Создание первого эксперимента по обработке и анализу данных в Студии машинного обучения (классической)
Область применения: Студия машинного обучения (классическая)
Студия машинного обучения (классическая)  Машинное обучение Azure
Машинное обучение Azure
Важно!
Поддержка Студии машинного обучения (классической) будет прекращена 31 августа 2024 г. До этой даты рекомендуется перейти на Машинное обучение Azure.
Начиная с 1 декабря 2021 года вы не сможете создавать новые ресурсы Студии машинного обучения (классической). Существующие ресурсы Студии машинного обучения (классическая версия) можно будет использовать до 31 августа 2024 г.
- См. сведения о переносе проектов машинного обучения из Студии машинного обучения (классическая версия) в Машинное обучение Azure.
- См. дополнительные сведения о Машинном обучении Azure.
Прекращается поддержка документации по Студии машинного обучения (классическая версия). В будущем она может не обновляться.
С помощью этой статьи вы создадите эксперимент по машинному обучению в Студии машинного обучения (классической), который будет прогнозировать цену на автомобили с учетом различных переменных, например марки и технических спецификаций.
Если вы еще не знакомы с машинным обучением, в серии видеороликов Обработка и анализ данных для начинающих простым языком объясняются базовые принципы машинного обучения.
В этом руководстве для эксперимента используется рабочий процесс по умолчанию:
- Создание модели
- Обучение модели
- Оценка и тестирование модели
Получение данных
Для машинного обучения нам прежде всего нужны данные. Студия включает несколько примеров наборов данных (классическая модель). Также данные можно импортировать из других источников. Для этого примера мы воспользуемся примером набора данных Automobile price data (Raw) (Данные о ценах на автомобили (необработанные)), который доступен в вашем рабочем пространстве. В этом наборе данных содержится информация о разных автомобилях, включая сведения о производителе, модели, технических характеристиках и цене.
Совет
Рабочую копию этого эксперимента вы можете найти в коллекции решений Azure AI. Перейдите по ссылке Ваш первый эксперимент по анализу данных. Прогнозирование цен на автомобили , затем щелкните Open in Studio (Открыть в студии), чтобы загрузить в рабочее пространство классической версии Студии копию этого эксперимента.
Теперь мы узнаем, как поместить этот набор данных в эксперимент.
Создайте эксперимент, щелкнув +NEW (+Создать) в нижней части окна классической версии Студии машинного обучения. Выберите EXPERIMENT>Blank Experiment (Эксперимент > Пустой эксперимент).
Эксперименту будет присвоено имя по умолчанию, которое отображается в верхней части холста. Щелкните этот текст и измените его на любое удобное для вас имя, например Прогнозирование цен на автомобили. Имя не обязано быть уникальным.
В левой части области эксперимента расположена выборка данных и модулей. Введите значение автомобили в поле поиска в верхней части палитры и найдите набор данных с названием Данные о ценах на автомобили (необработанные) . Перетащите набор данных на холст эксперимента.
Чтобы просмотреть, как выглядят эти данные, щелкните порт вывода в нижней части набора данных об автомобилях и выберите Visualize (Визуализировать).
Совет
У наборов данных и модулей есть входные и выходные порты, представленные маленькими кружками. Входные порты всегда расположены вверху, а выходные — внизу. Чтобы создать поток данных через эксперимент, подключите выходной порт одного модуля ко входному порту другого. Вы можете щелкнуть выходной порт набора данных или модуля, чтобы увидеть, как выглядят данные в этой точке потока данных.
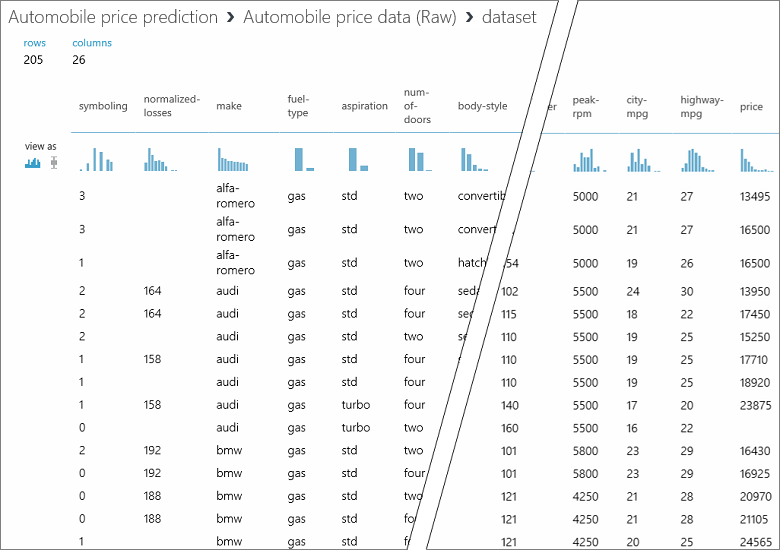
В этом наборе данных каждая строка представляет автомобиль, а переменные, обозначающие их характеристики, представлены в виде столбцов. Мы спрогнозируем цену автомобиля по представленным характеристикам и отобразим ее в крайнем правом столбце (столбец 26 с названием price (Цена)).
Закройте окно визуализации, нажав «x» в правом верхнем углу.
Подготовка данных
Перед анализом, как правило, требуется определенная предварительная обработка набора данных. Вы могли заметить, что в столбцах некоторых строк отсутствуют значения. Чтобы модель смогла правильно проанализировать данные, необходимо очистить эти недостающие значения. Мы удалим все строки, в которых есть недостающие значения. В столбце normalized-losses (нормированные потери) также есть значительная доля недостающих значений, поэтому мы исключим весь этот столбец из модели.
Совет
Удаление недостающих значений из входных данных является необходимым условием для использования большинства модулей.
Сначала мы добавим модуль, который полностью удаляет столбец normalized-losses (Нормированные потери). Затем мы добавим еще один модуль, который удаляет строки, в которых есть недостающие значения.
Введите select column в поле поиска в верхней части палитры модулей, чтобы найти модуль Select Columns in Dataset (Выбор столбцов в наборе данных). Перетащите этот модуль на холст эксперимента. Этот модуль позволяет выбрать, какие столбцы данных нужно включить в модель или исключить из нее.
Соедините выходной порт набора данных Automobile price data (Raw) (Данные о ценах на автомобили (необработанные) с входным портом модуля Select Columns in Dataset (Выбор столбцов в наборе данных).
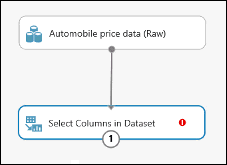
Выберите модуль Select Columns in Dataset (Выбор столбцов в наборе данных) и нажмите Launch column selector (Запустить средство выбора столбцов) в области Свойства.
Слева щелкните With rules (Применяя правила)
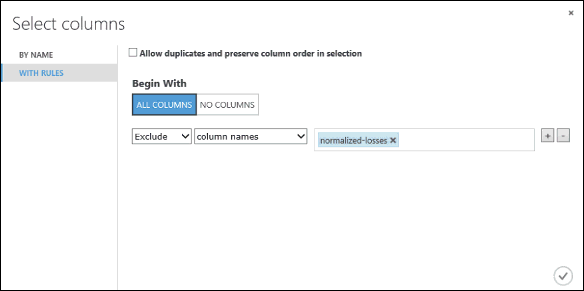
В разделе Begin With (Начинаются с) нажмите кнопку All columns (Все столбцы). Такие правила укажут модулю Select Columns in Dataset (Выбор столбцов в наборе данных) обрабатывать все столбцы (кроме тех, которые мы собираемся исключить).
В раскрывающихся списках выберите Exclude (Исключить) и Column names (Имена столбцов), а затем щелкните внутри текстового поля. Отобразится список столбцов. Выберите элемент normalized-losses (нормированные потери), чтобы добавить его в текстовое поле.
Нажмите кнопку ОК (с зеленым флажком) внизу справа, чтобы закрыть средство выбора столбцов.
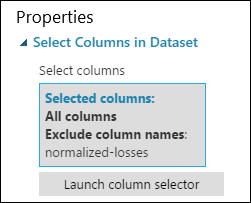
Теперь область свойств модуля Select Columns in Dataset (Выбор столбцов в наборе данных) показывает, что модуль пройдет через все столбцы набора данных, за исключением столбца Normalized-losses.
Совет
Дважды щелкните модуль и введите текст, чтобы добавить комментарий. Это поможет вам увидеть описание модуля и его действие в рамках эксперимента. В этом случае дважды щелкните модуль Select Columns in Dataset (Выбор столбцов в наборе данных) и введите комментарий об исключении столбца нормированных потерь.
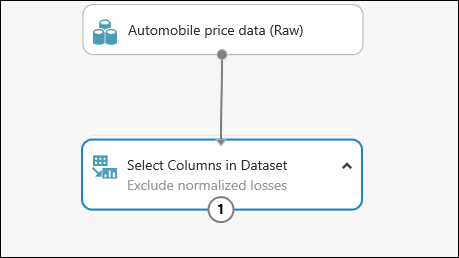
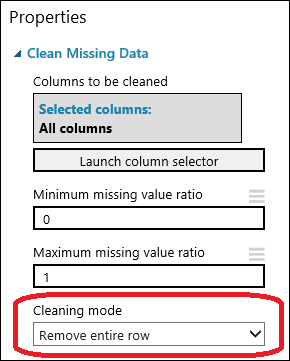
Перетащите на холст эксперимента модуль Clean Missing Data (Очистка недостающих данных) и присоедините его к модулю Select Columns in Dataset (Выбор столбцов в наборе данных). В панели Properties (Свойства) выберите значение Remove entire row (Удалить всю строку) для параметра Cleaning mode (Режим очистки). Этот параметр указывает модулю Clean Missing Data (Очистка недостающих данных) полностью удалять те строки, в которых есть недостающие значения. Дважды щелкните модуль и введите комментарий "Удаление строк с недостающими значениями".
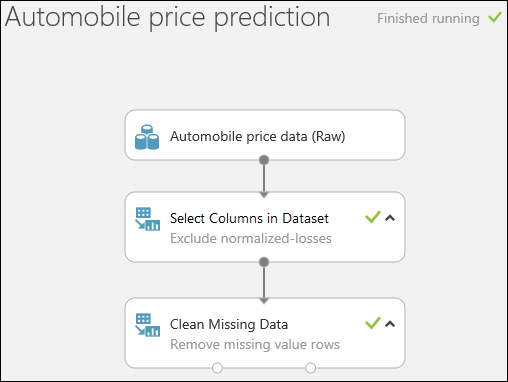
Запустите эксперимент, щелкнув кнопку RUN (Запуск) в нижней части страницы.
После завершения эксперимента у всех модулей должен появиться зеленый флажок, означающий успешное выполнение. Обратите также внимание на состояние Работа завершена в правом верхнем углу.
Совет
Для чего мы сейчас запускаем эксперимент? После запуска эксперимента все определения столбцов из нашего набора данных передаются в модуль Select Columns in Dataset (Выбор столбцов в наборе данных) и проходят через него к модулю Clean Missing Data (Очистка недостающих данных). Теперь все модули, которые мы подключим к модулю Clean Missing Data (Очистка недостающих данных), смогут получить эту информацию.
Мы получили очищенные данные. Чтобы просмотреть очищенный набор данных, щелкните левый выходной порт модуля Clean Missing Data (Очистка отсутствующих данных) и выберите Visualize (Визуализировать). Обратите внимание, что столбца normalized-losses больше нет. Кроме того, теперь нет недостающих значений.
После очистки данных мы готовы к заданию свойств, которые будут использоваться в прогнозной модели.
Определение признаков
В машинном обучении признаки — это отдельные измеримые свойства интересующих вас объектов. В нашем наборе данных каждая строка представляет собой один автомобиль, а каждый столбец — его признак.
Чтобы подобрать подходящий набор признаков для создания прогнозной модели, нужно разбираться в проблеме, которую необходимо решить, и провести ряд экспериментов. Некоторые свойства лучше подходят для прогнозирования цели, чем другие. Некоторые признаки совпадают с другими, и часть из них можно удалить. Например, свойства city-mpg и highway-mpg действуют почти одинаково, и мы можем удалить любое из них без существенного ухудшения прогноза.
Давайте создадим модель, которая использует подмножество свойств в нашей выборке. Вы можете вернуться сюда позже и выбрать различные свойства, заново запустить эксперимент и оценить результаты. Но для начала давайте попробуем следующие возможности.
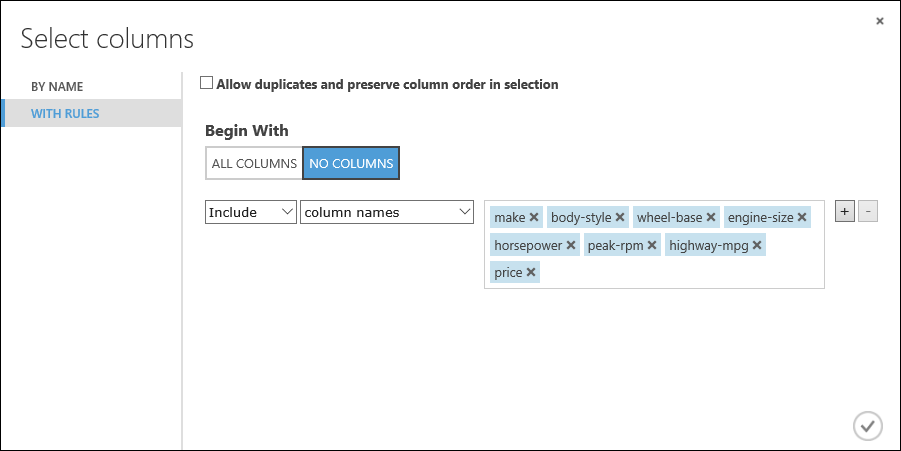
make, body-style, wheel-base, engine-size, horsepower, peak-rpm, highway-mpg, price
Перетащите на холст эксперимента еще один модуль Select Columns in Dataset (Выбор столбцов в наборе данных). Подключите левый выходной порт модуля Clean Missing Data (Очистка недостающих данных) к входу модуля Select Columns in Dataset (Выбор столбцов в наборе данных).
Дважды щелкните модуль и введите: "Выбор признаков для прогнозирования".
В области Свойства щелкните Launch column selector (Запустить средство выбора столбцов).
Щелкните With rules(С правилами).
В разделе Begin With (Начальное состояние) нажмите кнопку No columns (Нет столбцов). В строке фильтра выберите Include (Включить) и column names (имена столбцов), а затем выберите в текстовом поле созданный список столбцов. Этот фильтр указывает модулю не проходить никакие столбцы (признаки), кроме выбранных.
Щелкните значок с изображением флажка (кнопка "ОК").
В результате мы получим отфильтрованный набор данных, содержащий только те признаки, которые мы хотим передать в обучающий алгоритм на следующем шаге. Позже вы сможете вернуться назад и заново попробовать выбрать другой набор признаков.
Выбор и применение алгоритма
Теперь, когда данные готовы, процесс построения прогнозной модели состоит из обучения и тестирования. Сначала мы используем имеющиеся данные для обучения модели, а затем протестируем ее, чтобы увидеть, насколько точно она может прогнозировать цены.
Есть два типа алгоритмов контролируемого машинного обучения — классификация и регрессия. Классификация используется, чтобы сформировать прогноз по заданному набору категорий, таких как цвет (красный, синий, или зеленый). Регрессия используется для прогнозирования числа.
Мы хотим предсказать цену, которая является числом, поэтому будем использовать модель регрессии. В нашем примере мы воспользуемся моделью линейной регрессии.
Для обучения модели мы передаем ей набор данных, содержащий цены. Модель сканирует эти данные и ищет зависимости между свойствами автомобиля и его ценой. После этого мы тестируем модель, то есть передаем ей набор свойств известных нам автомобилей и проверяем, насколько точно модель прогнозирует известные нам цены.
Наш набор данных мы разделим на два набора, один из которых применим для обучения модели, а второй — для тестирования.
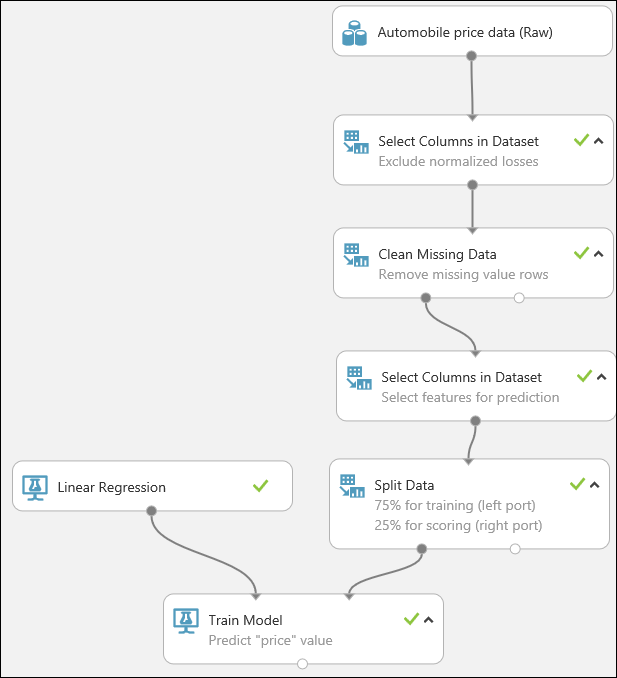
Выберите и перетащите в область эксперимента модуль Split Data (Разделение данных), а затем подключите его к последнему модулю Select Columns in Dataset (Выбор столбцов в наборе данных).
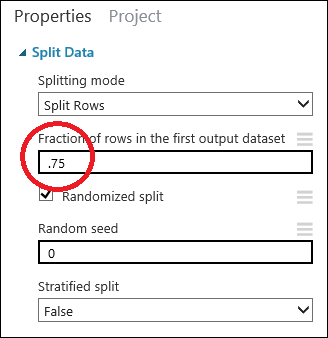
Щелчком выберите модуль Split Data (Разделение данных). В панели Properties (Свойства) справа от холста найдите параметр Fraction of rows in the first output dataset (Доля строк в первом выходном наборе данных) и установите для него значение 0,75. Таким образом, мы используем 75 процентов данных для обучения модели и оставим 25 процентов для тестирования.
Совет
Изменяя параметр Псевдослучайные числа, вы можете создавать различные случайные выборки для обучения и тестирования. Этот параметр задает начальное значение для генератора псевдослучайных чисел.
Запустите эксперимент. После выполнения эксперимента модули Select Columns in Dataset (Выбор столбцов в наборе данных) и Split Data (Разделение данных) смогут передать определения столбцов следующим модулям, которые мы добавим позже.
Для выбора алгоритма обучения разверните категорию Машинное обучение на палитре модулей слева на холсте эксперимента, а затем разверните Initialize Model (Инициализировать модель). Появится несколько категорий модулей, которые можно использовать для инициализации алгоритма обучения. Для этого эксперимента выберите модуль Linear Regression (Линейная регрессия) из категории Regression (Регрессия) и перетащите его на холст. (Можно также найти модуль, введя "linear regression" в поле поиска палитры.)
Найдите и переместите модуль Train Model (Обучение модели) на холст эксперимента. Соедините выход модуля Linear Regression (Линейная регрессия) с левым входом модуля Train Model (Обучение модели), а затем соедините выход (левый порт) модуля Split Data (Разделение данных) с правым входом модуля Train Model (Обучение модели).
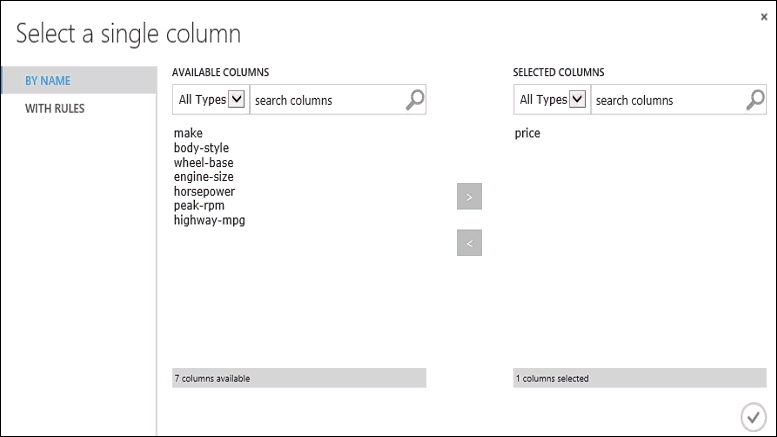
Выберите модуль Train Model (Обучение модели), щелкните Launch column selector (Запустить средство выбора столбцов) в области Properties (Свойства) и выберите столбец price (цена). Price (Цена) — это значение, которое спрогнозирует наша модель.
Чтобы выбрать столбец price (цена) в средстве выбора столбцов, переместите его из списка Available columns (Доступные столбцы) в список Selected columns (Выбранные столбцы).
Запустите эксперимент.
Теперь у нас есть обученная регрессионная модель, которую можно использовать для оценки новых данных об автомобилях с целью прогнозирования цен.
Прогнозирование цен на новые автомобили
После того как мы обучили модель, использовав 75 процентов наших данных, ее можно использовать для оценки оставшихся 25 процентов данных, чтобы проверить, насколько хорошо она работает.
Найдите модуль Score Model (Оценка модели) и перетащите его на холст эксперимента. Соедините выход модуля Train Model (Обучение модели) с левым входным портом модуля Score Model (Оценка модели). Соедините выход тестовых данных (правый порт) модуля Split Data (Разделение данных) с правым входным портом Score Model (Оценка модели).
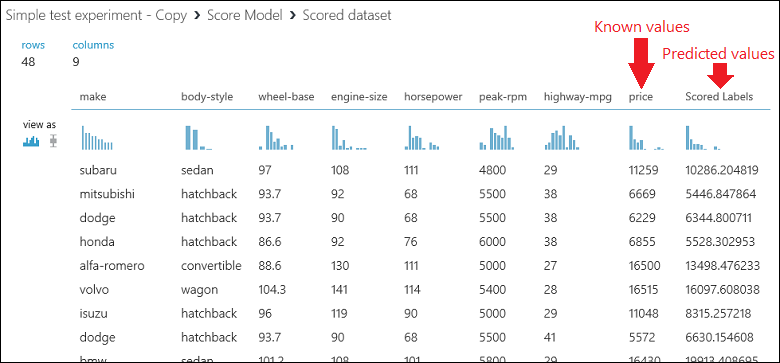
Запустите эксперимент и проверьте выходные данные модуля Score Model (Оценка модели), щелкнув порт вывода модуля Score Model (Оценка модели) и выбрав Visualize (Визуализировать). На порту вывода будут показаны прогнозируемые значения цены вместе с известными значениями проверочных данных.
Теперь мы готовы проверить качество результатов. Выберите модуль Evaluate Model (Анализ модели) и перетащите его на холст эксперимента, а затем соедините выход модуля Score Model (Оценка модели) с левым входом модуля Evaluate Model (Анализ модели). Окончательная схема нашего эксперимента должна выглядеть следующим образом:
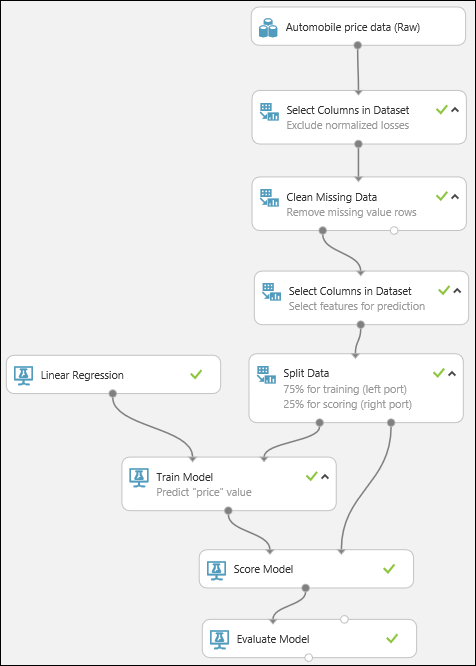
Запустите эксперимент.
Чтобы проверить выходные данные модуля Evaluate Model (Анализ модели), щелкните порт вывода и выберите элемент Visualize (Визуализировать).
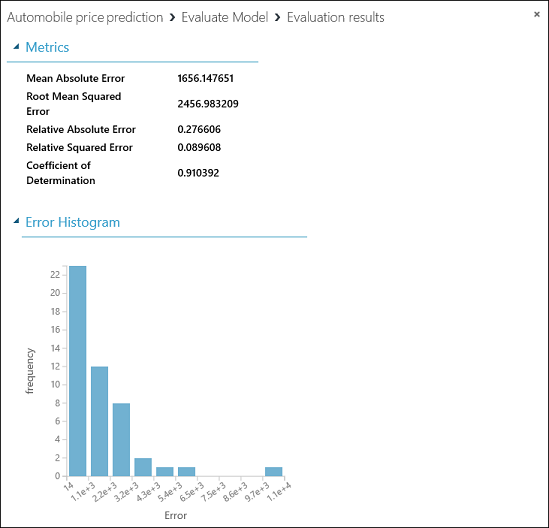
Для нашей модели будет выведена следующая статистика.
- Средняя абсолютная погрешность. Среднее значение абсолютной погрешности (погрешность — это разница между спрогнозированным и фактическим значением).
- Среднеквадратичное отклонение. Квадратный корень из среднего значения возведенных в квадрат арифметических отклонений спрогнозированных значений тестового набора данных.
- Относительное арифметическое отклонение. Среднее арифметическое отклонение по отношению к абсолютной разнице между фактическими значениями и средним арифметическим всех фактических значений.
- Относительное среднеквадратичное отклонение. Среднее арифметическое среднеквадратичных отклонений по отношению к абсолютной разнице между фактическими значениями и средним арифметическим всех фактических значений.
- Коэффициент смешанной корреляции (R в квадрате). Статистический показатель, который оценивает соответствие модели данным.
Чем меньше значение каждой погрешности, тем лучше. Меньшее значение указывает на то, что прогноз лучше соответствует фактическим значениям. Для показателя коэффициент смешанной корреляциичем ближе его значение к единице (1,0), тем точнее прогноз.
Очистка ресурсов
Если вы не планируете дальше использовать ресурсы, созданные при работе с этой статьей, удалите их, чтобы плата не взималась. О том, как это сделать, см. в статье Экспорт и удаление встроенных в продукт данных пользователей из Студии машинного обучения Azure.
Дальнейшие действия
В этом кратком руководстве описано, как создать простой эксперимент с использованием примера набора данных. Чтобы узнать больше о создании и развертывании модели, перейдите к руководству по прогнозному решению.