Общие сведения о рабочих процессах Azure Databricks
Рабочие процессы Azure Databricks оркеструет обработку данных, машинное обучение и конвейеры аналитики на платформе Аналитики данных Databricks. Рабочие процессы имеют полностью управляемые службы оркестрации, интегрированные с платформой Databricks, включая задания Azure Databricks для запуска неинтерактивного кода в рабочей области Azure Databricks и разностных динамических таблиц для создания надежных и поддерживаемых конвейеров ETL.
Дополнительные сведения о преимуществах оркестрации рабочих процессов с помощью платформы Databricks см. в разделе "Рабочие процессы Databricks".
Пример рабочего процесса Azure Databricks
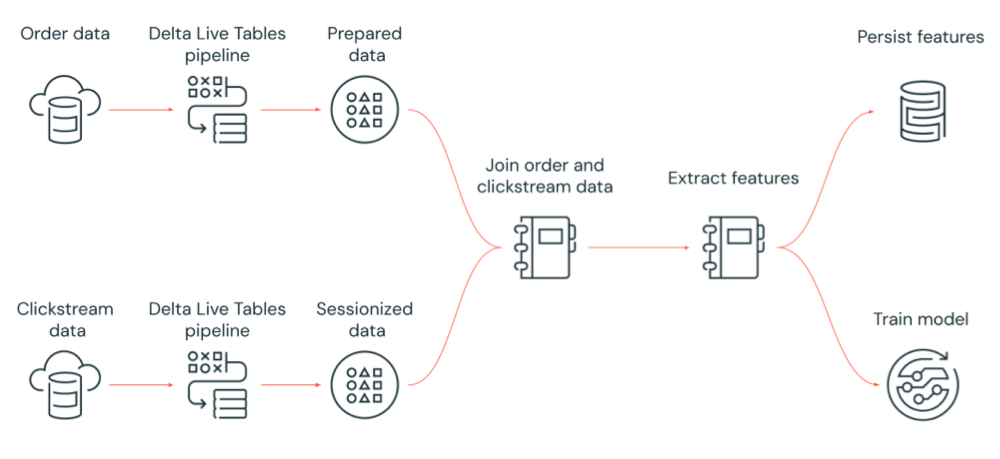
На следующей схеме показан рабочий процесс, управляемый заданием Azure Databricks:
- Запустите конвейер Delta Live Tables, который отправляет необработанные данные clickstream из облачного хранилища, очищает и подготавливает данные, сеансизирует данные и сохраняет окончательный сеансизованный набор данных в Delta Lake.
- Запустите конвейер Delta Live Tables, который обрабатывает данные заказа из облачного хранилища, очищает и преобразует данные для обработки и сохраняет окончательный набор данных в Delta Lake.
- Присоедините порядок и сеансизованные данные clickstream, чтобы создать новый набор данных для анализа.
- Извлеките функции из подготовленных данных.
- Параллельно выполняйте задачи для сохранения функций и обучения модели машинного обучения.
Что такое задания Azure Databricks?
Задание Azure Databricks — это способ выполнения приложений обработки и анализа данных в рабочей области Azure Databricks. Задание может состоять из одной задачи или представлять собой большой рабочий процесс с несколькими задачами со сложными зависимостями. Azure Databricks управляет оркестрацией задач, администрированием кластера, мониторингом и созданием отчетов об ошибках для всех заданий. Вы можете выполнять задания немедленно, периодически используя систему планирования с простым использованием, всякий раз, когда новые файлы приходят во внешнее расположение или непрерывно, чтобы убедиться, что экземпляр задания всегда выполняется. Задания могут также выполняться в интерактивном режиме в пользовательском интерфейсе записной книжки.
Вы можете создать и запустить задание с помощью пользовательского интерфейса заданий, интерфейса командной строки Databricks или вызова API заданий. С помощью пользовательского интерфейса или API можно восстанавливать и повторно запускать невыполненные и отмененные задания. Результаты выполнения задания можно отслеживать с помощью пользовательского интерфейса, интерфейса командной строки, API и уведомлений (например, сообщений электронной почты, назначения веб-перехватчика или уведомлений Slack).
Дополнительные сведения об использовании интерфейса командной строки Databricks см. в статье "Что такое интерфейс командной строки Databricks?". Дополнительные сведения об использовании API заданий см. в API заданий.
В следующих разделах рассматриваются важные функции заданий Azure Databricks.
Внимание
- Рабочая область ограничена 1000 одновременных запусков задач. Ответ
429 Too Many Requestsвозвращается при запросе на выполнение, которое не может быть запущено немедленно. - Число заданий, создаваемых рабочей областью в течение часа, ограничено 10000 (включая "Отправка процессов выполнений"). Это ограничение также влияет на задания, создаваемые рабочими процессами записных книжек и REST API.
Реализация обработки и анализа данных с помощью задач задания
Вы реализуете рабочий процесс обработки и анализа данных с помощью задач. Задание состоит из одной или нескольких задач. Вы можете создавать задачи задания, которые выполняют записные книжки, JARS, конвейеры Delta Live Tables или Python, Scala, Spark submit и Java. Задачи задания также могут управлять запросами Databricks SQL, оповещениями и панелями мониторинга для создания анализа и визуализаций или использовать задачу dbt для выполнения преобразований dbt в рабочем процессе. Также поддерживаются устаревшие приложения Spark Submit.
Вы также можете добавить задачу в задание, которое выполняет другое задание. Эта функция позволяет разбить большой процесс на несколько небольших заданий или создать обобщенные модули, которые могут повторно использоваться несколькими заданиями.
Для управления порядком выполнения задач можно указывать зависимости между ними. В зависимости от настроек задачи могут выполняться последовательно или параллельно.
Выполнение заданий в интерактивном режиме, непрерывно или с помощью триггеров заданий
Задания можно запускать в интерактивном режиме из пользовательского интерфейса заданий, API или интерфейса командной строки или непрерывного задания. Вы можете создать расписание для периодического запуска задания или запустить задание при поступлении новых файлов в внешнее расположение, например Amazon S3, хранилище Azure или google Cloud storage.
Мониторинг хода выполнения задания с помощью уведомлений
Вы можете получать уведомления при запуске задания или задачи, завершении или сбое. Вы можете отправлять уведомления на один или несколько адресов электронной почты или системных назначений (например, назначения веб-перехватчика или Slack). См. статью "Добавление уведомлений по электронной почте и системе" для событий задания.
Выполнение заданий с помощью вычислительных ресурсов Azure Databricks
Кластеры Databricks и хранилища SQL предоставляют вычислительные ресурсы для заданий. Задания можно запускать с помощью кластера заданий, кластера всех целей или хранилища SQL:
- Кластер заданий — это выделенный кластер для заданий или отдельных задач задания. Задание может использовать кластер заданий, общий для всех задач или настроить кластер для отдельных задач при создании или изменении задачи. Кластер заданий создается, когда задание или задача запускаются и завершаются после завершения задания или задачи.
- Кластер всех целей — это общий кластер, который запускается вручную и завершается и может использоваться несколькими пользователями и заданиями.
Для оптимизации использования ресурсов Databricks рекомендует использовать кластер заданий для заданий. Чтобы сократить время ожидания запуска кластера, рассмотрите возможность использования кластера с универсальным назначением. См. статью "Использование вычислений Azure Databricks с заданиями".
Хранилище SQL используется для выполнения задач Databricks SQL, таких как запросы, панели мониторинга или оповещения. Вы также можете использовать хранилище SQL для выполнения преобразований dbt с задачей dbt.
Следующие шаги
Чтобы приступить к работе с Заданиями Azure Databricks, выполните приведенные действия.
Создайте первое задание Azure Databricks с помощью краткого руководства.
Узнайте, как создавать и запускать рабочие процессы с помощью пользовательского интерфейса Заданий Azure Databricks.
Узнайте, как выполнять задание без необходимости настраивать вычислительные ресурсы Azure Databricks с бессерверными рабочими процессами.
Сведения о выполнении заданий мониторинга в пользовательском интерфейсе Заданий Azure Databricks.
Узнайте о параметрах конфигурации заданий.
Дополнительные сведения о создании, управлении и устранении неполадок рабочих процессов с помощью заданий Azure Databricks:
- Узнайте, как обмениваться данными между задачами в задании Azure Databricks со значениями задач.
- Узнайте, как передать контекст о выполнении задания в задачи задания с переменными параметров задачи.
- Узнайте, как настроить задачи задания для условного выполнения на основе состояния зависимостей задачи.
- Узнайте, как устранять неполадки и устранять неудачные задания.
- Получите уведомление о запуске задания, завершении или сбое с уведомлениями о выполнении задания.
- Активируйте задания в пользовательском расписании или выполните непрерывное задание.
- Узнайте, как запустить задание Azure Databricks при поступлении новых данных с триггерами прибытия файла.
- Узнайте, как использовать вычислительные ресурсы Databricks для выполнения заданий.
- Сведения об обновлениях API заданий для поддержки создания рабочих процессов и управления ими с помощью заданий Azure Databricks.
- Ознакомьтесь с руководствами и руководствами , чтобы узнать больше о реализации рабочих процессов данных с помощью заданий Azure Databricks.
Что такое разностные динамические таблицы?
Примечание.
Для Delta Live Tables требуется план Премиум. Чтобы получить дополнительные сведения, обратитесь к группе учетной записи Databricks.
Delta Live Tables — это платформа, которая упрощает обработку данных ETL и потоковой передачи данных. Delta Live Tables обеспечивает эффективное прием данных со встроенной поддержкой автозагрузчика, интерфейсов SQL и Python, поддерживающих декларативную реализацию преобразований данных и поддержку записи преобразованных данных в Delta Lake. Вы определяете преобразования, выполняемые с данными, а платформа "Разностные динамические таблицы" управляет оркестрацией задач, администрированием кластеров, мониторингом, качеством данных и обработкой ошибок.
Чтобы приступить к работе, ознакомьтесь с разделом "Что такое разностные динамические таблицы?".
Задания Azure Databricks и разностные динамические таблицы
Задания Azure Databricks и разностные динамические таблицы предоставляют комплексную платформу для создания и развертывания комплексных рабочих процессов обработки и анализа данных.
Используйте разностные динамические таблицы для всех приемов и преобразования данных. Используйте задания Azure Databricks для оркестрации рабочих нагрузок, состоящих из одной задачи или нескольких задач обработки и анализа данных на платформе Databricks, включая прием и преобразование разностных динамических таблиц.
Как система оркестрации рабочих процессов, Задания Azure Databricks также поддерживают:
- Выполнение заданий на триггерной основе, например запуск рабочего процесса по расписанию.
- Анализ данных с помощью запросов SQL, машинного обучения и анализа данных с помощью записных книжек, скриптов или внешних библиотек и т. д.
- Выполнение задания, состоящего из одной задачи, например выполнение задания Apache Spark, упаковаемого в JAR-файл.
Оркестрация рабочих процессов с помощью Apache AirFlow
Хотя Databricks рекомендует использовать задания Azure Databricks для оркестрации рабочих процессов данных, вы также можете использовать Apache Airflow для управления и планирования рабочих процессов данных. При использовании Airflow вы определяете рабочий процесс в файле Python, а Airflow управляет планированием и выполнением рабочего процесса. См . сведения о заданиях Orchestrate Azure Databricks с помощью Apache Airflow.
Оркестрация рабочих процессов с помощью Фабрика данных Azure
Фабрика данных Azure (ADF) — это облачная служба интеграции данных, которая позволяет создавать хранилища данных, перемещения и обработки служб в автоматизированные конвейеры данных. С помощью ADF можно управлять заданием Azure Databricks в рамках конвейера ADF.
Сведения о запуске задания с помощью веб-действия ADF, включая проверку подлинности в Azure Databricks из ADF, см. в статье "Использование оркестрации заданий Azure Databricks из Фабрика данных Azure".
ADF также обеспечивает встроенную поддержку запуска записных книжек Databricks, скриптов Python или кода, упакованных в jaRs в конвейере ADF.
Чтобы узнать, как запустить записную книжку Databricks в конвейере ADF, см. статью "Запуск записной книжки Databricks с действием записной книжки Databricks в Фабрика данных Azure", а затем преобразование данных путем запуска записной книжки Databricks.
Сведения о запуске скрипта Python в конвейере ADF см. в статье "Преобразование данных", выполнив действие Python в Azure Databricks.
Сведения о том, как выполнять код, упакованный в JAR-файл в конвейере ADF, см. в разделе "Преобразование данных", выполнив действие JAR в Azure Databricks.
Обратная связь
Ожидается в ближайшее время: в течение 2024 года мы постепенно откажемся от GitHub Issues как механизма обратной связи для контента и заменим его новой системой обратной связи. Дополнительные сведения см. в разделе https://aka.ms/ContentUserFeedback.
Отправить и просмотреть отзыв по