Руководство. Создание кластеров Apache Hadoop в HDInsight по запросу с помощью Фабрики данных Azure
Из этого руководства вы узнаете, как создать кластер Apache Hadoop по запросу в Azure HDInsight с помощью Фабрики данных Azure. Затем как использовать конвейеры данных в фабрике данных Azure для выполнения заданий Hive и удалить кластер. Изучив это руководство, вы узнаете, как operationalize запуск задания больших данных, когда создание кластера, выполнение задания и удаление кластера выполняются по расписанию.
В рамках этого руководства рассматриваются следующие задачи:
- Создание учетной записи службы хранилища Azure
- Суть происходящего в фабрике данных Azure
- Создание фабрики данных с помощью портала Azure
- Создание связанных служб
- Создание конвейера
- Активация конвейера
- Мониторинг конвейера
- Проверка выходных данных
Если у вас нет подписки Azure, создайте бесплатную учетную запись, прежде чем приступить к работе.
Необходимые компоненты
Установите модуль Az для PowerShell.
Субъект-служба Microsoft Entra. После создания субъект-службы, обязательно получите идентификатор приложения и ключ проверки подлинности с помощью инструкций в соответствующей статье. Эти значения вам понадобятся позже (в рамках этого руководства). Кроме того, убедитесь, что субъект-службе должна быть назначена роль участника подписки или группы ресурсов, в которой создается кластер. Инструкции по получению необходимых значений и назначению справа ролей см. в разделе "Создание субъекта-службы Microsoft Entra".
Создание предварительных объектов Azure
В этом разделе вы создадите различные объекты, используемые для кластера HDInsight, который создается по требованию. Созданная учетная запись хранения будет содержать пример сценария HiveQL, partitionweblogs.hql, который позволяет моделировать пример задания Apache Hive, выполняющегося в кластере.
В этом разделе используется сценарий Azure PowerShell для создания учетной записи хранения и копирования необходимых файлов в учетную запись хранения. Ниже описаны действия для примера скрипта Azure PowerShell, приведенного в этом разделе.
- Входит в Azure.
- Создает группы ресурсов Azure.
- Создает учетную запись хранения Azure.
- Создание контейнера больших двоичных объектов в учетной записи хранения
- Копирует пример сценария HiveQL (partitionweblogs.hql) в контейнер больших двоичных объектов. Пример сценария, который уже доступен в другом общедоступном контейнере больших двоичных объектов. Приведенный ниже сценарий PowerShell создает копии этих файлов в учетной записи хранилища Azure, которую он создал.
Создание учетной записи хранения и копирование файлов
Внимание
Укажите имена для группы ресурсов Azure и учетную запись хранения Azure, которая будет создана с помощью скрипта. Запишите имя группы ресурсов, имя учетной записи хранения и ключ учетной записи хранения, выводимые скриптом. Они потребуются в следующем разделе.
$resourceGroupName = "<Azure Resource Group Name>"
$storageAccountName = "<Azure Storage Account Name>"
$location = "East US"
$sourceStorageAccountName = "hditutorialdata"
$sourceContainerName = "adfv2hiveactivity"
$destStorageAccountName = $storageAccountName
$destContainerName = "adfgetstarted" # don't change this value.
####################################
# Connect to Azure
####################################
#region - Connect to Azure subscription
Write-Host "`nConnecting to your Azure subscription ..." -ForegroundColor Green
$sub = Get-AzSubscription -ErrorAction SilentlyContinue
if(-not($sub))
{
Connect-AzAccount
}
# If you have multiple subscriptions, set the one to use
# Select-AzSubscription -SubscriptionId "<SUBSCRIPTIONID>"
#endregion
####################################
# Create a resource group, storage, and container
####################################
#region - create Azure resources
Write-Host "`nCreating resource group, storage account and blob container ..." -ForegroundColor Green
New-AzResourceGroup `
-Name $resourceGroupName `
-Location $location
New-AzStorageAccount `
-ResourceGroupName $resourceGroupName `
-Name $destStorageAccountName `
-Kind StorageV2 `
-Location $location `
-SkuName Standard_LRS `
-EnableHttpsTrafficOnly 1
$destStorageAccountKey = (Get-AzStorageAccountKey `
-ResourceGroupName $resourceGroupName `
-Name $destStorageAccountName)[0].Value
$sourceContext = New-AzStorageContext `
-StorageAccountName $sourceStorageAccountName `
-Anonymous
$destContext = New-AzStorageContext `
-StorageAccountName $destStorageAccountName `
-StorageAccountKey $destStorageAccountKey
New-AzStorageContainer `
-Name $destContainerName `
-Context $destContext
#endregion
####################################
# Copy files
####################################
#region - copy files
Write-Host "`nCopying files ..." -ForegroundColor Green
$blobs = Get-AzStorageBlob `
-Context $sourceContext `
-Container $sourceContainerName `
-Blob "hivescripts\hivescript.hql"
$blobs|Start-AzStorageBlobCopy `
-DestContext $destContext `
-DestContainer $destContainerName `
-DestBlob "hivescripts\partitionweblogs.hql"
Write-Host "`nCopied files ..." -ForegroundColor Green
Get-AzStorageBlob `
-Context $destContext `
-Container $destContainerName
#endregion
Write-host "`nYou will use the following values:" -ForegroundColor Green
write-host "`nResource group name: $resourceGroupName"
Write-host "Storage Account Name: $destStorageAccountName"
write-host "Storage Account Key: $destStorageAccountKey"
Write-host "`nScript completed" -ForegroundColor Green
Проверка учетной записи хранения
- Выполните вход на портал Azure.
- В левой части последовательно выберите Все службы>Общие>Группы ресурсов.
- Выберите имя группы ресурсов, созданной в сценарии PowerShell. Если отображается слишком много групп ресурсов, используйте фильтр.
- В представлении Обзор должен отображаться один ресурс, если только группа ресурсов не является общей для других проектов. Этим ресурсом будет учетная запись хранения с именем, которое вы указали ранее. Выберите имя учетной записи хранения.
- Щелкните плитку Контейнеры.
- Выберите контейнер adfgetstarted . Перед вами папка с именем
hivescripts. - Откройте папку, она должна содержать пример файла сценария partitionweblogs.hql.
Суть происходящего в фабрике данных Azure
Фабрика данных Azure координирует и автоматизирует процессы перемещения и преобразования данных. С ее помощью вы можете создать кластер Hadoop в HDInsight, когда это требуется для обработки входящих срезов данных. После завершения обработки кластер можно удалить.
В фабрике данных Azure фабрика данных может содержать один или несколько конвейеров. Конвейер данных включает одно или несколько действий. Существует два вида действий:
- Действия перемещения данных. Для перемещения данных из исходного хранилища данных в целевое используются действия перемещения данных.
- Действия по преобразованию данных. Для перемещения и обработки данных используются действия преобразования данных. Действие Hive HDInsight — одно из действий преобразования, которое поддерживает фабрика данных. В этом руководстве используется действие преобразования Hive.
В этой статье идет речь о настройке действия Hive для создания по требованию кластера Hadoop в HDInsight. При выполнении действия по обработке данных, происходит следующее.
Автоматически создается кластер Hadoop HDInsight для своевременной обработки среза.
Для обработки входных данных выполняется скрипт HiveQL в кластере. В этом руководстве описываются действия скрипта HiveQL, связанного с действием Hive.
- Он использует существующую таблицу (hivesampletable) для создания другой таблицы HiveSampleOut.
- Скрипт заполняет таблицу HiveSampleOut только определенными столбцами из исходной таблицы hivesampletable.
По завершении обработки кластер Hadoop HDInsight удаляется и не используется в течение заданного времени (параметр timeToLive). Если во время простоя (параметр timeToLive) можно обработать следующий срез данных, для этого используется тот же кластер.
Создание фабрики данных
Войдите на портал Azure.
В меню слева последовательно выберите
+ Create a resource>Аналитика>Фабрика данных.
Введите или выберите следующие значения для плитки Новая фабрика данных.
Свойство Значение Имя. Введите имя фабрики данных. Оно должно быть глобально уникальным. Версия Оставьте V2. Отток подписок Выберите свою подписку Azure. Группа ресурсов Выберите группу ресурсов, созданную с помощью сценария PowerShell. Расположение Автоматически задается то расположение, которое было указано при предыдущем создании группы ресурсов. В этом руководстве расположение установлено как восточная часть США. Включить GIT Снимите этот флажок. 
Нажмите кнопку создания. Создание фабрики данных может занять от 2 до 4 минут.
После создания фабрики данных вы получите уведомление Развертывание прошло успешно с кнопкой Перейти к ресурсу. Нажмите кнопку Перейти к ресурсу, чтобы открыть представление фабрики данных по умолчанию.
Выберите Создание и мониторинг для запуска портала создания и наблюдения фабрики данных Azure.

Создание связанных служб
В этом разделе вы создаете две связанные службы на своей фабрике данных.
- Связанную службу хранилища Azure, которая связывает учетную запись хранения Azure с фабрикой данных. Это хранилище используется кластером HDInsight по запросу. Оно также содержит сценарий Hive, выполняющийся в кластере.
- Связанную службу HDInsight по запросу. Фабрика данных Azure автоматически создает кластер HDInsight и запускает сценарий Hive. Кластер Hadoop удаляется, если он не используется в течение заданного времени.
Создание связанной службы хранилища Azure
В левой области страницы Начать работу выберите значок Создание.

Выберите в нижнем левом углу окна кнопку Подключения, а затем выберите +Создать.

В диалоговом окне New Linked Service (Новая связанная служба) выберите Хранилище BLOB-объектов Azure и щелкните Продолжить.
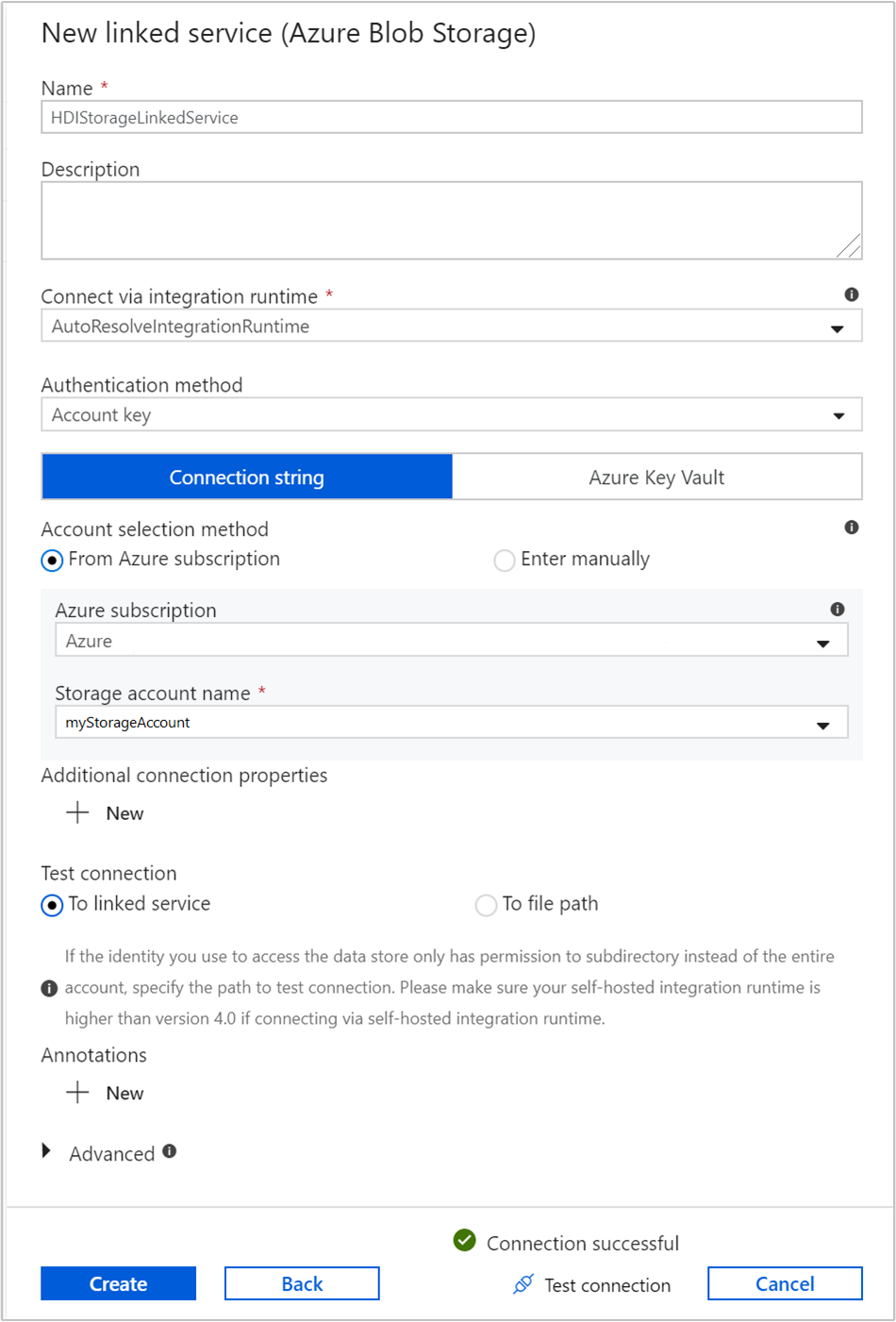
Введите следующие значения для связанной службы хранилища.
Свойство Значение Имя. Введите HDIStorageLinkedService.Подписка Azure. Выберите подписку в раскрывающемся списке. Storage account name Выберите созданную учетную запись службы хранилища Azure, созданную в рамках сценария PowerShell. Нажмите копку Проверить подключение, и если проверка прошла успешно, щелкните Создать.
Создание связанной службы HDInsight по запросу
Снова нажмите кнопку + Создать, чтобы создать еще одну связанную службу.
В окне New Linked Service (Новая связанная служба) выберите вкладку Службы вычислений.
Выберите Azure HDInsight, а затем Продолжить.
В окне New Linked Service (Новая связанная служба) введите следующие значения и оставьте остальные по умолчанию.
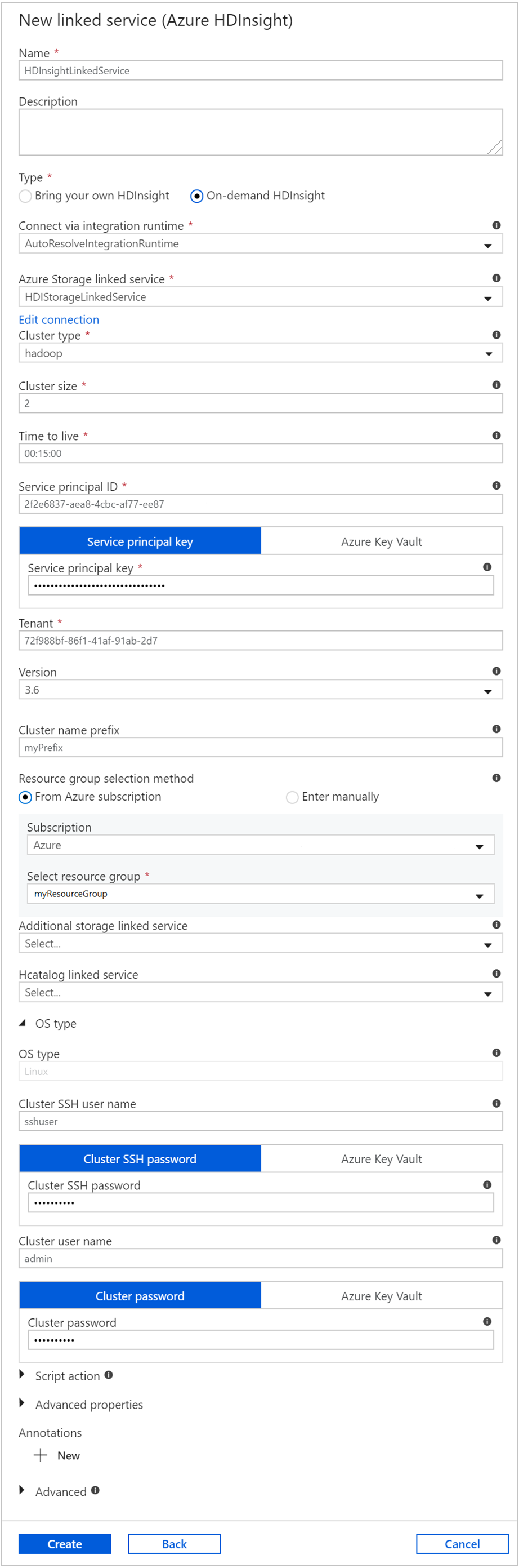
Свойство Значение Имя. Введите HDInsightLinkedService.Тип Выберите On-demand HDInsight (HDInsight по требованию). Связанная служба хранилища Azure Выберите HDIStorageLinkedService.Тип кластера Выберите hadoop Срок жизни Укажите продолжительность времени, в течение которого кластер HDInsight должен быть доступен до его автоматического удаления Идентификатор субъекта-службы Укажите идентификатор приложения субъекта-службы Microsoft Entra, созданного в рамках предварительных требований. Ключ субъекта-службы Укажите ключ проверки подлинности для субъекта-службы Microsoft Entra. Префикс имени кластера Укажите значение, которое будет добавлено как префикс ко всем типам кластера, созданным фабрикой данных. Отток подписок Выберите подписку в раскрывающемся списке. Выберите группу ресурсов Выберите группу ресурсов, созданную в рамках сценария PowerShell, которая использовалась ранее. Тип ОС/Имя пользователя кластера SSH Введите имя пользователя SSH, обычно sshuser.Тип ОС/Пароль кластера SSH Укажите пароль пользователя SSH. Тип ОС/Имя пользователя кластера Введите имя пользователя кластера, обычно admin.Тип ОС/Пароль кластера Укажите пароль для пользователя кластера. Затем выберите Создать.
Создание конвейера
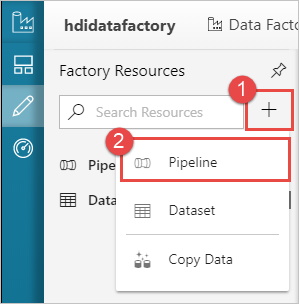
Нажмите кнопку + (плюс) и выберите Pipeline (Конвейер).
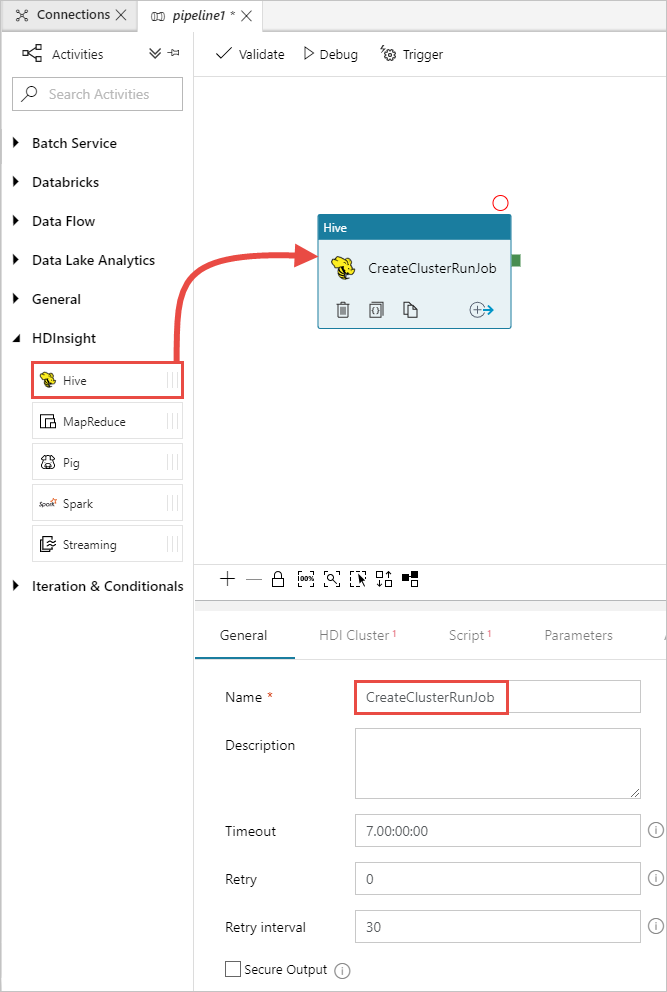
В панели инструментов Действия разверните HDInsight и перетащите действие Hive в область конструктора конвейера. Во вкладке Общие укажите имя для действия.
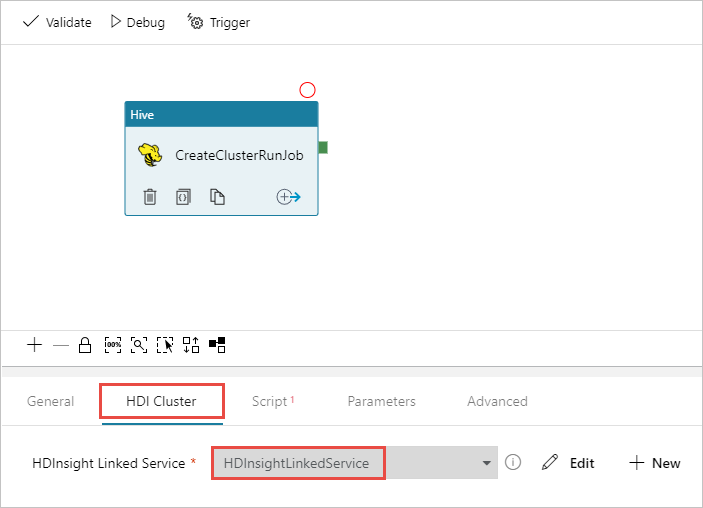
Убедитесь, что выбрано действие Hive, перейдите на вкладку кластера HDI. В раскрывающемся списке связанной службы HDInsight выберите связанную службу, созданную ранее, HDInsightLinkedService, для HDInsight.
Выберите вкладку Скрипт и затем сделайте следующее:
Для параметра Служба, связанная со скриптом выберите в раскрывающемся списке HDIStorageLinkedService. Это — связанная служба хранилища, созданная ранее.
Для Путь к файлу выберите Поиск в хранилище и перейдите в расположение, где находится образец скрипта Hive. Если ранее выполнялся скрипт PowerShell, это расположение должно быть
adfgetstarted/hivescripts/partitionweblogs.hql.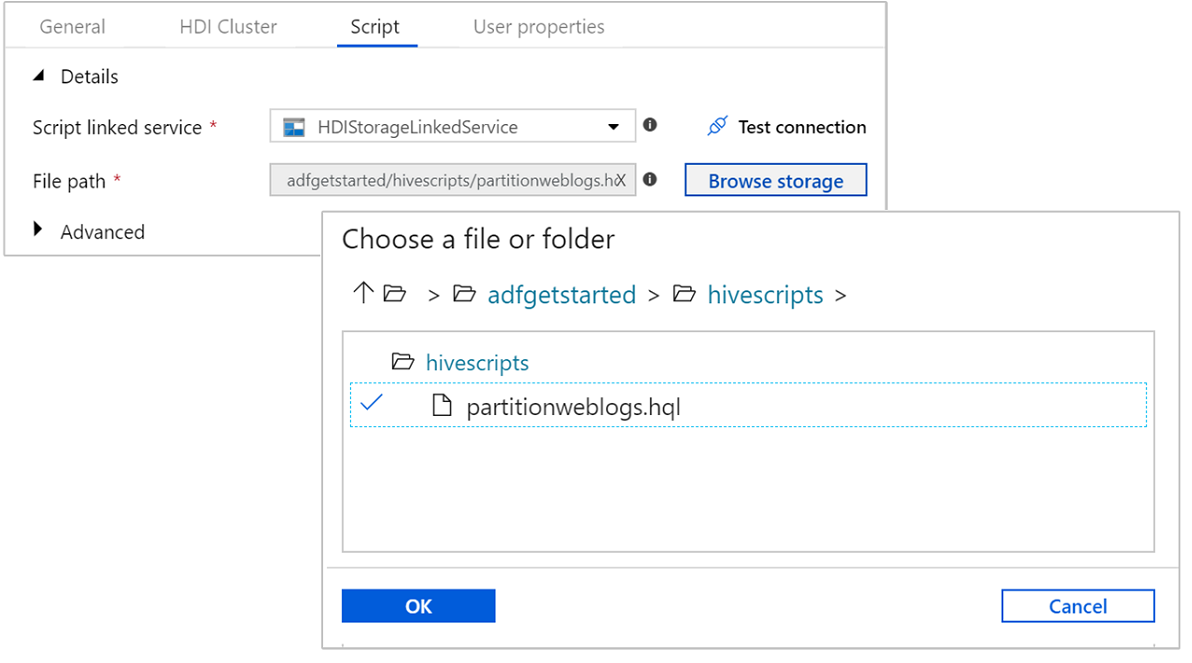
В разделе Дополнительно>Параметры выберите
Auto-fill from script. Этот параметр ищет любые параметры в сценарии Hive, которым требуются значения во время выполнения.В текстовое поле значение добавьте имеющуюся папку в формате
wasbs://adfgetstarted@<StorageAccount>.blob.core.windows.net/outputfolder/. Путь учитывает регистр. Это путь, где будут храниться выходные данные сценария. Схемаwasbsнеобходима, так как у учетных записей хранения теперь по умолчанию включено требование безопасной передачи.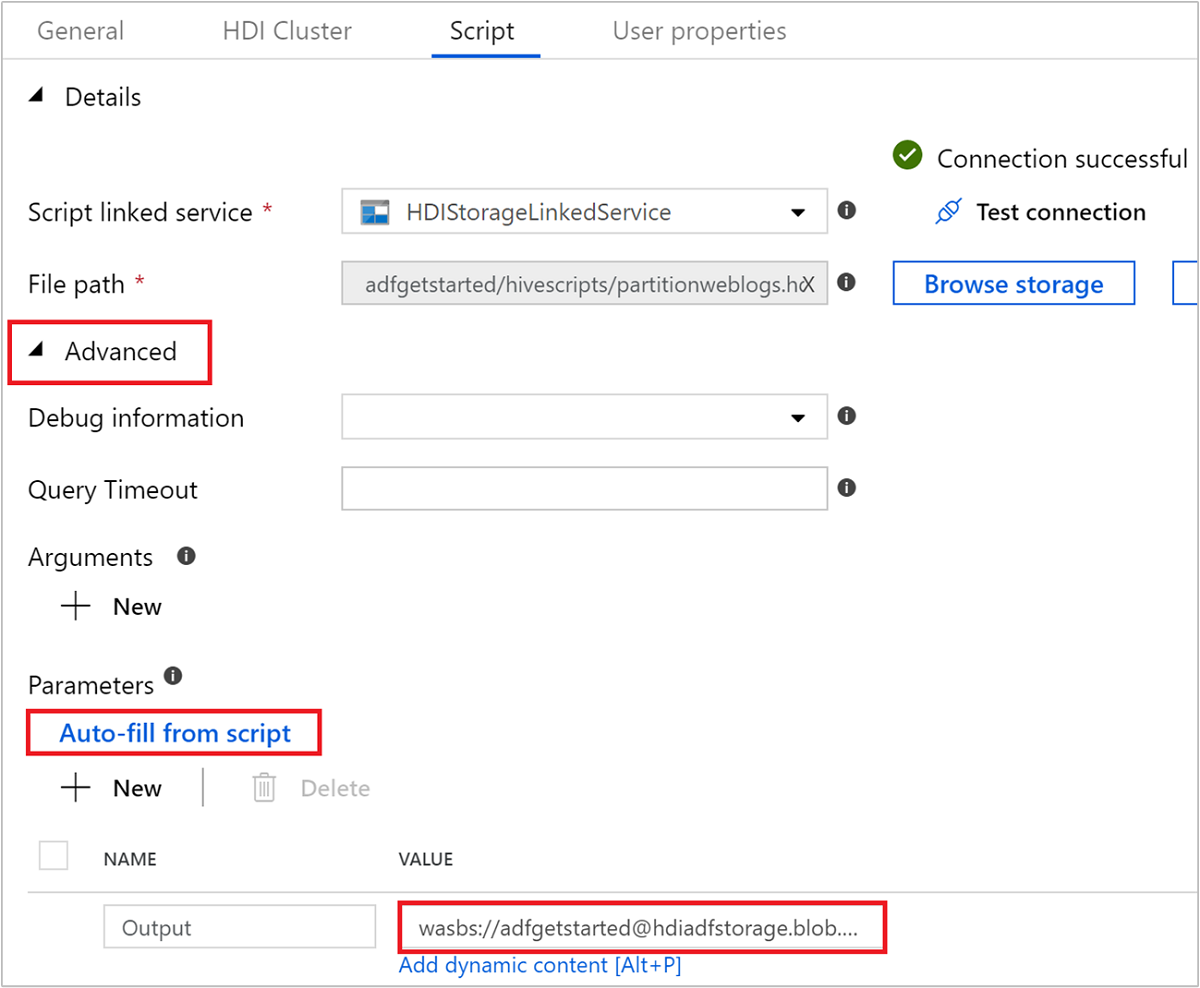
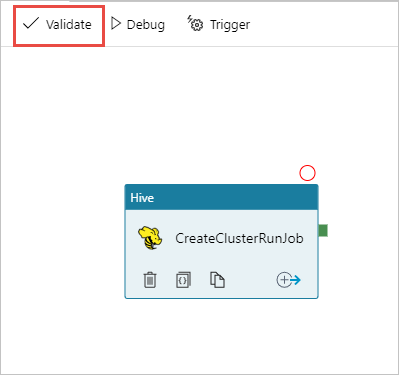
Чтобы проверить конвейер, выберите Проверить. Чтобы закрыть окно проверки, нажмите кнопку >>Стрелка вправо.
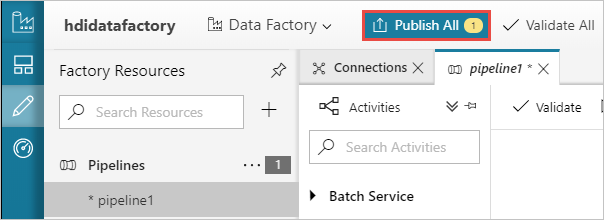
Наконец, выберите Опубликовать все для публикации артефактов фабрики данных Azure.
Активация конвейера
Из панели инструментов на поверхности конструктора выберите Добавить триггер>Trigger Now (Активировать сейчас).
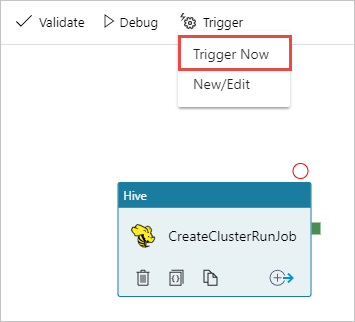
Нажмите кнопку OK на всплывающей боковой панели.
Мониторинг конвейера
Перейдите на вкладку Мониторинг слева. Вы увидите, что запуск конвейера появится в списке Pipeline Runs (Запуски конвейера). Обратите внимание на состояние выполнения в столбце Состояние.
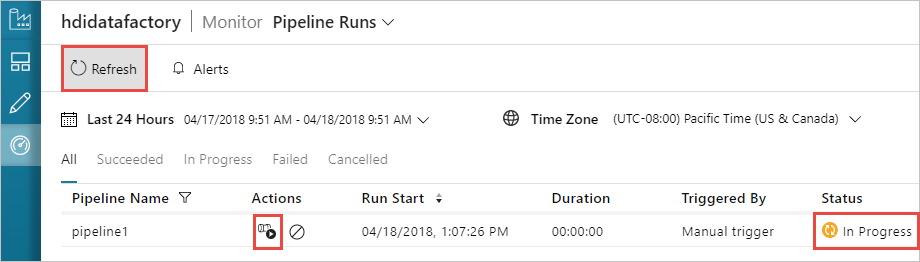
Щелкните Обновить, чтобы обновить состояние.
Можно также выбрать значок Представление выполнения действия для просмотра выполнения действия связанного с конвейером. На снимке экрана ниже видно только одно выполнение действия, так как в созданном конвейере есть только одно действие. Чтобы вернуться к предыдущему представлению, выберите Конвейеры в верхней части страницы.
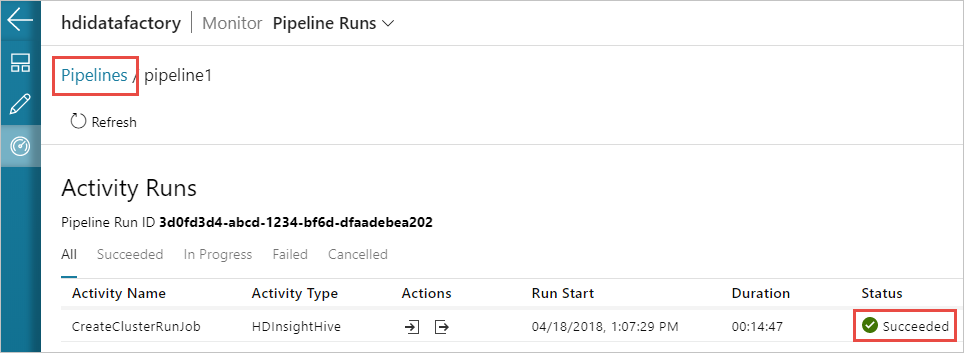
Проверка выходных данных
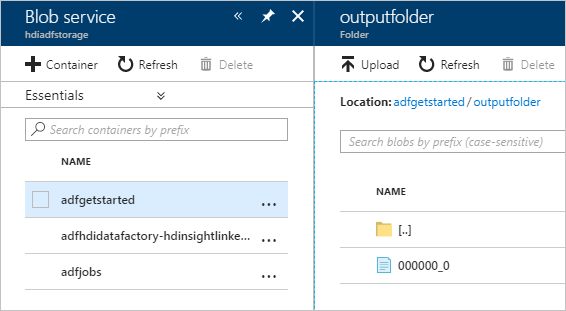
Чтобы проверить выходные данные, на портале Azure перейдите к учетной записи хранения, используемой в этом руководстве. Там должны быть следующие папки или контейнеры.
adfgerstarted/outputfolder, содержащий выходные данные сценария Hive, который был запущен в рамках конвейера.
Контейнер adfhdidatafactory-<linked-service-name>-<timestamp>. Этот контейнер по умолчанию является местом хранения кластера HDInsight, который был создан в рамках выполнения конвейера.
Контейнер adfjobs, содержащий журналы заданий фабрики данных Azure.
Очистка ресурсов
Если вы создаете кластер HDInsight по требованию, явно удалять кластер HDInsight не нужно. Удаление кластера заложено в основе конфигурации, которая указывается при создании конвейера. Учетные записи хранения, связанные с кластером, продолжают существовать даже после удаления кластера. Это сделано намеренно, чтобы сохранить данные без изменений. Но если вы не хотите сохранять данные, можно удалить созданную учетную запись хранения.
Кроме того, можно целиком удалить группу ресурсов, созданную в этом руководстве. Этот процесс приведет к удалению учетной записи хранения и созданной Фабрики данных Azure.
Удаление группы ресурсов
Выполните вход на портал Azure.
Выберите Группы ресурсов на левой панели.
Выберите имя группы ресурсов, созданной в сценарии PowerShell. Если отображается слишком много групп ресурсов, используйте фильтр. Он открывает группу ресурсов.
В элементе Ресурсы должны отображаться учетная запись хранения по умолчанию и фабрика данных, если только группа ресурсов не является общей для других проектов.
Выберите команду Удалить группу ресурсов. При этом также будет удалена учетная запись хранения и данные, хранящиеся в ней.
Введите имя группы ресурсов, чтобы подтвердить удаление, и нажмите Удалить.
Следующие шаги
Из этой статьи вы узнали, как использовать Фабрику данных Azure для создания кластера HDInsight по требованию и выполнения заданий Apache Hive. Перейдите к следующей статье, чтобы узнать, как создавать кластеры HDInsight с настраиваемой конфигурацией.