Итеративная разработка и отладка с помощью конвейеров Фабрики данных Azure и Synapse Analytics
Область применения: Фабрика данных Azure Azure Synapse Analytics
Фабрика данных Azure Azure Synapse Analytics
Совет
Попробуйте использовать фабрику данных в Microsoft Fabric, решение для аналитики с одним интерфейсом для предприятий. Microsoft Fabric охватывает все, от перемещения данных до обработки и анализа данных в режиме реального времени, бизнес-аналитики и отчетности. Узнайте, как бесплатно запустить новую пробную версию !
Фабрика данных Azure и Synapse Analytics поддерживают итеративную разработку и отладку конвейеров. Эти функции позволяют тестировать изменения перед созданием запроса на вытягивание или их публикацией в службе.
Общие сведения об этой функции и ее демонстрацию см. в следующем 8-минутном видео:
Отладка конвейера
Создав конвейер с помощью холста, вы можете тестировать его действия с помощью функции отладки. До выбора команды Отладка при выполнении тестовых запусков не нужно публиковать изменения в службе. Это помогает в сценариях, когда перед обновлением рабочих процессов необходимо убедиться, что изменения работают, как и ожидалось.
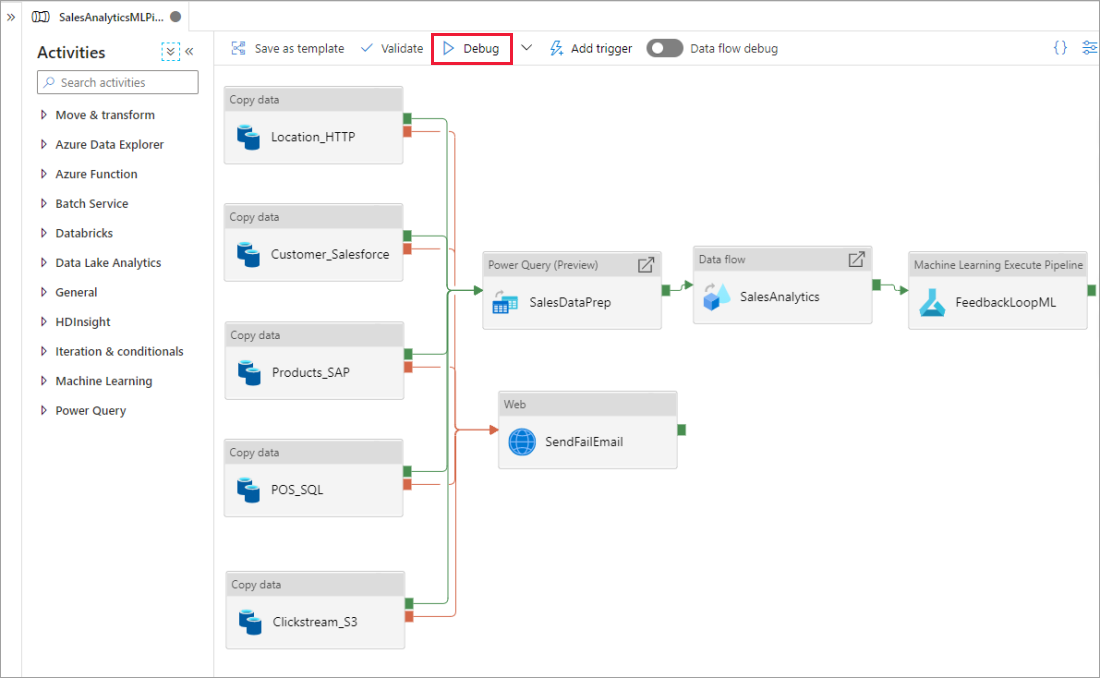
Когда конвейер запущен, результат каждого действия можно видеть на вкладке Выходные данные холста конвейера.
Просмотреть результаты тестовых запусков можно в окне Выходные данные на холсте конвейера.
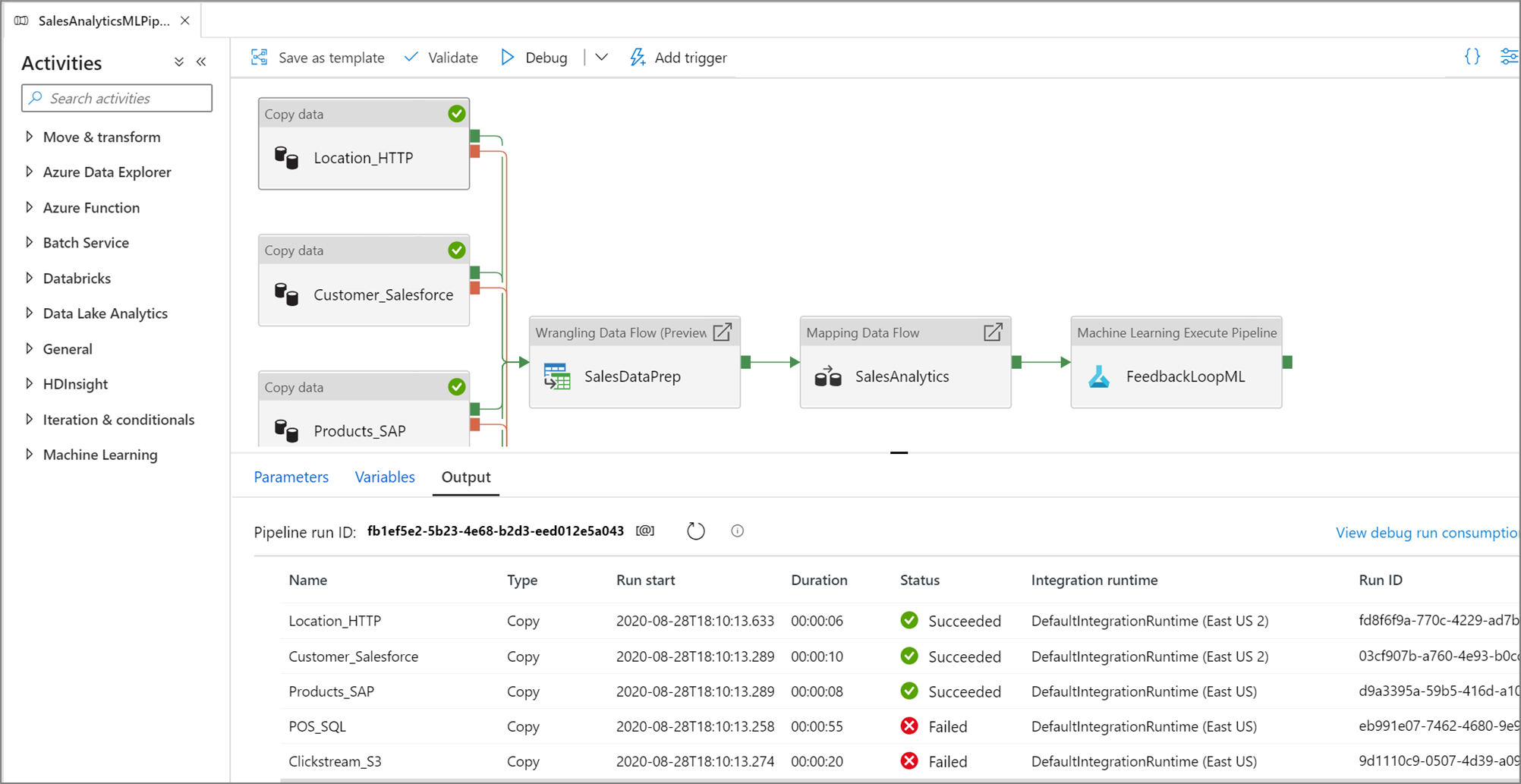
После успешных тестовых запусков добавьте дополнительные действия в конвейер и продолжайте отладку итеративным методом. В ходе выполнения тестового запуска также можно нажать кнопку Отмена.
Важно!
Если выбрать функцию Отладка, конвейер будет запущен. Например, если в конвейере находится действие копирования, при тестовом запуске данные скопируются из источника в место назначения. В итоге в действиях копирования и других действиях при отладке рекомендуется использовать тестовые папки. После отладки конвейера переключитесь на фактические папки, которые нужно использовать во время обычной работы.
Задание точек останова
Служба позволяет выполнять отладку конвейера до тех пор, пока не будет достигнуто определенное действие на холсте конвейера. Поместите точку останова в позицию действия, до которого необходимо выполнять проверку, и выберите Отладка. Служба обеспечит выполнение теста до указанной точки останова на холсте конвейера. Функцию Debug Until (Отладка до момента) следует использовать, когда необходимо проверить не весь конвейер, а только подмножество действий внутри него.
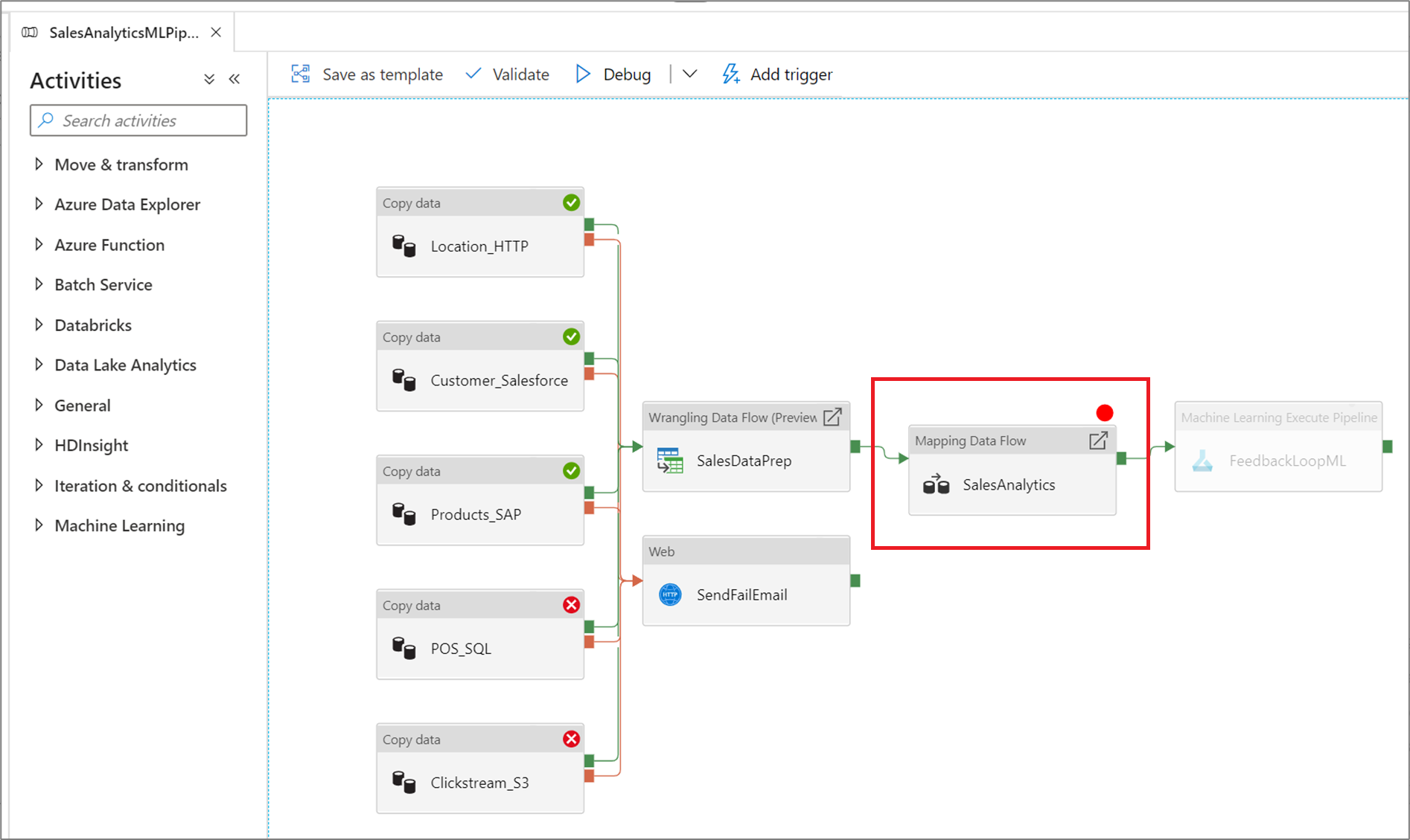
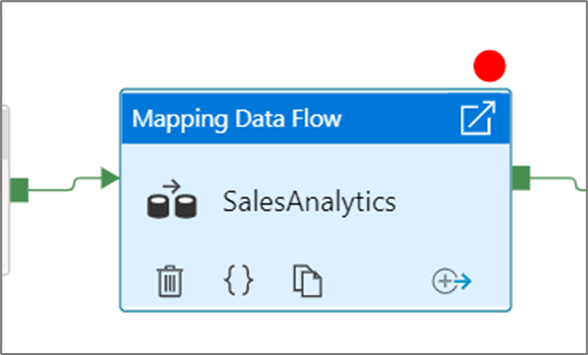
Чтобы задать точку останова, выберите элемент на холсте конвейера. Параметр Отладка до момента появляется в виде пустого красного круга в правом верхнем углу элемента.
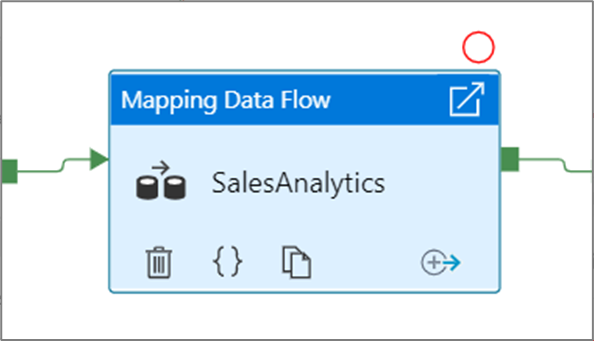
Когда вы выберете параметр Отладка до момента, он изменится на красный круг с заливкой, указывая на включение точки останова.
Мониторинг запусков отладки
При выполнении отладки конвейера результаты будут отображаться в окне Выходные данные на холсте конвейера. На вкладке "Выходные данные" будет содержаться только последнее выполнение, произошедшее во время текущего сеанса работы в браузере.
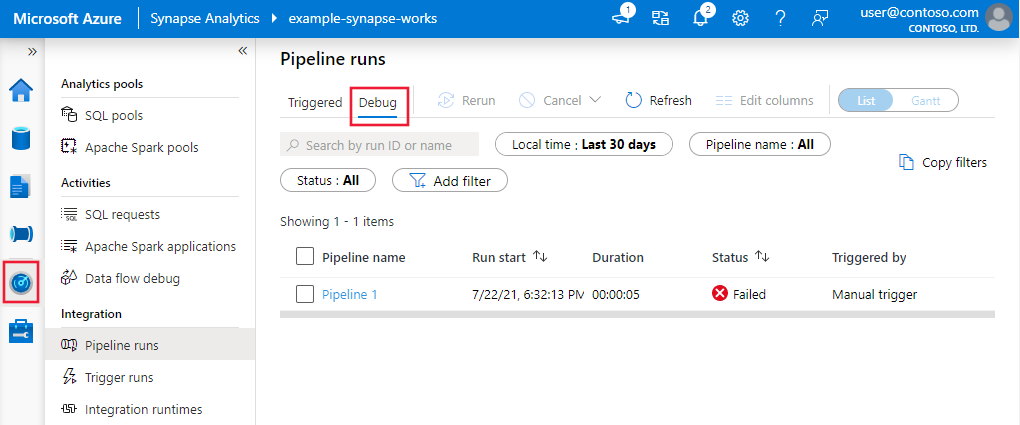
Для просмотра журнала запусков отладки или просмотра списка всех активных запусков отладки можно перейти к Монитору.

Примечание.
Служба сохраняет журнал отладки только за последние 15 дней.
Отладка потоков данных для сопоставления
Потоки данных для сопоставления позволяют создавать логику преобразования данных без написания кода, которая выполняется в большом масштабе. При разработке логики можно включить сеанс отладки для интерактивной работы с данными с помощью активного кластера Spark. Дополнительные сведения см. в статье Режим отладки потока данных для сопоставления.
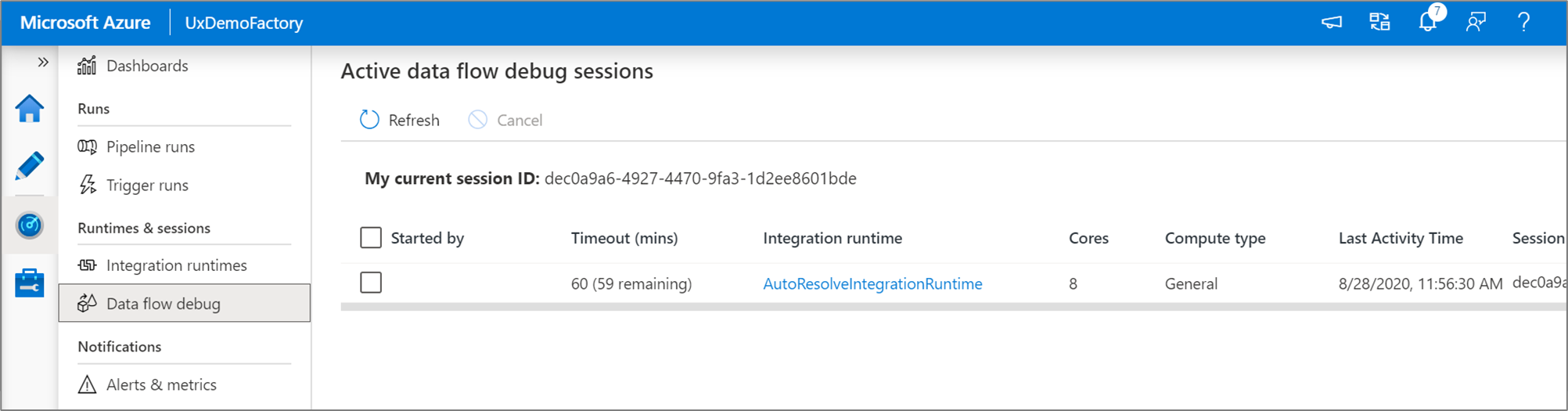
Активные сеансы отладки потока данных можно отслеживать на странице Мониторинг.
Предварительный просмотр данных в конструкторе потоков данных и отладка конвейеров потоков данных лучше всего работают с небольшими порциями данных. Однако если необходимо протестировать логику в конвейере или потоке данных с использованием больших объемов данных, увеличьте размер Azure Integration Runtime, используемого в сеансе отладки, увеличив количество ядер и сведя к минимуму число вычислений общего назначения.
Отладка конвейера с помощью действия "Поток данных"
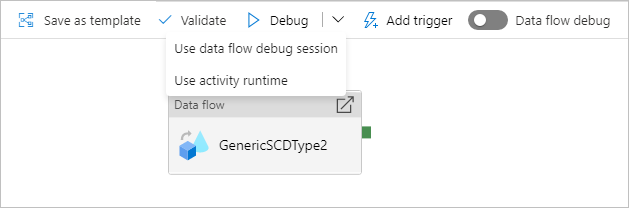
При выполнении отладки конвейера с потоком данных существует два варианта использования вычислений. Можно либо использовать существующий кластер отладки, либо запустить новый JIT-кластер для потоков данных.
Использование существующего сеанса отладки значительно сокращает время запуска потока данных, так как кластер уже выполняется, но не рекомендуется для сложных или параллельных рабочих нагрузок, так как может произойти сбой при одновременном запуске нескольких заданий.
При использовании среды выполнения действий будет создан новый кластер с параметрами, заданными в каждой среде выполнения интеграции действия потока данных. Это позволяет изолировать каждое задание и использовать его для сложных рабочих нагрузок или тестирования производительности. Можно также управлять сроком жизни в Azure IR, чтобы ресурсы кластера, используемые для отладки, по-прежнему были доступны в течение этого периода времени для обработки дополнительных запросов заданий.
Примечание.
При наличии конвейера с потоками данных, выполняемыми параллельно, или потоками данных, которые необходимо протестировать с помощью больших наборов данных, выберите пункт "Использовать среду выполнения действий", чтобы служба могла использовать среду выполнения интеграции, выбранную в действии потока данных. Это позволит потокам данных выполняться на нескольких кластерах и справиться с параллельным выполнением потоков данных.
Связанный контент
После тестирования изменений распространяйте их на среды более высокого уровня, используя непрерывную интеграцию и развертывание.