемлемые цели являются во время инцидента. Четко укажите лицо, которое будет отвечать за это решение.
Учиться на инциденте
Инцидент выявляет пробелы или уязвимые точки в проектировании или реализации. Это возможность улучшения, которая обусловлена уроками в области технических аспектов проектирования, автоматизации, процессов разработки продуктов, которые включают тестирование, и эффективности процесса реагирования на инциденты. Ведение подробных записей инцидентов, включая предпринятые действия, сроки и результаты.
Мы настоятельно рекомендуем провести структурированные проверки после инцидента, такие как анализ первопричин и ретроспективы. Отслеживайте и приоритизация результатов этих проверок, а также рассмотрите возможность использования того, что вы узнаете в будущих проектах рабочих нагрузок.
Планы улучшения должны включать обновления для отработок и тестирования безопасности, таких как непрерывность бизнес-процессов и аварийное восстановление (BCDR). Используйте компрометацию безопасности в качестве сценария для выполнения отработки BCDR. С помощью отработки можно проверить, как работают задокументированные процессы. Не должно быть нескольких сборников схем реагирования на инциденты. Используйте один источник, который можно настроить в зависимости от размера инцидента и того, насколько широко распространен или локализован эффект. Упражнения основаны на гипотетических ситуациях. Проводите отработки в среде с низким риском и включите этап обучения в отработку.
Проведите обзоры после инцидентов или посмертные проверки для выявления слабых мест в процессе реагирования и областей для улучшения. На основе уроков, извлеченных из инцидента, обновите план реагирования на инциденты (IRP) и элементы управления безопасностью.
Отправка необходимого сообщения
Реализуйте план коммуникации, чтобы уведомить пользователей о сбоях и информировать внутренних заинтересованных лиц об исправлении и улучшениях. Другие люди в вашей организации должны быть уведомлены о любых изменениях в базовых показателях безопасности рабочей нагрузки, чтобы предотвратить инциденты в будущем.
Создавайте отчеты об инцидентах для внутреннего использования и, при необходимости, для соблюдения нормативных требований или юридических целей. Кроме того, следует принять отчет в стандартном формате (шаблон документа с определенными разделами), который команда SOC использует для всех инцидентов. Перед завершением расследования убедитесь, что с каждым инцидентом связан отчет.
Упрощение поддержки Azure
Microsoft Sentinel — это решение SIEM и SOAR. Это единое решение для обнаружения оповещений, отображения угроз, упреждающей охоты и реагирования на угрозы. Дополнительные сведения см. в статье Что такое Microsoft Sentinel?
Убедитесь, что портал регистрации Azure содержит контактные данные администратора, чтобы можно было получать уведомления об операциях безопасности напрямую через внутренний процесс. Дополнительные сведения см. в разделе Обновление параметров уведомлений.
Дополнительные сведения о создании назначенной точки контакта, которая получает уведомления об инцидентах Azure от Microsoft Defender для облака, см. в статье Настройка Уведомления по электронной почте для оповещений системы безопасности.
Соответствие структуре организации
Cloud Adoption Framework для Azure предоставляет рекомендации по планированию реагирования на инциденты и операциям безопасности. Дополнительные сведения см. в разделе Операции безопасности.
Связанные ссылки
- Автоматически создавайте инциденты на основе оповещений системы безопасности Майкрософт
- Выполнение комплексной охоты на угрозы с помощью функции охоты
- Настройка отправляемых по электронной почте уведомлений для оповещений системы безопасности
- Обзор реагирования на инциденты
- Готовность к инцидентам Microsoft Azure
- Навигация и исследование инцидентов в Microsoft Sentinel
- Управление безопасностью: реагирование на инциденты
- Решения SOAR в Microsoft Sentinel
- Учебный курс. Общие сведения о готовности к инцидентам в Azure
- Обновление параметров уведомлений портал Azure
- Что такое SOC?
- Что такое Microsoft Sentinel?
Контрольный список по безопасности
См. полный набор рекомендаций.
Обратная связь
Ожидается в ближайшее время: в течение 2024 года мы постепенно откажемся от GitHub Issues как механизма обратной связи для контента и заменим его новой системой обратной связи. Дополнительные сведения см. в разделе https://aka.ms/ContentUserFeedback.
Отправить и просмотреть отзыв по