Устранение неполадок в Apache Spark с помощью Azure HDInsight
Ознакомьтесь с основными проблемами, которые возникают при работе с полезными данными Apache Spark в Apache Ambari, и способами их решения.
Как настроить приложение Apache Spark с помощью Apache Ambari в кластерах?
Можно настроить значения конфигурации Spark, чтобы избежать исключения OutofMemoryError в приложении Apache Spark. На этапах ниже показаны значения конфигурации Spark по умолчанию в Azure HDInsight.
Войдите в Ambari по адресу
https://CLUSTERNAME.azurehdidnsight.netс помощью учетных данных кластера. На начальном экране показана панель мониторинга с общими сведениями. Существуют незначительные косметические различия между HDInsight 4.0.Перейдите в раздел Spark2>Configs.
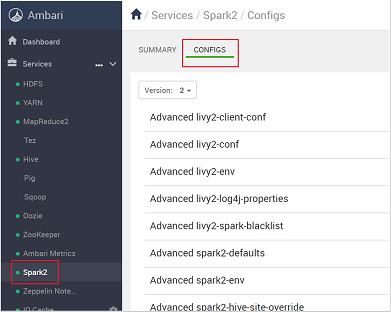
В списке конфигураций выберите и разверните Custom-spark2-defaults.
Найдите параметр значения, который необходимо настроить, например spark.executor.memory. В этом случае значение 9728m слишком высокое.
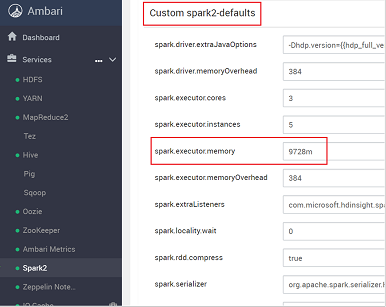
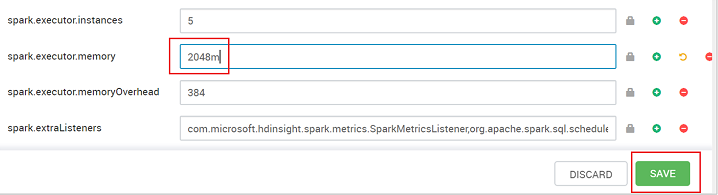
Задайте для этого параметра рекомендуемое значение. Рекомендуется использовать значение 2048m.
Сохраните это значение, а затем сохраните конфигурацию. Выберите Сохранить.
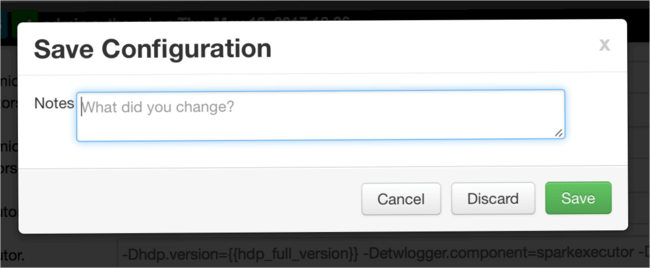
Запишите примечание об изменениях конфигурации, а затем нажмите кнопку Сохранить.
Вы получите уведомление, если какие-либо конфигурации требуют внимания. Проверьте элементы, а затем нажмите кнопку Proceed Anyway (Продолжить).

При сохранении конфигурации вам будет предложено перезапустить службу. Выберите Перезапустить.
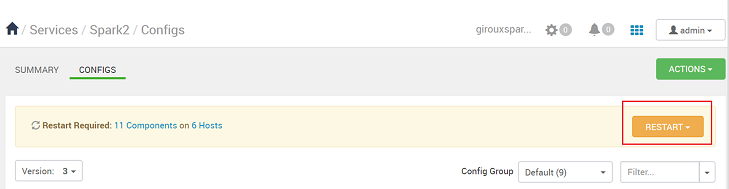
Подтвердите перезапуск.
Вы можете просмотреть запущенные процессы.
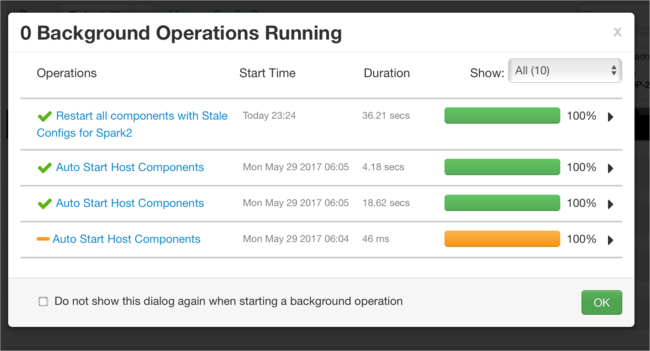
Вы можете добавить конфигурации. В списке конфигураций выберите Custom-spark2-defaults, а затем щелкните Добавить свойство.
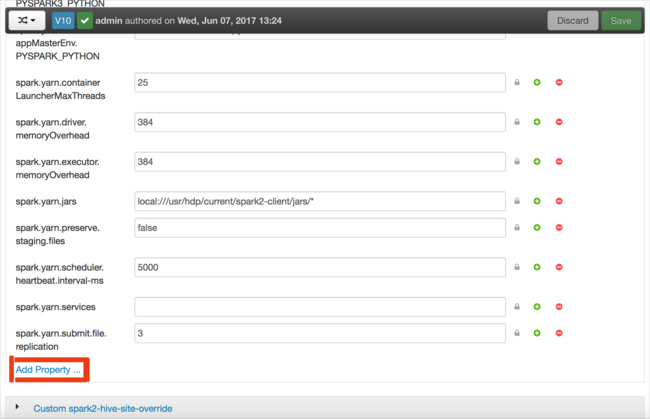
Определите новое свойство. Вы можете определить отдельное свойство с помощью диалогового окна для определенных параметров, например тип данных. Или вы можете определить несколько свойств с одним определением на строку.
В этом примере свойство spark.driver.memory определяется со значением 4 ГБ.

Сохраните конфигурацию и перезапустите службу, как описано на шагах 6 и 7.
Эти изменения применяются на уровне кластера, но их можно переопределить при отправке задания Spark.
Как настроить приложение Apache Spark с помощью Jupyter Notebook в кластерах?
Укажите конфигурации Spark в допустимом формате JSON в первой ячейке Jupyter Notebook после директивы %%configure. При необходимости измените фактические значения:

Как настроить приложение Apache Spark с помощью Apache Livy в кластерах?
Отправьте приложение Spark в Livy с помощью клиента REST, например cURL. Используйте команду, аналогичную приведенной ниже. При необходимости измените фактические значения:
curl -k --user 'username:password' -v -H 'Content-Type: application/json' -X POST -d '{ "file":"wasb://container@storageaccountname.blob.core.windows.net/example/jars/sparkapplication.jar", "className":"com.microsoft.spark.application", "numExecutors":4, "executorMemory":"4g", "executorCores":2, "driverMemory":"8g", "driverCores":4}'
Как настроить приложение Apache Spark с помощью spark-submit в кластерах?
Запустите оболочку Spark с помощью команды, аналогичной приведенной ниже. При необходимости измените фактические значения конфигураций:
spark-submit --master yarn-cluster --class com.microsoft.spark.application --num-executors 4 --executor-memory 4g --executor-cores 2 --driver-memory 8g --driver-cores 4 /home/user/spark/sparkapplication.jar
Дополнительное чтение
Отправка заданий Apache Spark в кластерах HDInsight
Следующие шаги
Если вы не видите своего варианта проблемы или вам не удается ее устранить, дополнительные сведения можно получить, посетив один из следующих каналов.
Получите ответы специалистов Azure на сайте поддержки сообщества пользователей Azure.
Подпишитесь на @AzureSupport — официальный канал Microsoft Azure для улучшения качества взаимодействия с клиентами. Вступайте в сообщество Azure для получения нужных ресурсов: ответов, поддержки и советов экспертов.
Если вам нужна дополнительная помощь, отправьте запрос в службу поддержки на портале Azure. Выберите Поддержка в строке меню или откройте центр Справка и поддержка. Дополнительные сведения см. в статье Создание запроса на поддержку Azure. Доступ к управлению подписками и поддержкой выставления счетов уже включен в вашу подписку Microsoft Azure, а техническая поддержка предоставляется в рамках одного из планов Службы поддержки Azure.