Создание приложений Apache Spark для кластера HDInsight с помощью Azure Toolkit for Eclipse
Использование средств HDInsight из набора Azure Toolkit for Eclipse для разработки приложений Apache Spark на языке Scala и их отправки в кластер Azure HDInsight Spark непосредственно из интегрированной среды разработки Eclipse. Подключаемый модуль средств HDInsight можно использовать по-разному.
- Для разработки и отправки приложений Scala Spark в кластер HDInsight Spark.
- Для доступа к ресурсам кластера Azure HDInsight Spark.
- Для разработки и локального запуска приложений Scala Spark.
Необходимые компоненты
Кластер Apache Spark в HDInsight. Инструкции см. в статье Начало работы. Создание кластера Apache Spark в HDInsight на платформе Linux и выполнение интерактивных запросов с помощью SQL Spark.
Интегрированная среда разработки Eclipse. В этой статье используется интегрированная среда разработки Eclipse для разработчиков Java.
Установка необходимых подключаемых модулей
Установка Azure Toolkit for Eclipse
Инструкции по установке см. в статье Установка набора средств Azure для Eclipse.
Установка подключаемого модуля Scala
При открытии Eclipse средства HDInsight автоматически определяют, установлен ли подключаемый модуль Scala. Щелкните ОК, чтобы продолжить, и следуйте инструкциям по установке подключаемого модуля из Eclipse Marketplace. Перезапустите интегрированную среду разработки после завершения установки.
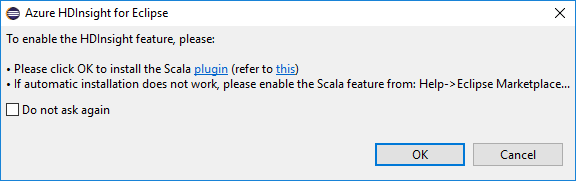
Подтверждение подключаемых модулей
Перейдите в раздел Справка >Eclipse Marketplace....
Откройте вкладку Установленные.
Должны отображаться по крайней мере следующие компоненты.
- <Версия> Azure Toolkit for Eclipse.
- <Версия> интегрированной среды разработки Scala.
Войдите в подписку Azure.
Запустите интегрированную среду разработки Eclipse.
Перейдите в раздел Окно >Показать представление >Другие... >Войти....
В диалоговом окне Показать представление перейдите в раздел Azure >Azure Explorer и нажмите кнопку Открыть.

В Azure Explorer щелкните правой кнопкой мыши узел Azure, а затем выберите Войти.
В диалоговом окне Вход в Azure выберите способ проверки подлинности, нажмите кнопку Войти и завершите процесс входа.
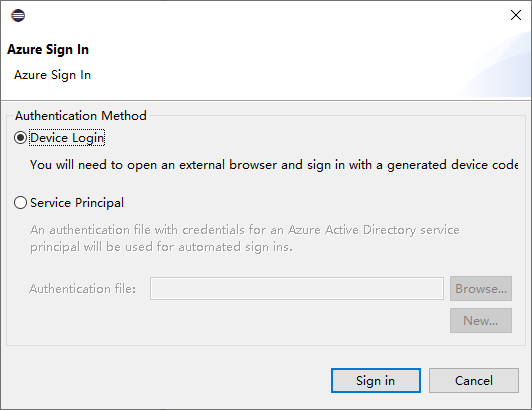
После входа в диалоговом окне Ваши подписки будут перечислены все подписки Azure, связанные с указанными учетными данными. Щелкните Выбрать, чтобы закрыть диалоговое окно.
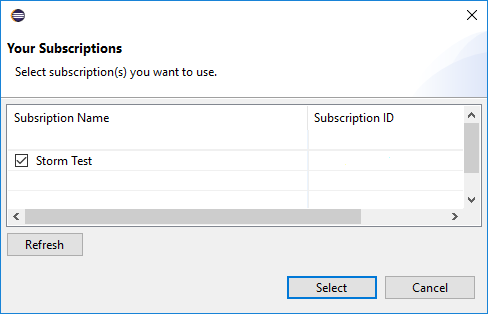
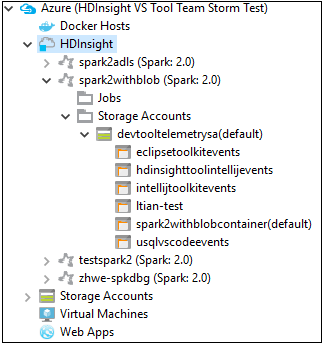
На вкладке Azure Explorer перейдите в раздел Azure >HDInsight, чтобы просмотреть кластеры HDInsight Spark в своей подписке.
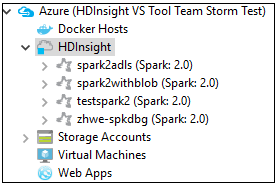
Далее можно развернуть узел имени кластера, чтобы увидеть ресурсы (например, учетные записи хранения), связанные с ним.
Связывание кластера
Можно связать обычный кластер с помощью управляемого имени пользователя Ambari. Аналогичным образом, присоединенный к домену кластер HDInsight можно связать с помощью домена и имени пользователя, например user1@contoso.com.
В Azure Explorer щелкните правой кнопкой мыши HDInsight, а затем — Связать кластер.
Введите имя кластера, имя пользователя и пароль, а затем нажмите кнопку OK. При необходимости введите учетную запись хранения, ключ к хранилищу данных, а затем выберите в представлении в виде дерева контейнер хранилища для обозревателя хранилищ.
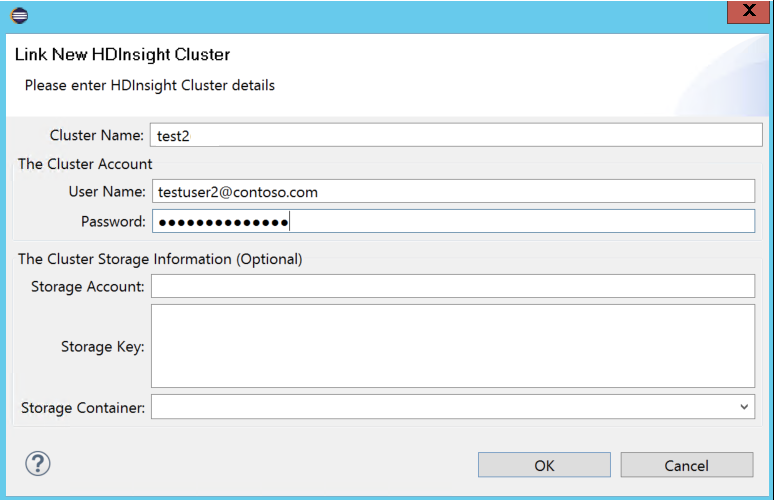
Примечание.
Если кластер зарегистрирован в подписке Azure и связан, используется ключ к хранилищу данных, имя пользователя и пароль для связывания.
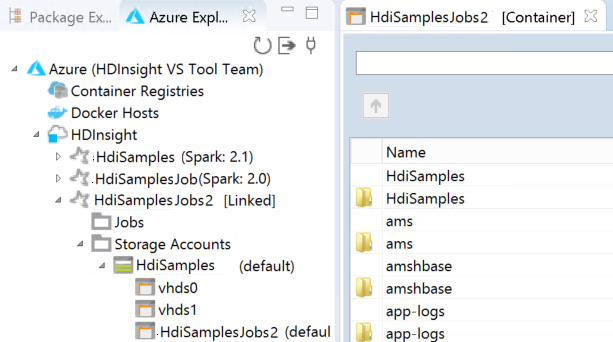
Когда текущий фокус находится на ключе к хранилищу данных, для пользователя с доступом только к клавиатуре необходимо использовать сочетание клавиш Ctrl+TAB, чтобы переместить фокус на следующее поле в диалоговом окне.
Связанный кластер отображается в разделе HDInsight. Теперь в этот связанный кластер можно отправить приложение.
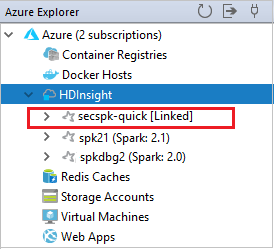
В обозревателе Azure также можно удалить связь кластера.
Настройка проекта Spark Scala для кластера HDInsight Spark
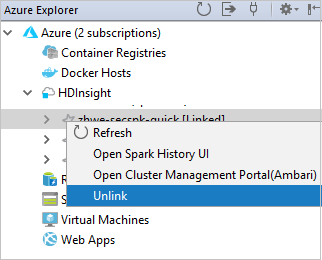
В рабочей области IDE Eclipse выберите Файл >Создать >Проект....
В мастере Новый проект выберите Проект HDInsight >Spark в HDInsight (Scala). Затем выберите Далее.
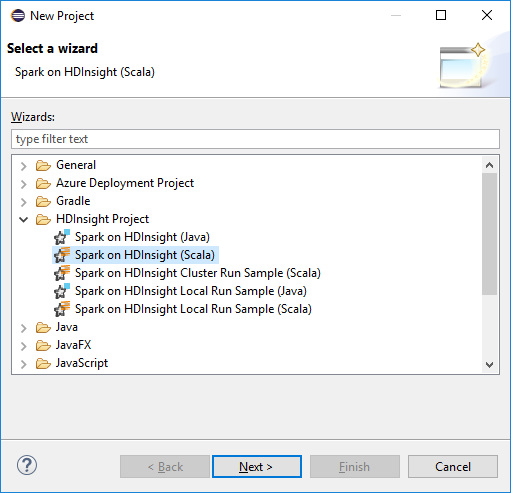
В диалоговом окне New HDInsight Scala Project (Новый проект Scala HDInsight) введите следующие значения, после чего нажмите кнопку Next (Далее).
- Введите имя проекта.
- Убедитесь, что в поле JRE параметр Use an execution environment JRE (Использовать среду выполнения JRE) имеет значение JavaSE-1.7 или более позднюю версию.
- В области библиотеки Spark вы можете выбрать вариант Use Maven to configure Spark SDK (Использовать Maven для настройки пакета SDK для Spark). Наше средство интегрирует правильную версию пакета SDK для Spark и пакета SDK для Scala. Вы также можете выбрать вариант Добавить пакет SDK для Spark вручную, скачать этот пакет и добавить его вручную.
В следующем диалоговом окне проверьте сведения и выберите Готово.
Создание приложения Scala для кластера HDInsight Spark
В обозревателе пакетов разверните проект, созданный ранее. Щелкните правой кнопкой мыши элемент src, выберите Создать >Другой....
В диалоговом окне Выбор мастера выберите Мастера Scala >Объект Scala. Затем выберите Далее.
В диалоговом окне Create New File (Создание файла) введите имя объекта и нажмите кнопку Finish (Готово). Откроется текстовый редактор.
В текстовом редакторе замените текущее содержимое следующим кодом:
import org.apache.spark.SparkConf import org.apache.spark.SparkContext object MyClusterApp{ def main (arg: Array[String]): Unit = { val conf = new SparkConf().setAppName("MyClusterApp") val sc = new SparkContext(conf) val rdd = sc.textFile("wasbs:///HdiSamples/HdiSamples/SensorSampleData/hvac/HVAC.csv") //find the rows that have only one digit in the seventh column in the CSV val rdd1 = rdd.filter(s => s.split(",")(6).length() == 1) rdd1.saveAsTextFile("wasbs:///HVACOut") } }Запустите приложение в кластере HDInsight Spark.
a. В обозревателе пакетов щелкните имя проекта правой кнопкой мыши и выберите пункт Submit Spark Application to HDInsight (Отправить приложение Spark в HDInsight).
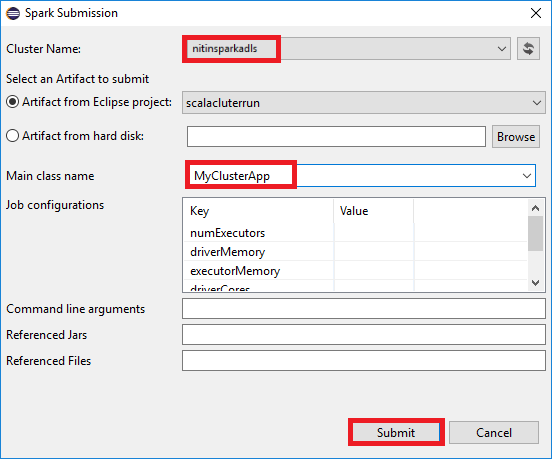
b. В диалоговом окне Spark Submission (Отправка в Spark) введите следующие значения и нажмите кнопку Submit (Отправить).
В поле Cluster Name(Имя кластера) выберите кластер HDInsight Spark, в котором вы хотите запустить приложение.
Выберите артефакт из проекта Eclipse или с жесткого диска. Значение по умолчанию зависит от элемента, который вы щелкнете правой кнопкой мыши в обозревателе пакетов.
В раскрывающемся списке Main class name (Имя класса main) в мастере отправки отображаются имена всех объектов из вашего проекта. Выберите или введите имя любого из объектов, который требуется запустить. Если вы выбрали артефакт с жесткого диска, необходимо ввести имя класса main вручную.
Поскольку для кода приложения в этом примере не требуются аргументы командной строки, справочные JAR или файлы, остальные текстовые поля можно не заполнять.
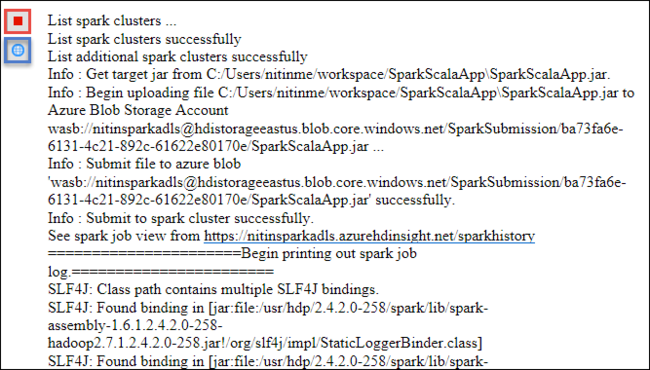
На вкладке Spark Submission (Отправка в Spark) начнет отображаться ход выполнения. Приложение можно остановить, нажав красную кнопку в окне Spark Submission (Отправка в Spark). Можно также просмотреть журналы для данного запуска приложения, щелкнув значок глобуса (обозначен на рисунке синей рамкой).
Доступ к кластерам HDInsight Spark и управление ими с помощью средств HDInsight в наборе средств Azure для Eclipse
С помощью средств HDInsight можно выполнять различные операции, включая доступ к выходным данным заданий.
Доступ к представлению задания
В Azure Explorer разверните HDInsight, а затем выберите имя кластера Spark, после чего щелкните Задания.
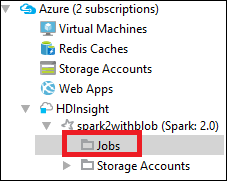
Перейдите на вкладку Задания. Если версия Java ниже, чем 1.8, средства HDInsight автоматически отправят напоминание об установке подключаемого модуля E(fx)clipse. Щелкните ОК, чтобы продолжить, и следуйте инструкциям мастера для установки подключаемого модуля из Eclipse Marketplace. По завершении перезапустите Eclipse.
Откройте представление задания из узла Задания. В области справа на вкладке Spark Job View (Просмотр заданий Spark) отображаются все приложения, запускаемые в кластере. Выберите имя приложения, дополнительные сведения о котором вы хотите просмотреть.
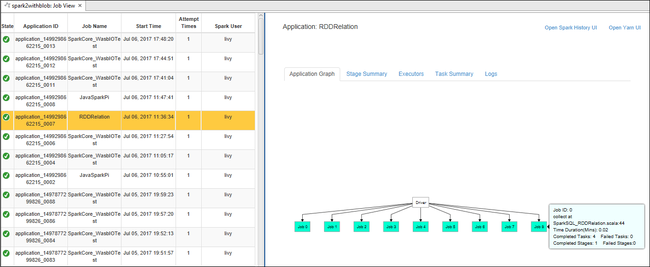
Затем можно использовать любое из следующих действий:
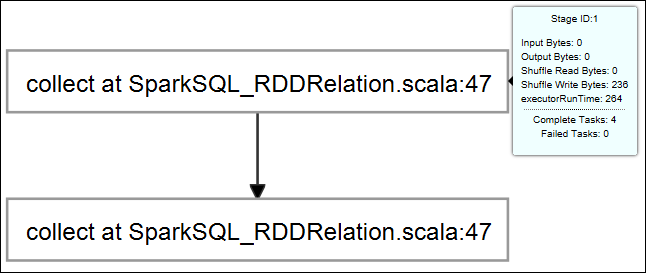
Наведите указатель мыши на граф задания. На нем отображаются основные сведения о выполняемом задании. Щелкните граф задания, и вы увидите его этапы и сведения, создаваемые каждым заданием.
Выберите вкладку Журнал, чтобы просмотреть часто используемые журналы, включая Driver Stderr, Driver Stdout и Directory Info.

Откройте пользовательский интерфейс журнала Spark и пользовательский интерфейс Apache Hadoop YARN (на уровне приложения), щелкнув ссылки в верхней части окна.
Доступ к контейнеру хранилища для кластера
В Azure Explorer разверните корневой узел HDInsight, чтобы увидеть список доступных кластеров HDInsight Spark.
Разверните имя кластера, чтобы увидеть учетную запись хранилища и контейнер хранилища по умолчанию для кластера.
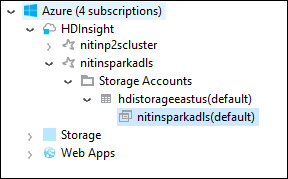
Выберите имя связанного с кластером контейнера хранилища. В области справа дважды щелкните папку HVACOut. Откройте один из файлов part- для просмотра выходных данных приложения.
Доступ к серверу журнала Spark
В Azure Explorer щелкните имя кластера Spark правой кнопкой мыши и выберите пункт Open Spark History UI (Открыть пользовательский интерфейс журнала Spark). При появлении запроса введите учетные данные администратора для кластера. Вы указали их при подготовке кластера.
На панели мониторинга сервера журнала Spark вы сможете найти приложение, выполнение которого только что было завершено, по его имени. В приведенном выше коде имя приложения было указано с помощью
val conf = new SparkConf().setAppName("MyClusterApp"). Следовательно, приложение Spark называлось MyClusterApp.
Запуск портала Apache Ambari
В Azure Explorer щелкните имя кластера Spark правой кнопкой мыши и выберите пункт Open Cluster Management Portal (Ambari) (Открыть портал управления кластерами (Ambari)).
При появлении запроса введите учетные данные администратора для кластера. Вы указали их при подготовке кластера.
Управление подписками Azure
По умолчанию средство HDInsight в наборе средств Azure для Eclipse содержит список кластеров Spark из всех ваших подписок Azure. При необходимости можно указать подписки, кластеры из которых вас интересуют.
В Azure Explorer щелкните правой кнопкой мыши корневой узел Azure, а затем выберите Управление подписками.
В диалоговом окне снимите флажки напротив подписок, доступ к которым вам не требуется, и нажмите кнопку Закрыть. Если вы хотите выйти из своей подписки Azure, выберите Выйти.
Запуск приложения Spark Scala на локальном компьютере
Средства HDInsight в наборе средств Azure для Eclipse позволяют запускать приложения Spark Scala локально на рабочей станции. Как правило, такие приложения не требуют доступа к ресурсам кластера, таким как контейнер хранилища, и могут запускаться и тестироваться локально.
Необходимые условия
При запуске локального приложения Spark Scala на компьютере с Windows может возникнуть исключение, описанное в SPARK-2356. Это исключение возникает, так как в Windows отсутствует файл WinUtils.exe.
Чтобы устранить эту ошибку, необходимо скачать исполняемый файл Winutils.exe, например в папку C:\WinUtils\bin, а затем добавить переменную среды HADOOP_HOME и задать C\WinUtils в качестве значения переменной.
Запуск локального приложения Spark Scala
Запустите Eclipse и создайте новый проект. В диалоговом окне New Project (Новый проект) установите параметры, как на снимке экрана ниже, а затем нажмите кнопку Next (Далее).
В мастере Новый проект выберите Проект HDInsight >Образец локального запуска Spark в HDInsight (Scala). Затем выберите Далее.

Чтобы предоставить сведения о проекте, выполните шаги 3–6, как описано в разделе Настройка проекта Spark Scala для кластера HDInsight Spark.
Шаблон добавляет пример кода (LogQuery) в папку src, который можно запустить локально на компьютере.
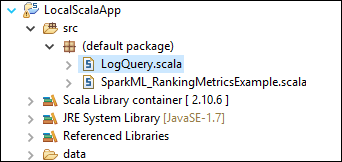
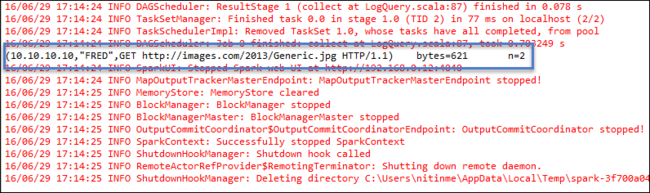
Щелкните правой кнопкой мыши LogQuery.scala и выберите Запуск от имени >1 приложение Scala. На вкладке Console (Консоль) отобразятся выходные данные следующего вида.
Роль только для чтения
Когда пользователи отправляют задания в кластер с разрешением на роль только для чтения, требуются учетные данные Ambari.
Связывание кластера из контекстного меню
Войдите с помощью учетной записи роли только для чтения.
В Azure Explorer разверните HDInsight, чтобы просмотреть кластеры HDInsight в своей подписке. Кластеры с пометкой Role:Reader, имеют только разрешение роли только для чтения.
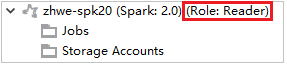
Щелкните правой кнопкой мыши кластер с разрешением роли только для чтения. Выберите Link this cluster (Связать этот кластер) из контекстного меню, чтобы связать кластер. Введите имя пользователя и пароль Ambari.
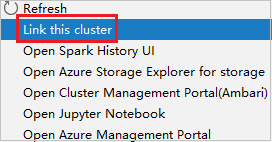
Если кластер связан успешно, HDInsight будет обновлен. Этап кластера станет связанным.
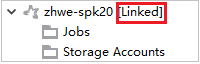
Связывание кластера путем развертывания узла "Задания"
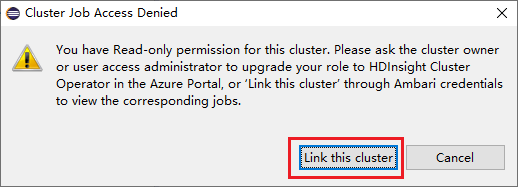
Щелкните узел Задания и появится всплывающее окно Cluster Job Access Denied (Доступ к заданию кластера запрещен).
Щелкните Link this cluster (Связать этот кластер), чтобы связать кластер.
Связывание кластера в окне отправки Spark
Создайте кластер HDInsight.
Щелкните пакет правой кнопкой мыши. Затем выберите Отправить приложение Spark в HDInsight.
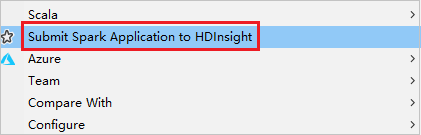
Выберите кластер, у которого есть разрешение роли только для чтения для Имя кластера. Появится сообщение с предупреждением. Вы можете щелкнуть Связать этот кластер, чтобы связать кластер.
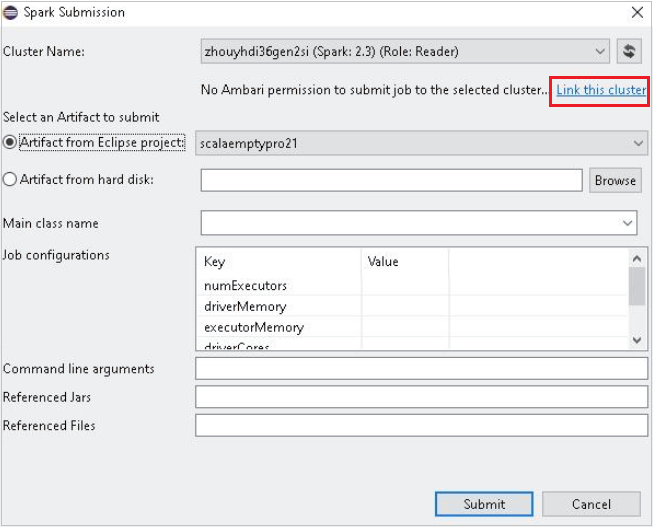
Просмотр учетных записей хранения
Для кластеров с разрешением роли только для чтения щелкните узел Учетные записи хранения и появится всплывающее окно Storage Access Denied (Доступ к хранилищу запрещен).
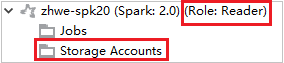
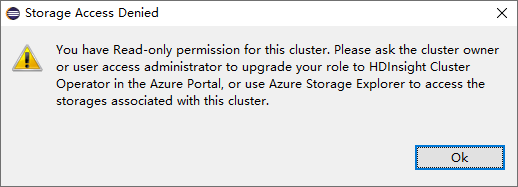
Для связанных кластеров щелкните узел Учетные записи хранения и появится всплывающее окно Storage Access Denied (Доступ к хранилищу запрещен).

Известные проблемы
Рекомендуем при связывании кластера указать учетные данные хранилища.
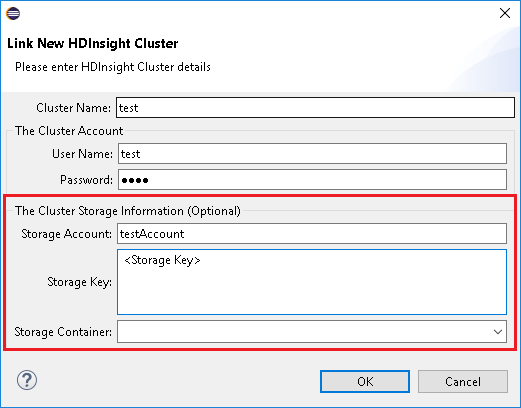
Существует два режима отправки заданий. Если учетные данные хранилища указаны, для отправки задания будет использоваться пакетный режим. В противном случае будет использоваться интерактивный режим. Если кластер занят, может появиться приведенная ниже ошибка.


См. также
Сценарии
- Использование Apache Spark со средствами бизнес-аналитики. Выполнение интерактивного анализа данных с использованием Spark в HDInsight с помощью средств бизнес-аналитики
- Apache Spark и Машинное обучение. Анализ температуры в здании на основе данных системы кондиционирования с помощью Spark в HDInsight
- Apache Spark и Машинное обучение. Прогнозирование результатов проверки пищевых продуктов с помощью Spark в HDInsight
- Анализ журналов веб-сайтов с помощью Apache Spark в HDInsight
Создание и запуск приложений
- Создание автономного приложения с использованием Scala
- Удаленный запуск заданий с помощью Apache Livy в кластере Apache Spark
Инструменты и расширения
- Создание приложений Spark для кластера HDInsight с помощью набора средств Azure для IntelliJ
- Удаленная отладка приложений Spark в HDInsight через VPN с помощью Azure Toolkit for IntelliJ
- Удаленная или локальная отладка приложений Spark в кластере HDInsight с помощью Azure Toolkit for IntelliJ через SSH
- Использование записных книжек Zeppelin с кластером Apache Spark в Azure HDInsight
- Ядра, доступные для Jupyter Notebook в кластерах Apache Spark в HDInsight
- Использование внешних пакетов с Jupyter Notebook
- Установка записной книжки Jupyter на компьютере и ее подключение к кластеру Apache Spark в Azure HDInsight (предварительная версия)