Руководство. Обучение модели в Python с помощью автоматизированного машинного обучения
Машинное обучение Azure представляет собой облачную среду, которая позволяет обучать, развертывать, автоматизировать, контролировать и отслеживать модели машинного обучения.
В этом руководстве показано, как в Машинном обучении Azure с помощью функции автоматизированного машинного обучения создать модель регрессии для прогнозирования тарифов на такси. Для получения оптимальной модели в ходе этого процесса добавляются данные для обучения и настраиваются параметры, а также выполняется автоматическая итерация с использованием комбинаций разных методов, моделей и настроек гиперпараметров.
В этом руководстве описано следующее:
- Скачивание данных с помощью Apache Spark и Открытых наборов данных Azure.
- Преобразование и очистка данных с помощью DataFrame в Apache Spark.
- Обучение модели регрессии в автоматизированном машинном обучении.
- Расчет точности модели.
Подготовка к работе
- Создайте бессерверный пул Apache Spark, следуя инструкциям из этого краткого руководства.
- Если у вас нет рабочей области Машинного обучения Azure, выполните инструкции из статьи Руководство по началу работы с Машинным обучением Azure в Jupyter Notebook.
Предупреждение
- Начиная с 29 сентября 2023 г. Azure Synapse прекратит официальную поддержку среды выполнения Spark 2.4. После 29 сентября 2023 г. мы не будем обращаться в службу поддержки, связанной с Spark 2.4. Конвейер выпуска не будет применяться для исправлений ошибок или безопасности для Spark 2.4. Использование Spark 2.4 после даты отключения поддержки выполняется по собственному риску. Мы настоятельно не рекомендуем использовать его продолжающееся использование из-за потенциальных проблем безопасности и функциональных возможностей.
- В рамках процесса нерекомендуемого использования Apache Spark 2.4 мы хотели бы уведомить вас о том, что AutoML в Azure Synapse Analytics также не рекомендуется. Это включает как интерфейс с низким кодом, так и ИНТЕРФЕЙСы API, используемые для создания пробных версий AutoML с помощью кода.
- Обратите внимание, что функции AutoML были доступны исключительно в среде выполнения Spark 2.4.
- Для клиентов, желающих продолжить использование возможностей AutoML, рекомендуется сохранить данные в вашей учетной записи Azure Data Lake Storage 2-го поколения (ADLSg2). Оттуда вы можете легко получить доступ к интерфейсу AutoML с помощью Машинное обучение Azure (AzureML). Дополнительные сведения об этом обходной путь доступны здесь.
Общие сведения о моделях регрессии
Модели регрессии прогнозируют числовые выходные значения на основе независимых прогностических факторов. В случае регрессии цель заключается в том, чтобы установить связь между этими независимыми переменными прогнозирования, оценивая, как одна переменная влияет на другие.
Пример на основе данных о поездках в такси по Нью-Йорку
В этом примере показано, как с помощью Spark выполнить анализ данных о чаевых таксистам Нью-Йорка. Данные доступны через открытые наборы данных Azure. Это подмножество набора данных содержит сведения о поездках на такси, включая сведения о каждой поездке, время начала и окончания, расположения и стоимость.
Внимание
За извлечение этих данных из хранилища может взиматься дополнительная плата. В следующих шагах вам предстоит разработать модель для прогнозирования тарифов на такси в Нью-Йорке.
Скачивание и подготовка данных
Это делается следующим образом:
Создайте записную книжку, используя ядро PySpark. Инструкции см. в разделе Создание записной книжки.
Примечание.
Ядро PySpark позволяет не задавать контексты явным образом. Контекст Spark будет создан автоматически при выполнении первой ячейки кода.
Так как необработанные данные имеют формат Parquet, можно использовать контекст Spark, чтобы извлечь файл в память напрямую в виде DataFrame. Создайте DataFrame в Spark, получив данные с помощью API Открытых наборов данных. Здесь мы будем использовать свойства
schema on readDataFrame в Spark, чтобы вывести типы и схему данных.blob_account_name = "azureopendatastorage" blob_container_name = "nyctlc" blob_relative_path = "yellow" blob_sas_token = r"" # Allow Spark to read from the blob remotely wasbs_path = 'wasbs://%s@%s.blob.core.windows.net/%s' % (blob_container_name, blob_account_name, blob_relative_path) spark.conf.set('fs.azure.sas.%s.%s.blob.core.windows.net' % (blob_container_name, blob_account_name),blob_sas_token) # Spark read parquet; note that it won't load any data yet df = spark.read.parquet(wasbs_path)В зависимости от размера пула Spark объем необработанных данных может быть слишком большим или их обработка может занимать слишком много времени. Для этих данных можно создать выборку (например, за месяц) с помощью фильтров
start_dateиend_date. После фильтрации DataFrame вам нужно выполнить функциюdescribe()с новым экземпляром DataFrame, чтобы просмотреть сводную статистику для каждого поля.В сводной статистике можно заметить, что в данных есть некоторое количество отклонений. Например, минимальное расстояние поездки в этой статистике имеет отрицательное значение. Вам придется отфильтровать эти некорректные точки данных.
# Create an ingestion filter start_date = '2015-01-01 00:00:00' end_date = '2015-12-31 00:00:00' filtered_df = df.filter('tpepPickupDateTime > "' + start_date + '" and tpepPickupDateTime< "' + end_date + '"') filtered_df.describe().show()Теперь создайте признаки по этому набору данных. Для этого выберите набор столбцов и создайте признаки на основе поля
datetimeс данными о времени посадки. Отфильтруйте обнаруженные на предыдущем шаге выбросы, а затем удалите несколько последних столбцов, так как они не нужны для обучения.from datetime import datetime from pyspark.sql.functions import * # To make development easier, faster, and less expensive, downsample for now sampled_taxi_df = filtered_df.sample(True, 0.001, seed=1234) taxi_df = sampled_taxi_df.select('vendorID', 'passengerCount', 'tripDistance', 'startLon', 'startLat', 'endLon' \ , 'endLat', 'paymentType', 'fareAmount', 'tipAmount'\ , column('puMonth').alias('month_num') \ , date_format('tpepPickupDateTime', 'hh').alias('hour_of_day')\ , date_format('tpepPickupDateTime', 'EEEE').alias('day_of_week')\ , dayofmonth(col('tpepPickupDateTime')).alias('day_of_month') ,(unix_timestamp(col('tpepDropoffDateTime')) - unix_timestamp(col('tpepPickupDateTime'))).alias('trip_time'))\ .filter((sampled_taxi_df.passengerCount > 0) & (sampled_taxi_df.passengerCount < 8)\ & (sampled_taxi_df.tipAmount >= 0)\ & (sampled_taxi_df.fareAmount >= 1) & (sampled_taxi_df.fareAmount <= 250)\ & (sampled_taxi_df.tipAmount < sampled_taxi_df.fareAmount)\ & (sampled_taxi_df.tripDistance > 0) & (sampled_taxi_df.tripDistance <= 200)\ & (sampled_taxi_df.rateCodeId <= 5)\ & (sampled_taxi_df.paymentType.isin({"1", "2"}))) taxi_df.show(10)Как видите, в результате создается новый экземпляр DataFrame, где есть дополнительные столбцы для дня месяца, часа посадки в такси, дня недели и общего времени поездки.

Создание наборов данных для тестирования и проверки
Получив итоговый набор данных, вам нужно разделить эти данные на обучающий и проверочный наборы данных с помощью функции random_ split в Spark. Используя предоставленные весовые коэффициенты, эта функция случайным образом разбивает данные на обучающий набор для обучения модели и проверочный набор для тестирования.
# Random split dataset using Spark; convert Spark to pandas
training_data, validation_data = taxi_df.randomSplit([0.8,0.2], 223)
Этот шаг гарантирует, что для проверки готовой модели будут использоваться точки данных, которые не использовались для обучения модели.
Подключение к рабочей области Машинного обучения Azure
Класс workspace в Машинном обучении Azure принимает сведения о подписке и ресурсах Azure. Он также создает облачный ресурс для мониторинга и отслеживания работы модели. На этом шаге вы создадите объект рабочей области на основе имеющейся рабочей области Машинного обучения Azure.
from azureml.core import Workspace
# Enter your subscription id, resource group, and workspace name.
subscription_id = "<enter your subscription ID>" #you should be owner or contributor
resource_group = "<enter your resource group>" #you should be owner or contributor
workspace_name = "<enter your workspace name>" #your workspace name
ws = Workspace(workspace_name = workspace_name,
subscription_id = subscription_id,
resource_group = resource_group)
Преобразование DataFrame в набор данных Машинного обучения Azure
Чтобы отправить удаленный эксперимент, преобразуйте набор данных в экземпляр TabularDatset для Машинного обучения Azure. TabularDataset представляет данные в табличном формате, выполняя синтаксический анализ предоставленных файлов.
Приведенный ниже код позволяет получить сведения о существующей рабочей области и стандартном хранилище данных Машинного обучения Azure. Затем это хранилище и расположение файлов передаются в параметре path для создания нового экземпляра TabularDataset.
import pandas
from azureml.core import Dataset
# Get the Azure Machine Learning default datastore
datastore = ws.get_default_datastore()
training_pd = training_data.toPandas().to_csv('training_pd.csv', index=False)
# Convert into an Azure Machine Learning tabular dataset
datastore.upload_files(files = ['training_pd.csv'],
target_path = 'train-dataset/tabular/',
overwrite = True,
show_progress = True)
dataset_training = Dataset.Tabular.from_delimited_files(path = [(datastore, 'train-dataset/tabular/training_pd.csv')])

Отправка эксперимента автоматизированного машинного обучения
В следующих разделах показано, как отправить эксперимент автоматизированного машинного обучения.
Определение параметров обучения
Чтобы отправить эксперимент, нужно определить параметр эксперимента и параметры модели для обучения. Полный список параметров см. в статье Настройка экспериментов автоматизированного машинного обучения на Python.
import logging automl_settings = { "iteration_timeout_minutes": 10, "experiment_timeout_minutes": 30, "enable_early_stopping": True, "primary_metric": 'r2_score', "featurization": 'auto', "verbosity": logging.INFO, "n_cross_validations": 2}Передайте определенные параметры обучения в качестве параметра
kwargsдля объектаAutoMLConfig. Так как вы используете Spark, нужно передать еще и контекст Spark, который автоматически будет доступен в переменнойsc. Кроме того, укажите обучающие данные и тип модели (в нашем примере это регрессия).from azureml.train.automl import AutoMLConfig automl_config = AutoMLConfig(task='regression', debug_log='automated_ml_errors.log', training_data = dataset_training, spark_context = sc, model_explainability = False, label_column_name ="fareAmount",**automl_settings)
Примечание.
Этапы предварительной обработки для автоматизированного машинного обучения становятся частью базовой модели. Они включают нормализацию признаков, обработку недостающих данных и преобразование текста в числовой формат. При использовании модели для прогнозирования эти этапы предварительной обработки, которые выполнялись во время обучения, автоматически выполняются для входных данных.
Обучение модели автоматической регрессии
Теперь создайте объект эксперимента в рабочей области Машинного обучения Azure. Эксперимент выступает в качестве контейнера для отдельных запусков.
from azureml.core.experiment import Experiment
# Start an experiment in Azure Machine Learning
experiment = Experiment(ws, "aml-synapse-regression")
tags = {"Synapse": "regression"}
local_run = experiment.submit(automl_config, show_output=True, tags = tags)
# Use the get_details function to retrieve the detailed output for the run.
run_details = local_run.get_details()
После завершения эксперимента возвращаются выходные данные с информацией о завершенных итерациях. Для каждой итерации вы видите тип модели, длительность выполнения и точность обучения. Поле BEST отслеживает лучший показатель обучения на основе типа метрик.

Примечание.
После отправки эксперимент автоматизированного машинного обучения будет выполнять разные итерации с разными типами моделей. Выполнение обычно занимает 60–90 мин.
Извлечение наиболее эффективной модели
Чтобы выбрать лучшую модель из выполненных итераций, примените функцию get_output, которая возвращает лучшее выполнение и полученную в нем модель. В приведенном ниже коде извлекаются данные о лучшем выполнении и соответствующей ему модели по любой зарегистрированной метрике или по определенной итерации.
# Get best model
best_run, fitted_model = local_run.get_output()
Проверка точности модели
Чтобы проверить точность модели, примените лучшую из полученных моделей для прогнозирования тарифов на такси по набору проверочных данных. Функция
predictиспользует лучшую модель и прогнозирует значенияy(стоимость поездки) по набору проверочных данных.# Test best model accuracy validation_data_pd = validation_data.toPandas() y_test = validation_data_pd.pop("fareAmount").to_frame() y_predict = fitted_model.predict(validation_data_pd)Для оценки разницы между прогнозируемыми и наблюдаемыми значениями часто используется величина "корень среднеквадратической погрешности". Вычислите корень среднеквадратической погрешности для полученных результатов, сравнив экземпляр DataFrame
y_testсо значениями, прогнозируемыми моделью.Функция
mean_squared_errorпринимает два массива значений и вычисляет значение среднеквадратической погрешности между ними. Из полученного результата извлеките квадратный корень. Эта метрика дает грубую оценку того, насколько полученные прогнозы стоимости поездок на такси соответствуют фактическим значениями.from sklearn.metrics import mean_squared_error from math import sqrt # Calculate root-mean-square error y_actual = y_test.values.flatten().tolist() rmse = sqrt(mean_squared_error(y_actual, y_predict)) print("Root Mean Square Error:") print(rmse)Root Mean Square Error: 2.309997102577151Корень среднеквадратичной погрешности хорошо оценивает точность прогнозов модели. Как вы видите, конечный результат демонстрирует хорошую эффективность модели в прогнозировании стоимости поездок на такси по признакам из набора данных, обычно с точностью 2,00 доллара США.
Чтобы вычислить среднюю абсолютную погрешность в процентах, выполните следующий код. Эта метрика выражает точность в процентах величины ошибки. Для этого она вычисляет абсолютное отклонение для каждой пары прогнозируемого и фактического значения, а затем суммирует все отклонения. Затем эта сумма выражается в процентах от общей суммы фактических значений.
# Calculate mean-absolute-percent error and model accuracy sum_actuals = sum_errors = 0 for actual_val, predict_val in zip(y_actual, y_predict): abs_error = actual_val - predict_val if abs_error < 0: abs_error = abs_error * -1 sum_errors = sum_errors + abs_error sum_actuals = sum_actuals + actual_val mean_abs_percent_error = sum_errors / sum_actuals print("Model MAPE:") print(mean_abs_percent_error) print() print("Model Accuracy:") print(1 - mean_abs_percent_error)Model MAPE: 0.03655071038487368 Model Accuracy: 0.9634492896151263Обе метрики точности прогнозирования демонстрируют, что модель достаточно хороша в прогнозировании стоимости поездок на такси на основе признаков из набора данных.
После подгонки модели линейной регрессии вам осталось лишь определить, насколько хорошо модель соответствует реальным данным. Для этого сопоставьте графики фактических значений стоимости поездок и прогнозируемых данных. Кроме того, вычислите величину достоверности аппроксимации, чтобы оценить отклонение наших данных от линейной регрессии.
import matplotlib.pyplot as plt import numpy as np from sklearn.metrics import mean_squared_error, r2_score # Calculate the R2 score by using the predicted and actual fare prices y_test_actual = y_test["fareAmount"] r2 = r2_score(y_test_actual, y_predict) # Plot the actual versus predicted fare amount values plt.style.use('ggplot') plt.figure(figsize=(10, 7)) plt.scatter(y_test_actual,y_predict) plt.plot([np.min(y_test_actual), np.max(y_test_actual)], [np.min(y_test_actual), np.max(y_test_actual)], color='lightblue') plt.xlabel("Actual Fare Amount") plt.ylabel("Predicted Fare Amount") plt.title("Actual vs Predicted Fare Amount R^2={}".format(r2)) plt.show()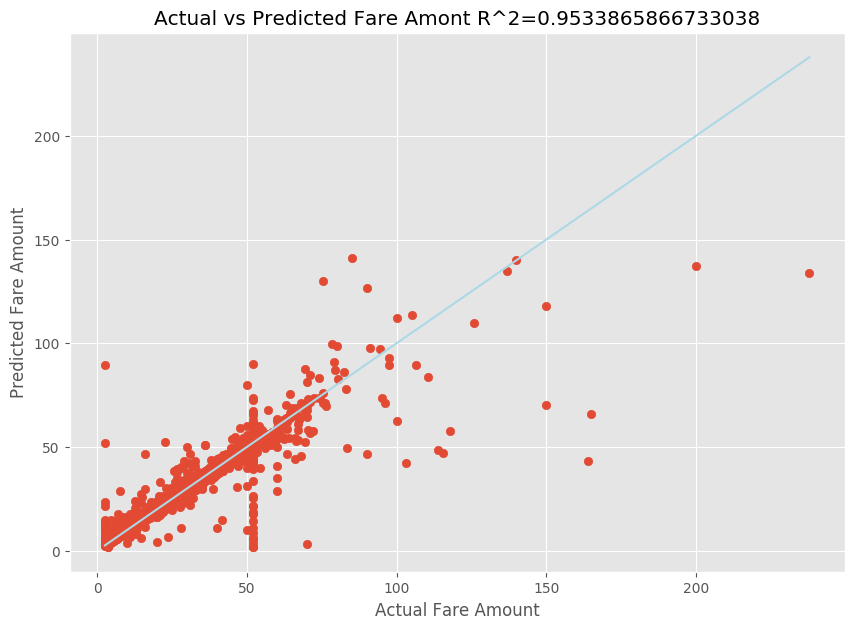
В результатах показано, что величина достоверности аппроксимации составляет 95 % наблюдаемой дисперсии. Также это подтверждается сравнением графиков реальных и наблюдаемых значений. Чем большую часть дисперсии учитывает модель регрессии, тем ближе будут точки данных к графику полученной регрессии.
Регистрация модели в Машинном обучении Azure
Выполнив проверку лучшей модели, вы можете зарегистрировать ее в Машинном обучении Azure. После этого можно скачать или развернуть зарегистрированную модель, а также получить все зарегистрированные в ней файлы.
description = 'My automated ML model'
model_path='outputs/model.pkl'
model = best_run.register_model(model_name = 'NYCYellowTaxiModel', model_path = model_path, description = description)
print(model.name, model.version)
NYCYellowTaxiModel 1
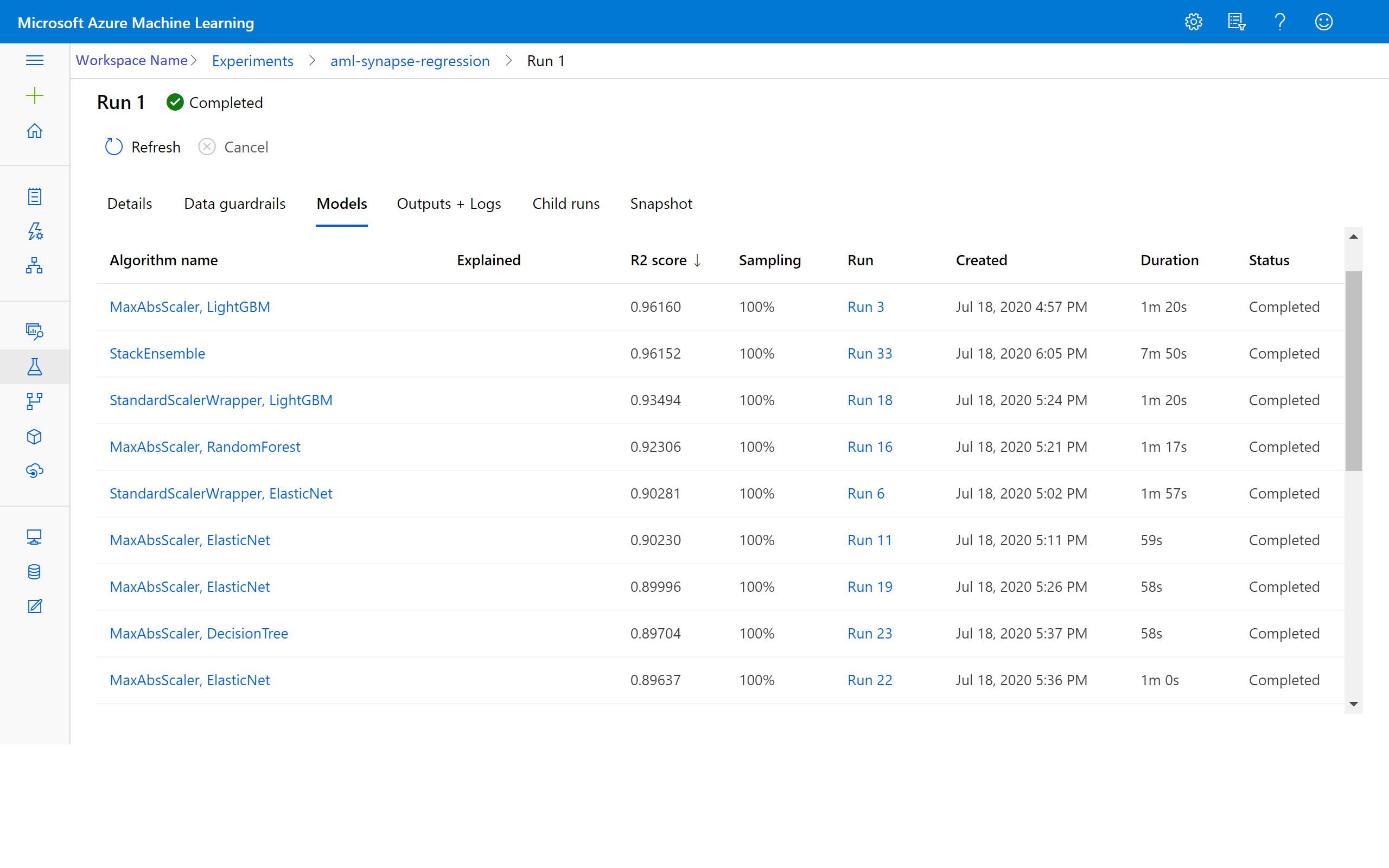
Просмотр результатов в Машинном обучении Azure
Вы можете получить результаты итераций, перейдя к нужному эксперименту в рабочей области Машинного обучения Azure. Здесь можно получить дополнительные сведения о состоянии запуска, проверенных моделях и других метриках модели.