Рекомендации по проектированию приложений для критически важных рабочих нагрузок
Базовая эталонная архитектура для критически важных задач иллюстрирует высоконадежную рабочую нагрузку с помощью простого приложения сетевого каталога. Пользователи могут просматривать каталог элементов, просматривать сведения об элементе, публиковать оценки и комментарии к элементам. В этой статье рассматриваются аспекты надежности и устойчивости критически важных приложений, такие как асинхронная обработка запросов и способы достижения высокой пропускной способности в решении.
Важно!
 Руководство подкреплено эталонной реализацией производственного уровня, которая демонстрирует критически важные разработки приложений в Azure. Эту реализацию можно использовать в качестве основы для дальнейшей разработки решения на первом шаге к рабочей среде.
Руководство подкреплено эталонной реализацией производственного уровня, которая демонстрирует критически важные разработки приложений в Azure. Эту реализацию можно использовать в качестве основы для дальнейшей разработки решения на первом шаге к рабочей среде.
Структура приложения
Для крупномасштабных критически важных приложений важно оптимизировать архитектуру для обеспечения комплексной масштабируемости и устойчивости. Этого состояния можно достичь путем разделения компонентов на функциональные единицы, которые могут работать независимо друг от друга. Используйте это разделение на всех уровнях стека приложений, что позволит каждой части системы масштабироваться независимо и соответствовать изменениям спроса.
Пример такого подхода показан в реализации . Приложение использует конечные точки API без отслеживания состояния, которые асинхронно отделяют длительные запросы на запись через брокер обмена сообщениями. Рабочая нагрузка состоит таким образом, что весь кластер AKS и другие зависимости в метке можно удалить и повторно создать в любое время. Ниже перечислены основные компоненты.
- Пользовательский интерфейс: одностраничное веб-приложение, к которым обращаются конечные пользователи, размещается на статичном веб-сайте учетной записи хранения Azure.
- API (
CatalogService): REST API, вызываемый приложением пользовательского интерфейса, но доступный для других потенциальных клиентских приложений. - Рабочая роль (
BackgroundProcessor): фоновая рабочая роль, которая обрабатывает запросы на запись в базу данных путем прослушивания новых событий в шине сообщений. Этот компонент не предоставляет интерфейсы API. - API службы работоспособности (
HealthService): используется для создания отчетов о работоспособности приложения путем проверки работоспособности критически важных компонентов (базы данных, шины обмена сообщениями).

Api, рабочая роль и проверка работоспособности приложений называются рабочей нагрузкой и размещаются как контейнеры в выделенном пространстве имен AKS (называется workload). Прямой обмен данными между модулями pod отсутствует. Модули pod не имеют состояния и могут масштабироваться независимо друг от друга.
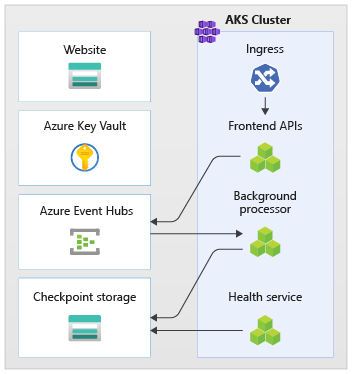
В кластере выполняются другие вспомогательные компоненты:
- Контроллер входящего трафика. Контроллер входящего трафика Nginx используется для маршрутизации входящих запросов к рабочей нагрузке и балансировки нагрузки между модулями pod. Он предоставляется через Azure Load Balancer с общедоступным IP-адресом (но доступ осуществляется только через Azure Front Door).
- Диспетчер сертификатов. Jetstack
cert-managerиспользуется для автоматической подготовки SSL/TLS-сертификатов (с помощью Let's Encrypt) для правил входящего трафика. - Драйвер секретов CSI. Поставщик azure Key Vault для хранилища секретов CSI используется для безопасного чтения секретов, таких как строки подключения из azure Key Vault.
- Агент мониторинга. Конфигурация OMSAgent по умолчанию корректируется, чтобы уменьшить объем данных мониторинга, отправляемых в рабочую область Log Analytics.
Подключение к базе данных
Из-за эфемерного характера меток развертывания избегайте сохранения состояния в метках, насколько это возможно. Состояние должно сохраняться в внешнем хранилище данных. Для поддержки SLO надежности это хранилище данных должно быть устойчивым. Рекомендуется использовать управляемые службы (PaaS) в сочетании с собственными библиотеками SDK, которые автоматически обрабатывают время ожидания, отключения и другие состояния сбоев.
В эталонной реализации Azure Cosmos DB выступает в качестве main хранилища данных для приложения. Azure Cosmos DB была выбрана, так как она обеспечивает операции записи в нескольких регионах. Каждая метка может выполнять запись в реплика Azure Cosmos DB в том же регионе, где Azure Cosmos DB обрабатывает репликацию данных и синхронизацию между регионами. Azure Cosmos DB для NoSQL используется, так как поддерживает все возможности ядра СУБД.
Дополнительные сведения см. в статье Платформа данных для критически важных рабочих нагрузок.
Примечание
Новые приложения должны использовать Azure Cosmos DB для NoSQL. Для устаревших приложений, использующих другой протокол NoSQL, оцените путь миграции в Azure Cosmos DB.
Совет
Для критически важных приложений, для которых доступность имеет приоритет над производительностью, рекомендуется выполнять запись в одном регионе и чтение в нескольких регионах с уровнем строгой согласованности .
В этой архитектуре необходимо временно сохранить состояние в метке для контрольных точек Центров событий. Для этой цели используется служба хранилища Azure.
Все компоненты рабочей нагрузки используют пакет SDK .NET Core для Azure Cosmos DB для взаимодействия с базой данных. Пакет SDK включает надежную логику для поддержки подключения к базе данных и обработки сбоев. Ниже приведены некоторые ключевые параметры конфигурации.
- Использует режим прямого подключения. Это параметр по умолчанию для пакета SDK для .NET версии 3, так как он обеспечивает более высокую производительность. Число сетевых прыжков меньше по сравнению с режимом шлюза, в котором используется ПРОТОКОЛ HTTP.
- Возврат ответа содержимого при записи отключен, чтобы предотвратить возврат документа клиентом Azure Cosmos DB из операций Create, Upsert, Patch и Replace для сокращения сетевого трафика. Кроме того, это не требуется для дальнейшей обработки на клиенте.
- Настраиваемая сериализация используется для задания политики именования свойств JSON для
JsonNamingPolicy.CamelCaseпреобразования . Свойства в стиле NET для стандартного стиля JSON и наоборот. Условие пропуска по умолчанию игнорирует свойства со значениями NULL во время сериализации (JsonIgnoreCondition.WhenWritingNull). - Регион приложения — это регион метки, что позволяет пакету SDK найти ближайшую конечную точку подключения (желательно в том же регионе).
//
// /src/app/AlwaysOn.Shared/Services/CosmosDbService.cs
//
CosmosClientBuilder clientBuilder = new CosmosClientBuilder(sysConfig.CosmosEndpointUri, sysConfig.CosmosApiKey)
.WithConnectionModeDirect()
.WithContentResponseOnWrite(false)
.WithRequestTimeout(TimeSpan.FromSeconds(sysConfig.ComsosRequestTimeoutSeconds))
.WithThrottlingRetryOptions(TimeSpan.FromSeconds(sysConfig.ComsosRetryWaitSeconds), sysConfig.ComsosMaxRetryCount)
.WithCustomSerializer(new CosmosNetSerializer(Globals.JsonSerializerOptions));
if (sysConfig.AzureRegion != "unknown")
{
clientBuilder = clientBuilder.WithApplicationRegion(sysConfig.AzureRegion);
}
_dbClient = clientBuilder.Build();
Асинхронный обмен сообщениями
Слабая связь позволяет разрабатывать службы таким образом, чтобы служба не зависела от других служб. Свободный аспект позволяет службе работать независимо. Аспект взаимозависимости позволяет взаимодействовать между службами через четко определенные интерфейсы. В контексте критически важных приложений оно обеспечивает высокий уровень доступности, предотвращая каскадное переключение подчиненных сбоев на внешние интерфейсы или различные метки развертывания.
Основные характеристики:
- Службы не ограничены использованием одной и той же вычислительной платформы, языка программирования или операционной системы.
- Службы масштабироваться независимо.
- Подчиненные сбои не влияют на клиентские транзакции.
- Целостность транзакций сложнее поддерживать, так как создание и сохранение данных происходит в отдельных службах. Это также проблема в службах обмена сообщениями и сохраняемости, как описано в этом руководстве по обработке идемпотентных сообщений.
- Для комплексной трассировки требуется более сложная оркестрация.
Настоятельно рекомендуется использовать хорошо известные конструктивные шаблоны, такие как шаблон выравнивания нагрузки на основе очередей и шаблон конкурирующих потребителей. Эти шаблоны помогают в распределении нагрузки от производителя к потребителям и асинхронной обработке потребителями. Например, рабочая роль позволяет API принять запрос и быстро вернуться вызывающей объекту при отдельной обработке операции записи базы данных.
Центры событий Azure используется в качестве брокера сообщений между API и рабочей ролью.
Важно!
Брокер сообщений не предназначен для использования в качестве постоянного хранилища данных в течение длительных периодов времени. Служба Центров событий поддерживает функцию записи , которая позволяет концентратору событий автоматически записывать копии сообщений в связанную учетную запись хранения Azure. Это сохраняет использование в проверка но также служит механизмом резервного копирования сообщений.
Сведения о реализации операций записи
Операции записи, такие как post rating и post comment , обрабатываются асинхронно. API сначала отправляет в очередь сообщений сообщение со всеми соответствующими сведениями, такими как тип действия и данные примечаний, и немедленно возвращается HTTP 202 (Accepted) с дополнительным Location заголовком создаваемого объекта.
Сообщения в очереди затем обрабатываются экземплярами, которые обрабатывают фактическое взаимодействие с базой BackgroundProcessor данных для операций записи. BackgroundProcessor выполняет динамическое масштабирование в зависимости от объема сообщений в очереди. Ограничение горизонтального увеличения масштаба экземпляров процессора определяется максимальным числом секций Центров событий (32 для уровней Базовый и Стандартный, 100 для уровня "Премиум" и 1024 для уровня "Выделенный").

Библиотека обработчика Azure EventHub в BackgroundProcessor использует Хранилище BLOB-объектов Azure для управления владением секциями, балансировки нагрузки между различными экземплярами рабочих ролей и отслеживания хода выполнения с помощью контрольных точек. Запись контрольных точек в хранилище BLOB-объектов происходит не после каждого события , так как это приведет к чрезмерно дорогостоящей задержке для каждого сообщения. Вместо этого запись контрольной точки выполняется в цикле таймера (настраиваемая длительность с текущим параметром 10 секунд):
while (!stoppingToken.IsCancellationRequested)
{
await Task.Delay(TimeSpan.FromSeconds(_sysConfig.BackendCheckpointLoopSeconds), stoppingToken);
if (!stoppingToken.IsCancellationRequested && !checkpointEvents.IsEmpty)
{
string lastPartition = null;
try
{
foreach (var partition in checkpointEvents.Keys)
{
lastPartition = partition;
if (checkpointEvents.TryRemove(partition, out ProcessEventArgs lastProcessEventArgs))
{
if (lastProcessEventArgs.HasEvent)
{
_logger.LogDebug("Scheduled checkpointing for partition {partition}. Offset={offset}", partition, lastProcessEventArgs.Data.Offset);
await lastProcessEventArgs.UpdateCheckpointAsync();
}
}
}
}
catch (Exception e)
{
_logger.LogError(e, "Exception during checkpointing loop for partition={lastPartition}", lastPartition);
}
}
}
Если приложение процессора обнаруживает ошибку или останавливается перед обработкой сообщения, сделайте следующее:
- Другой экземпляр получит сообщение для повторной обработки, так как он не был должным образом контрольными точками в хранилище.
- Если предыдущей рабочей роли удалось сохранить документ в базе данных до сбоя, произойдет конфликт (так как используется тот же идентификатор и ключ секции), и обработчик может спокойно игнорировать сообщение, так как оно уже сохранено.
- Если предыдущая рабочая роль была завершена перед записью в базу данных, новый экземпляр повторит шаги и завершит сохранение.
Сведения о реализации операций чтения
Операции чтения обрабатываются непосредственно API и немедленно возвращают данные пользователю.

Обратный канал, который обменивается данными с клиентом в случае успешного завершения операции, отсутствует. Клиентское приложение должен заранее опрашивать API на наличие обновлений элемента, указанного в заголовке Location HTTP.
Масштабируемость
Отдельные компоненты рабочей нагрузки должны масштабироваться независимо, так как каждый из них имеет разные шаблоны нагрузки. Требования к масштабированию зависят от функциональных возможностей службы. Некоторые службы оказывают непосредственное влияние на конечных пользователей и, как ожидается, смогут активно масштабироваться, чтобы обеспечить быстрый отклик для положительного взаимодействия с пользователем и производительности в любое время.
В реализации службы упаковываются как контейнеры Docker и развертываются с помощью диаграмм Helm для каждой метки. Для них настроены ожидаемые запросы и ограничения Kubernetes, а также предварительно настроенное правило автоматического масштабирования. Компонент CatalogService рабочей нагрузки BackgroundProcessor и может масштабироваться по отдельности, обе службы не имеют отслеживания состояния.
Конечные пользователи взаимодействуют напрямую с CatalogService, поэтому эта часть рабочей нагрузки должна отвечать под любой нагрузкой. В каждом кластере есть по крайней мере 3 экземпляра, распределенных по трем Зоны доступности в регионе Azure. Средство горизонтального автомасштабирования pod AKS (HPA) при необходимости автоматически добавляет дополнительные модули pod, а автоматическое масштабирование Azure Cosmos DB позволяет динамически увеличивать и уменьшать количество единиц запросов, доступных для коллекции. CatalogService Вместе и Azure Cosmos DB образуют единицу масштабирования в метку.
HPA развертывается с помощью диаграммы Helm с настраиваемым максимальным и минимальным количеством реплик. Значения настраиваются следующим образом:
Во время нагрузочного теста было установлено, что каждый экземпляр должен обрабатывать около 250 запросов в секунду со стандартным шаблоном использования.
Служба BackgroundProcessor имеет совершенно разные требования и считается фоновой рабочей ролью, которая оказывает ограниченное влияние на взаимодействие с пользователем. Таким образом, имеет конфигурацию CatalogService автоматического масштабирования, BackgroundProcessor отличную от конфигурации, и она может масштабироваться от 2 до 32 экземпляров (это ограничение должно основываться на количестве секций, используемых в Центрах событий. Больше рабочих ролей больше, чем секций).
| Компонент | minReplicas |
maxReplicas |
|---|---|---|
| CatalogService | 3 | 20 |
| BackgroundProcessor | 2 | 32 |
Кроме того, в каждом компоненте рабочей нагрузки, включая такие ingress-nginx зависимости, настроены бюджеты прерывания pod (PDB ), гарантирующие, что при выпуске изменений в кластерах всегда доступно минимальное количество экземпляров.
#
# /src/app/charts/healthservice/templates/pdb.yaml
# Example pod distribution budget configuration.
#
apiVersion: policy/v1
kind: PodDisruptionBudget
metadata:
name: {{ .Chart.Name }}-pdb
spec:
minAvailable: 1
selector:
matchLabels:
app: {{ .Chart.Name }}
Примечание
Фактическое минимальное и максимальное количество модулей pod для каждого компонента должно определяться с помощью нагрузочного тестирования и может отличаться для каждой рабочей нагрузки.
Инструментирование
Инструментирование — это важный механизм для оценки производительности и проблем работоспособности, которые компоненты рабочей нагрузки могут внедрять в систему. Каждый компонент должен выдавать достаточно информации через метрики и журналы трассировки для количественной оценки решений. Ниже приведены некоторые ключевые рекомендации по инструментированию приложения.
- Отправляйте журналы, метрики и дополнительные данные телеметрии в систему журналов метки.
- Используйте структурированное ведение журнала вместо обычного текста, чтобы можно было запрашивать сведения.
- Реализуйте корреляцию событий, чтобы обеспечить сквозное представление транзакций. В зарезервированном экземпляре каждый ответ API содержит идентификатор операции в качестве заголовка HTTP для отслеживания.
- Не полагайтесь только на ведение журнала stdout (консоль). Однако эти журналы можно использовать для немедленного устранения неполадок при сбое модуля pod.
Эта архитектура реализует распределенную трассировку с помощью Application Insights на основе рабочей области Log Analytics для всех данных мониторинга приложений. Azure Log Analytics используется для журналов и метрик всех компонентов рабочей нагрузки и инфраструктуры. Рабочая нагрузка реализует полную сквозную трассировку запросов, поступающих из API через Центры событий в Azure Cosmos DB.
Важно!
Ресурсы мониторинга меток развертываются в отдельной группе ресурсов мониторинга и имеют другой жизненный цикл, чем сама метка. Дополнительные сведения см. в разделе Мониторинг данных для ресурсов меток.

Сведения о реализации мониторинга приложений
Компонент BackgroundProcessor использует Microsoft.ApplicationInsights.WorkerService пакет NuGet для получения встроенного инструментирования из приложения. Кроме того, Serilog используется для всех ведения журнала в приложении с приложение Azure Insights, настроенным в качестве приемника (рядом с приемником консоли). Экземпляр Application Insights используется напрямую TelemetryClient только при необходимости отслеживания дополнительных метрик.
//
// /src/app/AlwaysOn.BackgroundProcessor/Program.cs
//
public static IHostBuilder CreateHostBuilder(string[] args) =>
Host.CreateDefaultBuilder(args)
.ConfigureServices((hostContext, services) =>
{
Log.Logger = new LoggerConfiguration()
.ReadFrom.Configuration(hostContext.Configuration)
.Enrich.FromLogContext()
.WriteTo.Console(outputTemplate: "[{Timestamp:yyyy-MM-dd HH:mm:ss.fff zzz} {Level:u3}] {Message:lj} {Properties:j}{NewLine}{Exception}")
.WriteTo.ApplicationInsights(hostContext.Configuration[SysConfiguration.ApplicationInsightsConnStringKeyName], TelemetryConverter.Traces)
.CreateLogger();
}

Чтобы продемонстрировать практическую возможность трассировки запросов, каждый запрос API (успешный или нет) возвращает вызывающей объекту заголовок Идентификатор корреляции. С помощью этого идентификатора группа поддержки приложений может выполнять поиск в Application Insights и получать подробные сведения о полной транзакции.
//
// /src/app/AlwaysOn.CatalogService/Startup.cs
//
app.Use(async (context, next) =>
{
context.Response.OnStarting(o =>
{
if (o is HttpContext ctx)
{
// ... code omitted for brevity
context.Response.Headers.Add("X-Server-Location", sysConfig.AzureRegion);
context.Response.Headers.Add("X-Correlation-ID", Activity.Current?.RootId);
context.Response.Headers.Add("X-Requested-Api-Version", ctx.GetRequestedApiVersion()?.ToString());
}
return Task.CompletedTask;
}, context);
await next();
});
Примечание
По умолчанию в пакете SDK для Application Insights включена адаптивная выборка. Это означает, что не каждый запрос отправляется в облако и доступен для поиска по идентификатору. Критически важные команды приложений должны иметь возможность надежно отслеживать каждый запрос, поэтому эталонная реализация отключила адаптивную выборку в рабочей среде.
Сведения о реализации мониторинга Kubernetes
Помимо использования параметров диагностики для отправки журналов и метрик AKS в Log Analytics, AKS также настроен для использования Аналитики контейнеров. Включение Аналитики контейнеров позволяет развернуть OMSAgentForLinux с помощью daemonSet Kubernetes на каждом из узлов в кластерах AKS. OMSAgentForLinux может собирать дополнительные журналы и метрики из кластера Kubernetes и отправлять их в соответствующую рабочую область Log Analytics. Он содержит более подробные данные о модулях pod, развертываниях, службах и общей работоспособности кластера.
Обширное ведение журнала может негативно повлиять на затраты, не предоставляя никаких преимуществ. По этой причине сбор журналов stdout и очистка Prometheus отключены для модулей pod рабочей нагрузки в конфигурации Container Insights, так как все трассировки уже фиксируются с помощью Application Insights, создавая дубликаты записей.
#
# /src/config/monitoring/container-azm-ms-agentconfig.yaml
# This is just a snippet showing the relevant part.
#
[log_collection_settings]
[log_collection_settings.stdout]
enabled = false
exclude_namespaces = ["kube-system"]
См. полный файл конфигурации для справки.
Мониторинг работоспособности
Мониторинг и наблюдаемость приложений обычно используются для быстрого выявления проблем с системой и информирования модели работоспособности о текущем состоянии приложения. Мониторинг работоспособности, который отображается через конечные точки работоспособности и используется пробами работоспособности, предоставляет информацию, которая сразу же становится практически возможной. Обычно она предписывает подсистеме балансировки нагрузки main вывести неработоспособный компонент из ротации.
В архитектуре мониторинг работоспособности применяется на следующих уровнях:
- Модули pod рабочей нагрузки, работающие в AKS. Эти модули pod имеют пробы работоспособности и активности, поэтому AKS может управлять их жизненным циклом.
- Служба работоспособности — это выделенный компонент в кластере. Azure Front Door настроен для проверки служб работоспособности в каждой метке и автоматического удаления неработоспособных меток из балансировки нагрузки.
Сведения о реализации службы работоспособности
HealthService — это компонент рабочей нагрузки, который выполняется вместе с другими компонентами (CatalogService и BackgroundProcessor) в вычислительном кластере. Он предоставляет REST API, вызываемый проверка работоспособности Azure Front Door для определения доступности метки. В отличие от базовых проб активности, служба работоспособности является более сложным компонентом, который добавляет состояние зависимостей в дополнение к собственному.

Если кластер AKS не работает, служба работоспособности не отвечает, что делает рабочую нагрузку неработоспособной. Когда служба запущена, она периодически проверяет критически важные компоненты решения. Все проверки выполняются асинхронно и параллельно. Если какой-либо из них завершится ошибкой, вся метка будет считаться недоступной.
Предупреждение
Пробы работоспособности Azure Front Door могут создавать значительную нагрузку на службу работоспособности, так как запросы поступают из нескольких расположений PoP. Чтобы предотвратить перегрузку подчиненных компонентов, необходимо выполнить соответствующее кэширование.
Служба работоспособности также используется для явно настроенных тестов проверки ping URL-адреса с ресурсом Application Insights для каждой метки.
Дополнительные сведения о реализации см. в HealthService разделе Служба работоспособности приложений.
Обратная связь
Ожидается в ближайшее время: в течение 2024 года мы постепенно откажемся от GitHub Issues как механизма обратной связи для контента и заменим его новой системой обратной связи. Дополнительные сведения см. в разделе https://aka.ms/ContentUserFeedback.
Отправить и просмотреть отзыв по