Копирование нескольких таблиц в пакетном режиме с помощью Фабрики данных Azure на портале Azure
Область применения: Фабрика данных Azure Azure Synapse Analytics
Фабрика данных Azure Azure Synapse Analytics
Совет
Попробуйте использовать фабрику данных в Microsoft Fabric, решение для аналитики с одним интерфейсом для предприятий. Microsoft Fabric охватывает все, от перемещения данных до обработки и анализа данных в режиме реального времени, бизнес-аналитики и отчетности. Узнайте, как бесплатно запустить новую пробную версию !
В этом руководстве показано, как скопировать несколько таблиц из Базы данных SQL Azure в Azure Synapse Analytics. Этот подход можно применить и в других сценариях. Например, копирование таблиц из SQL Server или Oracle в Базу данных SQL Azure, Azure Synapse Analytics или большой двоичный объект Azure, копирование различных путей из большого двоичного объекта в таблицы Базы данных SQL Azure.
Примечание.
Если вы еще не работали с фабрикой данных Azure, ознакомьтесь со статьей Введение в фабрику данных Azure.
В целом это руководство включает следующие шаги:
- Создали фабрику данных.
- Создание экземпляров Базы данных SQL Azure, Azure Synapse Analytics и связанных служб хранилища Azure.
- Создание Базы данных SQL Azure и наборов данных Azure Synapse Analytics.
- Создание конвейера для поиска таблиц, которые нужно скопировать, и конвейера для выполнения операции копирования.
- Запуск конвейера.
- Мониторинг конвейера и выполнения действий.
В этом руководстве используется портал Azure. Сведения об использовании других средств или пакетов SDK для создания фабрики данных см. в этом кратком руководстве.
Комплексный рабочий процесс
Предположим, у вас есть несколько таблиц в Базе данных SQL Azure и вы хотите скопировать их в Azure Synapse Analytics. Вот логическая последовательность действий рабочего процесса в конвейерах:

- Первый конвейер ищет список таблиц, который необходимо скопировать в хранилище данных-приемник. В качестве альтернативы можно создать таблицу метаданных, в которой перечислены все таблицы, которые нужно скопировать в хранилище данных-приемник. Затем конвейер активирует другой конвейер, который выполняет итерацию по каждой таблице базы данных и выполняет операцию копирования данных.
- Второй конвейер выполняет фактическое копирование. Он принимает список таблиц в качестве параметра. Чтобы добиться лучшей производительности, для каждой таблицы в списке скопируйте определенную таблицу из Базы данных SQL Azure в соответствующую таблицу Azure Synapse Analytics, используя промежуточное копирование с помощью хранилища BLOB-объектов и PolyBase. В этом примере первый конвейер передает список таблиц в качестве значения параметра.
Если у вас нет подписки Azure, создайте бесплатную учетную запись, прежде чем приступить к работе.
Необходимые компоненты
- Учетная запись хранения Azure. Учетная запись хранения Azure используется в качестве промежуточного хранилища больших двоичных объектов в операции массового копирования.
- База данных SQL Azure. Эта база данных содержит исходные данные. Создайте базу данных в службе "База данных SQL", используя пример данных Adventure Works LT, представленный в статье о создании базы данных в службе "База данных SQL Azure". В этом учебнике все таблицы из этого примера базы данных копируются в Azure Synapse Analytics.
- Azure Synapse Analytics. Это хранилище данных содержит данные, копируемые из базы данных SQL. Если у вас нет рабочей области Azure Synapse Analytics, создайте ее по инструкциям из статьи Начало работы с Azure Synapse Analytics.
Доступ служб Azure к серверу SQL Server
В Базе данных SQL и Azure Synapse Analytics предоставьте службам Azure доступ к серверу SQL Server. Убедитесь, что параметру Разрешить доступ к серверу службам и ресурсам Azure задано состояние ВКЛ для вашего сервера. Этот параметр позволяет службе Фабрики данных читать данные из Базы данных SQL Azure и записывать их в Azure Synapse Analytics.
Чтобы проверить и при необходимости включить этот параметр, перейдите к серверу, выберите >Безопасность > Брандмауэры и виртуальные сети> и переведите параметр Разрешить доступ к серверу службам и ресурсам Azure в состояние ВКЛ.
Создание фабрики данных
Запустите веб-браузер Microsoft Edge или Google Chrome. Сейчас только эти браузеры поддерживают пользовательский интерфейс фабрики данных.
Переход на портал Azure.
На портале Azure в меню слева выберите Создать ресурс>Интеграция>Фабрика данных.
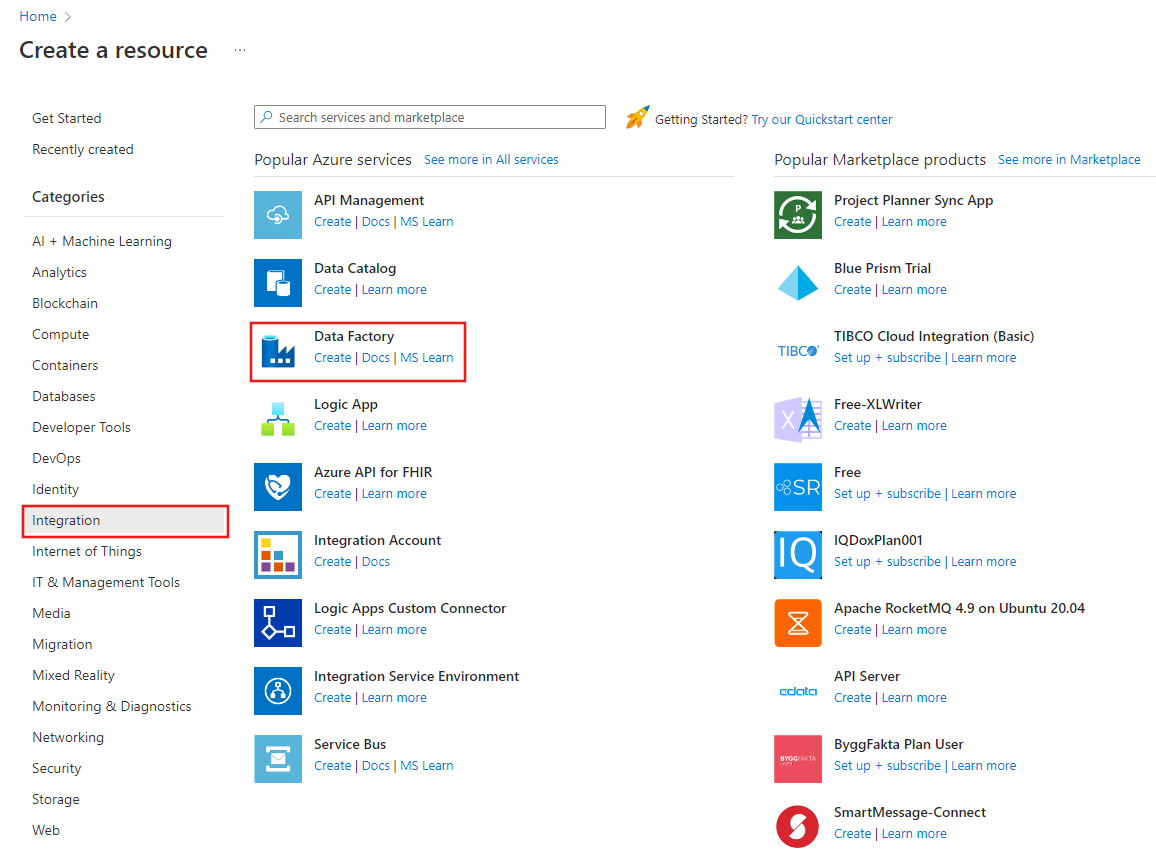
На странице Новая фабрика данных введите ADFTutorialBulkCopyDF в поле Имя.
Имя фабрики данных Azure должно быть глобально уникальным. Если вы увидите следующую ошибку для поля имени, введите другое имя фабрики данных (например, ваше_имя_ADFTutorialBulkCopyDF). Ознакомьтесь со статьей Фабрика данных Azure — правила именования, чтобы узнать правила именования для артефактов службы "Фабрика данных".
Data factory name "ADFTutorialBulkCopyDF" is not availableВыберите подписку Azure, в рамках которой вы хотите создать фабрику данных.
Для группы ресурсов выполните одно из следующих действий.
Выберите Использовать существующуюи укажите существующую группу ресурсов в раскрывающемся списке.
Выберите Создать новуюи укажите имя группы ресурсов.
Сведения о группах ресурсов см. в статье, где описывается использование групп ресурсов для управления ресурсами Azure.
Укажите V2 при выборе версии.
Укажите расположение фабрики данных. Чтобы получить список регионов Azure, в которых в настоящее время доступна Фабрика данных, выберите интересующие вас регионы на следующей странице, а затем разверните раздел Аналитика, чтобы найти пункт Фабрика данных: Доступность продуктов по регионам. Хранилища данных (служба хранилища Azure, база данных SQL Azure и т. д.) и вычисления (HDInsight и т. д.), используемые фабрикой данных, могут располагаться в других регионах.
Нажмите кнопку Создать.
Когда создание завершится, щелкните элемент Перейти к ресурсу, чтобы открыть страницу Фабрика данных.
Выберите Открыть на плитке Открыть Azure Data Factory Studio, чтобы запустить приложение пользовательского интерфейса Фабрики данных в отдельной вкладке.
Создание связанных служб
Связанная служба связывает хранилища данных и вычислительные ресурсы с фабрикой данных. Связанная служба содержит сведения о подключении, которые Фабрика данных использует для подключения к хранилищу данных в среде выполнения.
В этом руководстве вы создадите привязку к фабрике данных для Базы данных SQL Azure, Azure Synapse Analytics и Хранилища BLOB-объектов Azure. База данных Azure SQL используется в качестве исходного хранилища данных. Служба Azure Synapse Analytics выполняет роль целевого хранилища данных (назначения). Хранилище BLOB-объектов Azure временно хранит данные, чтобы передать их в Azure Synapse Analytics с помощью PolyBase.
Создание исходной связанной службы Базы данных SQL Azure
На этом шаге вы создадите связанную службу, чтобы связать базу данных в службе "База данных SQL Azure" с фабрикой данных.
Откройте вкладку Manage (Управление) на панели слева.
На странице связанных служб выберите +New (+Создать), чтобы создать связанную службу.
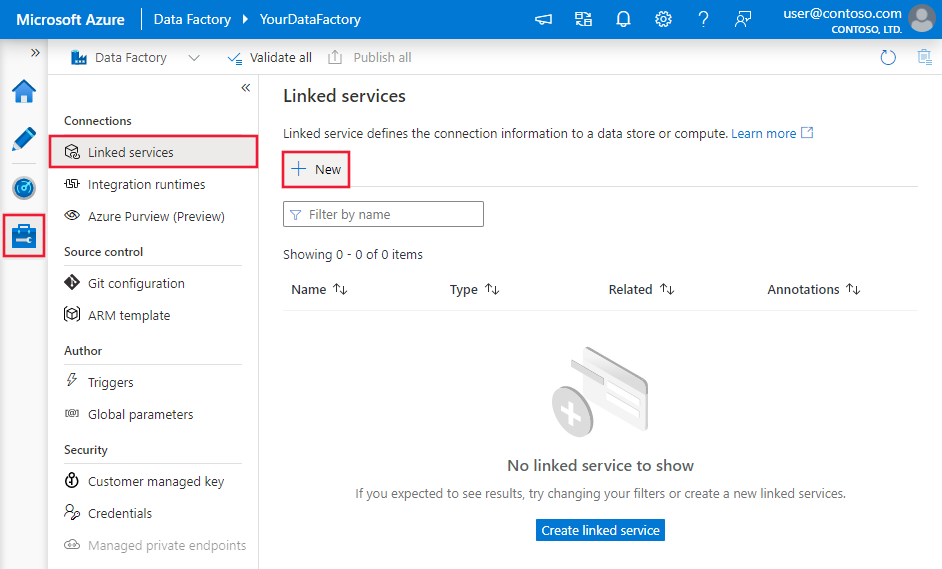
В окне New Linked Service (Новая связанная служба) выберите Azure SQL Database (База данных SQL Microsoft Azure) и щелкните Continue (Продолжить).
В окне New Linked Service (Azure SQL Database) (Новая связанная служба (База данных SQL Azure)) сделайте следующее:
a. Введите AzureSqlDatabaseLinkedService в поле Имя.
b. Выберите нужный сервер в списке Имя сервера.
c. Выберите нужную базу данных в списке Имя базы данных.
d. Введите имя пользователя для подключения к своей базе данных.
д) Введите пароль для этого пользователя.
f. Чтобы проверить подключение к своей базе данных с указанными данными, нажмите кнопку Проверить подключение.
ж. Щелкните Создать, чтобы сохранить связанную службу.
Создание приемника связанной службы Azure Synapse Analytics
На вкладке Подключения снова щелкните + Создать на панели инструментов.
В окне New Linked Service (Новая связанная служба) выберите Azure Synapse Analytics и щелкните Continue (Продолжить).
В окне New Linked Service (Azure Synapse Analytics) (Новая связанная служба) выполните следующие шаги.
a. Введите AzureSqlDWLinkedService в поле Имя.
b. Выберите нужный сервер в списке Имя сервера.
c. Выберите нужную базу данных в списке Имя базы данных.
d. Введите имя пользователя для подключения к своей базе данных.
д) Введите пароль для этого пользователя.
f. Чтобы проверить подключение к своей базе данных с указанными данными, нажмите кнопку Проверить подключение.
ж. Нажмите кнопку Создать.
Создание промежуточной связанной службы хранилища Azure
В этом руководстве хранилища BLOB-объектов Azure используются в качестве области промежуточного хранения, чтобы включить PolyBase для повышения производительности копирования.
На вкладке Подключения снова щелкните + Создать на панели инструментов.
В окне New Linked Service (Новая связанная служба) выберите хранилище BLOB-объектов Azure и щелкните Continue (Продолжить).
В окне New Linked Service (Azure Blob Storage) (Новая связанная служба (хранилище BLOB-объектов Azure)) выполните следующие действия:
a. Введите AzureStorageLinkedService в поле имени.
b. Выберите учетную запись хранения в списке Имя учетной записи хранения.c. Нажмите кнопку Создать.
Создайте наборы данных.
В этом руководстве вы создадите наборы данных источника и приемника, в которых указывается место хранения данных.
Исходный набор данных AzureSqlDatabaseDataset ссылается на службу AzureSqlDatabaseLinkedService. Связанная служба определяет строку подключения для подключения к базе данных. Набор данных указывает имена базы данных и таблицы, которые содержат исходные данные.
Целевой набор данных AzureSqlDWDataset ссылается на службу AzureSqlDWLinkedService. Связанная служба определяет строку подключения для подключения к Azure Synapse Analytics. Набор данных указывает имена базы данных и таблицы, в которую копируются данные.
В этом руководстве таблицы SQL для источника и назначения не заданы жестко в определениях наборов данных. Действие ForEach передает имена таблиц действию копирования во время выполнения.
Создание набора данных для исходной базы данных SQL
На панели слева откройте вкладку Автор.
Нажмите кнопку + (плюс) на панели слева и выберите Набор данных.
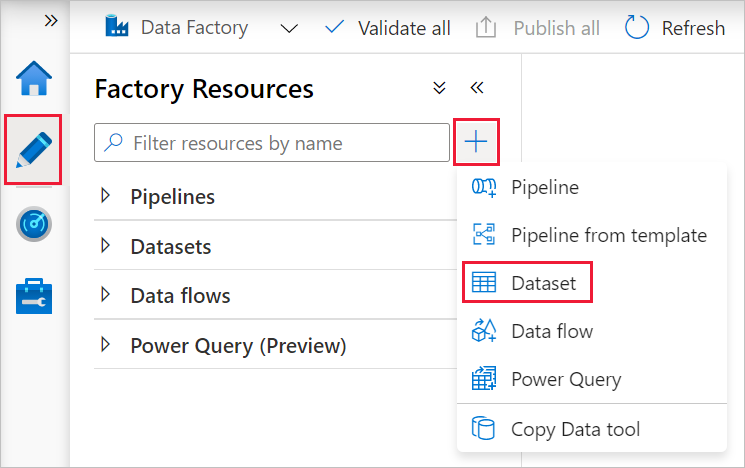
В окне Новый набор данных выберите База данных SQL Azure и нажмите кнопку Продолжить.
В окне Set properties (Установка свойств) в поле Имя введите AzureSqlDatabaseDataset. В разделе Связанная служба выберите AzureSqlDatabaseLinkedService. Затем нажмите кнопку ОК.
Перейдите на вкладку Подключение и выберите любую таблицу для параметра Таблица. Эта таблица используется в качестве заглушки. Реальный запрос к исходному набору данных будет указан отдельно при создании конвейера. Этот запрос нужен для извлечения данных из вашей базы данных. Или можно установить флажок Изменить и ввести произвольное имя таблицы, например dbo.dummyName.
Создание набора данных для приемника Azure Synapse Analytics
Нажмите кнопку + (плюс) на левой панели и выберите пункт Набор данных.
В окне Новый набор данных выберите Azure Synapse Analytics и щелкните Продолжить.
В окне Set properties (Установка свойств) в поле Имя введите AzureSqlDWDataset. В разделе Связанная служба выберите AzureSqlDWLinkedService. Затем нажмите кнопку ОК.
Перейдите на вкладку Параметры, щелкните +Создать и введите DWTableName в качестве имени параметра. Снова щелкните элемент + Создать и введите DWSchema в качестве имени параметра. Если вы копируете и вставляете имя со страницы, убедитесь в отсутствии пробела в конце имени DWTableName и DWSchema.
Перейдите на вкладку Подключение.
В разделе Таблица выберите действие Правка. Щелкните первое поле ввода и ссылку Добавить динамическое содержимое ниже. На странице Добавить динамическое содержимое щелкните DWSchema в разделе Параметры. Верхнее текстовое поле выражения будет автоматически заполнено значением
@dataset().DWSchema. Затем нажмите кнопку Готово.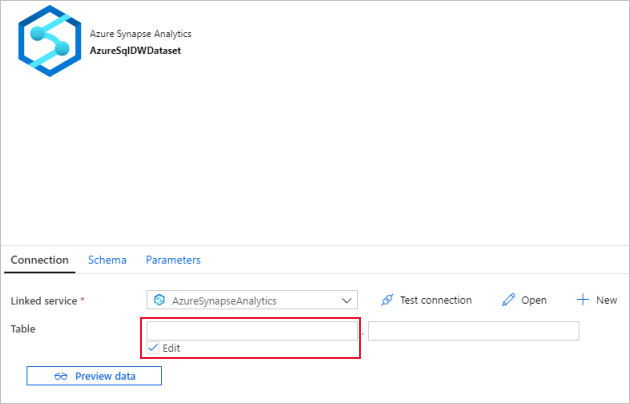
Щелкните второе поле ввода и ссылку Добавить динамическое содержимое ниже. На странице Добавить динамическое содержимое щелкните DWTAbleName в разделе Параметры. Сверху в текстовом поле выражения будет автоматически указано значение
@dataset().DWTableName. Затем нажмите кнопку Готово.В свойстве TableName для набора данных укажите значения, которые передаются в качестве аргументов для параметров DWSchema и DWTableName. Действие ForEach последовательно перебирает список таблиц и по одной передает их действию копирования.
Создание конвейеров
В этом руководстве вы создадите два конвейера: IterateAndCopySQLTables и GetTableListAndTriggerCopyData.
Конвейер GetTableListAndTriggerCopyData выполняет два действия.
- Ищет системную таблицу базы данных SQL Azure, чтобы получить список таблиц для копирования.
- Активирует конвейер IterateAndCopySQLTables для копирования данных.
Конвейер IterateAndCopySQLTables принимает список таблиц в качестве параметра. Для каждой таблицы в списке он копирует данные из таблицы в Базе данных SQL Azure в Azure Synapse Analytics с помощью промежуточного копирования и PolyBase.
Создание конвейера IterateAndCopySQLTables
На левой панели нажмите кнопку + (плюс) и выберите пункт Конвейер.
На общей панели в разделе Свойства укажите значение IterateAndCopySQLTables для параметра Имя. Затем сверните панель, щелкнув значок Свойства в правом верхнем углу.
Перейдите на вкладку Параметры и выполните здесь следующие действия.
a. Щелкните + Создать.
b. Введите значение tableList в качестве имени параметра.
c. Выберите Массив в столбце Тип.
На панели элементов Действия разверните Iteration & Conditions (Итерация и условия), затем перетащите действие ForEach в область конструктора конвейера. Также на панели элементов Действия можно применить поиск.
a. На вкладке Общие внизу введите значение IterateSQLTables в поле Имя.
b. Перейдите на вкладку Параметры, щелкните поле для ввода элементов и щелкните ссылку Добавить динамическое содержимое ниже.
c. На странице Добавление динамического содержимого сверните разделы Системные переменные и Функции и щелкните tableList в разделе Параметры. Верхнее текстовое поле выражения будет автоматически заполнено значением
@pipeline().parameter.tableList. Нажмите кнопку Готово.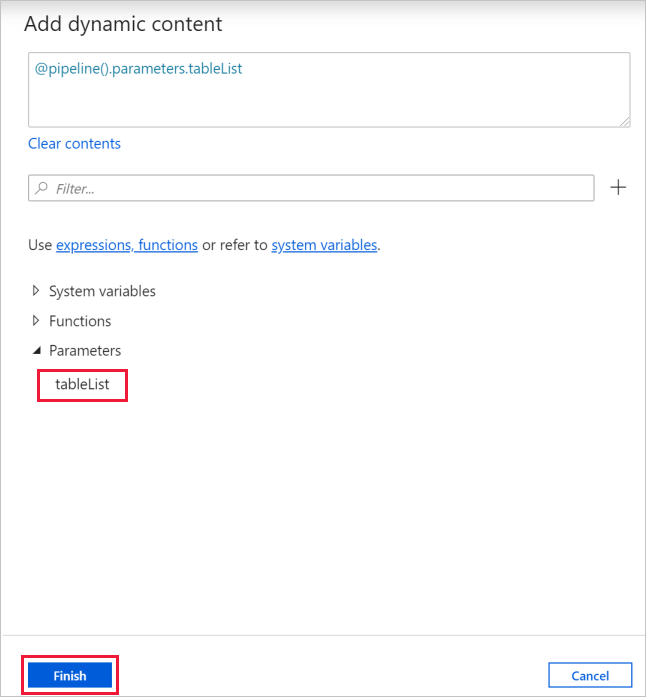
d. Перейдите на вкладку Действия, щелкните значок карандаша, чтобы добавить дочернее действие к действию ForEach.
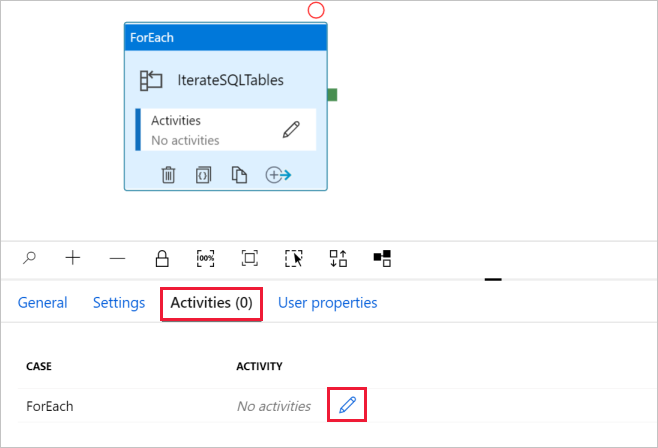
На панели элементов Действия разверните узел Move & Transfer (Перемещение и передача) и перетащите действие Копирование данных в область конструктора конвейера. Обратите внимание на строку навигации вверху. Здесь IterateAndCopySQLTable — это имя конвейера, а IterateSQLTables — имя действия ForEach. Конструктор находится в области действия. Чтобы снова переключиться в редактор конвейера из редактора ForEach, можно щелкнуть ссылку в этом меню навигации.
Перейдите на вкладку Источник и выполните здесь следующие действия:
Выберите AzureSqlDatabaseDataset в списке Source Dataset (Исходный набор данных).
Выберите вариант Запрос для параметра Использовать запрос.
Щелкните поле ввода Запрос, выберите Добавить динамическое содержимое ниже, введите указанное ниже выражение в качестве запроса и выберите Готово.
SELECT * FROM [@{item().TABLE_SCHEMA}].[@{item().TABLE_NAME}]
Перейдите на вкладку Приемник и выполните здесь следующие действия:
Выберите AzureSqlDWDataset в списке Sink Dataset (Целевой набор данных).
Щелкните поле ввода для значения VALUE параметра DWTableName, выберите Добавить динамическое содержимое ниже, введите выражение
@item().TABLE_NAMEв качестве скрипта и выберите Готово.Щелкните поле ввода для значения VALUE параметра DWSchema, выберите Добавить динамическое содержимое ниже, введите выражение
@item().TABLE_SCHEMAв качестве скрипта и выберите Готово.Для метода "Копирование" выберите значение PolyBase.
Снимите флажок Use type default (Использовать значение по умолчанию для типа).
Для параметра "Таблица" по умолчанию установлено значение "Нет". Если у вас нет предварительно созданных в приемнике Azure Synapse Analytics таблиц, включите параметр Auto create table (Автоматическое создание таблицы). После этого с помощью действия копирования будут автоматически созданы таблицы на основе исходных данных. Дополнительные сведения см. в разделе Автоматическое создание таблиц в приемнике.
Щелкните поле ввода Скрипт предварительного копирования, выберите Добавить динамическое содержимое ниже, введите указанное ниже выражение в качестве скрипта и выберите Готово.
IF EXISTS (SELECT * FROM [@{item().TABLE_SCHEMA}].[@{item().TABLE_NAME}]) TRUNCATE TABLE [@{item().TABLE_SCHEMA}].[@{item().TABLE_NAME}]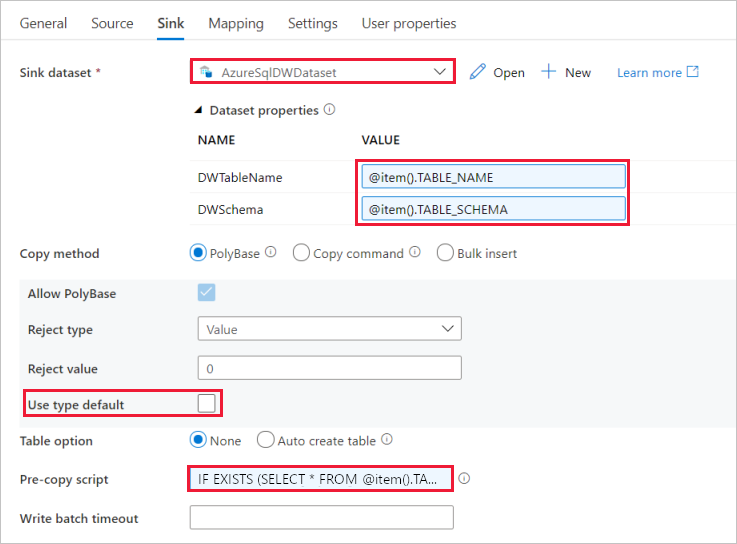
Перейдите на вкладку Настройки и выполните здесь следующие действия:
- Установите флажок напротив Enable Staging (Включить промежуточный режим).
- Выберите AzureStorageLinkedService в списке Store Account Linked Service (Связанная служба учетной записи хранилища).
Чтобы проверить параметры конвейера, щелкните Проверить на панели инструментов для этого конвейера. Убедитесь, что проверка завершается без ошибок. Чтобы закрыть отчет о проверке конвейера, нажмите кнопку с двойными угловыми скобками (>>).
Создание конвейера GetTableListAndTriggerCopyData
Этот конвейер выполняет два действия.
- Ищет системную таблицу базы данных SQL Azure, чтобы получить список таблиц для копирования.
- Активирует конвейер IterateAndCopySQLTables для выполнения копирования данных.
Вот как создать конвейер:
На левой панели нажмите кнопку + (плюс) и выберите пункт Конвейер.
На панели "Общие" в разделе Свойства укажите имя конвейера GetTableListAndTriggerCopyData.
На панели Действия разверните элемент Общие и перетащите действие Поиск в область конструктора конвейера, а затем выполните следующие действия:
- Введите LookupTableList в качестве значения для параметра Имя.
- Введите Получение списка таблиц из моей базы данных в поле Описание.
Перейдите на вкладку Настройки и выполните здесь следующие действия:
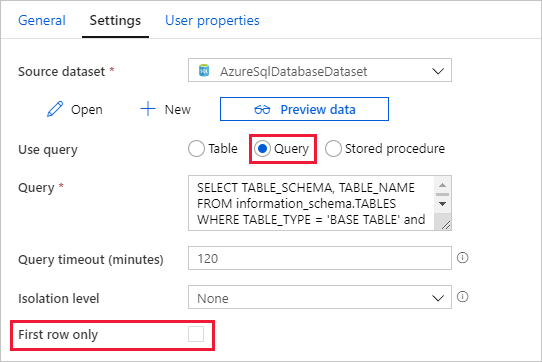
Выберите AzureSqlDatabaseDataset в списке Source Dataset (Исходный набор данных).
Выберите Запрос в списке Использовать запрос.
Введите следующий запрос SQL в поле Запрос.
SELECT TABLE_SCHEMA, TABLE_NAME FROM information_schema.TABLES WHERE TABLE_TYPE = 'BASE TABLE' and TABLE_SCHEMA = 'SalesLT' and TABLE_NAME <> 'ProductModel'Снимите флажок для поля First row only (Только первая строка).
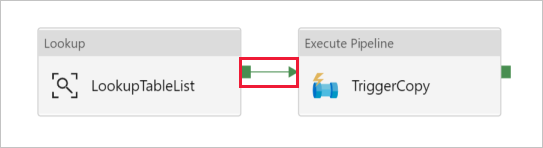
Перетащите действие Execute Pipeline (Выполнить конвейер) из панели элементов "Действия" в область конструктора конвейера и задайте для него имя TriggerCopy.
Чтобы подключить действие Поиск к действию Execute Pipeline (Выполнение конвейера), перетащите зеленое поле от действия поиска к действию выполнения конвейера слева.
Перейдите на вкладку Настройки для действия Выполнение конвейера и сделайте следующее.
Выберите IterateAndCopySQLTables в списке Вызываемый конвейер.
Снимите флажок напротив элемента Ожидать завершения.
В разделе Параметры щелкните поле ввода под элементом "Значение". Выберите Добавить динамическое содержимое ниже и введите
@activity('LookupTableList').output.valueв качестве значения имени таблицы. Нажмите кнопку Готово. Теперь список результатов, полученных от действия поиска, будет использоваться как входные данные для второго конвейера. Список результатов содержит список таблиц, данные которых нужно скопировать в место назначения.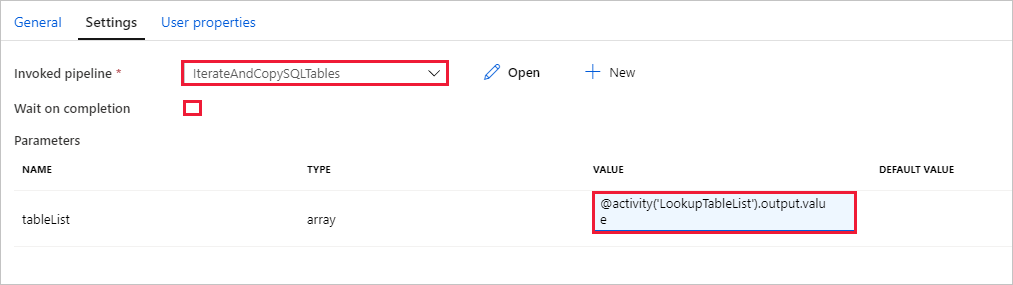
Чтобы проверить работу конвейера, нажмите кнопку Проверка на панели инструментов. Убедитесь, что проверка завершается без ошибок. Чтобы закрыть отчет о проверке конвейера, нажмите кнопку >>.
Чтобы опубликовать сущности (наборы данных, конвейеры и т. д.) в службе "Фабрика данных", щелкните Опубликовать все в верхней части окна. Подождите, пока публикация успешно завершится.
Активация выполнения конвейера
Перейдите к конвейеру GetTableListAndTriggerCopyData, щелкните Добавить триггер на панели инструментов для конвейера вверху и выберите Trigger Now (Активировать сейчас).
На странице Выполнение конвейера подтвердите выполнение и щелкните Готово.
Мониторинг конвейера
Перейдите на вкладку "Монитор ". Нажимайте кнопку " Обновить" , пока не увидите выполнение обоих конвейеров в решении. Продолжайте обновлять отображение списка, пока не отобразится состояние Успешно.
Чтобы просмотреть запуски действий, связанные с конвейером GetTableListAndTriggerCopyData, щелкните ссылку, назначенную для имени этого конвейера. Вы увидите два запуска действий для этого запуска конвейера.
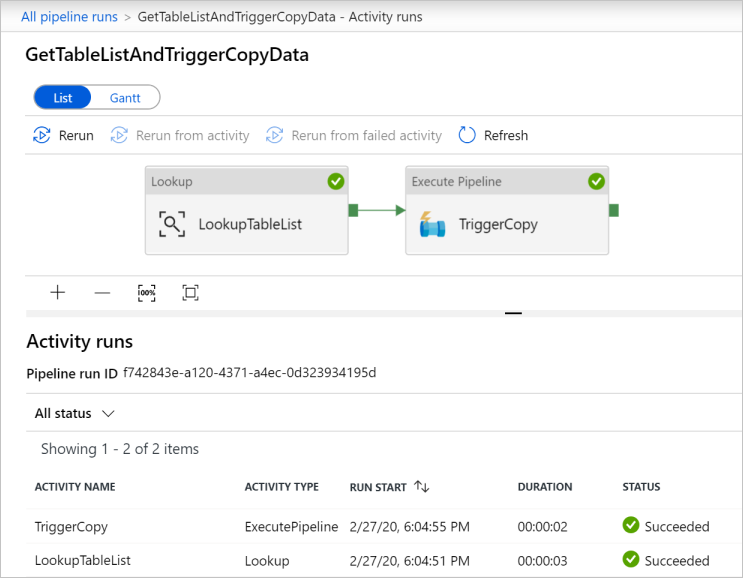
Чтобы просмотреть выходные данные действия Поиск, щелкните ссылку Выходные данные рядом с этим действием в столбце ИМЯ ДЕЙСТВИЯ. Окно Выходные данные можно развернуть и восстановить. Завершив просмотр, нажмите кнопку X, чтобы закрыть окно Выходные данные.
{ "count": 9, "value": [ { "TABLE_SCHEMA": "SalesLT", "TABLE_NAME": "Customer" }, { "TABLE_SCHEMA": "SalesLT", "TABLE_NAME": "ProductDescription" }, { "TABLE_SCHEMA": "SalesLT", "TABLE_NAME": "Product" }, { "TABLE_SCHEMA": "SalesLT", "TABLE_NAME": "ProductModelProductDescription" }, { "TABLE_SCHEMA": "SalesLT", "TABLE_NAME": "ProductCategory" }, { "TABLE_SCHEMA": "SalesLT", "TABLE_NAME": "Address" }, { "TABLE_SCHEMA": "SalesLT", "TABLE_NAME": "CustomerAddress" }, { "TABLE_SCHEMA": "SalesLT", "TABLE_NAME": "SalesOrderDetail" }, { "TABLE_SCHEMA": "SalesLT", "TABLE_NAME": "SalesOrderHeader" } ], "effectiveIntegrationRuntime": "DefaultIntegrationRuntime (East US)", "effectiveIntegrationRuntimes": [ { "name": "DefaultIntegrationRuntime", "type": "Managed", "location": "East US", "billedDuration": 0, "nodes": null } ] }Чтобы вернуться к представлению Запуски конвейера, выберите ссылку All Pipeline Runs (Все запуски конвейера). Щелкните ссылку IterateAndCopySQLTables (она расположена в столбце ИМЯ КОНВЕЙЕРА), чтобы просмотреть выполнения действий для этого конвейера. Обратите внимание, что здесь отображается одно действие копирования для каждой таблицы из выходных данных действия Поиск.
Убедитесь, что нужные данные скопированы в целевую службу Azure Synapse Analytics, которую вы использовали при прохождении этого учебника в качестве приемника.
Связанный контент
В этом руководстве вы выполнили следующие шаги:
- Создали фабрику данных.
- Создание экземпляров Базы данных SQL Azure, Azure Synapse Analytics и связанных служб хранилища Azure.
- Создание Базы данных SQL Azure и наборов данных Azure Synapse Analytics.
- Создание конвейера для поиска таблиц, которые нужно скопировать, и конвейера для выполнения операции копирования.
- Запуск конвейера.
- Мониторинг конвейера и выполнения действий.
Перейдите к следующему руководству, чтобы узнать о копировании данных по шагам из источника в место назначения: