Перенос данных из Amazon S3 в Azure Data Lake Storage 2-го поколения
Область применения: Фабрика данных Azure Azure Synapse Analytics
Фабрика данных Azure Azure Synapse Analytics
Совет
Попробуйте использовать фабрику данных в Microsoft Fabric, решение для аналитики с одним интерфейсом для предприятий. Microsoft Fabric охватывает все, от перемещения данных до обработки и анализа данных в режиме реального времени, бизнес-аналитики и отчетности. Узнайте, как бесплатно запустить новую пробную версию !
Используйте шаблон, с помощью которого можно перенести из Amazon S3 в Azure Data Lake Storage 2-го поколения сотни миллионов файлов, общий объем которых измеряется петабайтами.
Примечание.
Если вы хотите скопировать небольшое количество информации из AWS S3 в Azure (например, менее 10 ТБ), эффективнее и удобнее будет использовать специальный инструмент копирования в Фабрике данных Azure. Шаблон, описанный в этой статье, рекомендуется для большого объема данных.
Общая информация о шаблонах решений
При переносе более чем 10 ТБ данных рекомендуется применить секционирование. Чтобы секционировать данные, используйте параметр prefix для фильтрации папок и файлов в Amazon S3 по имени. После этого каждое задание копирования в Фабрике данных Azure будет копировать по одной секции за раз. Для повышения пропускной способности можно одновременно запустить несколько заданий копирования в Фабрике данных Azure.
Обычно требуется однократный перенос исторических данных, а также периодическая синхронизация изменений AWS S3 с Azure. Ниже приведено два шаблона. Один из них покрывает однократный перенос исторических данных, а другой — синхронизацию изменений AWS S3 с Azure.
Шаблон для переноса исторических данных из Amazon S3 в Azure Data Lake Storage 2-го поколения
Этот шаблон для переноса называется Migrate historical data from AWS S3 to Azure Data Lake Storage Gen2 и предполагает, что вы прописали список секций во внешней управляющей таблице в Базе данных SQL Azure. Поэтому он будет использовать действие Lookup для извлечения списка секций из внешней управляющей таблицы, затем выполнит итерацию для каждой секции и запустит задание копирования в Фабрике данных Azure для одной секции за раз. Когда задание копирования завершится, шаблон применит действие StoredProcedure, и в управляющей таблице обновится информация о состоянии процедуры копирования для каждой секции.
Шаблон состоит из пяти действий.
- Действие Lookup извлекает из внешней управляющей таблицы секции, которые не были скопированы в Azure Data Lake Storage 2-го поколения. Имя таблицы — s3_partition_control_table, а запрос для загрузки из нее данных выглядит следующим образом: "SELECT PartitionPrefix FROM s3_partition_control_table WHERE SuccessOrFailure = 0".
- Действие ForEach получает список секций из действия Lookup и выполняет итерацию для каждой секции для действия TriggerCopy. Чтобы одновременно запустить несколько заданий копирования в Фабрике данных Azure, можно настроить параметр batchCount. В этом шаблоне мы задали значение 2.
- Действие ExecutePipeline выполняет конвейер команд CopyFolderPartitionFromS3. Мы создаем отдельный конвейер для каждого задания копирования секции, потому что это облегчает повторный запуск неудачного задания и загрузку этой секции из AWS S3. Остальные задания копирования, которые загружают другие секции, не будут затронуты.
- Действие Copy копирует каждую секцию из AWS S3 в Azure Data Lake Storage 2-го поколения.
- Действие SqlServerStoredProcedure обновляет в управляющей таблице информацию о состоянии процедуры копирования для каждой секции.
Шаблон содержит два параметра.
- AWS_S3_bucketName — это имя контейнера в AWS S3, из которого вам нужно перенести данные. Если вы хотите перенести данные из нескольких контейнеров AWS S3, добавьте еще один столбец во внешнюю управляющую таблицу, в котором будет храниться имя контейнера для каждой секции, и соответствующим образом обновите конвейер, чтобы он получал данные из этого столбца.
- Azure_Storage_fileSystem — это имя файловой системы на Azure Data Lake Storage 2-го поколения, в которую вам нужно перенести данные.
Шаблон для копирования только измененных файлов из Amazon S3 в Azure Data Lake Storage 2-го поколения
Этот шаблон для переноса называется Copy delta data from AWS S3 to Azure Data Lake Storage Gen2. Он использует данные свойства LastModifiedTime для каждого файла, чтобы копировать из AWS S3 в Azure только новые или обновленные файлы. Если файлы или папки в AWS S3 уже секционированы по времени и информация о временном срезе указана в их именах (например, файл с именем /гггг/мм/дд/файл.csv), переходите к этому руководству. В нем вы найдете информацию о более эффективном подходе к добавочной загрузке новых файлов. Этот шаблон предполагает, что вы прописали список секций во внешней управляющей таблице в Базе данных SQL Azure. Поэтому он будет использовать действие Lookup для извлечения списка секций из внешней управляющей таблицы, затем выполнит итерацию для каждой секции и запустит задание копирования в Фабрике данных Azure для одной секции за раз. При запуске каждого задания копирования файлов из AWS S3 используется свойство LastModifiedTime, чтобы обнаруживать и копировать только новые или обновленные файлы. Когда задание копирования завершится, шаблон применит действие StoredProcedure, и в управляющей таблице обновится информация о состоянии процедуры копирования для каждой секции.
Шаблон состоит из семи действий.
- Действие Lookup извлекает секции из внешней управляющей таблицы. Имя таблицы — s3_partition_delta_control_table, а запрос для загрузки из нее данных выглядит следующим образом: "select distinct PartitionPrefix from s3_partition_delta_control_table".
- Действие ForEach получает список секций из действия Lookup и выполняет итерацию для каждой секции для действия TriggerDeltaCopy. Чтобы одновременно запустить несколько заданий копирования в Фабрике данных Azure, можно настроить параметр batchCount. В этом шаблоне мы задали значение 2.
- Действие ExecutePipeline выполняет конвейер команд DeltaCopyFolderPartitionFromS3. Мы создаем отдельный конвейер для каждого задания копирования секции, потому что это облегчает повторный запуск неудачного задания и загрузку этой секции из AWS S3. Остальные задания копирования, которые загружают другие секции, не будут затронуты.
- Действие Lookup извлекает из внешней управляющей таблицы информацию о времени выполнения последнего задания копирования, чтобы новые или обновленные файлы можно было обнаружить с помощью свойства LastModifiedTime. Имя таблицы — s3_partition_delta_control_table, а запрос для загрузки из нее данных выглядит следующим образом: "select max(JobRunTime) as LastModifiedTime from s3_partition_delta_control_table where PartitionPrefix = '@{pipeline().parameters.prefixStr}' and SuccessOrFailure = 1".
- Действие Copy копирует из AWS S3 в Azure Data Lake Storage 2-го поколения только новые или измененные файлы из каждой секции. Для свойства modifiedDatetimeStart задано значение времени выполнения последнего задания копирования. Для свойства modifiedDatetimeEnd задано значение времени выполнения текущего задания копирования. Имейте в виду, что используется время часового пояса UTC.
- Действие SqlServerStoredProcedure обновляет в управляющей таблице информацию о состоянии процедуры копирования для каждой секции и времени ее выполнения в случае успешного завершения. Для столбца SuccessOrFailure задано значение 1.
- Действие SqlServerStoredProcedure обновляет в управляющей таблице информацию о состоянии процедуры копирования для каждой секции и времени ее выполнения в случае сбоя. Для столбца SuccessOrFailure задано значение 0.
Шаблон содержит два параметра.
- AWS_S3_bucketName — это имя контейнера в AWS S3, из которого вам нужно перенести данные. Если вы хотите перенести данные из нескольких контейнеров AWS S3, добавьте еще один столбец во внешнюю управляющую таблицу, в котором будет храниться имя контейнера для каждой секции, и соответствующим образом обновите конвейер, чтобы он получал данные из этого столбца.
- Azure_Storage_fileSystem — это имя файловой системы на Azure Data Lake Storage 2-го поколения, в которую вам нужно перенести данные.
Использование шаблонов решений
Шаблон для переноса исторических данных из Amazon S3 в Azure Data Lake Storage 2-го поколения
Создайте управляющую таблицу в Базе данных SQL Azure для хранения списка секций AWS S3.
Примечание.
Имя таблицы — s3_partition_control_table. Схема управляющей таблицы — PartitionPrefix и SuccessOrFailure. PartitionPrefix — это параметр префикса в S3 для фильтрации папок и файлов по имени в Amazon S3. SuccessOrFailure указывает на состояние процедуры копирования для каждой секции, где 0 означает, что секция не скопирована в Azure, а 1 — успешное копирование. В управляющей таблице определены 5 секций, и по умолчанию для состояния процедуры копирования для каждой секции установлено значение 0.
CREATE TABLE [dbo].[s3_partition_control_table]( [PartitionPrefix] [varchar](255) NULL, [SuccessOrFailure] [bit] NULL ) INSERT INTO s3_partition_control_table (PartitionPrefix, SuccessOrFailure) VALUES ('a', 0), ('b', 0), ('c', 0), ('d', 0), ('e', 0);Создайте хранимую процедуру в той же Базе данных SQL Azure для управляющей таблицы.
Примечание.
Имя хранимой процедуры — sp_update_partition_success. Эта процедура будет вызываться действием SqlServerStoredProcedure в конвейере Фабрики данных Azure.
CREATE PROCEDURE [dbo].[sp_update_partition_success] @PartPrefix varchar(255) AS BEGIN UPDATE s3_partition_control_table SET [SuccessOrFailure] = 1 WHERE [PartitionPrefix] = @PartPrefix END GOПерейдите к шаблону Migrate historical data from AWS S3 to Azure Data Lake Storage Gen2. Установите соединение с внешней управляющей таблицей, укажите AWS S3 в качестве хранилища источников данных и Azure Data Lake Storage 2-го поколения в качестве целевого хранилища. Имейте в виду, что внешняя управляющая таблица и хранимая процедура ссылаются на одно и то же соединение.

Выберите Использовать этот шаблон.
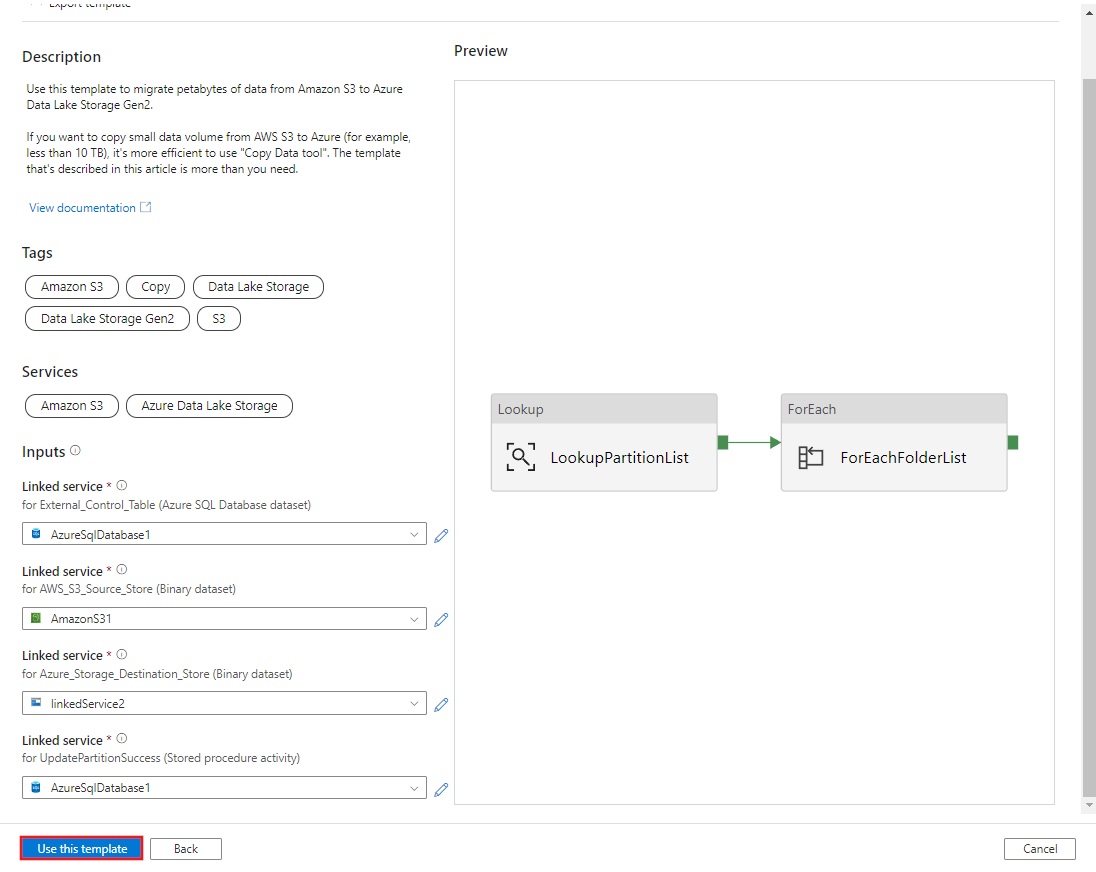
Вы увидите два созданных конвейера и три набора данных, как показано в примере ниже.
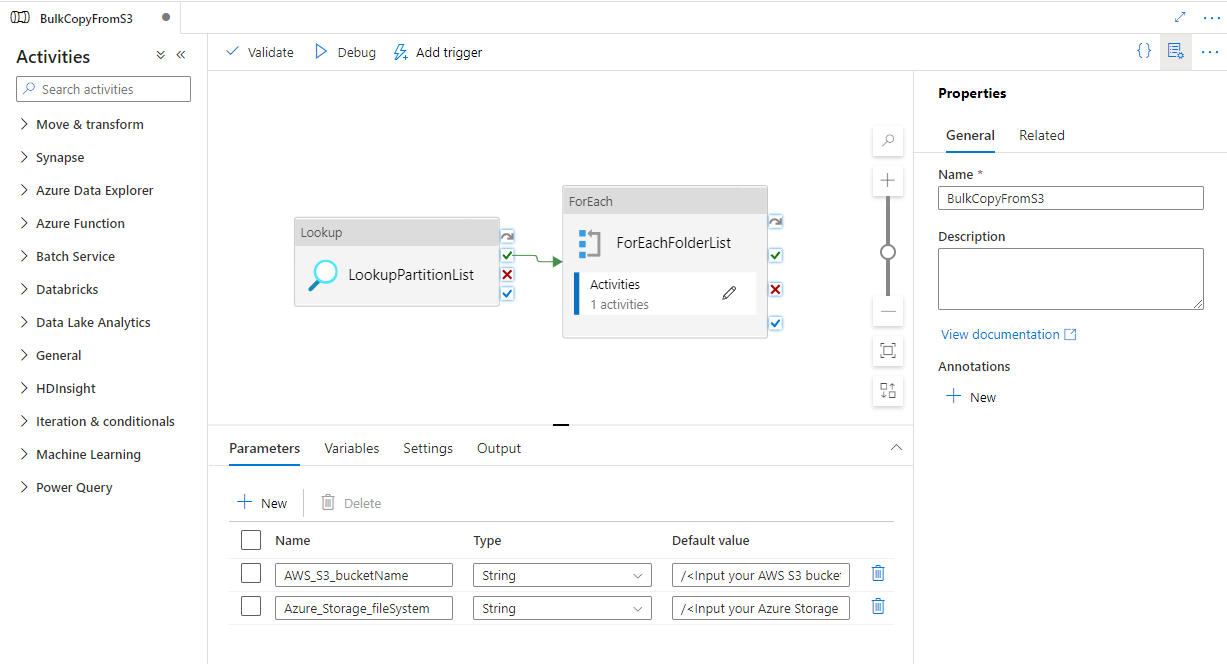
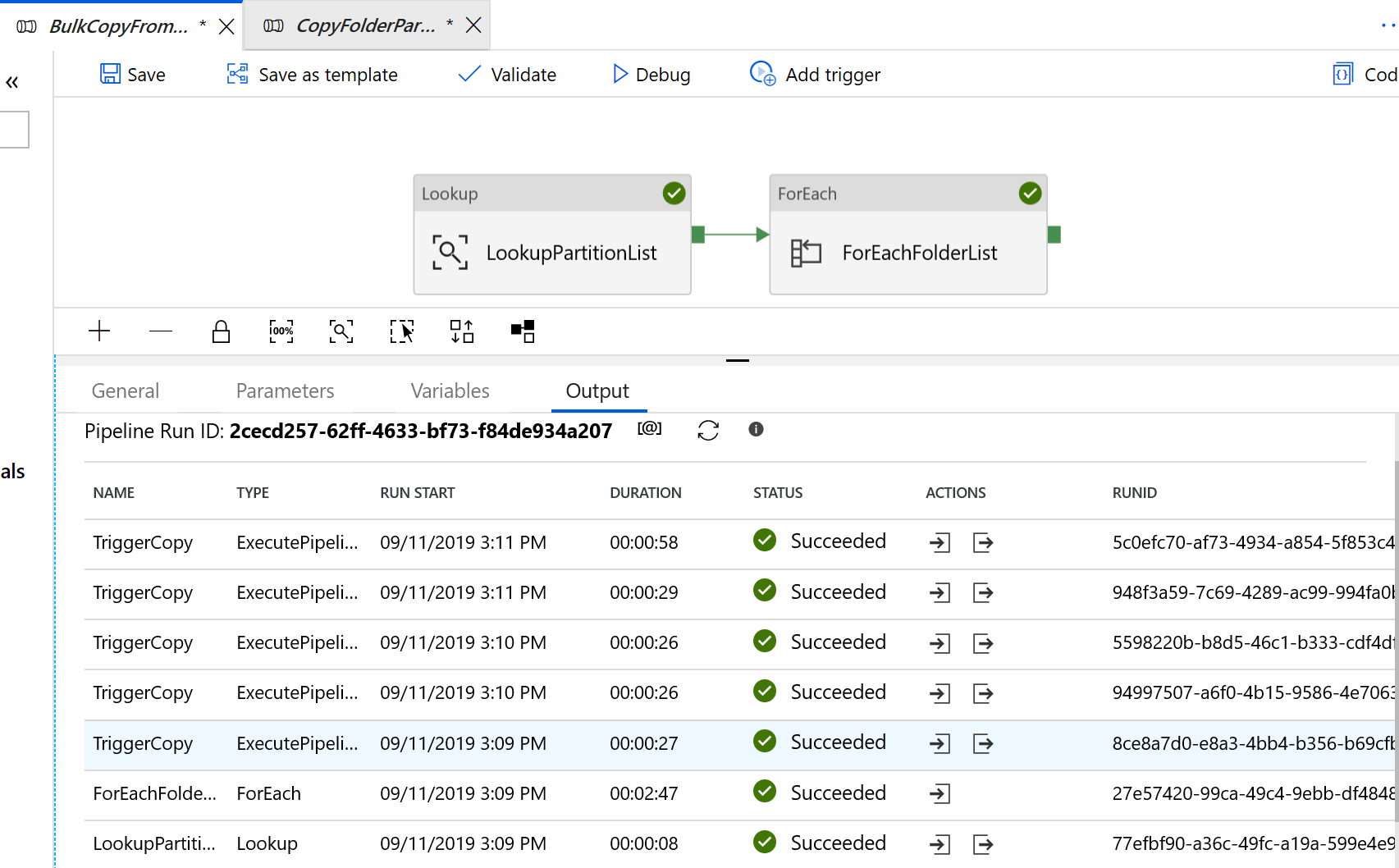
Перейдите к конвейеру BulkCopyFromS3 и выберите Debug (Отладка), а затем введите значения в разделе Parameters (Параметры). Щелкните Готово.
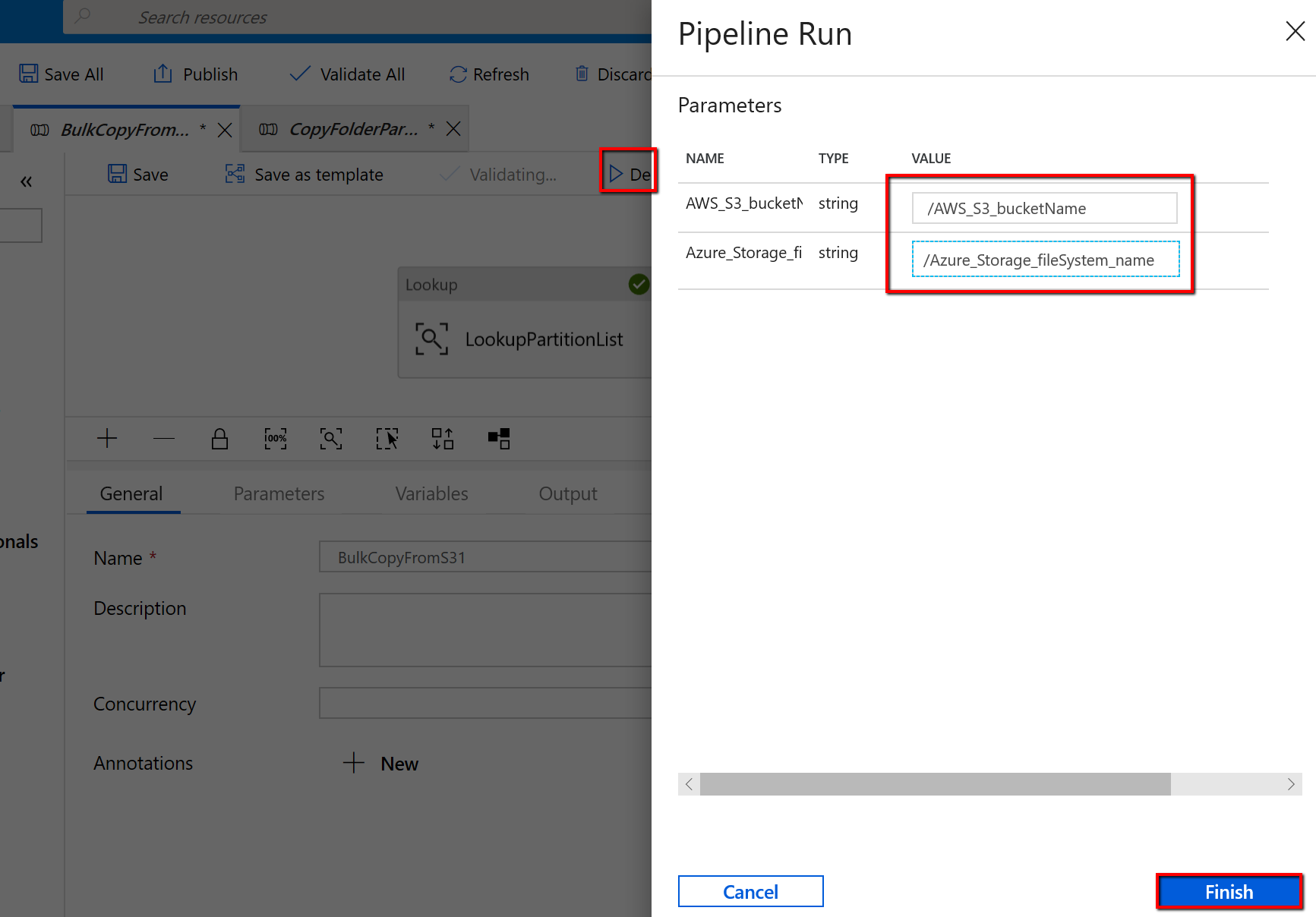
Вы увидите результат, аналогичный приведенному ниже:
Шаблон для копирования только измененных файлов из Amazon S3 в Azure Data Lake Storage 2-го поколения
Создайте управляющую таблицу в Базе данных SQL Azure для хранения списка секций AWS S3.
Примечание.
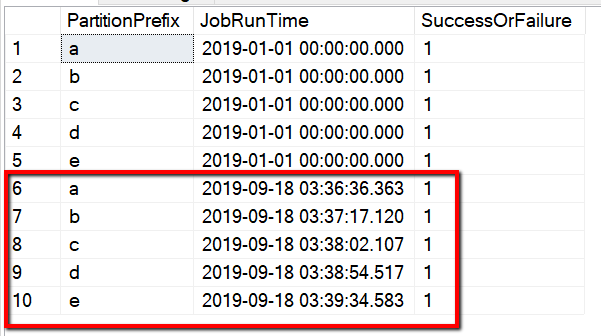
Имя таблицы — s3_partition_delta_control_table. Схема управляющей таблицы — PartitionPrefix, JobRunTime и SuccessOrFailure. PartitionPrefix — это параметр префикса в S3 для фильтрации папок и файлов по имени в Amazon S3. JobRunTime — это значение даты и времени при запуске заданий копирования. SuccessOrFailure указывает на состояние процедуры копирования для каждой секции, где 0 означает, что секция не скопирована в Azure, а 1 — успешное копирование. В управляющей таблице определены 5 секций. Значением по умолчанию для JobRunTime может быть время, когда начинается однократный перенос исторических данных. Действие копирования в Фабрике данных Azure скопирует файлы AWS S3, которые были последний раз изменены после этого времени. По умолчанию для состояния процедуры копирования для каждой секции установлено значение 1.
CREATE TABLE [dbo].[s3_partition_delta_control_table]( [PartitionPrefix] [varchar](255) NULL, [JobRunTime] [datetime] NULL, [SuccessOrFailure] [bit] NULL ) INSERT INTO s3_partition_delta_control_table (PartitionPrefix, JobRunTime, SuccessOrFailure) VALUES ('a','1/1/2019 12:00:00 AM',1), ('b','1/1/2019 12:00:00 AM',1), ('c','1/1/2019 12:00:00 AM',1), ('d','1/1/2019 12:00:00 AM',1), ('e','1/1/2019 12:00:00 AM',1);Создайте хранимую процедуру в той же Базе данных SQL Azure для управляющей таблицы.
Примечание.
Имя хранимой процедуры — sp_insert_partition_JobRunTime_success. Эта процедура будет вызываться действием SqlServerStoredProcedure в конвейере Фабрики данных Azure.
CREATE PROCEDURE [dbo].[sp_insert_partition_JobRunTime_success] @PartPrefix varchar(255), @JobRunTime datetime, @SuccessOrFailure bit AS BEGIN INSERT INTO s3_partition_delta_control_table (PartitionPrefix, JobRunTime, SuccessOrFailure) VALUES (@PartPrefix,@JobRunTime,@SuccessOrFailure) END GOПерейдите к шаблону Copy delta data from AWS S3 to Azure Data Lake Storage Gen2. Установите соединение с внешней управляющей таблицей, укажите AWS S3 в качестве хранилища источников данных и Azure Data Lake Storage 2-го поколения в качестве целевого хранилища. Имейте в виду, что внешняя управляющая таблица и хранимая процедура ссылаются на одно и то же соединение.
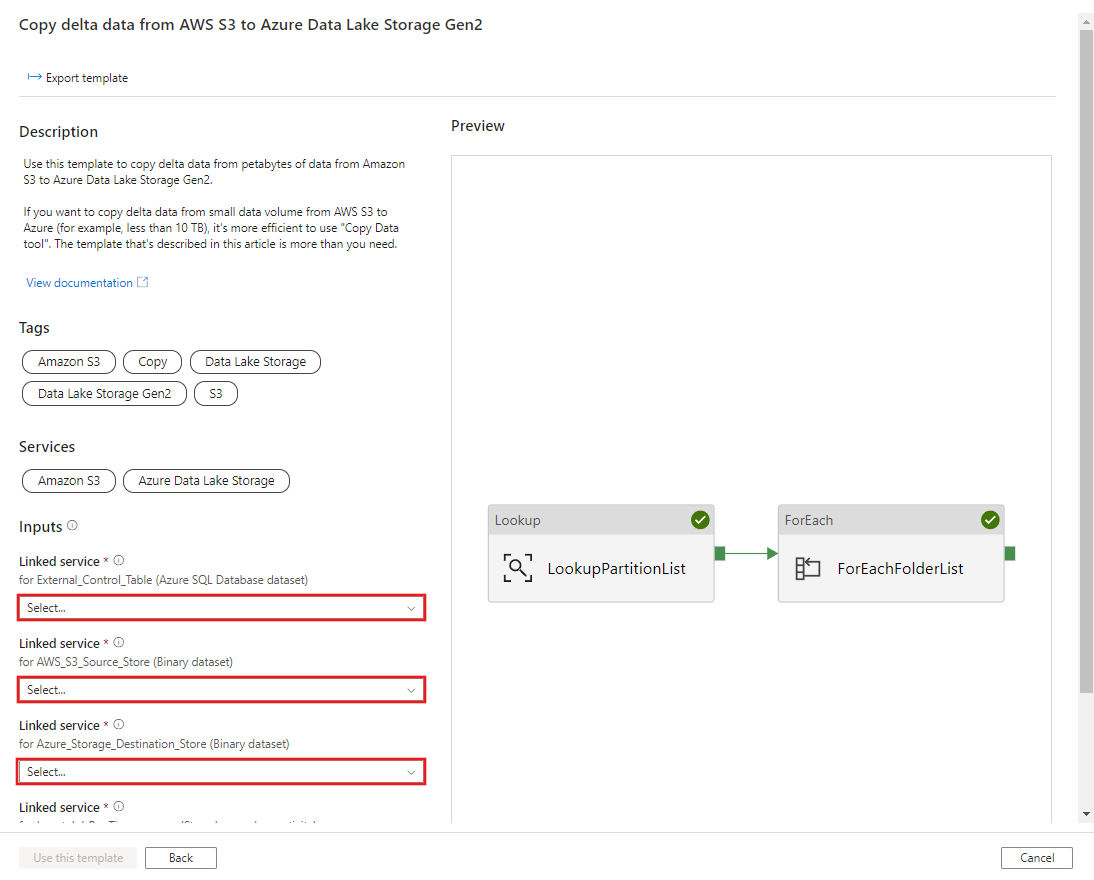
Выберите Использовать этот шаблон.
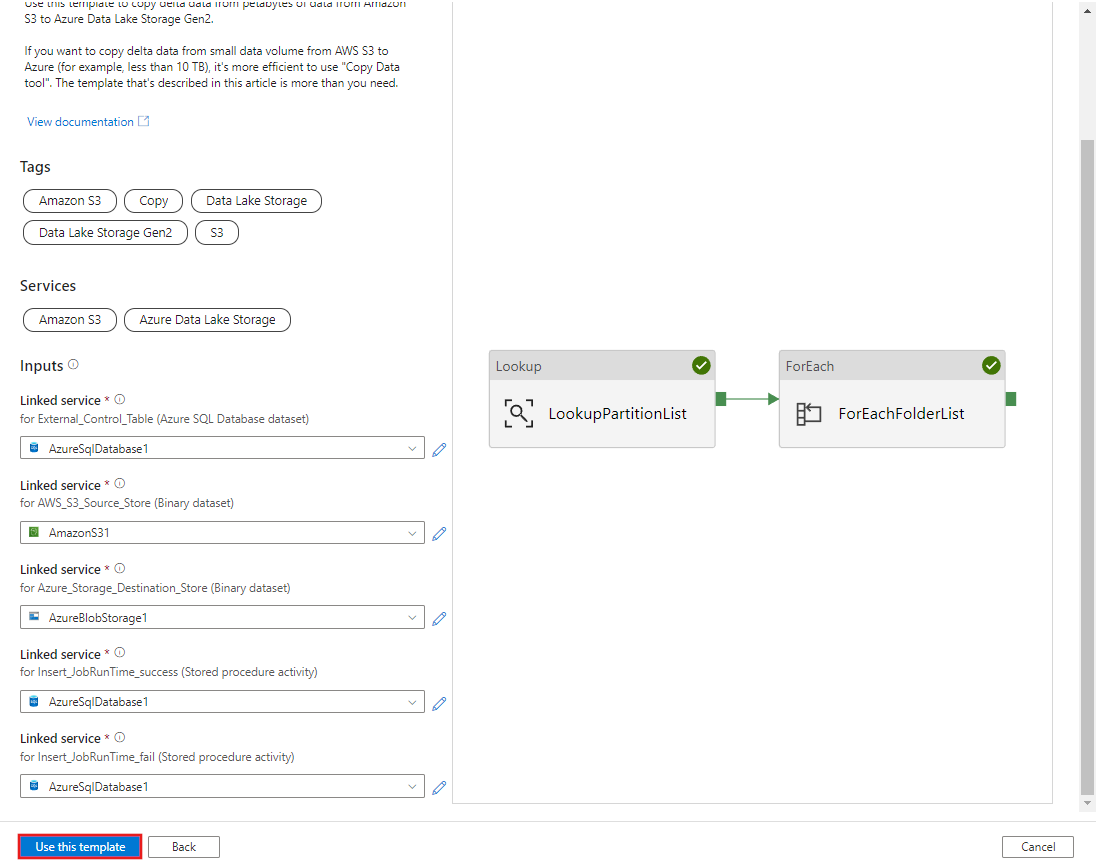
Вы увидите два созданных конвейера и три набора данных, как показано в примере ниже.
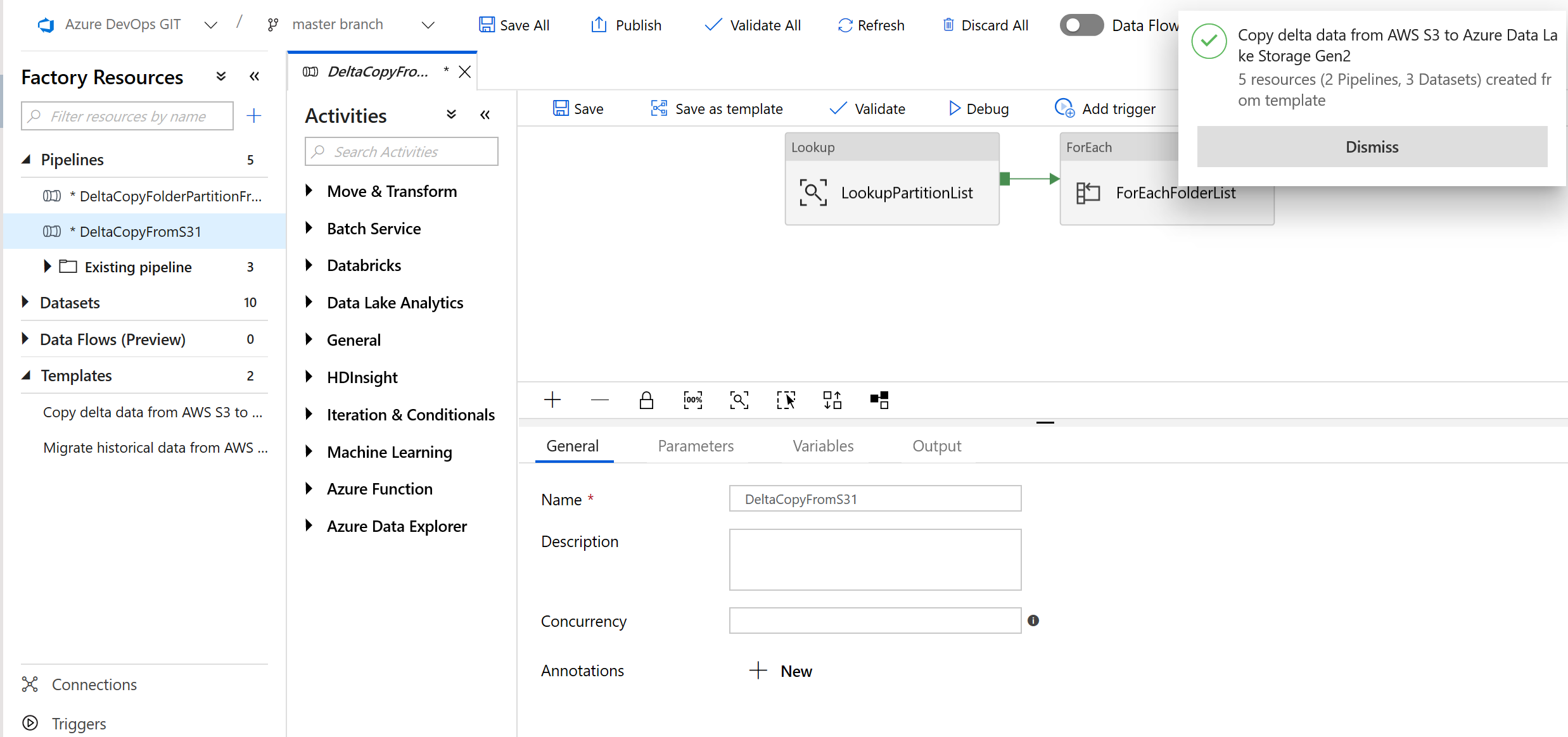
Перейдите к конвейеру DeltaCopyFromS3 и выберите Debug (Отладка), а затем введите значения в разделе Parameters (Параметры). Щелкните Готово.
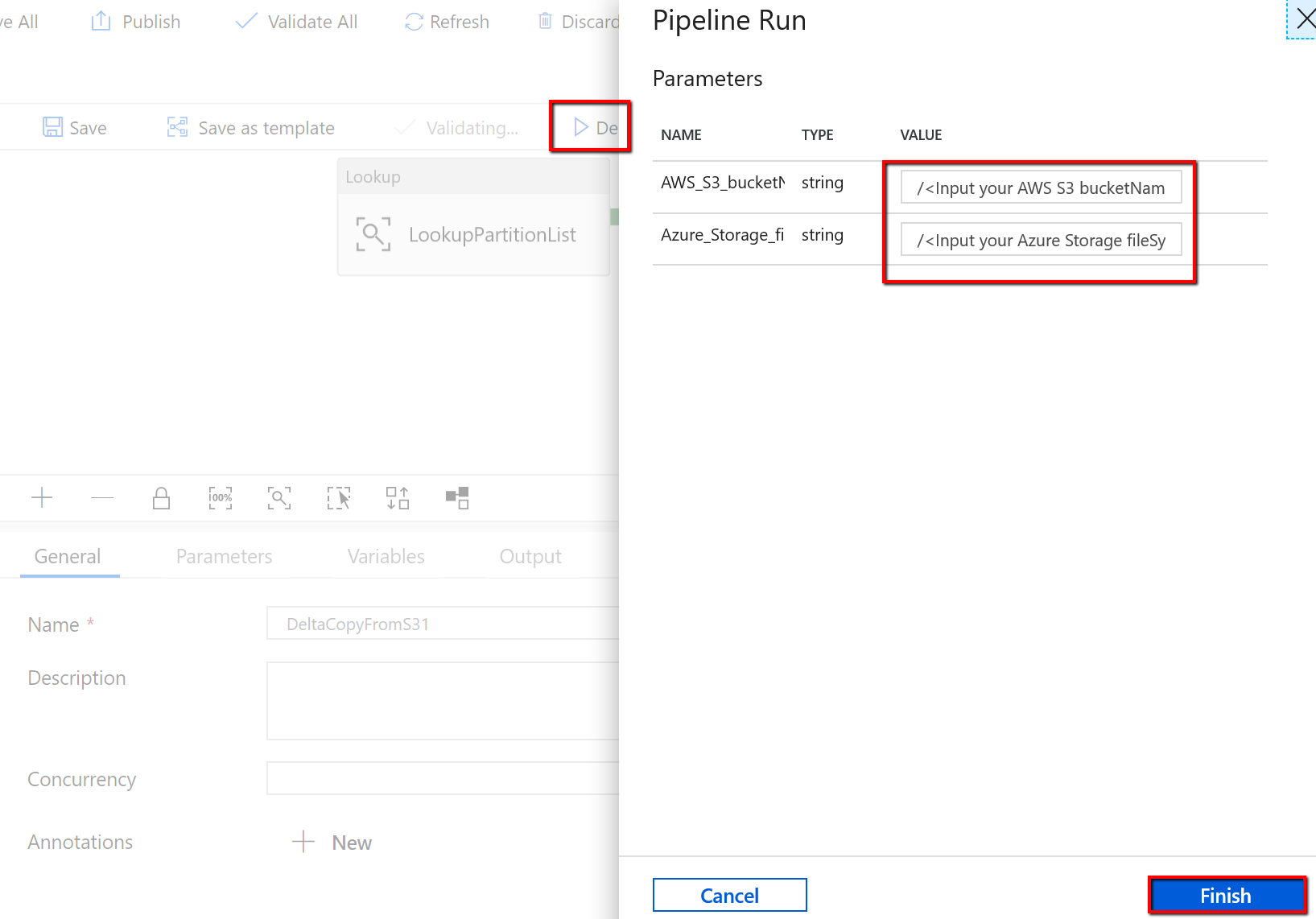
Вы увидите результат, аналогичный приведенному ниже:
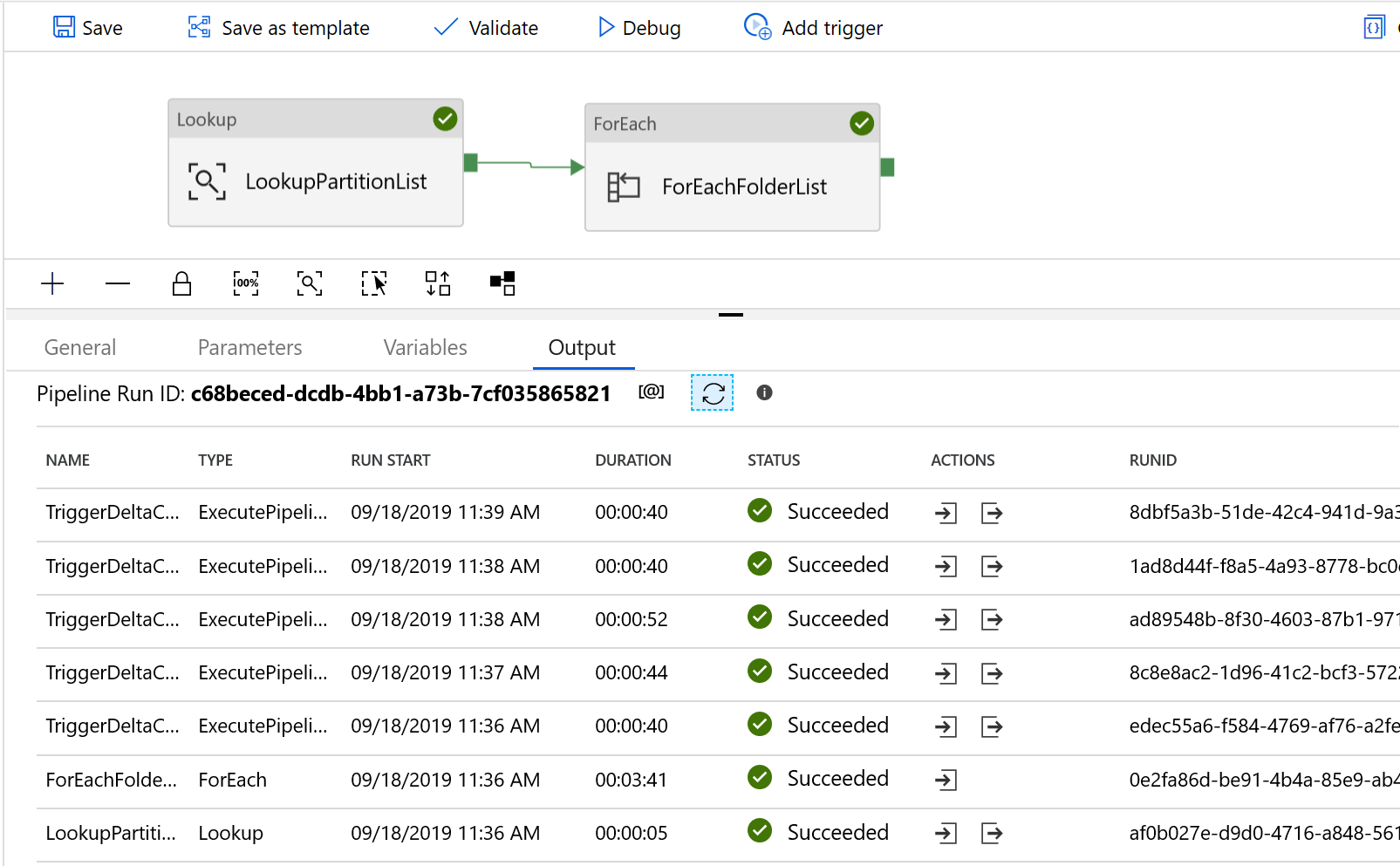
Вы также можете проверить результаты из управляющей таблицы с помощью запроса "select * from s3_partition_delta_control_table". Вы получите результат, как на приведенном ниже изображении.