Использование структурированной потоковой передачи Apache Spark с Apache Kafka в Azure Cosmos DB
Узнайте, как использовать структурированную потоковую передачуApache Spark для чтения данных из Apache Kafka в Azure HDInsight и как сохранить эти данные в Azure Cosmos DB.
Azure Cosmos DB — это многомодельная глобально распределенная база данных. В этом примере используется модель базы данных Azure Cosmos DB для NoSQL. Дополнительные сведения см. в документе Добро пожаловать в базу данных Azure Cosmos DB.
Структурированная потоковая передача Spark — это механизм обработки потока, встроенный в Spark SQL. Он позволяет выражать потоковые вычисления так же, как пакетные вычисления статических данных. Дополнительные сведения о структурированной потоковой передаче см. в руководстве по программированию структурированной потоковой передачи на Apache.org.
Внимание
В этом примере используется Spark 2.4 в HDInsight 4.0.
Вы узнаете, как создать группу ресурсов Azure, которая содержит кластеры Spark и Kafka в HDInsight. Оба этих кластера находятся в виртуальной сети Azure, что позволяет кластеру Spark напрямую обмениваться данными с кластером Kafka.
Выполнив инструкции, не забудьте удалить кластеры, чтобы избежать ненужных расходов.
Создание кластеров
Apache Kafka в HDInsight не предоставляет доступ к брокерам Kafka через общедоступный сегмент Интернета. Все объекты, обращающиеся к Kafka, должны находиться в той же виртуальной сети Azure, что и узлы в кластере Kafka. В этом примере кластеры Kafka и Spark расположены в виртуальной сети Azure. На следующей схеме показано, как взаимодействуют кластеры.
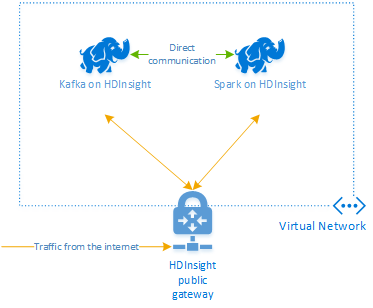
Примечание.
Служба Kafka ограничена обменом данными в пределах виртуальной сети. Другие службы в кластере, например SSH и Ambari, могут быть доступны через Интернет. Дополнительные сведения об общих портах, доступных в HDInsight, см. в статье Порты и универсальные коды ресурсов (URI), используемые кластерами HDInsight.
Хотя виртуальную сеть Azure, а также кластеры Kafka и Spark можно создать вручную, проще использовать шаблон Azure Resource Manager. Выполните следующие действия, чтобы развернуть виртуальную сеть Azure, а также кластеры Kafka и Spark в подписке Azure.
Нажмите эту кнопку, чтобы войти в Azure и открыть шаблон на портале Azure.

Шаблон Azure Resource Manager находится в репозитории GitHub для этого проекта (https://github.com/Azure-Samples/hdinsight-spark-scala-kafka-cosmosdb).
Этот шаблон создает следующие ресурсы:
Кластер Kafka в HDInsight 4.0.
Кластер Spark в HDInsight 4.0.
виртуальную сеть Azure, содержащую кластеры HDInsight. Виртуальная сеть, созданная шаблоном, использует адресное пространство 10.0.0.0/16.
База данных Azure Cosmos DB для NoSQL.
Внимание
Структурированная записная книжка потоковой передачи, используемая в этом примере, требует Spark в HDInsight 4.0. Если используется более ранняя версия Spark в HDInsight, возникнут ошибки при использовании этой записной книжки.
Используйте следующие сведения, чтобы заполнить раздел Настраиваемое развертывание:
Свойство Значение Отток подписок Выберите свою подписку Azure. Группа ресурсов Создайте новую группу или выберите существующую. Эта группа содержит кластер HDInsight. Имя учетной записи Azure Cosmos DB Это значение используется в качестве имени учетной записи Azure Cosmos DB. Имя может содержать только строчные буквы, цифры и знак дефиса (-). Длина — от 3 до 31 знака. Базовое имя кластера Это значение будет использоваться в качестве базового имени для кластеров Spark и Kafka. Например, если ввести myhdi, будет создан кластер Spark с именем spark-myhdi и кластер Kafka с именем kafka-myhdi. Версия кластера Версия кластера HDInsight. Этот пример тестируется с помощью HDInsight 4.0 и может не работать с другими типами кластеров. Имя пользователя для входа в кластер Имя администратора для кластеров Spark и Kafka. Пароль для входа в кластер Пароль администратора для кластеров Spark и Kafka. Имя пользователя SSH Создаваемый пользователь SSH для кластеров Spark и Kafka. Пароль SSH Пароль пользователя SSH для кластеров Spark и Kafka. 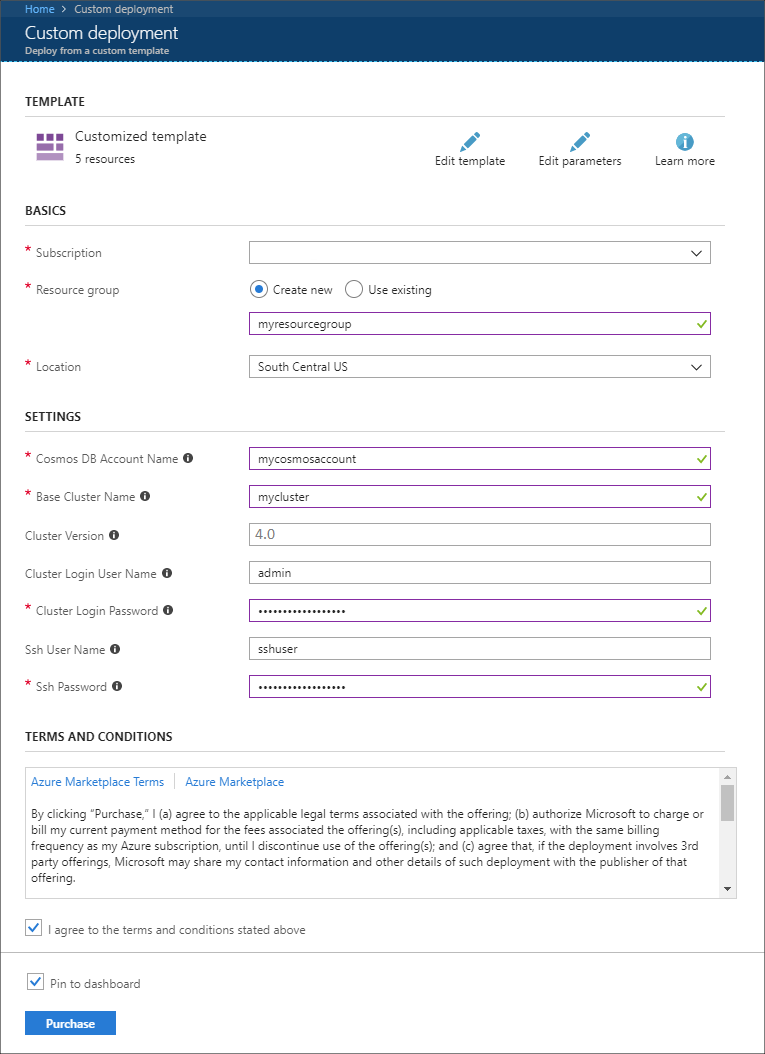
Прочтите условия использования и установите флажок Я принимаю указанные выше условия.
Наконец, щелкните Приобрести. Создание кластеров, виртуальной сети и учетной записи Azure Cosmos DB может занять до 45 минут.
Создание базы данных и коллекции Azure Cosmos DB
Проект, используемый в этом документе, хранит данные в Azure Cosmos DB. Перед запуском кода необходимо сначала создать базу данных и коллекцию в экземпляре Azure Cosmos DB. Кроме того, необходимо получить конечную точку документа и ключ, используемый для проверки подлинности запросов к Azure Cosmos DB.
Один из способов сделать это — воспользоваться Azure CLI 2.0. Следующий скрипт создаст базу данных с именем kafkadata и коллекцию с именем kafkacollection. Затем он возвращает первичный ключ.
#!/bin/bash
# Replace 'myresourcegroup' with the name of your resource group
resourceGroupName='myresourcegroup'
# Replace 'mycosmosaccount' with the name of your Azure Cosmos DB account name
name='mycosmosaccount'
# WARNING: If you change the databaseName or collectionName
# then you must update the values in the Jupyter Notebook
databaseName='kafkadata'
collectionName='kafkacollection'
# Create the database
az cosmosdb sql database create --account-name $name --name $databaseName --resource-group $resourceGroupName
# Create the collection
az cosmosdb sql container create --account-name $name --database-name $databaseName --name $collectionName --partition-key-path "/my/path" --resource-group $resourceGroupName
# Get the endpoint
az cosmosdb show --name $name --resource-group $resourceGroupName --query documentEndpoint
# Get the primary key
az cosmosdb keys list --name $name --resource-group $resourceGroupName --type keys
Конечная точка документа и сведения о первичном ключе подобны следующему тексту:
# endpoint
"https://mycosmosaccount.documents.azure.com:443/"
# key
"YqPXw3RP7TsJoBF5imkYR0QNA02IrreNAlkrUMkL8EW94YHs41bktBhIgWq4pqj6HCGYijQKMRkCTsSaKUO2pw=="
Внимание
Сохраните конечную точку и значения ключей. Они понадобятся при работе с записными книжками Jupyter.
Получение записных книжек
Код для примера, описанного в этом документе: https://github.com/Azure-Samples/hdinsight-spark-scala-kafka-cosmosdb.
Отправка записных книжек
Чтобы отправить записные книжки из проекта в кластер Spark в HDInsight, выполните следующие действия.
В веб-браузере подключитесь к записной книжке Jupyter в своем кластере Spark. В следующем URL-адресе замените
CLUSTERNAMEименем вашего кластера Spark:https://CLUSTERNAME.azurehdinsight.net/jupyterПри появлении запроса введите имя администратора кластера и пароль, которые использовались при создании кластера.
В правой верхней части страницы нажмите кнопку Отправить, чтобы отправить файл Stream-taxi-data-to-kafka.ipynb в кластер. Нажмите Открыть для запуска отправки.
Найдите запись Stream-taxi-data-to-kafka.ipynb в списке записных книжек, а затем нажмите расположенную рядом кнопку Отправить.
Повторите шаги 1–3, чтобы загрузить записную книжку Stream-data-from-Kafka-to-Cosmos-DB.ipynb.
Загрузка данных о поездках в такси в Kafka
После отправки файлов выберите запись Stream-taxi-data-to-kafka.ipynb, чтобы открыть записную книжку. Выполните действия в записной книжке, чтобы загрузить данные в Kafka.
Обработка данных о поездках в такси с помощью структурированной потоковой передачи Spark
На домашней странице Jupyter Notebook выберите запись Stream-data-from-Kafka-to-Cosmos-DB.ipynb. Следуйте инструкциям в записной книжке, чтобы выполнить потоковую передачу данных из Kafka в Azure Cosmos DB с помощью структурированной потоковой передачи Spark.
Следующие шаги
Теперь, когда вы узнали, как использовать структурированную потоковую передачу Apache Spark, перейдите к следующим документам для углубленного изучения работы с Apache Spark, Apache Kafka и Azure Cosmos DB: