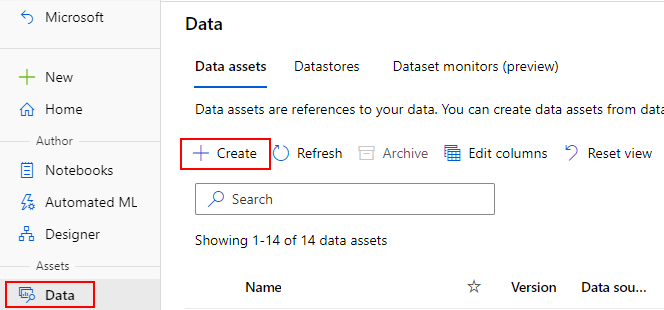
Создание ресурсов данных и управление ими
ОБЛАСТЬ ПРИМЕНЕНИЯ: Расширение машинного обучения Azure CLI версии 2 (current)Python SDK azure-ai-ml версии 2 (current)
Расширение машинного обучения Azure CLI версии 2 (current)Python SDK azure-ai-ml версии 2 (current)
В этой статье показано, как создавать ресурсы данных и управлять ими в Машинное обучение Azure.
Ресурсы данных могут помочь при необходимости в следующих возможностях:
- Управление версиями. Ресурсы данных поддерживают управление версиями данных.
- Воспроизводимость. После создания версии ресурса данных она неизменяема. Его нельзя изменить или удалить. Таким образом, можно воспроизвести задания обучения или конвейеры, использующие ресурс данных.
- Возможность аудита. Так как версия ресурса данных неизменяема, можно отслеживать версии ресурсов, которые обновили версию и когда произошли обновления версий.
- Происхождение: для любого заданного ресурса данных можно просмотреть задания или конвейеры, которые используют данные.
- Простота использования: ресурс данных машинного обучения Azure напоминает закладки веб-браузера (избранное). Вместо запоминания длинных путей хранения (URI), ссылающихся на часто используемые данные на служба хранилища Azure, можно создать версию ресурса данных, а затем получить доступ к этой версии ресурса с понятным именем (например:
azureml:<my_data_asset_name>:<version>).
Совет
Чтобы получить доступ к данным в интерактивном сеансе (например, записной книжке) или задании, вам не нужно сначала создать ресурс данных. Для доступа к данным можно использовать URI хранилища данных. URI хранилища данных предоставляют простой способ доступа к данным для тех, кто начинает работу с машинным обучением Azure.
Необходимые компоненты
Для создания ресурсов данных и работы с ними требуются компоненты, указанные ниже.
Подписка Azure. Если у вас еще нет подписки Azure, создайте бесплатную учетную запись, прежде чем начать работу. Попробуйте бесплатную или платную версию Машинного обучения Azure.
Рабочая область Машинного обучения Azure. Создание ресурсов рабочей области.
Установлен Машинное обучение Azure CLI/SDK.
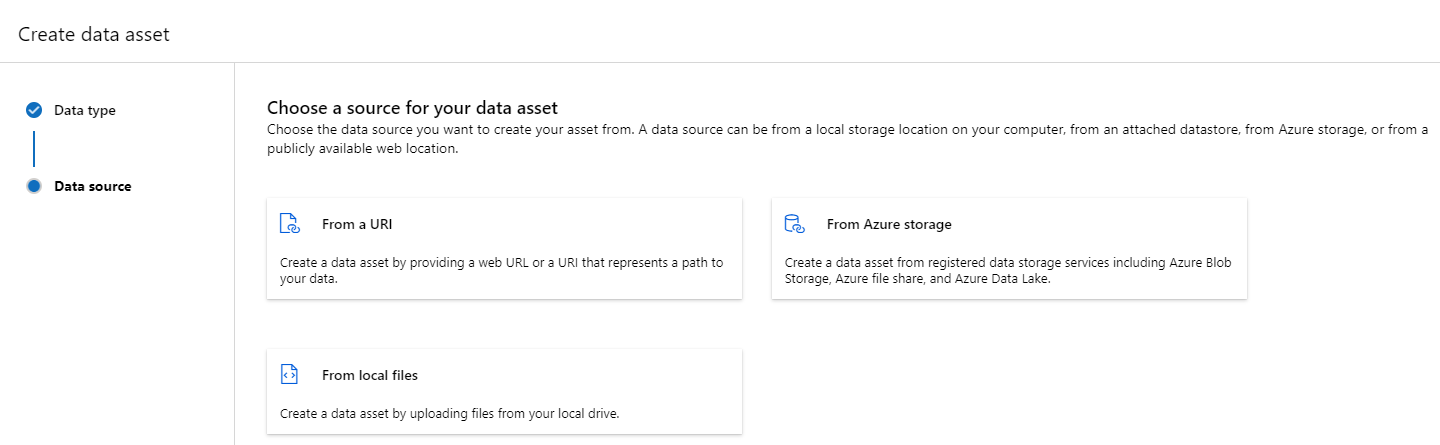
Создание ресурсов данных
При создании ресурса данных необходимо задать тип ресурса данных. Машинное обучение Azure поддерживает три типа ресурсов данных:
| Тип | API | Канонические сценарии |
|---|---|---|
| Файл Ссылка на один файл |
uri_file |
Чтение одного файла на служба хранилища Azure (файл может иметь любой формат). |
| Папка Ссылка на папку |
uri_folder |
Чтение папки parquet/CSV-файлов в Pandas/Spark. Чтение неструктурированных данных (изображений, текста, звука и т. д.), расположенных в папке. |
| Таблицу Ссылка на таблицу данных |
mltable |
У вас есть сложная схема с частыми изменениями или требуется подмножество больших табличных данных. AutoML с таблицами. Чтение неструктурированных данных (изображений, текста, звука и т. д.), которые распределяются по нескольким расположениям хранилища. |
Примечание.
Не используйте внедренные новые линии в CSV-файлах, если данные не регистрируются в качестве MLTable. Внедренные новые линии в CSV-файлах могут привести к неправильному значению поля при чтении данных. MLTable имеет этот параметр support_multi_lineв read_delimited преобразовании, чтобы интерпретировать разрывы строк в кавычках как одну запись.
При использовании ресурса данных в задании Машинное обучение Azure можно подключить или скачать ресурс на вычислительные узлы. Дополнительные сведения см. в режимах чтения.
Кроме того, необходимо указать параметр, указывающий path на расположение ресурса данных. К поддерживаемым путям относятся:
| Местонахождение | Примеры |
|---|---|
| Путь к локальному компьютеру | ./home/username/data/my_data |
| Путь к хранилищу данных | azureml://datastores/<data_store_name>/paths/<path> |
| Путь к общедоступному HTTP(S)-серверу | https://raw.githubusercontent.com/pandas-dev/pandas/main/doc/data/titanic.csv |
| Путь к службе хранилища Azure | (БОЛЬШОЙ двоичный объект) wasbs://<containername>@<accountname>.blob.core.windows.net/<path_to_data>/(ADLS 2-го поколения) abfss://<file_system>@<account_name>.dfs.core.windows.net/<path> (ADLS 1-го поколения) adl://<accountname>.azuredatalakestore.net/<path_to_data>/ |
Примечание.
При создании ресурса данных из локального пути он автоматически отправляется в хранилище данных по умолчанию Машинное обучение Azure облачного хранилища данных.
Создание ресурса данных: тип файла
Ресурс данных, представляющий собой тип файла (uri_file), указывает на один файл в хранилище (например, CSV-файл). Вы можете создать ресурс данных с типизированным файлом, используя следующее:
Создайте файл YAML и скопируйте и вставьте следующий код. Заполнители необходимо обновить <> с именем ресурса данных, версией, описанием и путем к одному файлу в поддерживаемом расположении.
$schema: https://azuremlschemas.azureedge.net/latest/data.schema.json
# Supported paths include:
# local: './<path>/<file>' (this will be automatically uploaded to cloud storage)
# blob: 'wasbs://<container_name>@<account_name>.blob.core.windows.net/<path>/<file>'
# ADLS gen2: 'abfss://<file_system>@<account_name>.dfs.core.windows.net/<path>/<file>'
# Datastore: 'azureml://datastores/<data_store_name>/paths/<path>/<file>'
type: uri_file
name: <NAME OF DATA ASSET>
version: <VERSION>
description: <DESCRIPTION>
path: <SUPPORTED PATH>
Затем выполните следующую команду в CLI (обновите <filename> заполнитель до имени файла YAML):
az ml data create -f <filename>.yml

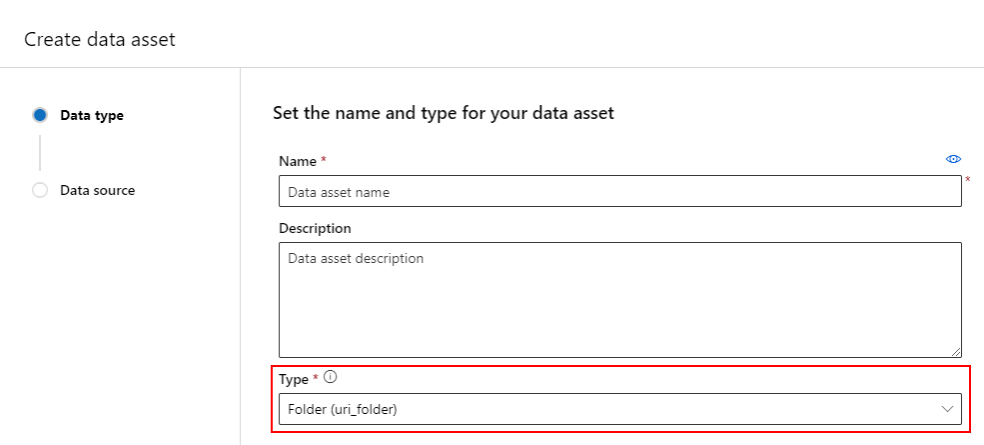
Создание ресурса данных: тип папки
Ресурс данных, представляющий собой тип папки (uri_folder), указывает на папку в хранилище (например, папку, содержащую несколько вложенных папок изображений). Вы можете создать ресурс данных с типизированным типом папки, используя следующее:
Создайте файл YAML и скопируйте и вставьте следующий код. Заполнители необходимо обновить <> с именем ресурса данных, версией, описанием и путем к папке в поддерживаемом расположении.
$schema: https://azuremlschemas.azureedge.net/latest/data.schema.json
# Supported paths include:
# local: './<path>/<folder>' (this will be automatically uploaded to cloud storage)
# blob: 'wasbs://<container_name>@<account_name>.blob.core.windows.net/<path>/<folder>'
# ADLS gen2: 'abfss://<file_system>@<account_name>.dfs.core.windows.net/<path>/<folder>'
# Datastore: 'azureml://datastores/<data_store_name>/paths/<path>/<folder>'
type: uri_folder
name: <NAME OF DATA ASSET>
version: <VERSION>
description: <DESCRIPTION>
path: <SUPPORTED PATH>
Затем выполните следующую команду в ИНТЕРФЕЙСе командной строки (обновите <filename> заполнитель до имени файла YAML):
az ml data create -f <filename>.yml
Создание ресурса данных: тип таблицы
Машинное обучение Azure таблицы (MLTable) имеют широкие функциональные возможности, подробно описанные в статье "Работа с таблицами в Машинное обучение Azure". Вместо повторения этой документации мы предоставляем пример создания ресурса данных с типизированными таблицами, используя титанические данные, расположенные на общедоступной Хранилище BLOB-объектов Azure учетной записи.
Сначала создайте новый каталог, называемый данными, и создайте файл с именем MLTable:
mkdir data
touch MLTable
Затем скопируйте и вставьте следующий YAML в файл MLTable , созданный на предыдущем шаге:
Внимание
Не переименуйте файл MLTable.yaml в MLTable илиMLTable.yml. Машинное обучение Azure ожидает MLTable файл.
paths:
- file: wasbs://data@azuremlexampledata.blob.core.windows.net/titanic.csv
transformations:
- read_delimited:
delimiter: ','
empty_as_string: false
encoding: utf8
header: all_files_same_headers
include_path_column: false
infer_column_types: true
partition_size: 20971520
path_column: Path
support_multi_line: false
- filter: col('Age') > 0
- drop_columns:
- PassengerId
- convert_column_types:
- column_type:
boolean:
false_values:
- 'False'
- 'false'
- '0'
mismatch_as: error
true_values:
- 'True'
- 'true'
- '1'
columns: Survived
type: mltable
Затем выполните следующую команду в интерфейсе командной строки. Обязательно обновите <> заполнители с использованием имени ресурса данных и значений версии.
az ml data create --path ./data --name <DATA ASSET NAME> --version <VERSION> --type mltable
Важно!
Должно path быть папка , содержащая допустимый MLTable файл.
Создание ресурсов данных из выходных данных задания
Вы можете создать ресурс данных из задания Машинное обучение Azure, задав name параметр в выходных данных. В этом примере вы отправляете задание, которое копирует данные из общедоступного хранилища BLOB-объектов в хранилище данных по умолчанию Машинное обучение Azure datastore и создает ресурс данных с именемjob_output_titanic_asset.
Создайте файл YAML спецификации задания (<file-name>.yml):
$schema: https://azuremlschemas.azureedge.net/latest/commandJob.schema.json
# path: Set the URI path for the data. Supported paths include
# local: `./<path>
# Blob: wasbs://<container_name>@<account_name>.blob.core.windows.net/<path>
# ADLS: abfss://<file_system>@<account_name>.dfs.core.windows.net/<path>
# Datastore: azureml://datastores/<data_store_name>/paths/<path>
# Data Asset: azureml:<my_data>:<version>
# type: What type of data are you pointing to?
# uri_file (a specific file)
# uri_folder (a folder)
# mltable (a table)
# mode: Set INPUT mode:
# ro_mount (read-only mount)
# download (download from storage to node)
# mode: Set the OUTPUT mode
# rw_mount (read-write mount)
# upload (upload data from node to storage)
type: command
command: cp ${{inputs.input_data}} ${{outputs.output_data}}
compute: azureml:cpu-cluster
environment: azureml://registries/azureml/environments/sklearn-1.1/versions/4
inputs:
input_data:
mode: ro_mount
path: azureml:wasbs://data@azuremlexampledata.blob.core.windows.net/titanic.csv
type: uri_file
outputs:
output_data:
mode: rw_mount
path: azureml://datastores/workspaceblobstore/paths/quickstart-output/titanic.csv
type: uri_file
name: job_output_titanic_asset
Затем отправьте задание с помощью интерфейса командной строки:
az ml job create --file <file-name>.yml
Управление ресурсами-контейнерами данных
Удаление ресурса данных
Важно!
По проектированию удаление ресурса данных не поддерживается.
Если машинное обучение Azure позволило удалить ресурс данных, это приведет к следующим негативным последствиям:
- Рабочие задания , использующие ресурсы данных, которые были удалены позже, завершится сбоем.
- Было бы труднее воспроизвести эксперимент машинного обучения.
- Происхождение заданий будет нарушено, так как невозможно просмотреть удаленную версию ресурса данных.
- Вы не сможете правильно отслеживать и проверять , так как версии могут быть отсутствуют.
Таким образом, неизменяемость ресурсов данных обеспечивает уровень защиты при работе в команде, создавая рабочие нагрузки рабочей среды.
Если ресурс данных был ошибочно создан, например с неправильным именем, типом или путем, Машинное обучение Azure предлагает решения для обработки ситуации без негативных последствий удаления:
| Я хочу удалить этот ресурс данных, так как... | Решение |
|---|---|
| Неправильное имя | Архивация ресурса данных |
| Команда больше не использует ресурс данных | Архивация ресурса данных |
| Он загромождает список ресурсов данных | Архивация ресурса данных |
| Неправильный путь | Создайте новую версию ресурса данных (то же имя) с правильным путем. Дополнительные сведения см. в статье "Создание ресурсов данных". |
| Он имеет неправильный тип | В настоящее время Машинное обучение Azure не позволяет создавать новую версию с другим типом по сравнению с исходной версией. (1) Архивация ресурса данных (2) Создайте новый ресурс данных под другим именем с правильным типом. |
Архивация ресурса данных
Архивация ресурса данных по умолчанию скрывается из обоих запросов списка (например, в CLI az ml data list) и в списке ресурсов данных в пользовательском интерфейсе Studio. Вы по-прежнему можете ссылаться и использовать архивированный ресурс данных в рабочих процессах. Вы можете архивировать:
- все версии ресурса данных под заданным именем или
- определенная версия ресурса данных
Архивация всех версий ресурса данных
Чтобы архивировать все версии ресурса данных под заданным именем, используйте следующую команду:
Выполните следующую команду (обновите <> заполнитель с именем ресурса данных):
az ml data archive --name <NAME OF DATA ASSET>
Архивация определенной версии ресурса данных
Чтобы архивировать определенную версию ресурса данных, используйте:
Выполните следующую команду (обновите <> заполнители с именем ресурса данных и версией):
az ml data archive --name <NAME OF DATA ASSET> --version <VERSION TO ARCHIVE>
Восстановление архивированного ресурса данных
Архивный ресурс данных можно восстановить. Если архивируются все версии ресурса данных, восстановление отдельных версий ресурса данных невозможно. Необходимо восстановить все версии.
Восстановление всех версий ресурса данных
Чтобы восстановить все версии ресурса данных под заданным именем, используйте следующую команду:
Выполните следующую команду (обновите <> заполнитель с именем ресурса данных):
az ml data restore --name <NAME OF DATA ASSET>

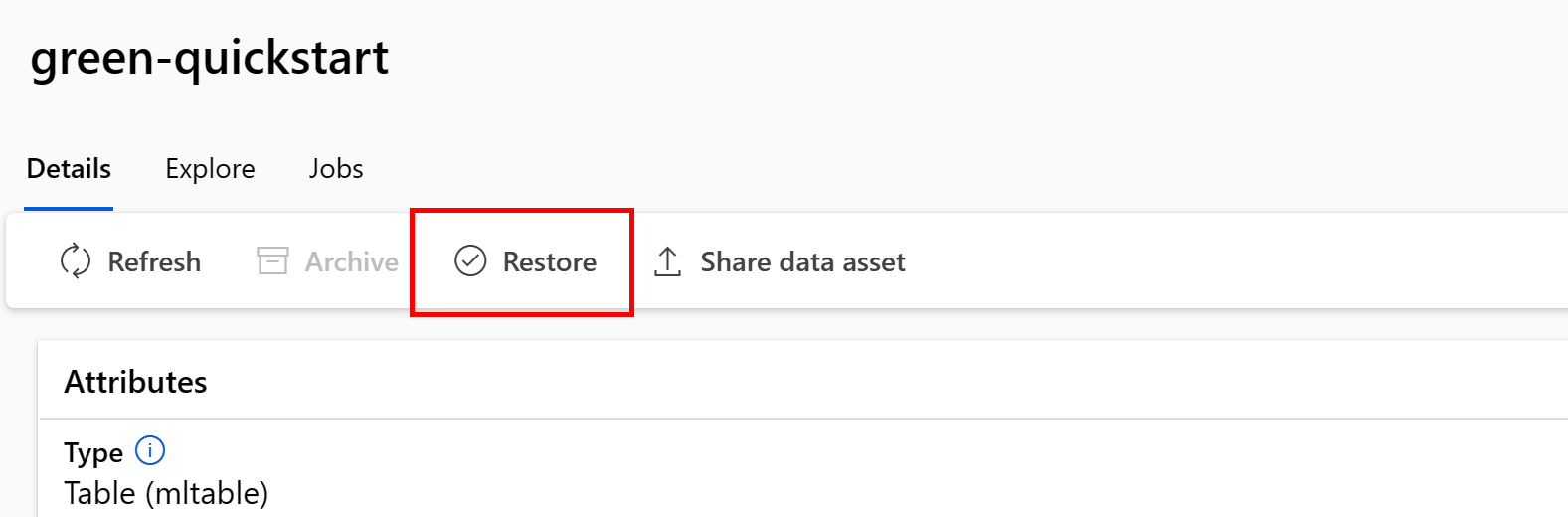
Восстановление определенной версии ресурса данных
Важно!
Если все версии ресурса данных были архивированы, вы не можете восстановить отдельные версии ресурса данных. Необходимо восстановить все версии.
Чтобы восстановить определенную версию ресурса данных, используйте:
Выполните следующую команду (обновите <> заполнители с именем ресурса данных и версией):
az ml data restore --name <NAME OF DATA ASSET> --version <VERSION TO ARCHIVE>
Происхождение данных
Происхождение данных широко понимается как жизненный цикл, охватывающий источник данных, и где он перемещается с течением времени в хранилище. Различные типы сценариев обратного просмотра используют его, например устранение неполадок, трассировку первопричин в конвейерах машинного обучения и отладку. Кроме того, используется анализ качества данных, соответствие требованиям и сценарии "что если". Происхождение представляется визуально для отображения данных, перемещаемых из источника в место назначения, а также охватывает преобразования данных. Учитывая сложность большинства корпоративных сред данных, эти представления могут стать трудно понять без консолидации или маскирования периферийных точек данных.
В конвейере Машинное обучение Azure ресурсы данных показывают происхождение данных и способ обработки данных, например:
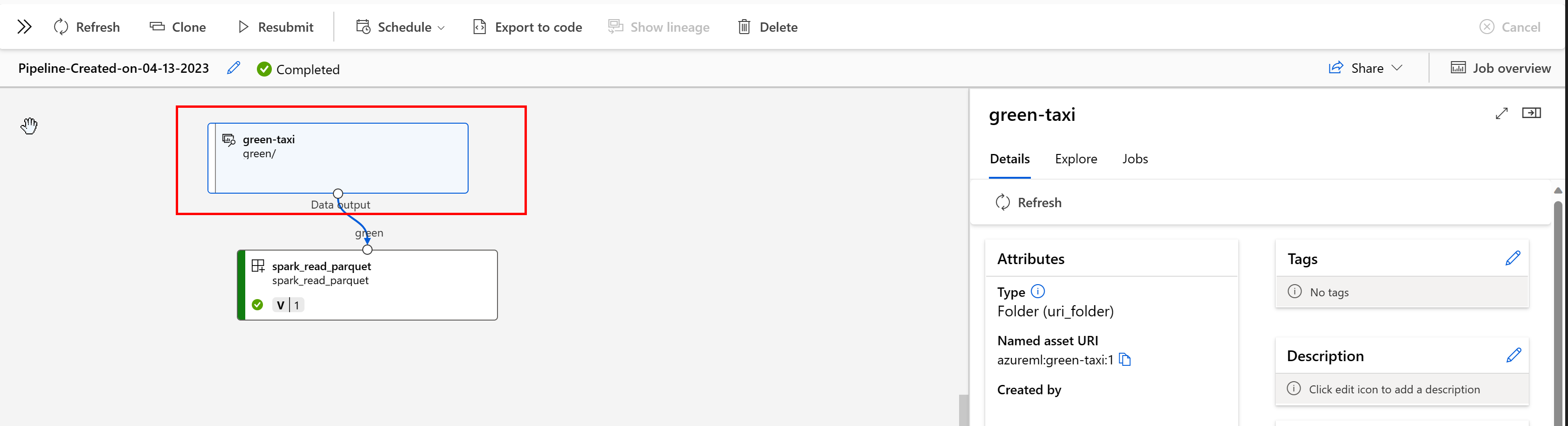
Вы можете просмотреть задания, использующие ресурс данных в пользовательском интерфейсе Студии. Сначала выберите "Данные " в меню слева и выберите имя ресурса данных. Вы можете увидеть задания, которые используют ресурс данных:
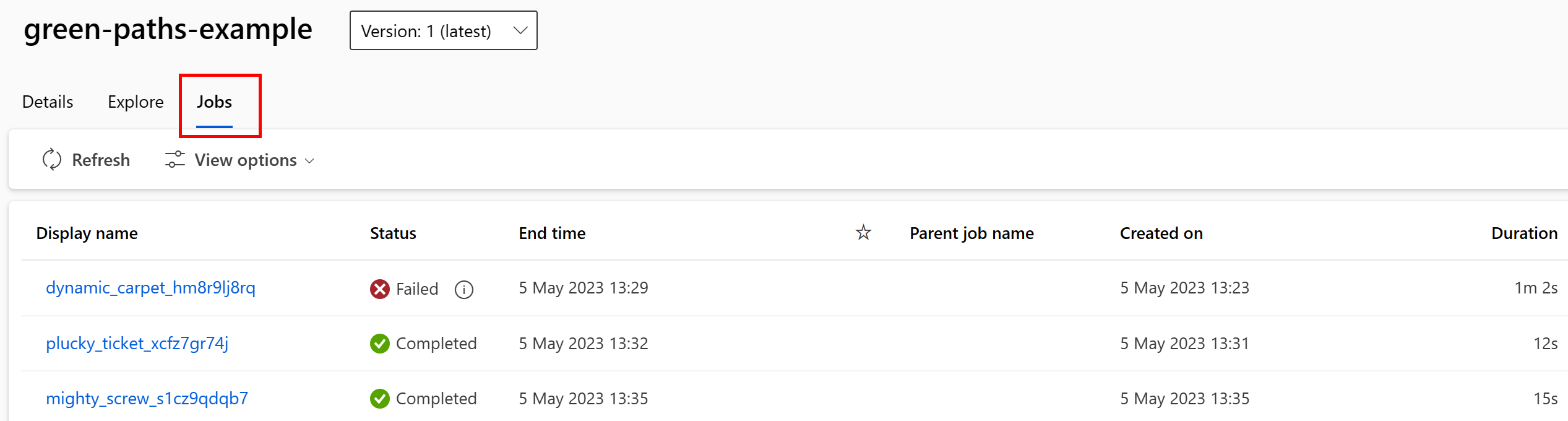
Представление заданий в ресурсах данных упрощает поиск сбоев заданий и выполнение анализа маршрутов в конвейерах машинного обучения и отладке.
Тег ресурса данных
Ресурсы данных поддерживают теги, которые являются дополнительными метаданными, применяемыми к ресурсу данных в виде пары "ключ-значение". Теги данных предоставляют множество преимуществ:
- Описание качества данных. Например, если в вашей организации используется архитектура medallion lakehouse, можно пометить ресурсы с
medallion:bronzeпомощью (необработанных),medallion:silver(проверено) иmedallion:gold(обогащено). - Обеспечивает эффективный поиск и фильтрацию данных, чтобы помочь в обнаружении данных.
- Помогает выявлять конфиденциальные персональные данные, правильно управлять доступом к данным и управлять ими. Например,
sensitivity:PII/sensitivity:nonPII. - Определите, утверждены ли данные из ответственного аудита ИИ (RAI). Например,
RAI_audit:approved/RAI_audit:todo.
Теги можно добавить в ресурсы данных в рамках процесса создания или добавить теги в существующие ресурсы данных. В этом разделе показаны оба.
Добавление тегов в рамках потока создания ресурса данных
Создайте ФАЙЛ YAML и скопируйте и вставьте следующий код. Заполнители необходимо обновить <> с именем ресурса данных, версией, описанием, тегами (парами "ключ-значение") и путем к одному файлу в поддерживаемом расположении.
$schema: https://azuremlschemas.azureedge.net/latest/data.schema.json
# Supported paths include:
# local: './<path>/<file>' (this will be automatically uploaded to cloud storage)
# blob: 'wasbs://<container_name>@<account_name>.blob.core.windows.net/<path>/<file>'
# ADLS gen2: 'abfss://<file_system>@<account_name>.dfs.core.windows.net/<path>/<file>'
# Datastore: 'azureml://datastores/<data_store_name>/paths/<path>/<file>'
# Data asset types, use one of:
# uri_file, uri_folder, mltable
type: uri_file
name: <NAME OF DATA ASSET>
version: <VERSION>
description: <DESCRIPTION>
tags:
<KEY1>: <VALUE>
<KEY2>: <VALUE>
path: <SUPPORTED PATH>
Затем выполните следующую команду в CLI (обновите <filename> заполнитель до имени файла YAML):
az ml data create -f <filename>.yml
Добавление тегов в существующий ресурс данных
Выполните следующую команду в Azure CLI и обновите <> заполнители с именем ресурса данных, версией и парой "ключ-значение" для тега.
az ml data update --name <DATA ASSET NAME> --version <VERSION> --set tags.<KEY>=<VALUE>

Рекомендации по управлению версиями
Как правило, процессы ETL упорядочивают структуру папок в хранилище Azure по времени, например:
/
└── 📁 mydata
├── 📁 year=2022
│ ├── 📁 month=11
│ │ └── 📄 file1
│ │ └── 📄 file2
│ └── 📁 month=12
│ └── 📄 file1
│ │ └── 📄 file2
└── 📁 year=2023
└── 📁 month=1
└── 📄 file1
│ │ └── 📄 file2
Сочетание структурированных папок времени и версий и таблиц Машинное обучение Azure (MLTable) позволяет создавать версии наборов данных. Чтобы показать, как достичь версионных данных с помощью таблиц Машинное обучение Azure, мы используем гипотетический пример. Предположим, что у вас есть процесс, который отправляет изображения камеры в хранилище BLOB-объектов Azure каждую неделю в следующей структуре:
/myimages
└── 📁 year=2022
├── 📁 week52
│ ├── 📁 camera1
│ │ └── 🖼️ file1.jpeg
│ │ └── 🖼️ file2.jpeg
│ └── 📁 camera2
│ └── 🖼️ file1.jpeg
│ │ └── 🖼️ file2.jpeg
└── 📁 year=2023
├── 📁 week1
│ ├── 📁 camera1
│ │ └── 🖼️ file1.jpeg
│ │ └── 🖼️ file2.jpeg
│ └── 📁 camera2
│ └── 🖼️ file1.jpeg
│ │ └── 🖼️ file2.jpeg
Примечание.
Хотя мы покажем, как использовать образ версии () данных, одна и та же методология может применяться к любому типу файла (jpegнапример, Parquet, CSV).
С помощью таблиц Машинное обучение Azure (mltable) создается таблица путей, включающих данные до конца первой недели в 2023 году, а затем создайте ресурс данных:
import mltable
from mltable import MLTableHeaders, MLTableFileEncoding, DataType
from azure.ai.ml import MLClient
from azure.ai.ml.entities import Data
from azure.ai.ml.constants import AssetTypes
from azure.identity import DefaultAzureCredential
# The ** in the pattern below will glob all sub-folders (camera1, ..., camera2)
paths = [
{
"pattern": "abfss://<file_system>@<account_name>.dfs.core.windows.net/myimages/year=2022/week=52/**/*.jpeg"
},
{
"pattern": "abfss://<file_system>@<account_name>.dfs.core.windows.net/myimages/year=2023/week=1/**/*.jpeg"
},
]
tbl = mltable.from_paths(paths)
tbl.save("./myimages")
# Connect to the AzureML workspace
subscription_id = "<SUBSCRIPTION_ID>"
resource_group = "<RESOURCE_GROUP>"
workspace = "<AML_WORKSPACE_NAME>"
ml_client = MLClient(
DefaultAzureCredential(), subscription_id, resource_group, workspace
)
# Define the Data asset object
my_data = Data(
path=mltable_folder,
type=AssetTypes.MLTABLE,
description="My images. Version includes data through to 2023-Jan-08.",
name="myimages",
version="20230108",
)
# Create the data asset in the workspace
ml_client.data.create_or_update(my_data)
В конце следующей недели ваш ETL обновил данные, чтобы включить дополнительные данные:
/myimages
└── 📁 year=2022
├── 📁 week52
│ ├── 📁 camera1
│ │ └── 🖼️ file1.jpeg
│ │ └── 🖼️ file2.jpeg
│ └── 📁 camera2
│ │ └── 🖼️ file1.jpeg
│ │ └── 🖼️ file2.jpeg
└── 📁 year=2023
├── 📁 week1
│ ├── 📁 camera1
│ │ └── 🖼️ file1.jpeg
│ │ └── 🖼️ file2.jpeg
│ └── 📁 camera2
│ │ └── 🖼️ file1.jpeg
│ │ └── 🖼️ file2.jpeg
├── 📁 week2
│ ├── 📁 camera1
│ │ └── 🖼️ file1.jpeg
│ │ └── 🖼️ file2.jpeg
│ └── 📁 camera2
│ │ └── 🖼️ file1.jpeg
│ │ └── 🖼️ file2.jpeg
Первая версия (20230108) продолжает подключать и скачивать файлы только из year=2022/week=52 файла, year=2023/week=1 так как пути объявлены в MLTable файле. Это обеспечивает воспроизводимость экспериментов. Чтобы создать новую версию ресурса данных, включающую в себя year=2023/week2, следует использовать следующее:
import mltable
from mltable import MLTableHeaders, MLTableFileEncoding, DataType
from azure.ai.ml import MLClient
from azure.ai.ml.entities import Data
from azure.ai.ml.constants import AssetTypes
from azure.identity import DefaultAzureCredential
# The ** in the pattern below will glob all sub-folders (camera1, ..., camera2)
paths = [
{
"pattern": "abfss://<file_system>@<account_name>.dfs.core.windows.net/myimages/year=2022/week=52/**/*.jpeg"
},
{
"pattern": "abfss://<file_system>@<account_name>.dfs.core.windows.net/myimages/year=2023/week=1/**/*.jpeg"
},
{
"pattern": "abfss://<file_system>@<account_name>.dfs.core.windows.net/myimages/year=2023/week=2/**/*.jpeg"
},
]
# Save to an MLTable file on local storage
tbl = mltable.from_paths(paths)
tbl.save("./myimages")
# Next, you create a data asset - the MLTable file will automatically be uploaded
# Connect to the AzureML workspace
subscription_id = "<SUBSCRIPTION_ID>"
resource_group = "<RESOURCE_GROUP>"
workspace = "<AML_WORKSPACE_NAME>"
ml_client = MLClient(
DefaultAzureCredential(), subscription_id, resource_group, workspace
)
# Define the Data asset object
my_data = Data(
path=mltable_folder,
type=AssetTypes.MLTABLE,
description="My images. Version includes data through to 2023-Jan-15.",
name="myimages",
version="20230115", # update version to the date
)
# Create the data asset in the workspace
ml_client.data.create_or_update(my_data)
Теперь у вас есть две версии данных, где имя версии соответствует дате отправки изображений в хранилище:
- 20230108: изображения до 2023-января-08.
- 20230115: изображения до 2023-января-15.
В обоих случаях MLTable создает таблицу путей, включающих только изображения до этих дат.
В задании Машинное обучение Azure можно подключить или скачать эти пути в версии MLTable в целевой объект вычислений eval_download с помощью режима или eval_mount режима:
from azure.ai.ml import MLClient, command, Input
from azure.ai.ml.entities import Environment
from azure.identity import DefaultAzureCredential
from azure.ai.ml.constants import InputOutputModes
# connect to the AzureML workspace
ml_client = MLClient.from_config(
DefaultAzureCredential()
)
# Get the 20230115 version of the data
data_asset = ml_client.data.get(name="myimages", version="20230115")
input = {
"images": Input(type="mltable",
path=data_asset.id,
mode=InputOutputModes.EVAL_MOUNT
)
}
cmd = """
ls ${{inputs.images}}/**
"""
job = command(
command=cmd,
inputs=input,
compute="cpu-cluster",
environment="azureml://registries/azureml/environments/sklearn-1.1/versions/4"
)
ml_client.jobs.create_or_update(job)
Примечание.
Режимы eval_mount и eval_download режимы уникальны для MLTable. В этом случае возможность среды выполнения данных AzureML оценивает MLTable файл и подключает пути к целевому объекту вычислений.