Кластеризация методом K-средних
Важно!
Поддержка Студии машинного обучения (классической) будет прекращена 31 августа 2024 г. До этой даты рекомендуется перейти на Машинное обучение Azure.
Начиная с 1 декабря 2021 года вы не сможете создавать новые ресурсы Студии машинного обучения (классической). Существующие ресурсы Студии машинного обучения (классическая версия) можно будет использовать до 31 августа 2024 г.
- См. сведения о перемещении проектов машинного обучения из ML Studio (классической) в Машинное обучение Azure.
- См. дополнительные сведения о Машинном обучении Azure.
Поддержка документации по ML Studio (классической) прекращается, а сама документация может не обновляться в будущем.
Настройка и инициализация модели кластеризация K-средних
Категория: Машинное обучение / Инициализация модели / Кластеризация
Примечание
Область применения: только Студия машинного обучения (классическая)
Подобные модули перетаскивания доступны в конструкторе машинного обучения Azure.
Обзор модуля
В этой статье описывается использование модуля кластеризации K-Средних в Студии машинного обучения (классической) для создания необученной модели K-средних кластеризация.
K-средний является одним из самых простых и самых известных алгоритмов неконтролируемого обучения и может использоваться для различных задач машинного обучения, таких как обнаружение аномальных данных, кластеризация текстовых документов и анализ набора данных до использования других методов классификации или регрессии. Чтобы создать модель кластеризация, необходимо добавить этот модуль в эксперимент, подключить набор данных и задать такие параметры, как ожидаемое количество кластеров, метрика расстояния, используемая при создании кластеров, и т. д.
Настроив гиперпараметры модуля, подключите необученную модель к модулям Обучение модели кластеризации или Очистка кластеризации , чтобы обучить модель по предоставленным входным данным. Поскольку алгоритм k-средних является неконтролируемым методом обучения, столбец меток необязателен.
- Если данные содержат метку, значения меток можно использовать как ориентир при выборе кластеров и оптимизации модели.
- Если данные не имеют меток, алгоритм создает кластеры, представляющие возможные категории, основываясь исключительно на данных.
Совет
Если данные для обучения содержат метки, рассмотрите возможность использования одного из контролируемых методов классификации , предоставляемых в Машинном обучении. Например, можно сравнить результаты кластеризация с результатами при использовании одного из алгоритмов многоклассового дерева принятия решений.
Основные сведения о кластеризация k-средних
Как правило, при кластеризации используются приемы итерации для объединения вариантов в наборе данных в кластеры, имеющие схожие характеристики. Такие группировки полезно использовать для изучения данных, выявления в них аномалий и создания прогнозов. Модели кластеризации также могут помочь выявить связи в наборе данных, которые нельзя вывести логически путем просмотра или простого наблюдения. По этим причинам кластеризация часто используется на ранних этапах задач машинного обучения для изучения данных и выявления необычных корреляций.
При настройке модели кластеризация с помощью метода k-средних необходимо указать целевое число k, указывающее необходимое количество центроидов в модели. Центроид — это точка, которая является репрезентативной для каждого кластера. Алгоритм k-средних назначает каждую входящую точку данных одному из кластеров за счет уменьшения суммы квадратов в кластере.
При обработке обучающих данных алгоритм K-средних начинается с начального набора случайно выбранных центроидов, которые служат начальными точками для каждого кластера, и применяет алгоритм Ллойда для итеративного уточнения расположения центроидов. Алгоритм k-средних прекращает построение и уточнение кластеров, когда выполняется одно из указанных ниже условий.
Центроиды стабилизируются, а это означает, что кластерные назначения для отдельных точек больше не изменяются, и алгоритм сходится в решении.
Алгоритм выполнил указанное число итераций.
После завершения этапа обучения используйте модуль Назначение данных кластерам , чтобы назначить новые варианты одному из кластеров, найденных алгоритмом k-средних. Назначение кластера выполняется путем вычисления расстояния между новым вариантом и центроидом каждого кластера. Каждый новый вариант назначается кластеру с ближайшим центроидом.
Настройка кластеризации K-Средних
Добавьте модуль кластеризации K-Средние в эксперимент.
Укажите, как вы хотите обучать модель, выбрав значение Create trainer mode (Создать режим учителя).
Одиночный параметр. Если вы точно знаете, какие параметры хотите использовать в модели кластеризации, можно указать конкретный набор значений в качестве аргументов.
Диапазон параметров. Если вы не уверены в лучших параметрах, вы можете найти оптимальные параметры, указав несколько значений и используя модуль Очистка кластеризации для поиска оптимальной конфигурации.
Модуль обучения выполняет итерацию по нескольким сочетаниям указанных вами параметров и определяет сочетание значений, которое дает оптимальные результаты кластеризация.
В поле Число центроидов введите число кластеров, с которых должен начинаться алгоритм.
Модель не гарантирует точное количество кластеров. Algorithn начинается с этого количества точек данных и выполняет итерацию для поиска оптимальной конфигурации, как описано в разделе Технические примечания .
Если выполняется очистка параметров, имя свойства изменится на Диапазон для числа центроидов. С помощью построителя диапазонов можно указать диапазон или ввести ряд чисел, представляющих разное количество кластеров, создаваемых при инициализации каждой модели.
Свойства Инициализация или Инициализация для очистки используются для указания алгоритма, используемого для определения начальной конфигурации кластера.
Первый N. Некоторое начальное количество точек данных выбирается из набора данных и используется в качестве начальных средств.
Также называется методом Forgy.
Случайный выбор. Этот алгоритм случайным образом помещает точку данных в кластер, а затем вычисляет исходное среднее для определения центроида случайно назначенных кластеру точек.
Также называется методом случайного секционирования .
K-средние++. Это метод по умолчанию для инициализации кластеров.
Алгоритм K-средних ++ был предложен в 2007 году Дэвидом Артуром и Сергеем Васильвицким, чтобы избежать плохого кластеризация стандартным алгоритмом k-средних. K-средний ++ улучшает стандартные K-средние за счет использования другого метода выбора начальных центров кластера.
K-Means++Fast: вариант алгоритма K-средних ++, оптимизированный для более быстрого кластеризация.
Равномерно: центроиды расположены равноудаленно друг от друга в пространстве D-Мерности n точек данных.
Использовать столбец меток. Значения в столбце метки используются для указания выбора центроидов.
В поле случайного начального значения при необходимости введите значение, которое будет использоваться как начальное для инициализации кластера. Это значение может существенно повлиять на выбор кластера.
Если используется очистка параметров, можно указать, что будет создано несколько начальных значений, чтобы найти лучшее начальное значение начального значения. В поле Число семян для очистки введите общее число случайных значений начального значения для использования в качестве отправных точек.
В поле Метрика выберите функцию, используемую для измерения расстояния между векторами кластера или между новыми точками данных и случайным образом выбранным центроидом. Машинное обучение поддерживает следующие метрики расстояния кластера:
Евклидова. Евклидово расстояние является обычной мерой рассеяния кластера при кластеризации методом k-средних. Эта метрика предпочтительна, так как она сводит к минимуму среднее расстояние между точками и центроидами.
Косинус. Функция косинуса используется для измерения сходства кластера. Подобие косинуса полезно в тех случаях, когда вас не интересует длина вектора, а только его угол.
Для итераций введите количество итераций, которые алгоритм должен выполнять по обучающим данным перед завершением выбора центроидов.
Этот параметр можно настроить, чтобы сбалансировать точность и время обучения.
Для параметра Режим назначения метки выберите параметр, указывающий способ обработки столбца метки, если он присутствует в наборе данных.
Поскольку кластеризация методом k-средних — это неконтролируемый метод машинного обучения, метки необязательны. Однако если в наборе данных уже есть столбец меток, эти значения можно использовать для выбора кластеров или указать, что значения будут игнорироваться.
Пропустить столбец меток. Значения в столбце меток игнорируются и не используются при построении модели.
Заполнение отсутствующих значений. Значения столбца меток используются в качестве компонентов для создания кластеров. Если в строках отсутствует метка, значение определяется с помощью других компонентов.
Перезаписывать данные из ближайшей к центру. Значения столбца меток заменяются прогнозируемыми значениями меток, причем для этого используется метка точки, ближайшей к текущему центроиду.
Обучение модели.
Если команде Создать режим преподавателя присвоено значение Одиночный параметр, добавьте набор данных с тегами и обучите модель с помощью модуля обучающей модели кластеризации.
Если для параметра Создать режим обучения задано значение Диапазон параметров, добавьте набор данных с тегами и обучите модель с помощью кластеризации Очистка. Вы можете использовать модель, обученную с помощью этих параметров, или запомнить либо записать эти параметры для использования при настройке ученика.
Результаты
После завершения настройки и обучения модели у вас будет модель, которую можно использовать для создания оценок. Однако существует несколько способов обучения модели, а также несколько способов просмотра и использования результатов.
Запись моментального снимка модели в рабочей области
Если вы использовали модуль Обучение модели кластеризации
- Щелкните правой кнопкой мыши модуль обучающей модели кластеризации.
- Выберите Обученная модель и нажмите кнопку Сохранить как обученную модель.
Если вы использовали модуль "Кластеризация очистки " для обучения модели
- Щелкните правой кнопкой мыши модуль Очистка кластеризации .
- Выберите Лучшая обученная модель и нажмите кнопку Сохранить как обученную модель.
Сохраненная модель будет представлять обучающие данные на момент сохранения модели. Если позже вы обновите обучающие данные, используемые в эксперименте, сохраненная модель не будет обновлена.
Просмотр визуального представления кластеров в модели
Если вы использовали модуль Обучение модели кластеризации
- Щелкните модуль правой кнопкой мыши и выберите Результаты набора данных.
- Выберите Визуализировать.
Если вы использовали модуль "Кластеризация очистки "
Добавьте экземпляр модуля Назначение данных кластерам и создайте оценки с помощью модели Best Trained.
Щелкните правой кнопкой мыши модуль Назначение данных кластерам , выберите Набор данных результатов и выберите Визуализировать.
Диаграмма создается с помощью анализа основных компонентов, который является методом в обработке и анализе данных для сжатия пространства признаков модели. На диаграмме показан некоторый набор признаков, сжатых в два измерения, которые лучше всего характеризуют разницу между кластерами. Визуально изучив общий размер пространства компонентов для каждого кластера и то, насколько кластеры перекрываются, вы можете получить представление о том, насколько хорошо модель может работать.
Например, следующие диаграммы PCA представляют результаты из двух моделей, обученных с использованием одних и того же данных: первая была настроена для вывода двух кластеров, а вторая — для вывода трех кластеров. На этих диаграммах видно, что увеличение числа кластеров не обязательно улучшает разделение классов.
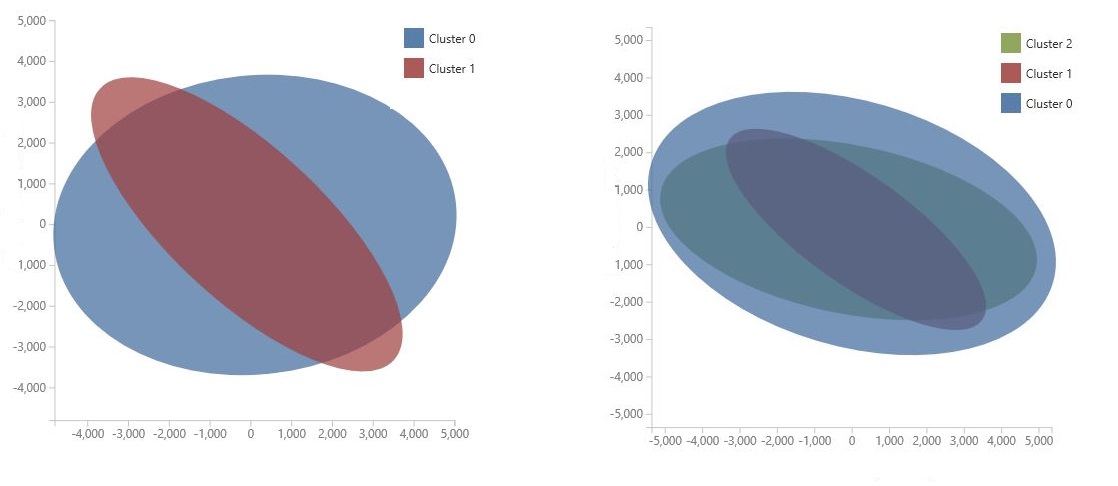
Совет
Используйте модуль Кластеризация очистки , чтобы выбрать оптимальный набор гиперпараметров, включая случайное начальное значение и число начальных центроидов.
Просмотрите список точек данных и кластеров, к которому они относятся.
Существует два варианта просмотра набора данных с результатами в зависимости от того, как вы обучили модель:
Если вы использовали модуль "Кластеризация очистки " для обучения модели
- Используйте флажок в модуле Очистка кластеризации , чтобы указать, нужно ли просматривать входные данные вместе с результатами или только результаты.
- После завершения обучения щелкните модуль правой кнопкой мыши и выберите Результаты набора данных (номер вывода 2).
- Щелкните Визуализировать.
Если вы использовали модуль Обучение модели кластеризации
- Добавьте модуль Назначение данных кластерам и подключите обученную модель к входным данным слева. Подключите набор данных к входным данным справа.
- Добавьте модуль Преобразовать в набор данных в эксперимент и подключите его к выходным данным параметра Назначение данных кластерам.
- Используйте флажок в модуле Назначение данных кластерам , чтобы указать, нужно ли просматривать входные данные вместе с результатами или только результаты.
- Запустите эксперимент или просто модуль Преобразовать в набор данных .
- Щелкните правой кнопкой мыши Преобразовать в набор данных, выберите Результаты набора данных и выберите пункт Визуализировать.
Выходные данные сначала содержат столбцы входных данных, если вы их включили, и следующие столбцы для каждой строки входных данных:
Назначение. Назначение представляет собой значение в диапазоне от 1 до n, где n — общее количество кластеров в модели. Каждая строка данных может быть назначена только одному кластеру.
DistancesToClusterCenter no.n. Это значение измеряет расстояние от текущей точки данных до центроида кластера. Отдельный столбец выходных данных для каждого кластера в обученной модели.
Значения расстояния кластера основаны на метрике расстояния, выбранной в параметре Метрика для измерения результата кластера. Даже если выполнить очистку параметров в модели кластеризация, во время очистки можно применить только одну метрику. Если вы измените метрику, вы можете получить различные значения расстояния.
Визуализация расстояний внутри кластера
В наборе данных результатов из предыдущего раздела щелкните столбец расстояний для каждого кластера. Студия (классическая) отображает гистограмму, которая визуализирует распределение расстояний для точек в кластере.
Например, следующие гистограммы показывают распределение расстояний кластера от одного эксперимента с использованием четырех разных метрик. Все остальные параметры для очистки параметров были одинаковыми. Изменение метрики привело к разному количеству кластеров в одной модели.
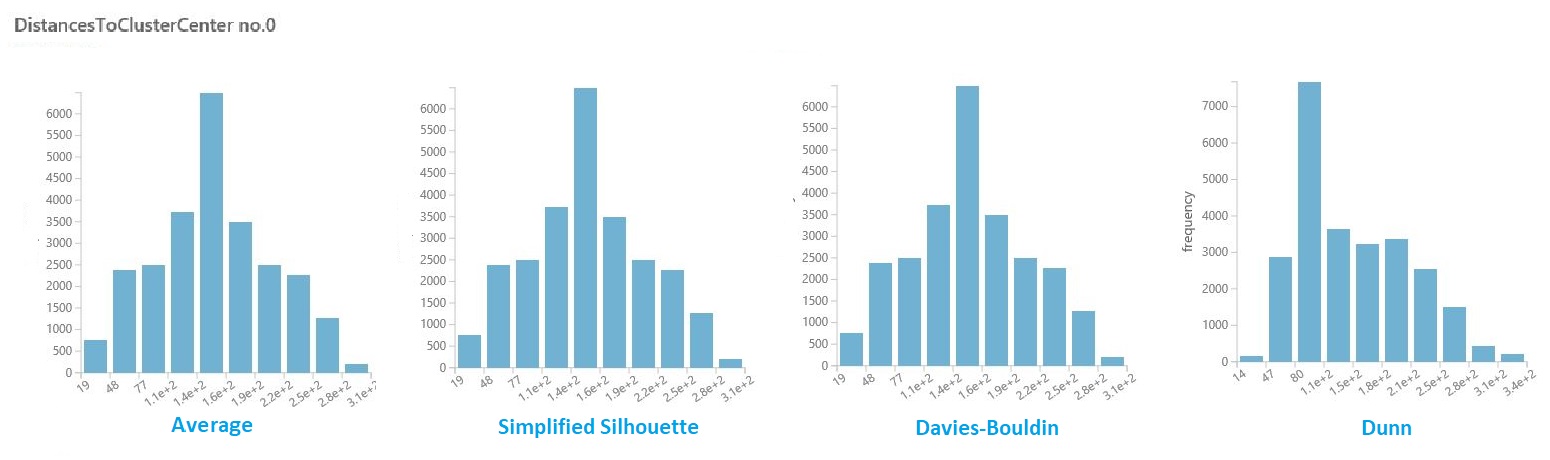
Как правило, следует выбрать метрику, которая максимально увеличивает расстояние между точками данных в разных классах и минимизирует расстояния внутри класса. Для принятия этого решения можно использовать предварительно вычисляемые средства и другие значения на панели Статистика .
Совет
Средства и другие значения, используемые в визуализациях, можно извлечь с помощью модуля PowerShell для машинного обучения.
Или используйте модуль Выполнение скрипта R для вычисления настраиваемой матрицы расстояний.
Советы по созданию лучшей модели кластеризации
Известно, что процесс заполнения, используемый во время кластеризация, может значительно повлиять на модель. Заполнения означает начальное размещение точек в мощные центроиды.
Например, если набор данных содержит много выбросов и для заполнения кластеров выбран выбросов, то другие точки данных не будут хорошо соответствовать кластеру, и кластер может быть одноэлементным, то есть кластером с одной точкой.
Существует несколько способов избежать этой проблемы.
Используйте очистку параметров, чтобы изменить количество центроидов и попробовать несколько начальных значений.
Создать несколько моделей, изменяя метрику или выполняя больше итераций.
Используйте метод, например PCA, для поиска переменных, которые оказывают негативное влияние на кластеризация. Пример поиска похожих компаний см. в разделе Пример поиска похожих компаний для демонстрации этого метода.
Как правило, при использовании кластеризация моделей любая конфигурация может привести к созданию локально оптимизированного набора кластеров. Другими словами, набор кластеров, возвращаемых моделью, соответствует только текущим точкам данных и не может быть обобщаемым для других данных. При использовании другой исходной конфигурации метод k-средних может дать более оптимальный результат.
Важно!
Рекомендуется всегда экспериментировать с параметрами, создавать несколько моделей и сравнивать результирующие модели.
Примеры
Примеры использования кластеризация K-средних в Машинном обучении см. в следующих экспериментах в коллекции ИИ Azure:
Данные группы ирисов. Сравнивает результаты кластеризации K-Средних и многоклассовой логистической регрессии для задачи классификации.
Пример квантования цвета. Создает несколько моделей K-средних с разными параметрами для поиска оптимального сжатия изображений.
Кластеризация: похожие компании. Различает количество центроидов для поиска групп похожих компаний в S&P500.
Технические примечания
При заданном количестве кластеров (K) и количестве точек N в D-мерном пространстве метод k-средних формирует кластеры указанным ниже способом:
Модуль инициализирует массив K-by-D с окончательными центроидами, которые определяют найденные кластеры K.
По умолчанию модуль назначает первые точки данных K для кластеров K .
Начиная с исходного набора из K центроидов этот метод использует алгоритм Ллойда для итеративного уточнения положений центроидов.
Выполнение алгоритма завершается, когда центроиды стабилизируются или после выполнения указанного числа итераций.
Метрика близости (по умолчанию евклидово расстояние) используется для назначения каждой точки данных кластеру с ближайшим центроидом.
Предупреждение
- При передаче диапазона параметров в обучение модели кластеризации используется только первое значение в списке диапазонов параметров.
- Если передать один набор значений параметров в модуль Кластеризация очистки , то, когда он ожидает диапазон параметров для каждого параметра, он игнорирует значения и использует значения по умолчанию для учащегося.
- Если выбран вариант Диапазон параметров и указано одно значение для любого параметра, это единственное заданное значение будет использоваться во время подбора параметров, даже если другие параметры меняются в диапазоне значений.
Параметры модуля
| Имя | Диапазон | Тип | По умолчанию | Описание |
|---|---|---|---|---|
| Число центроидов | >=2 | Целое число | 2 | Число центроидов |
| Metric | Список (подмножество) | Metric | Евклидов | Выбранная метрика |
| Инициализация | Список | Метод инициализации центроида | K-средних++ | Алгоритм инициализации |
| Количество итераций | >=1 | Целочисленный тип | 100 | Число итераций |
Выходные данные
| Имя | Тип | Описание |
|---|---|---|
| Необученная модель | Интерфейс ICluster | Необученная модель кластеризации К-средних |
Исключения
Список всех исключений см. в разделе Коды ошибок модуля машинного обучения.
| Исключение | Описание |
|---|---|
| Ошибка 0003 | Исключение возникает, если один или несколько входных аргументов имеют значение NULL или пусты. |
См. также раздел
Кластеризация
Назначение данных в кластеры
Обучение модели кластеризации
Кластеризация очистки