Выбор уровня служб для поиска ИИ Azure
Часть создания службы поиска — выбор ценовой категории (или SKU), фиксированной для времени существования службы. На портале уровень указывается на странице Выбор ценовой категории при создании службы. Если вы выполняете подготовку через PowerShell или Azure CLI, уровень указывается с помощью параметра -Sku.
Выбранная ценовая категория определяет:
- максимальное количество индексов и других объектов, разрешенных в службе;
- скорость секционирования и размер секций (физического хранилища).
- тариф как фиксированную ежемесячную стоимость (при наращивании емкости — с добавочной стоимостью).
В некоторых случаях от выбранной ценовой категории зависит также доступность функций уровня "Премиум"".
Цены (или оценочная ежемесячная стоимость работы службы) отображаются на странице Выбор ценовой категории портала. Изучите сведения о ценах на службы, чтобы спланировать затраты.
Примечание.
служба , созданные после 3 апреля 2024 г., имеют более крупные секции и более высокие квоты векторов почти на каждом уровне. Дополнительные сведения см. в разделе об ограничениях служб.
Описания ценовых категорий
Есть следующие ценовые категории: Бесплатный, Базовый, Стандартный и Оптимизированный для хранилища. Категории "Стандартный" и "Оптимизированный для операций в хранилище" предлагаются в нескольких конфигурациях и вариантах емкости. На следующем снимке экрана из портал Azure показаны доступные уровни, минус цены (которые можно найти на портале и на странице цен).
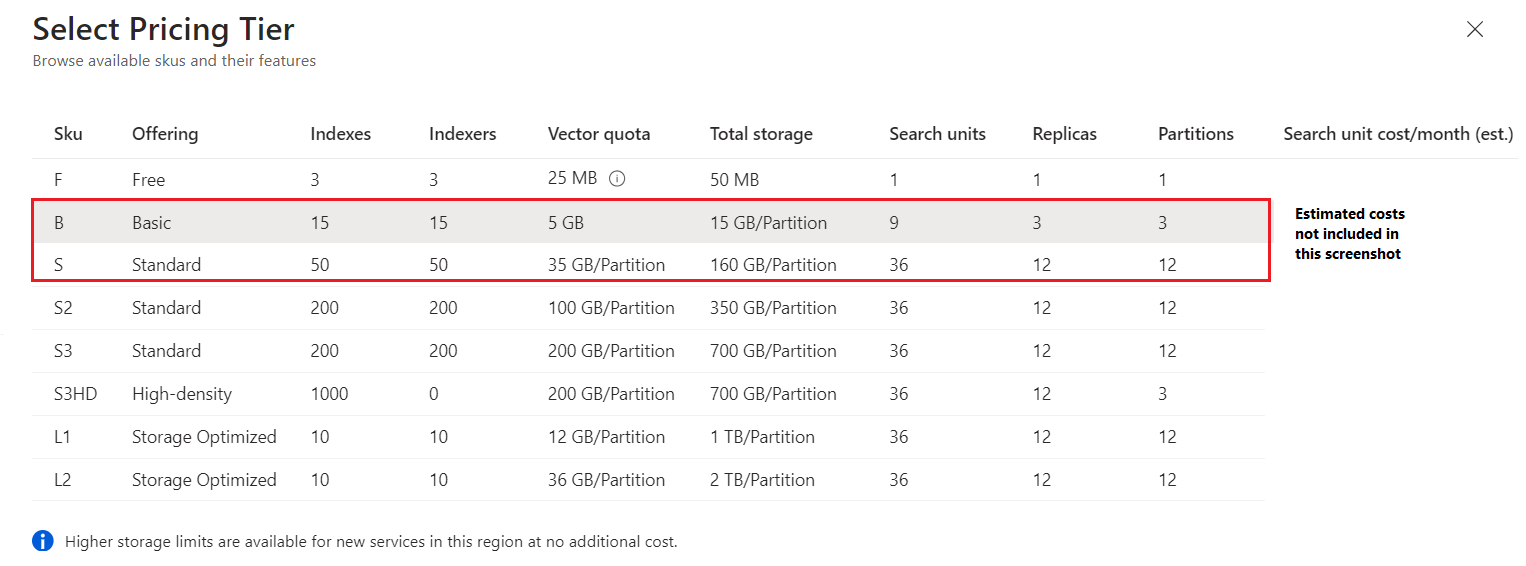
Free создает ограниченную службу поиска для небольших проектов, таких как выполнение учебников и примеров кода. На внутреннем уровне системные ресурсы используются совместно несколькими подписчиками. Вы не можете масштабировать бесплатную службу или выполнять значительные рабочие нагрузки. Для каждой подписки Azure можно использовать только одну бесплатную службу поиска.
Наиболее часто используемые уровни выставления счетов включают следующие:
Базовый имеет возможность удовлетворить соглашение об уровне обслуживания с поддержкой трех реплика.
Стандартная (S1, S2, S3) — это значение по умолчанию. Это обеспечивает большую гибкость масштабирования для рабочих нагрузок. Можно масштабировать секции и реплика. Имея в распоряжении выделенные ресурсы, вы можете разворачивать крупные проекты, оптимизировать производительность и наращивать емкость.
Некоторые уровни предназначены для определенных типов работы:
Стандартная 3 высокая плотность (S3 HD) — это режим размещения для S3, где базовое оборудование оптимизировано для большого количества небольших индексов и предназначено для сценариев мультитенантности. Плата за единицу в категории S3 HD такая же, как и в S3, но оборудование оптимизировано для быстрого чтения файлов в условиях значительного числа небольших индексов.
служба хранилища оптимизированные уровни (L1, L2) предлагают большую емкость хранилища по более низкой цене за ТБ, чем уровни "Стандартный". Эти уровни предназначены для больших индексов, которые не изменяются очень часто. Основной компромисс заключается в увеличенной задержке запросов, поэтому следует проверить, соответствует ли такая конфигурация требованиям вашего приложения.
Дополнительные сведения о различных уровнях на странице цен можно узнать в разделе "Ограничения службы" в статье "Поиск ИИ Azure" и на странице портала при подготовке службы.
Доступность компонентов по ценовым категориям
Большинство функций доступны во всех ценовых категориях, в том числе в категории "Бесплатный". В некоторых случаях уровень определяет доступность функции. В следующей таблице описываются ограничения.
| Функция | Ограничения |
|---|---|
| индексаторы | Индексаторы недоступны в S3 HD. Индексаторы имеют больше ограничений на бесплатный уровень. |
| Обогащение ИИ | Работает в категории "Бесплатный", но не рекомендуется. |
| Управляемые или доверенные удостоверения для исходящего доступа (индексатора) | Недоступен в категории "Бесплатный". |
| Управляемые пользователем ключи шифрования | Недоступен в категории "Бесплатный". |
| Доступ к брандмауэру IP | Недоступен в категории "Бесплатный". |
| Частная конечная точка (интеграция с Приватным каналом Azure) | Для входящих подключений к службе поиска — недоступна в категории "Бесплатный". Для исходящих подключений индексаторов к другим ресурсам Azure — недоступна в категориях "Бесплатный" и S3 HD. Для индексаторов, использующих наборы навыков — недоступна в категориях "Бесплатный", "Базовый", S1 и S3 HD. |
| Зоны доступности | Недоступно на уровне "Бесплатный" или "Базовый". |
| Семантический рангер | Недоступен в категории "Бесплатный". |
Качество работы ресурсоемких функций может быть недостаточным, если не выделить достаточную емкость. Например, при обогащении с помощью ИИ у ряда навыков, работающих на протяжении длительного времени, истекает время ожидания на уровне служб "Бесплатный", кроме случаев, когда набор данных небольшой.
Верхние пределы
Ценовые категории определяют максимальный объем хранилища самой службы, а также максимальное количество индексов, индексаторов, источников данных, наборов навыков и карт синонимов, которые можно создать. Полный разрыв всех ограничений см. в разделе "Ограничения службы" в службе "Поиск ИИ Azure".
Размер и производительность раздела
Ценовая категория содержит сведения о хранилище на секции, которое варьируется от 15 ГБ для уровня "Базовый" до 2 ТБ для уровней служба хранилища оптимизированных (L2). Другие аппаратные характеристики, такие как скорость операций, задержка и скорость передачи, не публикуются, но уровни, предназначенные для конкретных архитектур решений, основаны на оборудовании, которое имеет функции для поддержки этих сценариев. Дополнительные сведения о секциях см. в статье "Оценка емкости и надежность" в службе "Поиск ИИ Azure" и управление ими.
Тарифы
Тарифы различаются в зависимости от ценовой категории: в категориях, предусматривающих более дорогостоящие оборудование или функции, тарифы выше. Уровень выставления счетов можно найти на страницах цен Azure для поиска ИИ Azure.
После создания службы тариф складывается из фиксированной стоимости круглосуточной работы службы и добавочной стоимости в случае, если вы решите добавить емкость.
Вычислительные ресурсы выделяются службам поиска в форме разделов (хранилища) и реплик (экземпляров обработчика запросов). Изначально создается служба с одним разделом и одной репликой, а тариф включает оба эти ресурса. Однако при масштабировании емкости затраты повышаются или понижаются с шагом приращения, зависящим от тарифа.
Это показывается в следующем примере. Пусть действует гипотетический тариф, равный 100 долларам в месяц. Если служба поиска работает на исходном уровне емкости, т. е. с одним разделом и одной репликой, то можно ожидать, что в конце месяца вы заплатите те же 100 долларов. Если же вы добавите еще две реплики, чтобы обеспечить высокую доступность, сумма ежемесячного счета вырастет до 300 долларов (100 долларов за первую пару из раздела и реплики плюс 200 долларов за две реплики).
Эта модель выставления счетов основана на концепции применения тарифа выставления счетов к единицам поиска номеров (SU), используемым службой поиска. Изначально все службы подготавливаются к работе в расчете на одну SU, но вы можете увеличить число SU, добавив разделы или реплики для выполнения более интенсивных рабочих нагрузок. Дополнительные сведения см. в статье "Оценка и управление затратами на службу ''Когнитивный поиск Azure''".
Обновление уровня или понижение уровня
Встроенная поддержка обновления или понижения уровня отсутствует. Если вы хотите переключиться на другой уровень, подход :
Создайте новую службу поиска на новом уровне.
Разверните содержимое поиска в новой службе. Следуйте этому списку проверка, чтобы убедиться, что у вас есть все содержимое.
Удалите старую службу поиска после того, как вы уверены, что она больше не нужна.
Для больших индексов, которые вы не хотите перестроить с нуля, рекомендуется использовать образец резервного копирования и восстановления для их перемещения.
Следующие шаги
Лучший способ выбрать ценовую категорию — начать с наименее затратного уровня, с тем чтобы потом, основываясь на опыте и результатах тестирования, оставить службу как есть или создать другую в более высокой ценовой категории. Для дальнейшей работы рекомендуется создать службу поиска на уровне, соответствующем предполагаемому уровню тестирования, а затем рассмотреть следующие рекомендации по оценке затрат и емкости.