Публикация и мониторинг конвейеров машинного обучения
ОБЛАСТЬ ПРИМЕНЕНИЯ: Пакет SDK для Python для ML Azure версии 1
Пакет SDK для Python для ML Azure версии 1
В этой статье показано, как совместно с вашими коллегами или клиентами использовать конвейер машинного обучения.
Конвейеры машинного обучения — это рабочие процессы многократного использования для задач машинного обучения. Одним из преимуществ конвейеров является повышение степени совместной работы. Вы также можете создавать конвейеры версий, что позволяет клиентам использовать текущую модель при работе с новой версией.
Необходимые компоненты
Создайте рабочую область Машинного обучения Azure для хранения всех ресурсов конвейера.
Подготовьте среду разработки к установке пакета SDK для Машинного обучения Azure или используйте вычислительный экземпляр Машинного обучения Azure с уже установленным пакетом SDK.
Создайте и запустите конвейер машинного обучения, как описано в следующем учебнике по созданию конвейера Машинного обучения Azure для пакетной оценки. Другие варианты см. в статье Создание и запуск конвейеров машинного обучения с помощью пакета SDK Машинного обучения Azure
Публикация конвейера
После создания и запуска конвейер можно опубликовать, чтобы он выполнялся с разными входными данными. Чтобы конечная точка REST уже опубликованного конвейера принимала параметры, необходимо настроить конвейер на использование объектов PipelineParameter для аргументов, которые будут отличаться.
Чтобы создать параметр конвейера, используйте объект PipelineParameter со значением по умолчанию.
from azureml.pipeline.core.graph import PipelineParameter pipeline_param = PipelineParameter( name="pipeline_arg", default_value=10)Добавьте этот объект
PipelineParameterв качестве параметра в любой из шагов в конвейере следующим образом.compareStep = PythonScriptStep( script_name="compare.py", arguments=["--comp_data1", comp_data1, "--comp_data2", comp_data2, "--output_data", out_data3, "--param1", pipeline_param], inputs=[ comp_data1, comp_data2], outputs=[out_data3], compute_target=compute_target, source_directory=project_folder)Опубликуйте этот конвейер, который будет принимать параметр при вызове.
published_pipeline1 = pipeline_run1.publish_pipeline( name="My_Published_Pipeline", description="My Published Pipeline Description", version="1.0")После публикации конвейера его можно проверить в пользовательском интерфейсе. Идентификатор конвейера — это уникальный идентификатор опубликованного конвейера.


Запустите опубликованный конвейер.
Все опубликованные конвейеры используют конечную точку REST. Конечная точка конвейера позволяет запускать конвейер из любых внешних систем, включая клиенты, не относящиеся к Python. Эта конечная точка обеспечивает управляемую повторяемость для сценариев пакетной оценки и переобучения.
Важно!
При работе с доступом на основе ролей Azure (Azure RBAC) для управления доступом к конвейеру задайте разрешения для своего сценария конвейера (обучение или оценка).
Чтобы вызвать запуск предыдущего конвейера, требуется маркер заголовка проверки подлинности Microsoft Entra. Этот маркер описан в справочнике по классу AzureCliAuthentication и в записной книжке Аутентификация в Машинном обучении Azure.
from azureml.pipeline.core import PublishedPipeline
import requests
response = requests.post(published_pipeline1.endpoint,
headers=aad_token,
json={"ExperimentName": "My_Pipeline",
"ParameterAssignments": {"pipeline_arg": 20}})
Аргумент json для запроса POST должен содержать для ключа ParameterAssignments словарь с параметрами конвейера и их значениями. Кроме того, аргумент json может содержать следующие ключи:
| Ключ. | Description |
|---|---|
ExperimentName |
Название эксперимента, связанного с этой конечной точкой |
Description |
Произвольный текст, описывающий эту конечную точку |
Tags |
Произвольные пары "ключ–значение", которые могут использоваться для добавления меток и создания заметок к запросам |
DataSetDefinitionValueAssignments |
Словарь, используемый для изменения наборов данных без повторного обучения (см. ниже) |
DataPathAssignments |
Словарь, используемый для изменения путей к данным без повторного обучения (см. ниже) |
Запуск опубликованного конвейера с помощью C#
В следующем фрагменте кода показано, как асинхронно вызывать конвейер из C#. Частичный фрагмент кода просто показывает структуру вызова и не является частью примера Microsoft. В нем не показаны полные классы и обработка ошибок.
[DataContract]
public class SubmitPipelineRunRequest
{
[DataMember]
public string ExperimentName { get; set; }
[DataMember]
public string Description { get; set; }
[DataMember(IsRequired = false)]
public IDictionary<string, string> ParameterAssignments { get; set; }
}
// ... in its own class and method ...
const string RestEndpoint = "your-pipeline-endpoint";
using (HttpClient client = new HttpClient())
{
var submitPipelineRunRequest = new SubmitPipelineRunRequest()
{
ExperimentName = "YourExperimentName",
Description = "Asynchronous C# REST api call",
ParameterAssignments = new Dictionary<string, string>
{
{
// Replace with your pipeline parameter keys and values
"your-pipeline-parameter", "default-value"
}
}
};
string auth_key = "your-auth-key";
client.DefaultRequestHeaders.Authorization = new AuthenticationHeaderValue("Bearer", auth_key);
// submit the job
var requestPayload = JsonConvert.SerializeObject(submitPipelineRunRequest);
var httpContent = new StringContent(requestPayload, Encoding.UTF8, "application/json");
var submitResponse = await client.PostAsync(RestEndpoint, httpContent).ConfigureAwait(false);
if (!submitResponse.IsSuccessStatusCode)
{
await WriteFailedResponse(submitResponse); // ... method not shown ...
return;
}
var result = await submitResponse.Content.ReadAsStringAsync().ConfigureAwait(false);
var obj = JObject.Parse(result);
// ... use `obj` dictionary to access results
}
Запуск опубликованного конвейера с помощью Java
В следующем фрагменте кода показан вызов конвейера, требующего проверки подлинности (см. раздел Настройка проверки подлинности для ресурсов и рабочих процессов Машинного обучения Microsoft Azure). Если конвейер развернут для общего доступа, вызовы, создающие authKey, будут не нужны. В частичном фрагменте кода не показан стандартный класс Java и шаблон обработки исключений. Код использует Optional.flatMap для объединения функций, которые могут возвращать пустое значение Optional. Использование flatMap сокращает и разъясняет код, но обратите внимание, что getRequestBody() поглощает исключения.
import java.net.URI;
import java.net.http.HttpClient;
import java.net.http.HttpRequest;
import java.net.http.HttpResponse;
import java.util.Optional;
// JSON library
import com.google.gson.Gson;
String scoringUri = "scoring-endpoint";
String tenantId = "your-tenant-id";
String clientId = "your-client-id";
String clientSecret = "your-client-secret";
String resourceManagerUrl = "https://management.azure.com";
String dataToBeScored = "{ \"ExperimentName\" : \"My_Pipeline\", \"ParameterAssignments\" : { \"pipeline_arg\" : \"20\" }}";
HttpClient client = HttpClient.newBuilder().build();
Gson gson = new Gson();
HttpRequest tokenAuthenticationRequest = tokenAuthenticationRequest(tenantId, clientId, clientSecret, resourceManagerUrl);
Optional<String> authBody = getRequestBody(client, tokenAuthenticationRequest);
Optional<String> authKey = authBody.flatMap(body -> Optional.of(gson.fromJson(body, AuthenticationBody.class).access_token);;
Optional<HttpRequest> scoringRequest = authKey.flatMap(key -> Optional.of(scoringRequest(key, scoringUri, dataToBeScored)));
Optional<String> scoringResult = scoringRequest.flatMap(req -> getRequestBody(client, req));
// ... etc (`scoringResult.orElse()`) ...
static HttpRequest tokenAuthenticationRequest(String tenantId, String clientId, String clientSecret, String resourceManagerUrl)
{
String authUrl = String.format("https://login.microsoftonline.com/%s/oauth2/token", tenantId);
String clientIdParam = String.format("client_id=%s", clientId);
String resourceParam = String.format("resource=%s", resourceManagerUrl);
String clientSecretParam = String.format("client_secret=%s", clientSecret);
String bodyString = String.format("grant_type=client_credentials&%s&%s&%s", clientIdParam, resourceParam, clientSecretParam);
HttpRequest request = HttpRequest.newBuilder()
.uri(URI.create(authUrl))
.POST(HttpRequest.BodyPublishers.ofString(bodyString))
.build();
return request;
}
static HttpRequest scoringRequest(String authKey, String scoringUri, String dataToBeScored)
{
HttpRequest request = HttpRequest.newBuilder()
.uri(URI.create(scoringUri))
.header("Authorization", String.format("Token %s", authKey))
.POST(HttpRequest.BodyPublishers.ofString(dataToBeScored))
.build();
return request;
}
static Optional<String> getRequestBody(HttpClient client, HttpRequest request) {
try {
HttpResponse<String> response = client.send(request, HttpResponse.BodyHandlers.ofString());
if (response.statusCode() != 200) {
System.out.println(String.format("Unexpected server response %d", response.statusCode()));
return Optional.empty();
}
return Optional.of(response.body());
}catch(Exception x)
{
System.out.println(x.toString());
return Optional.empty();
}
}
class AuthenticationBody {
String access_token;
String token_type;
int expires_in;
String scope;
String refresh_token;
String id_token;
AuthenticationBody() {}
}
Изменение наборов данных и путей к ним без переобучения
У вас может возникнуть необходимость выполнить обучение и создать выводы для различных наборов данных и путей к ним. Например, вы можете провести обучение по набору данных меньшего размера, но вывод получать по полному набору данных. Вы можете переключать наборы данных с помощью ключа DataSetDefinitionValueAssignments в аргументе json запроса. Пути к данным переключаются с помощью DataPathAssignments. Оба метода реализуются аналогично:
В сценарии определения конвейера создайте
PipelineParameterдля набора данных. СоздайтеDatasetConsumptionConfigилиDataPathизPipelineParameter:tabular_dataset = Dataset.Tabular.from_delimited_files('https://dprepdata.blob.core.windows.net/demo/Titanic.csv') tabular_pipeline_param = PipelineParameter(name="tabular_ds_param", default_value=tabular_dataset) tabular_ds_consumption = DatasetConsumptionConfig("tabular_dataset", tabular_pipeline_param)В сценарии Машинного обучения получите доступ к динамически заданному набору данных с помощью
Run.get_context().input_datasets:from azureml.core import Run input_tabular_ds = Run.get_context().input_datasets['tabular_dataset'] dataframe = input_tabular_ds.to_pandas_dataframe() # ... etc ...Обратите внимание, что сценарий Машинного обучения обращается к значению, заданному для
DatasetConsumptionConfig(tabular_dataset), а не к значениюPipelineParameter(tabular_ds_param).В сценарии определения конвейера присвойте параметру
DatasetConsumptionConfigзначениеPipelineScriptStep:train_step = PythonScriptStep( name="train_step", script_name="train_with_dataset.py", arguments=["--param1", tabular_ds_consumption], inputs=[tabular_ds_consumption], compute_target=compute_target, source_directory=source_directory) pipeline = Pipeline(workspace=ws, steps=[train_step])Чтобы динамически переключать наборы данных в вызове REST для вывода, используйте
DataSetDefinitionValueAssignments:tabular_ds1 = Dataset.Tabular.from_delimited_files('path_to_training_dataset') tabular_ds2 = Dataset.Tabular.from_delimited_files('path_to_inference_dataset') ds1_id = tabular_ds1.id d22_id = tabular_ds2.id response = requests.post(rest_endpoint, headers=aad_token, json={ "ExperimentName": "MyRestPipeline", "DataSetDefinitionValueAssignments": { "tabular_ds_param": { "SavedDataSetReference": {"Id": ds1_id #or ds2_id }}}})
В записных книжках Демонстрация Dataset и PipelineParameter и Демонстрация DataPath и PipelineParameter содержатся полные примеры реализации этого метода.
Создание конечной точки версионного конвейера
Вы можете создать конечную точку конвейера с несколькими опубликованными конвейерами за ней. Эта методика позволяет получить фиксированную конечную точку REST после итерации и обновления конвейеров машинного обучения.
from azureml.pipeline.core import PipelineEndpoint
published_pipeline = PublishedPipeline.get(workspace=ws, id="My_Published_Pipeline_id")
pipeline_endpoint = PipelineEndpoint.publish(workspace=ws, name="PipelineEndpointTest",
pipeline=published_pipeline, description="Test description Notebook")
Отправка задания в конечную точку конвейера
Вы можете отправить задание в конечную точку конвейера с версией по умолчанию:
pipeline_endpoint_by_name = PipelineEndpoint.get(workspace=ws, name="PipelineEndpointTest")
run_id = pipeline_endpoint_by_name.submit("PipelineEndpointExperiment")
print(run_id)
Вы также можете отправить задание в определенную версию:
run_id = pipeline_endpoint_by_name.submit("PipelineEndpointExperiment", pipeline_version="0")
print(run_id)
То же самое можно сделать с помощью REST API:
rest_endpoint = pipeline_endpoint_by_name.endpoint
response = requests.post(rest_endpoint,
headers=aad_token,
json={"ExperimentName": "PipelineEndpointExperiment",
"RunSource": "API",
"ParameterAssignments": {"1": "united", "2":"city"}})
Использование опубликованных конвейеров в студии
Вы также можете запустить опубликованный конвейер из студии:
Войдите в Студию машинного обучения Azure.
Слева выберите конечные точки.
В верхней части окна выберите Конечные точки конвейера.
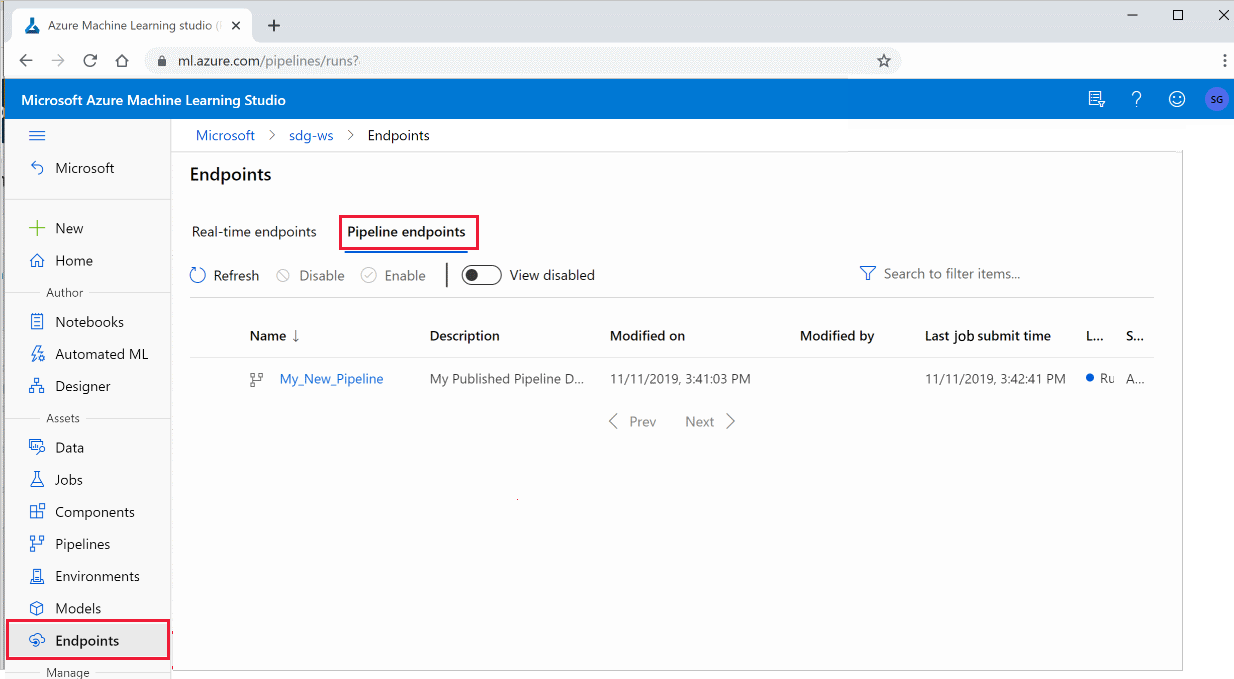
Выберите конкретный конвейер для выполнения, использования или просмотра результатов предыдущих запусков конечной точки конвейера.
Отключение опубликованного конвейера
Чтобы скрыть конвейер в списке опубликованных конвейеров, отключите его либо в студии, либо в пакете SDK:
# Get the pipeline by using its ID from Azure Machine Learning studio
p = PublishedPipeline.get(ws, id="068f4885-7088-424b-8ce2-eeb9ba5381a6")
p.disable()
Его можно включить снова с помощью p.enable(). Дополнительные сведения см. в справке для класса PublishedPipeline.
Следующие шаги
- Используйте эти записные книжки Jupyter на сайте GitHub, чтобы подробнее изучить конвейеры машинного обучения.
- См. справочные материалы по пакету SDK для пакетов azureml-pipelines-core и azureml-pipelines-steps.
- Советы по отладке и устранению неполадок в конвейерах см. в этой статье.