Использование обозревателя и представления заданий Azure Data Lake Analytics
Важно!
Поддержка Azure Data Lake Analytics прекращена 29 февраля 2024 г. Дополнительные сведения см. в этом объявлении.
Для аналитики данных ваша организация может использовать Azure Synapse Analytics или Microsoft Fabric.
Служба Azure Data Lake Analytics архивирует отправленные задания в хранилище запросов. В этой статье вы узнаете, как использовать браузер и представление заданий в средствах Azure Data Lake для Visual Studio, чтобы находить исторические сведения о заданиях.
По умолчанию служба Data Lake Analytics архивирует задания на 30 дней. Срок хранения можно настроить на портале Azure в настраиваемой политике окончания срока действия. После истечения срока действия вы не сможете получить доступ к сведениям о задании.
Предварительные требования
См. раздел о предварительных требованиях в отношении средств Data Lake для Visual Studio.
Доступ к браузеру заданий
Откройте обозреватель заданий через сервер Обозреватель> Azure> Data Lake Analytics> Jobs в Visual Studio. С помощью браузера заданий можно получить доступ к хранилищу запросов учетной записи Data Lake Analytics. В браузере заданий слева отображается хранилище запросов, в котором видны базовые сведения о задании, а справа — представление задания с подробными сведениями о задании.
Представление задания
В представлении задания отображаются подробные сведения о задании. Чтобы открыть задание, дважды щелкните его в браузере или откройте его из меню Data Lake, щелкнув пункт Job View ("Представление задания"). Вы увидите диалоговое окно с URL-адресом задания.
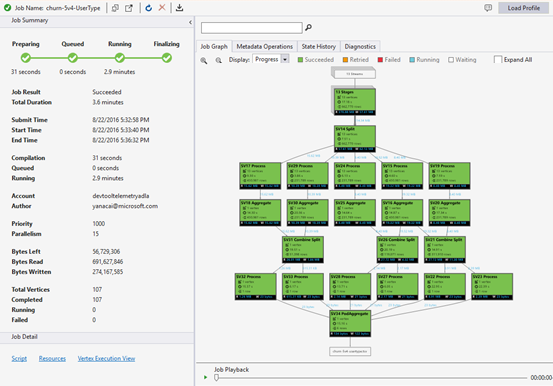
Представление задания содержит:
Сводные данные задания
Обновите представление заданий, чтобы просмотреть более свежие сведения о выполнении заданий.
Состояние задания (граф).
На графе "Состояние задания" отображаются основные этапы задания:
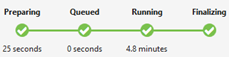
Подготовка. Загрузите скрипт в облако, компилировав и оптимизировав сценарий с помощью службы компиляции.
В очереди: задания помещаются в очередь, когда они ожидают достаточно ресурсов или задания превышают максимальное количество одновременных заданий на учетную запись. Параметр приоритета определяет последовательность постановки заданий в очередь: чем меньше число, тем выше приоритет.
Выполняется. Задание выполняется в учетной записи Data Lake Analytics.
Завершение. Задание завершается (например, завершение работы с файлом).
На любом этапе может произойти сбой задания, например ошибка компиляции на этапе подготовки, истечения времени ожидания на этапе "В очереди" или выполнения на этапе "Выполняется" и т. д.
Основные сведения
В нижней части панели "Сводка по заданию" отображаются основные сведения о задании.
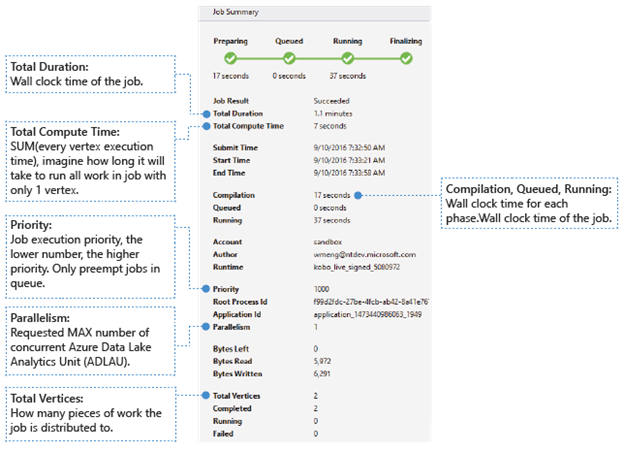
- Job Result ("Результат задания"). "Успешно" или "Сбой". Задание может завершиться ошибкой на каждом этапе.
- Total Duration ("Общая длительность"). Время с момента отправки и до момента завершения по часам (длительность).
- Total Compute Time ("Общее время вычислений"). Сумма количества времени, затраченного на выполнение каждой вершины. Его можно учитывать как время выполнения задания только с одной вершиной. Дополнительные сведения о вершинах см. в данных о параметре Total Vertices ("Общее количество вершин").
- Submit Time ("Время отправки"), "Время начала" и "Время окончания". Время, когда служба Data Lake Analytics получила задание, начала его выполнение и успешно или с ошибкой завершила задание.
- Compilation ("Компиляция"), "В очереди" и "Выполняется". Время, затраченное на фазу "Подготовка", "В очереди" и "Выполняется" по часам.
- Учетная запись. Учетная запись Data Lake Analytics, использованная для запуска задания.
- Автор. Пользователь, отправивший задание, используя учетную запись реального пользователя или системную запись.
- Приоритет. Приоритет задания. Чем меньше число, тем выше приоритет. Он влияет только на последовательность заданий в очереди. Установка более высокого приоритета не приводит к вытесению выполняемых заданий.
- Параллелизм. Максимальное количество одновременно используемых единиц Azure Data Lake Analytics, которые еще называются вершинами. В настоящее время одна вершина равна одной виртуальной машине с двумя виртуальными ядрами и шестью ГБ ОЗУ, хотя это может быть обновлено в будущих Data Lake Analytics обновлениях.
- Bytes Left ("Оставшееся количество байтов"). Байты, которые необходимо обработать, чтобы завершить выполнение задания.
- Bytes read ("Прочитанные байты") и Bytes written ("Записанные байты"). Количество байтов, прочитанных или записанных с начала выполнения задания.
- Total vertices ("Общее количество вершин"). Задание разбивается на множество рабочих частей, каждая из которых называется вершиной. Это значение указывает, из скольких рабочих частей состоит задание. Вершину можно рассматривать как основную единицу обработки, которую еще называют единицей Azure Data Lake Analytics. Вершины могут выполняться параллельно.
- "Завершено", "Выполняется", "Сбой". Количество завершенных, выполняемых вершин и вершин со сбоем. Сбой вершины может происходить из-за ошибки в коде пользователя и системе, но через некоторое время система автоматически выполняет повторную попытку выполнить такие вершины. Если после повторной попытки все равно произошел сбой, происходит сбой всего задания.
Граф задания.
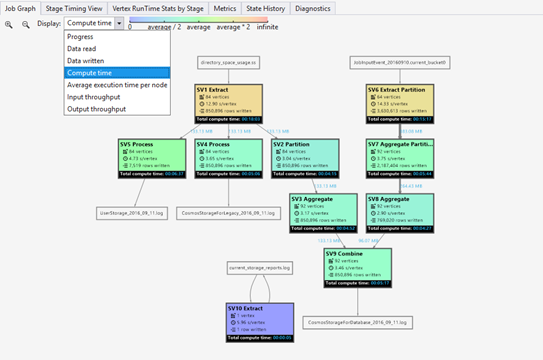
Скрипт U-SQL представляет логику преобразования входных данных в выходные. Скрипт компилируется и оптимизируется в виде плана физического выполнения на этапе подготовки. На графе задания показан план физического выполнения. На схеме ниже показан соответствующий процесс:
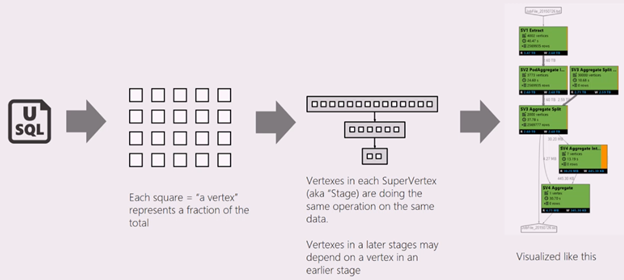
Задание разбивается на множество рабочих частей. Каждая рабочая часть называется вершиной. Вершины группируются в качестве супервершин (также называемых стадиями) и визуализируются в виде графа задания. Зеленые таблички на графе задания представляют собой стадии.
Каждая вершина стадии предусматривает аналогичные действия с различными частями одних и тех же данных. Например, если у вас есть файл с данными за один ТБ и из него считываются сотни вершин, каждая из них считывает фрагмент. Эти вершины группируются на одном этапе и выполняют одинаковую работу над разными частями одного входного файла.
-
В зависимости от стадии на табличках появляются цифры.
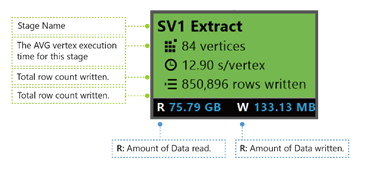
SV1 Extract. Имя стадии, указанное согласно номеру и операционному методу.
84 vertices ("84 вершины"). Общее число вершин на этом этапе. На рисунке показано, сколько фрагментов работ разделено на этом этапе.
12.90 s/vertex ("12,9 с/вершина"). Среднее время выполнения вершины для конкретной стадии. На этом рисунке показаны данные, вычисленные на основе суммы (времени выполнения каждой вершины), разделенной на общее число вершин. Это значит, что если назначено параллельное выполнение всех вершин, вся стадия завершится за 12,9 с. Это также значит, что если всю работу на этом этапе выполнять последовательно, время можно рассчитать, умножив количество вершин на среднее время.
850,895 rows written ("Записаны 850 895 строк"). Общее число строк, записанных на этой стадии.
R ("Ч") и W ("З"). Объем данных, прочитанных и записанных на этом этапе, в байтах.
Цвета. Чтобы указать состояние различных вершин используются разные цвета.
- Зеленый цвет значит, что вершина успешно выполнена.
- Оранжевый цвет обозначает повторную попытку выполнения вершины. Произошел сбой вершины, но автоматически предпринята повторная попытка выполнить вершину, которая успешно завершилась, как и вся стадия. Если после повторной попытки произошел сбой, используется красный цвет и происходит сбой всего задания.
- Красный цвет указывает на сбой. Это значит, что в системе выполнено несколько повторных попыток для определенной вершины, но все они завершились сбоем. При таком сценарии происходит сбой всего задания.
- Синий цвет значит, что вершина выполняется.
- Белый цвет значит, что вершина пребывает в состоянии ожидания. Вершина может ждать, чтобы быть запланирована после того, как ADLAU станет доступной, или она может ожидать входных данных, так как ее входные данные могут быть не готовы.
Дополнительные сведения о стадии можно увидеть, наведя курсор мыши на одну из стадий:
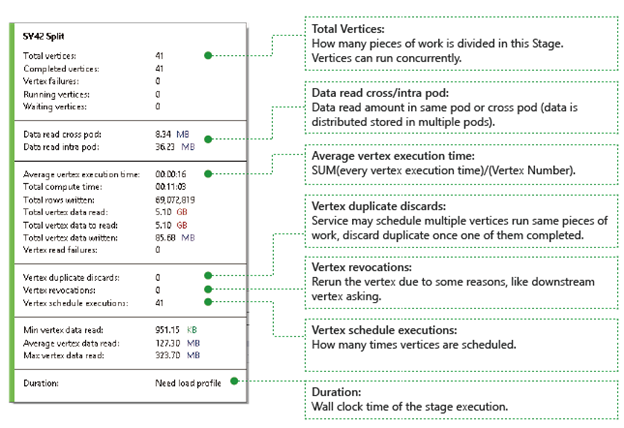
Вершины. Подробные сведения о вершинах, такие как их общее количество, количество завершенных вершин, вершин со сбоем, выполняемых вершин, вершин в ожидания и т. д.
Data read cross pod ("Данные из одного модуля, прочитанные в другом") и Data read intra pod ("Данные прочитанные в пределах модуля"). Файлы и данные, хранящиеся в нескольких модулях в распределенной файловой системе. Эти значения обозначают объем данных, прочитанных в одном модуле и межу модулями.
Total Compute Time ("Общее время вычислений"). Сумма количества времени, затраченного на выполнение каждой вершины на стадии. Его можно учитывать как время выполнения всей работы на стадии только с одной вершиной.
Data and rows written ("Записанные данные и строки") и Data and rows read ("Прочтенные данные и строки"). Указывают, сколько данных или строк прочитаны, записаны или необходимо прочитать.
Vertex read failures ("Сбои чтения вершин"). Количество вершин, для которых произошел сбой при чтении данных.
Удаление дубликатов вершин. Если вершина выполняется слишком медленно, система может запланировать несколько вершин для выполнения одного и того же фрагмента работы. Избыточные вершины будут удалены после успешного завершения одной из вершин. Счетчик отмены повторяющихся вершин записывает число вершин, удаленных из-за повторения на стадии.
Vertex revocations ("Отзывы вершин"). Количество вершин, выполненных успешно, но по некоторым причинам запущенных повторно. Например, если подчиненная вершина утратит промежуточные входные данные, будет предложено снова запустить вышестоящую вершину.
Выполненные расписания вершин. Общее время запланированных вершин.
Min Vertex data read ("Минимальный объем прочтенных данных"), Average Vertex data read ("Средний объем прочтенных данных"), Max Vertex data read ("Максимальный объем прочтенных данных"). Минимальный, средний и максимальный объем прочтенных данных каждой вершины.
Длительность. Время, необходимое для выполнения стадии, по часам. Чтобы просмотреть это значение, необходимо загрузить профиль.
Воспроизведение задания
Data Lake Analytics выполняет задания и архивирует сведения о вершинах, выполняемые заданиями, например, когда вершины запущены, остановлены, завершились сбоем, как они повторно выполнялись и т. д. Вся информация автоматически регистрируется в хранилище запросов и сохраняется в профиле задания. Профиль задания можно скачать, нажав кнопку Load Profile ("Загрузить профиль"), после чего можно просматривать воспроизведение задания.
Воспроизведение задания — это уменьшенная визуализация событий, произошедших в кластере. Она позволяет наблюдать за выполнением задания и быстро (менее чем за 30 секунд) визуально обнаруживать аномалии производительности и узкие места.
Отображение тепловой карты задания
Тепловую карту задания можно выбрать в раскрывающемся меню Display ("Отображение") на графе задания.
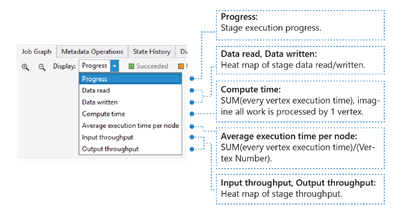
Здесь показываются данные о вводе-выводе, тепловая карта времени и пропускной способности задания, на основе которой можно определить, какая часть занимает больше времени и есть ли в задании ограничение ввода-вывода и т. д.
- Ход выполнения. Выполнение задания, дополнительные сведения см. в информации стадии.
- Data read ("Прочитанные данные"), Data written ("Записанные данные"). Тепловая карта общего объема данных, записанных или прочитанных на каждой стадии.
- Время вычислений. Тепловая карта SUM (время выполнения каждой вершины) можно рассматривать как продолжительность, если вся работа на этапе выполняется только с одной вершиной.
- Average execution time per node ("Среднее время выполнения для каждого узла"). Тепловая карта суммы (времени выполнения каждой вершины), разделенной на число вершин. Это значит, что если назначено параллельное выполнение всех вершин, вся стадия будет выполнена за этот промежуток времени.
- Input throughput ("Пропускная способность ввода") и Output throughput ("Пропускная способность вывода"). Тепловая карта пропускной способности ввода и вывода каждой стадии. Она позволяет узнать, есть ли в задании ограничение ввода-вывода.
-
Metadata Operations ("Операции с метаданными").
Вы можете выполнять в скрипте U-SQL некоторые операции с метаданными, такие как создание базы данных, удаление таблицы и т. д. Эти операции отображаются на вкладке "Операции с метаданными" после компиляции. Здесь можно найти утверждения, создать сущности и удалить сущности.

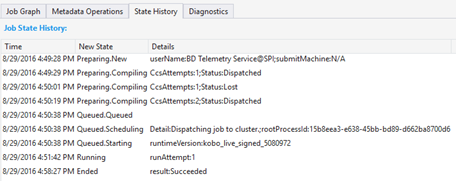
State History ("Журнал состояний").
На панели "Сводка по заданию" также отображается вкладка State History ("Журнал состояний"). Здесь можно получить дополнительные сведения, такие как время подготовки задания, его постановки в очередь, запуска и завершения. Здесь также можно узнать, сколько раз скомпилировано задание (CcsAttempts:1) и когда оно фактически отправлено в кластер (Detail: Dispatching job to cluster) и т. д.
Диагностика
Это средство автоматически диагностирует выполнение задания. Вы будете получать оповещения при возникновении ошибок или проблем с производительностью в заданиях. Обратите внимание, что необходимо загрузить профиль, чтобы здесь можно было получить полную информацию.
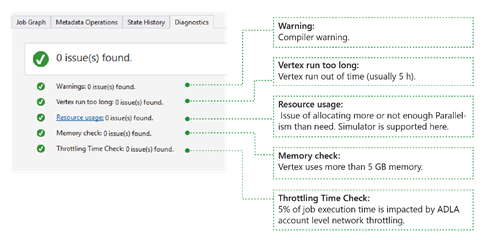
- Warnings ("Предупреждения"). Здесь отображаются оповещения с предупреждениями компилятора. Вы можете щелкнуть ссылку "X issue(s)", чтобы получить дополнительные сведения после появления оповещения.
- Вершина работает слишком долго: если какая-либо вершина закончится время (скажем, 5 часов), проблемы будут найдены здесь.
- Resource usage ("Использование ресурсов"). Если для параметра "Параллелизм" установлено значение меньше или больше, чем необходимое, эта проблема будет указана здесь. Кроме того, вы можете выбрать Использование ресурсов, чтобы просмотреть дополнительные сведения и выполнить сценарии "что если", чтобы найти лучшее распределение ресурсов (дополнительные сведения см. в этом руководстве).
- Memory check ("Проверка памяти"). Если какая-либо вершина использует более 5 ГБ памяти, эта проблема будет отображаться здесь. Выполнение задания может быть завершено системой, если оно использует больше памяти, чем системные ограничения.
Job Detail ("Сведения о задании").
В разделе сведений о задании отображаются подробные данные о задании, в том числе скрипт, ресурсы и представление выполнения вершин.
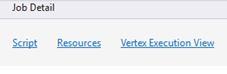
Скрипт
Скрипт U-SQL задания, содержащийся в хранилище запросов. Вы можете просмотреть исходный скрипт U-SQL и повторно отправить его при необходимости.
Ресурсы
Выходные данные компиляции задания, содержащиеся в хранилище запросов в разделе ресурсов. Например, здесь вы можете найти файл algebra.xml, который используется для отображения графа задания, зарегистрированных сборок и т. п.
Представление выполнения вершин.
Здесь показываются сведения о выполнении вершин. Профиль задания архивирует каждый журнал выполнения вершин, например сведения об общем объеме считанных и записанных данных, среде выполнения, состоянии и т. д. В этом представлении приводятся дополнительные сведения о выполнении задания. Дополнительные сведения см. в статьеИспользование представления выполнения вершин в инструментах Data Lake для Visual Studio.
Next Steps
- Сведения о том, как записывать диагностические данные в журнал, см. в статье Доступ к журналам диагностики для Azure Data Lake Analytics.
- Более сложный запрос можно посмотреть в статье Анализ журналов веб-сайта с помощью аналитики озера данных Azure.
- Дополнительные сведения см. в статье Использование представления выполнения вершин в инструментах Data Lake для Visual Studio.