Оценка емкости службы поиска, а также управление ею
В службе "Поиск ИИ Azure" емкость основана на реплика и секциях, которые можно масштабировать до рабочей нагрузки. Реплики — это копии поисковой системы. Секции — это единицы хранения. Каждая новая служба поиска начинается с каждой, но вы можете добавлять или удалять реплика и секции независимо для размещения изменяющихся рабочих нагрузок. Добавление емкости увеличивает затраты на выполнение службы поиска.
Физические характеристики реплик и секций, например скорость обработки и ввод-вывод на диск, зависят от уровня служб. В стандартной службе поиска реплика и секции быстрее и больше, чем в базовой службе.
Изменение емкости не является мгновенным. Для комиссии или списания секций может потребоваться до часа, особенно для служб с большими объемами данных.
При масштабировании службы поиска можно выбрать один из следующих средств и подходов:
Основные понятия: единицы поиска, реплика, секции
Емкость выражается в единицах поиска, которые можно выделить в сочетаниях секцийи реплика.
| Понятие | Определение |
|---|---|
| Единица поиска | Базовый шаг общей доступной емкости (36 единиц). Это также единица выставления счетов для azure AI служба . Для запуска службы требуется минимум одна единица поиска. |
| Реплика | Экземпляры службы поиска, используемые главным образом для распределения операций запросов. На каждой реплике размещается одна копия индекса. При выделении трех реплика у вас есть три копии индекса, доступного для обслуживания запросов. |
| Секция | Служит для физического хранения индексов и ввода-вывода данных для операций чтения и записи (например, при повторном создании или обновлении индексов). Каждая секция содержит срез общего индекса. Если вам выделено три секции, индекс делится на три части. |
Просмотрите таблицы секций и реплика для возможных сочетаний, которые остаются в пределах 36 единиц.
Когда следует расширять емкость
Для службы поиска изначально выделяется минимальный уровень ресурсов, состоящий из одного раздела и одной реплики. Выбранный ценовой уровень определяет размер и скорость секции, и каждый уровень оптимизирован по набору характеристик, соответствующих различным сценариям. При выборе более высокого уровня может потребоваться меньше секций, чем для уровня S1. Один из вопросов, на которые нужно ответить при самостоятельном тестировании, — удается ли вам добиться повышения производительности с более дорогой секцией большего размера по сравнению с двумя более дешевыми секциями в службе более низкого уровня.
Одна служба должна иметь достаточно ресурсов для обработки всех рабочих нагрузок (индексирования и запросов). Ни одна рабочая нагрузка не выполняется в фоновом режиме. Можно запланировать индексирование в течение времени, когда запросы, естественно, реже, но служба не будет определять приоритеты одной задачи по сравнению с другой. Кроме того, определенный объем избыточности повышает производительность запросов при внутреннем обновлении служб или узлов.
Вот еще несколько факторов, от которых зависит целесообразность расширения емкости.
- Обеспечение высокого уровня доступности в соответствии с соглашением об уровне обслуживания
- Повышение частоты ошибок HTTP 503.
- Предполагаемое увеличение объемов запросов
Как правило, приложениям поиска требуется больше реплик, чем секций, особенно если служба в основном обрабатывает рабочие нагрузки запросов. Реплика — это копия вашего индекса, позволяющая службе балансировать нагрузку по запросам, распределяя их между несколькими копиями. Все подсистемы балансировки нагрузки и реплика индексов управляются поиском ИИ Azure, и вы можете изменить количество реплика, выделенных для службы в любое время. Можно выделить до 12 реплик для службы поиска уровня "Стандартный" и до 3 реплик для службы поиска уровня "Базовый". Для выделения реплики можно использовать портал Azure либо одно из программных средств.
Дополнительные секции полезны для интенсивных индексирования рабочих нагрузок. Дополнительные секции распределяют операции чтения и записи в большем количестве вычислительных ресурсов.
Наконец, запрос к большому индексу выполняется дольше. Поэтому может оказаться, что каждое добавочное увеличение числа секций потребует меньшего, но пропорционального увеличения числа реплик. Сложность запросов и их объем обусловливают скорость выполнения запросов.
Примечание.
Добавление реплик или секций увеличивает затраты на эксплуатацию службы и может вести к незначительным колебаниям в порядке выдаваемых результатов. Не забудьте воспользоваться калькулятором цен, который позволяет понять, как добавление узлов влияет на затраты. Диаграмма ниже позволит вам сориентироваться в количестве единиц поиска, необходимых для той или иной конфигурации. Дополнительные сведения о том, как дополнительные реплики влияют на обработку запросов, см. в статье Упорядочение результатов.
Изменение емкости
Чтобы увеличить или уменьшить емкость службы поиска, добавьте или удалите секции и реплика.
Войдите на портал Azure и выберите службу поиска.
В разделе Параметрыоткройте страницу Масштаб, чтобы изменить число реплик и секций.
На следующем снимка экрана показана служба "Стандартный", подготовленная с одним реплика и разделом. В формуле внизу показано, сколько единиц поиска используется (1). Если бы цена за единицу составляла 1000 рублей (это произвольное, а не реальное значение), ежемесячная стоимость эксплуатации этой службы составляла бы в среднем 1000 рублей.
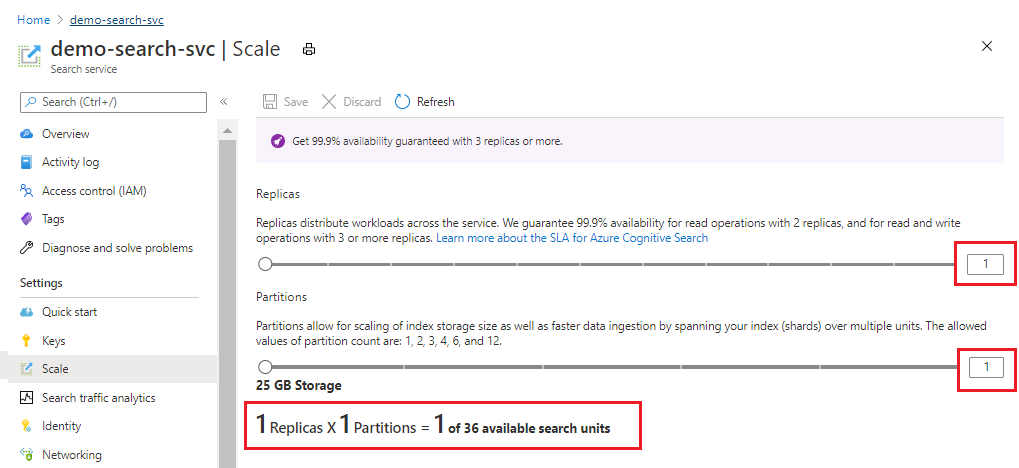
С помощью ползунка увеличивайте и уменьшайте число секций. Выберите Сохранить.
В этом примере добавляются вторая реплика и секция. Обратите внимание на количество единиц поиска; Теперь это четыре, так как формула выставления счетов реплика умножена на секции (2 x 2). Удвоение емкости ведет к увеличению затрат на службу более чем вдвое. Если бы цена за единицу поиска составляла 1000 рублей, новый ежемесячный счет теперь составлял бы 4000 рублей.
Текущую стоимость на единицу на каждом ценовом уровне см. на странице цен.
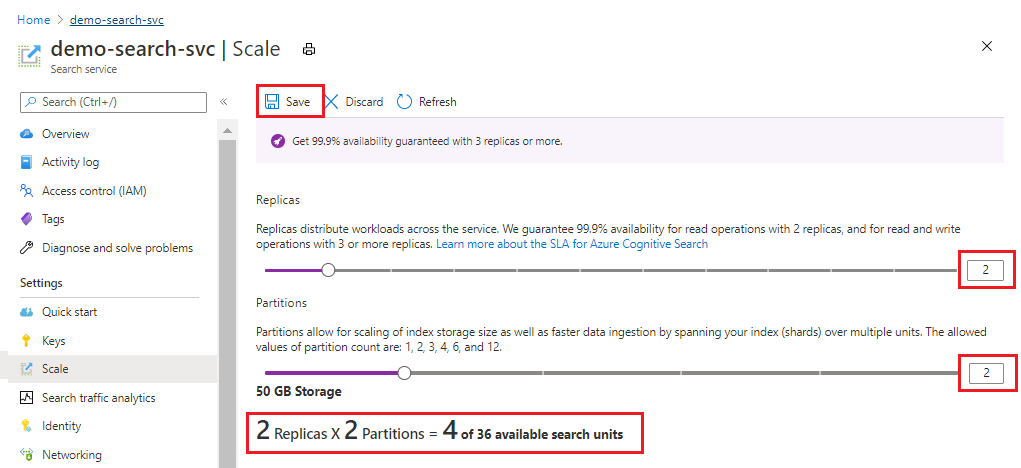
После сохранения проверьте уведомления на случай, если от вас требуются дополнительные действия.
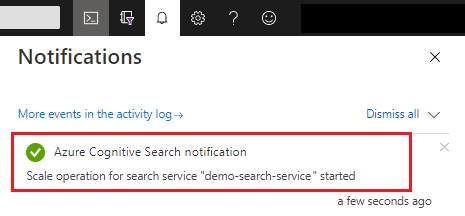
Для изменения емкости может потребоваться от 15 минут до нескольких часов. После начала процесса невозможно отменить мониторинг в режиме реального времени для реплика и корректировки секций. Однако в процессе применения изменений отображается следующее сообщение.

Примечание.
После подготовки службы перевести ее на более высокий ценовой уровень невозможно. Вам нужно будет создать службу поиска на новом уровне и перезагрузить индексы. Дополнительные сведения о подготовке служб см. в статье "Создание служба ИИ Azure" на портале.
Как обрабатываются запросы на масштабирование
При получении запроса на масштабирование служба поиска делает следующее:
- Проверяет, допустимый ли запрос.
- Запускает резервное копирование данных и системных сведений.
- Проверяет, находится ли служба в состоянии подготовки (в настоящее время добавление или удаление реплик или секций).
- Начинает подготовку.
Масштабирование службы может занять всего 15 минут или более часа, в зависимости от размера службы и области запроса. Резервное копирование может занять несколько минут в зависимости от объема данных и количества секций и реплик.
Приведенные выше шаги не полностью последовательны. Например, система начинает подготовку, когда она может запустить ее безопасно, а это может быть во время завершения резервного копирования.
Ошибки при масштабировании
Сообщение об ошибке "Операции обновления службы на данный момент не разрешены, так как мы обрабатываем предыдущий запрос" вызвано повтором запроса, чтобы уменьшить или увеличить масштаб, когда служба уже обрабатывает предыдущий запрос.
Чтобы устранить эту ошибку, проверьте состояние службы, чтобы проверить состояние подготовки:
- Для получения состояния службы используйте REST API управления, Azure PowerShell или Azure CLI.
- Вызовите службу get (REST) или эквивалентную для PowerShell или ИНТЕРФЕЙСА командной строки.
- Проверьте ответ на наличие состояния provisioningState: подготовка
Если состояние — "Подготовка", дождитесь завершения запроса. Перед попыткой выполнения другого запроса состояние должно иметь значение "Успешно" или "Ошибка". Для резервного копирования нет состояния. Резервное копирование является внутренней операцией, и маловероятно, что оно не повлияет на перерывы в выполнении упражнения масштабирования.
Если служба поиска, как представляется, остановилась в состоянии подготовки, проверка для потерянных индексов, которые недоступны для использования, с нулевыми томами запросов и без обновлений индекса. Неиспользуемый индекс может блокировать изменения емкости службы. В частности, найдите индексы, зашифрованные с помощью CMK, ключи которых больше не допустимы. Необходимо удалить индекс или восстановить ключи, чтобы вернуть индекс в режим "в сети" и разблокировать операцию масштабирования.
сочетания разделов и реплик
На следующей диаграмме применяется уровень "Стандартный" и выше. В нем отображаются все возможные сочетания секций и реплика, при условии, что для каждой службы максимальное количество единиц поиска составляет 36.
| 1 секция | 2 секции | 3 секции | 4 секции | 6 секций | 12 секций | |
|---|---|---|---|---|---|---|
| 1 реплика | 1 SU | 2 ЕП | 3 ЕП | 4 ЕП | 6 ЕП | 12 ЕП |
| 2 реплики | 2 ЕП | 4 ЕП | 6 ЕП | 8 ЕП | 12 ЕП | 24 ЕП |
| 3 реплики | 3 ЕП | 6 ЕП | 9 ЕП | 12 ЕП | 18 ЕП | 36 ЕП |
| 4 реплики | 4 ЕП | 8 ЕП | 12 ЕП | 16 ЕП | 24 ЕП | Н/П |
| 5 реплик | 5 ЕП | 10 ЕП | 15 ЕП | 20 ЕП | 30 ЕП | Н/П |
| 6 реплик | 6 ЕП | 12 ЕП | 18 ЕП | 24 ЕП | 36 ЕП | Н/П |
| 12 реплик | 12 ЕП | 24 ЕП | 36 ЕП | Неприменимо | Н/Д | Неприменимо |
Базовые службы поиска имеют меньшее количество единиц поиска.
В службах поиска, созданных до 3 апреля 2024 года, базовая служба поиска может иметь ровно одну секцию и до трех реплика для максимального ограничения трех единиц SUS. Единственным ресурсом, который можно изменять, являются реплики.
В службах поиска, созданных после 3 апреля 2024 г. в поддерживаемых регионах, базовые службы могут иметь до трех разделов и трех реплика. Максимальное ограничение su составляет девять для поддержки полного дополнения секций и реплика.
Для служб поиска на любом оплачиваемом уровне независимо от даты создания требуется не менее двух реплика для обеспечения высокой доступности запросов.
Сведения о тарифах выставления счетов на одну категорию и валюту см. на странице цен на поиск по искусственному интеллекту Azure.
Оценка емкости с помощью оплачиваемого уровня
Требования к хранилищу определяются размером индексов, которые предполагается создать. Не существует надежных эвристических или общих методов, помогающих провести оценку. Единственный способ определить размер индекса — создать его. Его размер основан на маркеризации и внедрении, а также включаете ли вы предложения, фильтрацию и сортировку или можете воспользоваться преимуществами сжатия векторов.
Мы рекомендуем оценить оплачиваемый уровень, базовый или более поздний. Уровень "Бесплатный" выполняется на физических ресурсах, общих несколькими клиентами, и зависит от факторов, выходящих за рамки вашего контроля. Только выделенные ресурсы оплачиваемой службы поиска могут вместить больше времени выборки и обработки для более реалистичных оценок количества индексов, размеров и томов запросов во время разработки.
Ознакомьтесь с ограничениями служб на каждом уровне, чтобы определить, поддерживают ли нижние уровни достаточное для вас количество индексов. Рассмотрите необходимость нескольких копий индекса для активной разработки, тестирования и рабочей среды.
Служба поиска подвергается ограничениям объектов (максимальное количество индексов, индексаторов, наборов навыков и т. д.) и ограничений хранения. Любое ограничение, достигнутое первым, является эффективным ограничением.
Создайте службу на оплачиваемом уровне. Уровни оптимизированы для определенных рабочих нагрузок. Например, служба хранилища оптимизированный уровень имеет ограничение в 10 индексов, так как он предназначен для поддержки небольшого количества очень больших индексов.
Если вы не уверены относительно масштабов нагрузки, начните с низкого уровня: "Базовый" или S1.
Если при тестировании предполагается масштабная индексация и высокая интенсивность запросов, начинайте сразу с уровня S2 или даже S3.
Если вы планируете индексировать большой объем данных, а интенсивность запросов будет относительно низкой (как для внутреннего бизнес-приложения), начните с уровня "Оптимизированный для операций в хранилище" L1 или L2.
Создайте начальный индекс, чтобы определить, как исходные данные преобразуются в индекс. Это единственный способ оценки размера индекса. Атрибуты определений полей влияют на требования к физическому хранилищу:
Для поиска ключевое слово пометка полей как фильтруемых и сортируемых увеличивает размер индекса.
Для поиска векторов можно задать параметры для уменьшения объема хранилища.
Отслеживайте хранилище, ограничения служб, объем запросов и задержку в портале. На портале отображаются показатели запросов в секунду, регулируемых запросов и задержки поиска, которые помогают определить, находитесь ли вы на правильном уровне.
Добавьте реплика для обеспечения высокой доступности или снижения производительности медленных запросов.
Рекомендаций по количеству реплик, необходимых для того или иного уровня интенсивности запросов, не существует. Производительность запросов зависит от сложности запроса и конкурирующих рабочих нагрузок. Хотя добавление реплика явно приводит к повышению производительности, результат не является строго линейным: добавление трех реплика не гарантирует тройную пропускную способность. Рекомендации по оценке QPS для решения см. в статье "Анализ производительностии мониторинг запросов".
Для инвертированного индекса размер и сложность определяются содержимым, а не обязательно объемом данных, которые вы передаете в него. Большой источник данных с высокой избыточностью может привести к созданию меньшего индекса, чем для меньшего набора данных, который содержит сильно изменяемое содержимое. Таким образом, редко бывает возможным определить размер индекса на основе размера исходного набора данных.
Требования к хранилищу могут оказаться ниже, если у вас есть данные, которые никто никогда не будут искать. В идеале документы должны содержать только данные, необходимые для поиска.
Рекомендации по соглашению на уровне обслуживания
Бесплатный уровень и предварительный просмотр функций не охватываются соглашениями об уровне обслуживания (SLA). Для всех оплачиваемых уровней соглашения об уровне обслуживания вступают в силу, если для службы обеспечена достаточная избыточность.
Два или более реплика удовлетворяют соглашениям об уровне обслуживания запросов (чтение).
Три или более реплика удовлетворяют соглашениям об уровне обслуживания запросов и индексации (чтение и запись).
Количество секций не влияет на соглашения об уровне обслуживания.