Мониторинг потоков данных
Область применения: Фабрика данных Azure Azure Synapse Analytics
Фабрика данных Azure Azure Synapse Analytics
Совет
Попробуйте использовать фабрику данных в Microsoft Fabric, решение для аналитики с одним интерфейсом для предприятий. Microsoft Fabric охватывает все, от перемещения данных до обработки и анализа данных в режиме реального времени, бизнес-аналитики и отчетности. Узнайте, как бесплатно запустить новую пробную версию !
После создания и отладки потока данных вы, возможно, захотите настроить его выполнение по расписанию в контексте конвейера. Вы можете запланировать конвейер с помощью триггеров. Для тестирования и отладки потока данных из конвейера можно использовать кнопку отладки на ленте панели инструментов или параметр "Активировать сейчас" из конвейера, чтобы выполнить однозапустите выполнение для тестирования потока данных в контексте конвейера.
Во время выполнения конвейера вы сможете осуществлять мониторинг конвейера и всех содержащихся в нем действий, в том числе действия потока данных. Щелкните значок монитора на панели пользовательского интерфейса слева. Вы можете увидеть экран, аналогичный следующему. Выделенные значки позволят посмотреть подробные сведения о действиях в конвейере, в том числе действии потока данных.
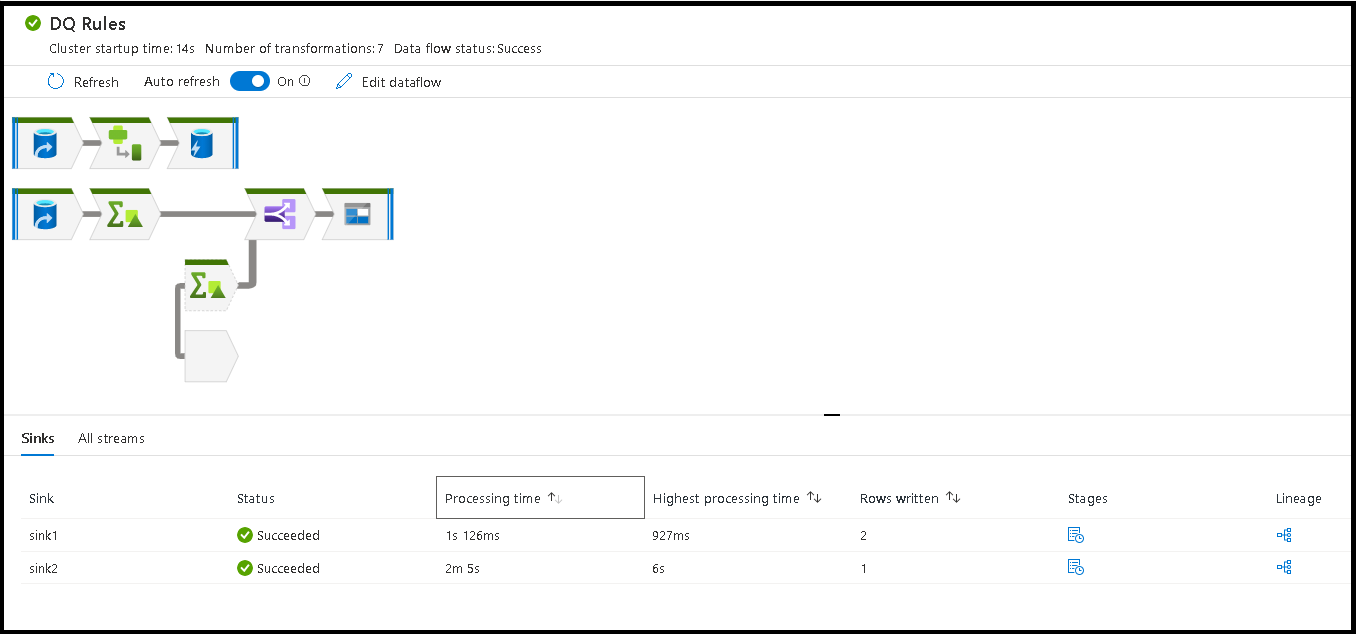
На этом уровне вы увидите статистику, включая статистику времени выполнения и состояния. Идентификаторы выполнения на уровне действия и конвейера отличаются. На предыдущем уровне приведен идентификатор выполнения конвейера. Если выбрать значок очков, появятся подробные сведения о выполнении потока данных.

В представлении графического мониторинга узла приведена упрощенная доступная только для просмотра версия графа потока данных. Чтобы просмотреть подробное представление с крупными узлами графа, включающими метки этапов преобразования, используйте ползунок "Масштаб" в правой части холста. Кроме того, с помощью кнопки поиска в правой части можно найти в графе элементы логики потока данных.
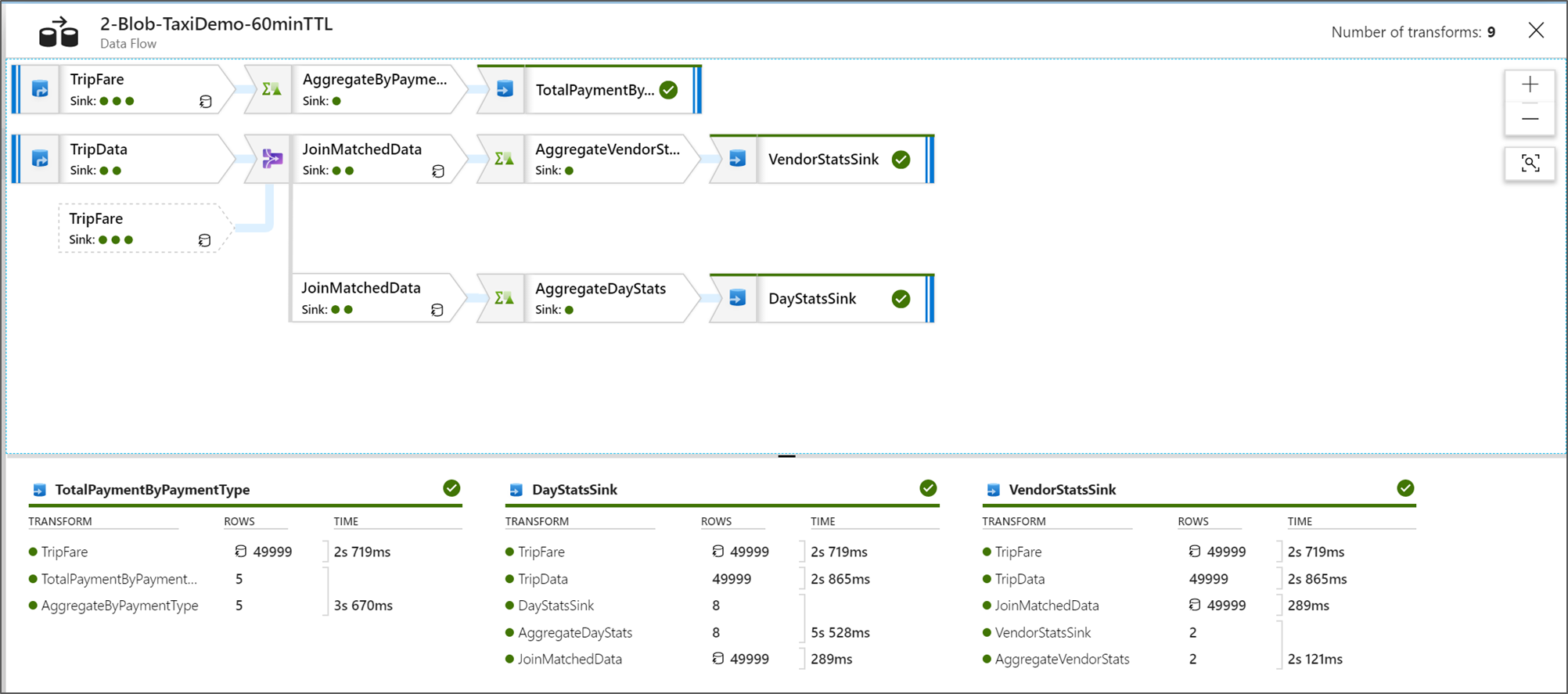
Просмотр планов выполнения потоков данных
Когда поток данных выполняется в Spark, служба определяет оптимальные пути выполнения кода на основе цельности потока данных. Кроме того, пути выполнения могут возникать на разных узлах горизонтального масштабирования и секциях данных. Таким образом, граф мониторинга представляет структуру потока, принимая во внимание путь выполнения преобразований. При выборе отдельных узлов вы увидите "этапы", представляющие код, который выполнялся вместе в кластере. Время и числа, которые вы видите, относятся к этим группам или этапам, а не отдельным этапам в структуре.
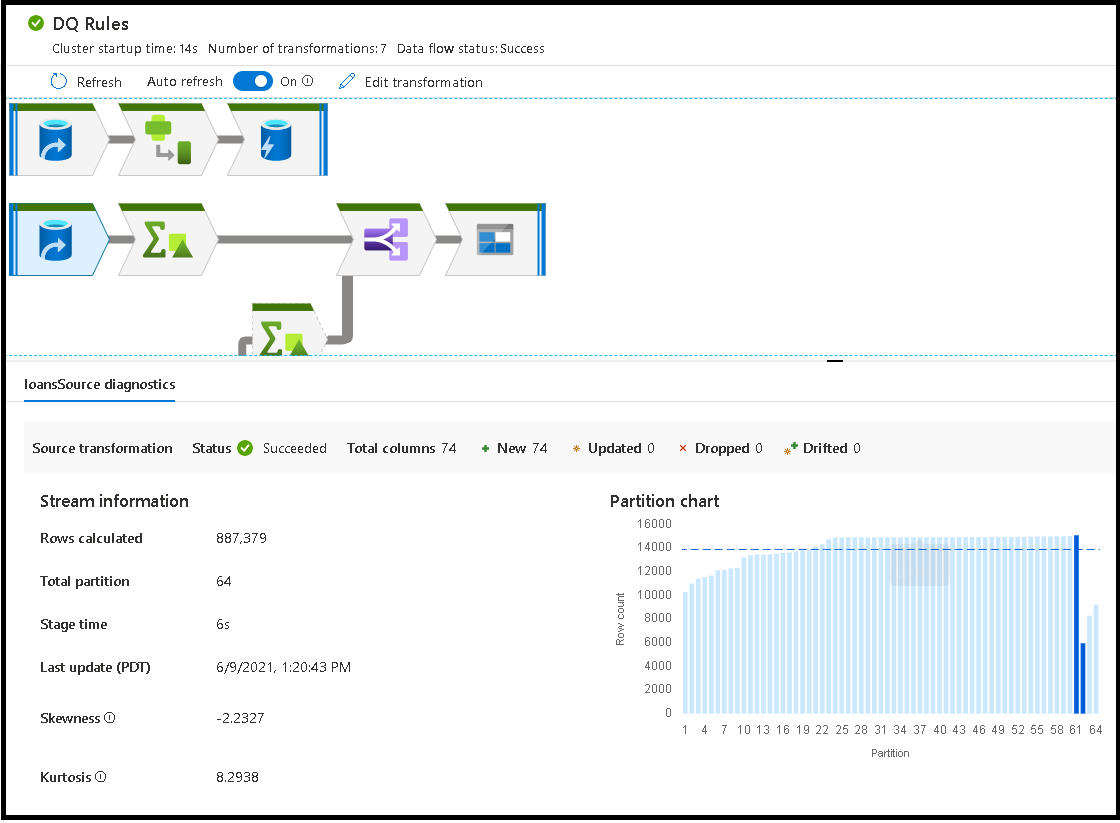
Если выбрать пустое место в окне мониторинга, в нижней области появится статистика со временем и количеством строк по каждому приемнику, а также преобразования, данные из приемников которых отображаются в журнале преобразований.
При выборе отдельных преобразований вы получите дополнительные отзывы на правой панели, где отображаются статистики секций, счетчики столбцов, отклонение (равномерное распределение данных между секциями) и куртоз (как пики являются данными).
Сортировка по времени обработки помогает определить, какие этапы потока данных заняли больше всего времени.
Чтобы определить, какие преобразования в каждом этапе заняли наибольшее время, отсортируйте их по возрастанию времени обработки.
Записанные строки *также можно сортировать как способ определить, какие потоки внутри потока данных записывают большинство данных.
Если выбрать приемник в представлении узла, отобразится журнал преобразований столбцов. Существуют три различных метода накопления столбцов в потоке данных перед попаданием в приемник. В их число входят:
- Вычислено: столбец используется для условной обработки или выражения в потоке данных, но не помещайте его в приемник.
- Производный: столбец — это новый столбец, созданный в потоке, то есть он не был представлен в источнике.
- Сопоставлено: столбец, полученный из источника, и вы сопоставляете его с полем приемника.
- Состояние потока данных: текущее состояние выполнения
- Время запуска кластера: время получения вычислительной среды JIT Spark для выполнения потока данных
- Количество преобразований: сколько шагов преобразования выполняется в потоке

Общее время обработки приемника и время обработки преобразования
Каждый этап преобразования включает общее время выполнения самого этапа с указанием суммарного времени выполнения каждого раздела. При выборе приемника отображается значение "Время обработки приемника". В время входит общее время преобразования и время ввода-вывода, затраченное на запись данных в конечное хранилище. Разница между временем обработки приемника и общей суммой преобразования — это время ввода-вывода для записи данных.
Подробные сведения об этапах преобразования каждого раздела можно просмотреть, открыв выходные данные JSON действия потока данных в представлении мониторинга конвейеров. В файле JSON содержится время в миллисекундах выполнения каждого раздела, а представление мониторинга UX представляет собой совокупное время разделов:
{
"stage": 4,
"partitionTimes": [
14353,
14914,
14246,
14912,
...
]
}
Время обработки приемника
При выборе значка преобразования приемника на карте на панели слайда справа отображается дополнительная точка данных с именем "время последующей обработки" внизу. Это количество времени, затраченного на выполнение задания в кластере Spark после загрузки, преобразования и записи данных. На этот раз можно включить закрытие пулов подключений, завершение работы драйвера, удаление файлов, объединение файлов и т. д. При выполнении действий в потоке, например "переместить файлы" и "выходные данные в один файл", вероятно, вы увидите увеличение значения времени после обработки.
- Длительность этапа записи: время записи данных в промежуточное расположение для Synapse SQL
- Длительность операции SQL с таблицей: время, затраченное на перемещение данных из временных таблиц в целевую таблицу
- Длительность до выполнения SQL и длительность после выполнения SQL: время, затраченное на выполнение команд до или после команды SQL
- Длительность до выполнения команд и длительность после выполнения команд: время, затраченное на выполнение операций, предшествующих или отправленных для источников и приемников на основе файлов. Например, перемещение или удаление файлов после обработки.
- Длительность слияния: время, затраченное на слияние файла; файлы слияния используются для приемников на основе файлов при записи в один файл или при использовании "имени файла в качестве данных столбца". Если в этой метрике тратится значительное время, следует избегать использования этих параметров.
- Время этапа: общее время, затраченное внутри Spark для завершения операции в качестве этапа
- Временная промежуточная среда: имя временной таблицы, используемой потоками данных для размещения данных в базе данных.
Строки ошибок
Включение обработки строк ошибок в приемнике потока данных влияет на выходные данные мониторинга. Если присвоить приемнику значение "Сообщить об успешном выполнении ошибки", выходные данные мониторинга показывают количество успешных и неудачных строк при выборе узла мониторинга приемника.
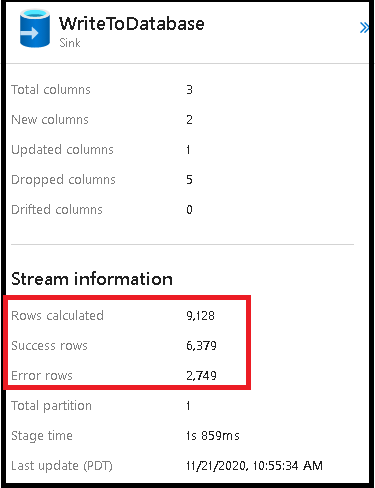
При выборе параметра "Ошибка отчета об ошибке" те же выходные данные отображаются только в тексте вывода мониторинга активности. Это связано с тем, что действие потока данных возвращает сбой для выполнения, а подробное представление мониторинга недоступно.
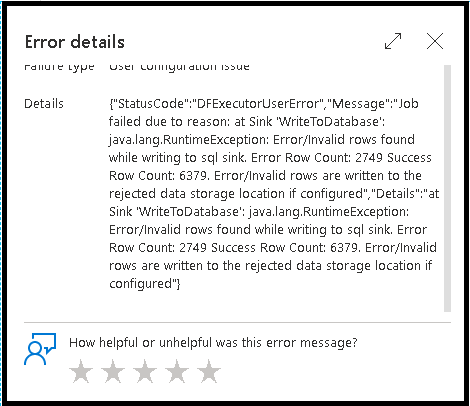
Значки мониторинга
Этот значок означает, что данные преобразования уже были кэшированы в кластере, поэтому это учитывается при расчете времени и определении пути выполнения.
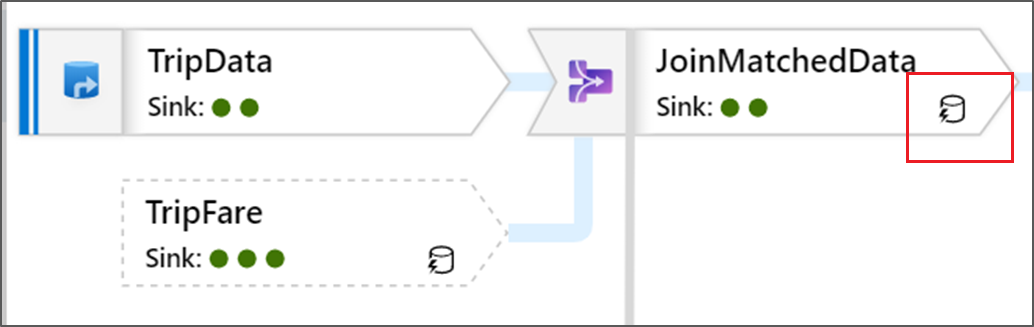
Кроме того, вы увидите зеленые круглые значки в преобразовании. Это количество приемников, в которые передаются данные.