Соединитель выделенного пула SQL в Azure Synapse для Apache Spark
Введение
Соединитель выделенного пула SQL в Azure Synapse для Apache Spark в Azure Synapse Analytics эффективно передает большие наборы данных между средой выполнения Apache Spark и выделенным пулом SQL. Соединитель поставляется в виде библиотеки по умолчанию с рабочей областью Azure Synapse. Соединитель реализован на языке Scala. Соединитель поддерживает Scala и Python. Чтобы использовать соединитель с другими вариантами языка записных книжек, используйте магическую команду Spark %%spark.
Соединитель предоставляет на высоком уровне такие возможности:
- Чтение из выделенного пула SQL Azure Synapse:
- Чтение больших наборов данных из выделенных таблиц пула SQL Synapse (внутренних и внешних) и представлений.
- Комплексная поддержка отправки предикатов, где фильтры в кадре данных сопоставляются с соответствующим отправленным предикатом SQL.
- Поддержка очистки столбцов.
- Поддержка отправки запроса.
- Запись в выделенный пул SQL Azure Synapse:
- Прием данных большого объема во внутренние и внешние табличные типы.
- Поддерживает следующие параметры режима сохранения кадра данных:
AppendErrorIfExistsIgnoreOverwrite
- Функция записи в тип внешней таблицы поддерживает форматы Parquet и текстовые файлы с разделителями (пример — CSV).
- Для записи данных во внутренние таблицы соединитель теперь использует оператор COPY вместо подхода CETAS/CTAS.
- Улучшения для оптимизации производительности сквозной записи.
- Представляет дополнительный обработчик обратного вызова (аргумент функции Scala), который клиенты могут использовать для получения метрик после записи
- Ниже приведены несколько примеров: количество записей, длительность выполнения определенного действия и причина сбоя.
Подход к оркестрации
Чтение
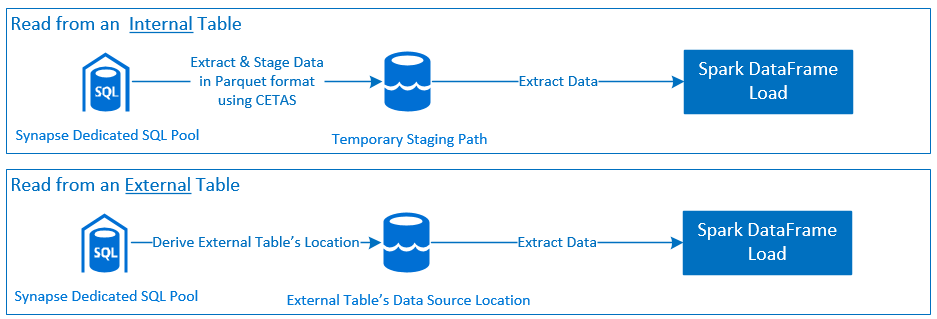
Запись
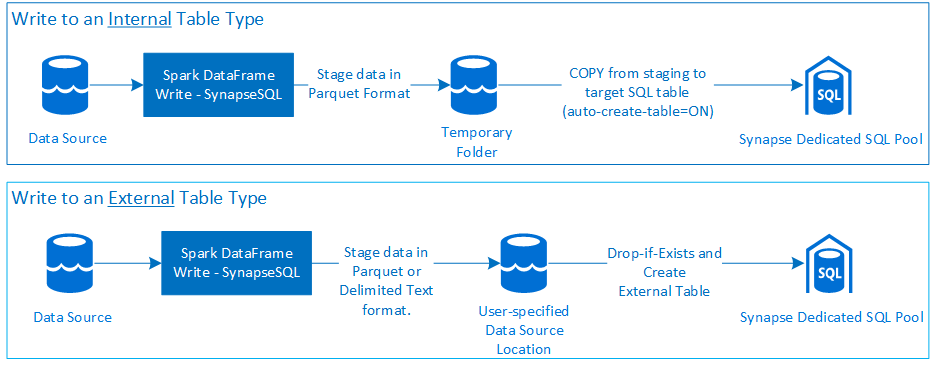
Предварительные требования
Предварительные требования, такие как настройка необходимых ресурсов Azure и действия по их настройке, рассматриваются в этом разделе.
Ресурсы Azure
Проверьте и настройте следующие зависимые ресурсы Azure:
- Azure Data Lake Storage — используется в качестве основной учетной записи хранения для рабочей области Azure Synapse.
- Рабочая область Azure Synapse — создание записных книжек, сборка и развертывание входящих и исходящих рабочих процессов на основе кадров данных.
- Выделенный пул SQL (ранее SQL DW) — для хранения корпоративных данных.
- Бессерверный пул Spark Azure Synapse — среда выполнения Spark, где задания выполняются в виде приложений Spark.
Подготовка базы данных
Подключитесь к базе данных выделенного пула SQL в Synapse и выполните приведенные ниже инструкции по настройке:
Создайте пользователя базы данных, сопоставленного с удостоверением пользователя Microsoft Entra, используемого для входа в рабочую область Azure Synapse.
CREATE USER [username@domain.com] FROM EXTERNAL PROVIDER;Создайте схему, в которой будут определены таблицы, чтобы соединитель мог успешно выполнять запись и чтение в соответствующих таблицах.
CREATE SCHEMA [<schema_name>];
Проверка подлинности
Проверка подлинности на основе идентификатора Microsoft Entra
Проверка подлинности на основе идентификатора Microsoft Entra — это интегрированный подход к проверке подлинности. Пользователь должен успешно войти в рабочую область Azure Synapse Analytics.
Обычная проверка подлинности
Для обычной проверки подлинности пользователь должен настроить параметры username и password. Дополнительные сведения о параметрах конфигурации см. в разделе Параметры конфигурации для чтения и записи в таблицы в выделенном пуле SQL в Azure Synapse.
Авторизация
Azure Data Lake Storage 2-го поколения
Предоставить разрешения на доступ к учетной записи службы хранилища Azure Data Lake Storage 2-го поколения можно двумя способами:
- Роль в системе управления доступом на основе ролей — роль "Участник данных BLOB-объектов хранилища"
- При назначении роли
Storage Blob Data Contributor Roleпользователь получает разрешения на чтение, запись и удаление для контейнеров Azure Storage Blob. - RBAC обеспечивает грубый контроль на уровне контейнера.
- При назначении роли
- Списки управления доступом (ACL)
- Метод ACL позволяет точно контролировать доступ к определенным путям и файлам в конкретной папке.
- Проверки ACL не применяются, если пользователю уже предоставлены разрешения с применением RBAC.
- Существует два широких типа разрешений ACL:
- Разрешения на доступ (применяются на определенном уровне или объекте).
- Разрешения по умолчанию (автоматически применяются для всех дочерних объектов во время их создания).
- К типу разрешений относятся следующие:
Executeпозволяет просматривать иерархии папок и перемещаться по ним.Readобеспечивает возможность чтения.Writeобеспечивает возможность записи.
- Списки ACL важно настроить таким образом, чтобы соединитель мог успешно выполнять запись и чтение в местах хранения.
Примечание.
Если вы хотите запускать записные книжки с помощью конвейеров рабочей области Synapse, необходимо также предоставить указанные выше разрешения на доступ к управляемому удостоверению рабочей области Synapse по умолчанию. Имя управляемого удостоверения рабочей области по умолчанию совпадает с именем рабочей области.
Чтобы использовать рабочую область Synapse с защищенными учетными записями хранения, необходимо настроить управляемую частную конечную точку из записной книжки. Управляемая частная конечная точка должна быть утверждена в разделе
Private endpoint connectionsучетной записи хранения ADLS 2-го поколения на панелиNetworking.
Выделенный пул SQL в Azure Synapse
Чтобы обеспечить успешное взаимодействие с выделенным пулом SQL в Azure Synapse, необходимо выполнить следующую авторизацию, за исключением случая когда вы являетесь пользователем, так же настроенным как Active Directory Admin на выделенной конечной точке SQL:
Сценарий чтения
Предоставьте пользователю
db_exporterдоступ к системной хранимой процедуреsp_addrolemember.EXEC sp_addrolemember 'db_exporter', [<your_domain_user>@<your_domain_name>.com];
Сценарий записи
- Соединитель использует команду COPY для записи данных из промежуточного расположения в управляемое расположение внутренней таблицы.
Настройте необходимые разрешения, как описано здесь.
Ниже приведен соответствующий фрагмент кода для быстрого доступа:
--Make sure your user has the permissions to CREATE tables in the [dbo] schema GRANT CREATE TABLE TO [<your_domain_user>@<your_domain_name>.com]; GRANT ALTER ON SCHEMA::<target_database_schema_name> TO [<your_domain_user>@<your_domain_name>.com]; --Make sure your user has ADMINISTER DATABASE BULK OPERATIONS permissions GRANT ADMINISTER DATABASE BULK OPERATIONS TO [<your_domain_user>@<your_domain_name>.com]; --Make sure your user has INSERT permissions on the target table GRANT INSERT ON <your_table> TO [<your_domain_user>@<your_domain_name>.com]
- Соединитель использует команду COPY для записи данных из промежуточного расположения в управляемое расположение внутренней таблицы.
Документация по API
Соединитель выделенного пула SQL в Azure Synapse для Apache Spark — документация по API.
Варианты конфигурации
Для успешной начальной загрузки и оркестрации операции чтения или записи соединитель ожидает определенные параметры конфигурации. Определение объекта com.microsoft.spark.sqlanalytics.utils.Constants предоставляет список стандартизированных констант для каждого ключа параметра.
Ниже приведен список параметров конфигурации на основе сценария использования:
- Чтение с помощью проверки подлинности на основе идентификатора Microsoft Entra
- Учетные данные автоматически сопоставляются, и от пользователя не требуется предоставлять определенные параметры конфигурации.
- Для чтения из соответствующей таблицы в выделенном пуле SQL в Azure Synapse требуется аргумент имени таблицы из трех частей на основе метода
synapsesql.
- Чтение с помощью обычной проверки подлинности
- Выделенная конечная точка SQL Azure Synapse
Constants.SERVER: конечная точка выделенного пула SQL в Synapse (полное доменное имя сервера)Constants.USER: имя пользователя SQL.Constants.PASSWORD: пароль пользователя SQL.
- Конечная точка Azure Data Lake служба хранилища (2-го поколения) — промежуточные папки
Constants.DATA_SOURCE: путь хранения, заданный в параметре расположения источника данных, используется для промежуточного хранения данных.
- Выделенная конечная точка SQL Azure Synapse
- Запись с помощью проверки подлинности на основе идентификатора Microsoft Entra
- Выделенная конечная точка SQL Azure Synapse
- По умолчанию соединитель определяет конечную точку выделенного SQL Synapse, используя имя базы данных, заданное в параметре имени таблицы из трех частей на основе метода
synapsesql. - Кроме того, пользователи могут использовать параметр
Constants.SERVERдля указания конечной точки SQL. Убедитесь, что конечная точка размещает соответствующую базу данных с соответствующей схемой.
- По умолчанию соединитель определяет конечную точку выделенного SQL Synapse, используя имя базы данных, заданное в параметре имени таблицы из трех частей на основе метода
- Конечная точка Azure Data Lake служба хранилища (2-го поколения) — промежуточные папки
- Для внутреннего типа таблицы:
- Настройте параметр
Constants.TEMP_FOLDERилиConstants.DATA_SOURCE. - Если пользователь решил предоставить параметр
Constants.DATA_SOURCE, промежуточная папка выводится с помощью значенияlocationв источнике данных. - Если указаны оба параметра, используется значение параметра
Constants.TEMP_FOLDER. - При отсутствии параметра промежуточной папки соединитель производит его на основе конфигурации среды выполнения
spark.sqlanalyticsconnector.stagingdir.prefix.
- Настройте параметр
- Для внешнего типа таблицы:
Constants.DATA_SOURCE- обязательный параметр конфигурации.- Соединитель использует путь к хранилищу, заданный в параметре расположения источника данных, в сочетании с аргументом
locationметодаsynapsesqlи является абсолютным путем для сохранения внешних данных таблицы. - Если аргумент
locationметодаsynapsesqlне указан, соединитель выводит значение расположения как<base_path>/dbName/schemaName/tableName.
- Для внутреннего типа таблицы:
- Выделенная конечная точка SQL Azure Synapse
- Запись с использованием обычной проверки подлинности
- Выделенная конечная точка SQL Azure Synapse
Constants.SERVER: конечная точка выделенного пула SQL в Synapse (полное доменное имя сервера).Constants.USER: имя пользователя SQL.Constants.PASSWORD: пароль пользователя SQL.Constants.STAGING_STORAGE_ACCOUNT_KEY, связанный с учетной записью хранения, в которой размещаютсяConstants.TEMP_FOLDERS(только типы внутренних таблиц) илиConstants.DATA_SOURCE.
- Конечная точка Azure Data Lake служба хранилища (2-го поколения) — промежуточные папки
- Учетные данные SQL для обычной проверки подлинности не применяются к конечным точкам хранилища.
- Поэтому назначьте соответствующие разрешения на доступ к хранилищу, как описано в разделе Azure Data Lake Storage 2-го поколения.
- Выделенная конечная точка SQL Azure Synapse
Шаблоны кода
В этом разделе представлены справочные шаблоны кода и описано, как использовать и вызывать соединитель выделенного пула SQL в Azure Synapse для Apache Spark.
Примечание.
Использование соединителя в Python
- Соединитель поддерживается только в Python для Spark 3. Для Spark 2.4 (неподдерживаемый) можно использовать API соединителя Scala для взаимодействия с содержимым из кадра данных в PySpark с помощью DataFrame.createOrReplaceTempView или DataFrame.createOrReplaceGlobalTempView. См. раздел Использование материализованных данных между ячейками.
- Дескриптор обратного вызова недоступен в Python.
Чтение данных из выделенного пула SQL в Azure Synapse
Запрос на чтение — сигнатура метода synapsesql
Чтение из таблицы с помощью проверки подлинности на основе идентификатора Microsoft Entra
//Use case is to read data from an internal table in Synapse Dedicated SQL Pool DB
//Azure Active Directory based authentication approach is preferred here.
import org.apache.spark.sql.DataFrame
import com.microsoft.spark.sqlanalytics.utils.Constants
import org.apache.spark.sql.SqlAnalyticsConnector._
//Read from existing internal table
val dfToReadFromTable:DataFrame = spark.read.
//If `Constants.SERVER` is not provided, the `<database_name>` from the three-part table name argument
//to `synapsesql` method is used to infer the Synapse Dedicated SQL End Point.
option(Constants.SERVER, "<sql-server-name>.sql.azuresynapse.net").
//Defaults to storage path defined in the runtime configurations
option(Constants.TEMP_FOLDER, "abfss://<container_name>@<storage_account_name>.dfs.core.windows.net/<some_base_path_for_temporary_staging_folders>").
//Three-part table name from where data will be read.
synapsesql("<database_name>.<schema_name>.<table_name>").
//Column-pruning i.e., query select column values.
select("<some_column_1>", "<some_column_5>", "<some_column_n>").
//Push-down filter criteria that gets translated to SQL Push-down Predicates.
filter(col("Title").startsWith("E")).
//Fetch a sample of 10 records
limit(10)
//Show contents of the dataframe
dfToReadFromTable.show()
Чтение из запроса с помощью проверки подлинности на основе идентификатора Microsoft Entra
Примечание.
Ограничения при чтении из запроса:
- Имя таблицы и запрос нельзя указать одновременно.
- Разрешены только запросы выбора. Не допускаются DDL и DML SQLs.
- Параметры выбора и фильтрации в кадре данных не отправляются в выделенный пул SQL при указании запроса.
- Чтение из запроса доступно только в Spark 3.1 и 3.2.
//Use case is to read data from an internal table in Synapse Dedicated SQL Pool DB
//Azure Active Directory based authentication approach is preferred here.
import org.apache.spark.sql.DataFrame
import com.microsoft.spark.sqlanalytics.utils.Constants
import org.apache.spark.sql.SqlAnalyticsConnector._
// Read from a query
// Query can be provided either as an argument to synapsesql or as a Constant - Constants.QUERY
val dfToReadFromQueryAsOption:DataFrame = spark.read.
// Name of the SQL Dedicated Pool or database where to run the query
// Database can be specified as a Spark Config - spark.sqlanalyticsconnector.dw.database or as a Constant - Constants.DATABASE
option(Constants.DATABASE, "<database_name>").
//If `Constants.SERVER` is not provided, the `<database_name>` from the three-part table name argument
//to `synapsesql` method is used to infer the Synapse Dedicated SQL End Point.
option(Constants.SERVER, "<sql-server-name>.sql.azuresynapse.net").
//Defaults to storage path defined in the runtime configurations
option(Constants.TEMP_FOLDER, "abfss://<container_name>@<storage_account_name>.dfs.core.windows.net/<some_base_path_for_temporary_staging_folders>")
//query from which data will be read
.option(Constants.QUERY, "select <column_name>, count(*) as cnt from <schema_name>.<table_name> group by <column_name>")
synapsesql()
val dfToReadFromQueryAsArgument:DataFrame = spark.read.
// Name of the SQL Dedicated Pool or database where to run the query
// Database can be specified as a Spark Config - spark.sqlanalyticsconnector.dw.database or as a Constant - Constants.DATABASE
option(Constants.DATABASE, "<database_name>")
//If `Constants.SERVER` is not provided, the `<database_name>` from the three-part table name argument
//to `synapsesql` method is used to infer the Synapse Dedicated SQL End Point.
option(Constants.SERVER, "<sql-server-name>.sql.azuresynapse.net").
//Defaults to storage path defined in the runtime configurations
option(Constants.TEMP_FOLDER, "abfss://<container_name>@<storage_account_name>.dfs.core.windows.net/<some_base_path_for_temporary_staging_folders>")
//query from which data will be read
.synapsesql("select <column_name>, count(*) as counts from <schema_name>.<table_name> group by <column_name>")
//Show contents of the dataframe
dfToReadFromQueryAsOption.show()
dfToReadFromQueryAsArgument.show()
Чтение из таблицы с помощью базовой проверки подлинности
//Use case is to read data from an internal table in Synapse Dedicated SQL Pool DB
//Azure Active Directory based authentication approach is preferred here.
import org.apache.spark.sql.DataFrame
import com.microsoft.spark.sqlanalytics.utils.Constants
import org.apache.spark.sql.SqlAnalyticsConnector._
//Read from existing internal table
val dfToReadFromTable:DataFrame = spark.read.
//If `Constants.SERVER` is not provided, the `<database_name>` from the three-part table name argument
//to `synapsesql` method is used to infer the Synapse Dedicated SQL End Point.
option(Constants.SERVER, "<sql-server-name>.sql.azuresynapse.net").
//Set database user name
option(Constants.USER, "<user_name>").
//Set user's password to the database
option(Constants.PASSWORD, "<user_password>").
//Set name of the data source definition that is defined with database scoped credentials.
//Data extracted from the table will be staged to the storage path defined on the data source's location setting.
option(Constants.DATA_SOURCE, "<data_source_name>").
//Three-part table name from where data will be read.
synapsesql("<database_name>.<schema_name>.<table_name>").
//Column-pruning i.e., query select column values.
select("<some_column_1>", "<some_column_5>", "<some_column_n>").
//Push-down filter criteria that gets translated to SQL Push-down Predicates.
filter(col("Title").startsWith("E")).
//Fetch a sample of 10 records
limit(10)
//Show contents of the dataframe
dfToReadFromTable.show()
Чтение из запроса с помощью базовой проверки подлинности
//Use case is to read data from an internal table in Synapse Dedicated SQL Pool DB
//Azure Active Directory based authentication approach is preferred here.
import org.apache.spark.sql.DataFrame
import com.microsoft.spark.sqlanalytics.utils.Constants
import org.apache.spark.sql.SqlAnalyticsConnector._
// Name of the SQL Dedicated Pool or database where to run the query
// Database can be specified as a Spark Config or as a Constant - Constants.DATABASE
spark.conf.set("spark.sqlanalyticsconnector.dw.database", "<database_name>")
// Read from a query
// Query can be provided either as an argument to synapsesql or as a Constant - Constants.QUERY
val dfToReadFromQueryAsOption:DataFrame = spark.read.
//Name of the SQL Dedicated Pool or database where to run the query
//Database can be specified as a Spark Config - spark.sqlanalyticsconnector.dw.database or as a Constant - Constants.DATABASE
option(Constants.DATABASE, "<database_name>").
//If `Constants.SERVER` is not provided, the `<database_name>` from the three-part table name argument
//to `synapsesql` method is used to infer the Synapse Dedicated SQL End Point.
option(Constants.SERVER, "<sql-server-name>.sql.azuresynapse.net").
//Set database user name
option(Constants.USER, "<user_name>").
//Set user's password to the database
option(Constants.PASSWORD, "<user_password>").
//Set name of the data source definition that is defined with database scoped credentials.
//Data extracted from the SQL query will be staged to the storage path defined on the data source's location setting.
option(Constants.DATA_SOURCE, "<data_source_name>").
//Query where data will be read.
option(Constants.QUERY, "select <column_name>, count(*) as counts from <schema_name>.<table_name> group by <column_name>" ).
synapsesql()
val dfToReadFromQueryAsArgument:DataFrame = spark.read.
//Name of the SQL Dedicated Pool or database where to run the query
//Database can be specified as a Spark Config - spark.sqlanalyticsconnector.dw.database or as a Constant - Constants.DATABASE
option(Constants.DATABASE, "<database_name>").
//If `Constants.SERVER` is not provided, the `<database_name>` from the three-part table name argument
//to `synapsesql` method is used to infer the Synapse Dedicated SQL End Point.
option(Constants.SERVER, "<sql-server-name>.sql.azuresynapse.net").
//Set database user name
option(Constants.USER, "<user_name>").
//Set user's password to the database
option(Constants.PASSWORD, "<user_password>").
//Set name of the data source definition that is defined with database scoped credentials.
//Data extracted from the SQL query will be staged to the storage path defined on the data source's location setting.
option(Constants.DATA_SOURCE, "<data_source_name>").
//Query where data will be read.
synapsesql("select <column_name>, count(*) as counts from <schema_name>.<table_name> group by <column_name>")
//Show contents of the dataframe
dfToReadFromQueryAsOption.show()
dfToReadFromQueryAsArgument.show()
Запись данных в выделенный пул SQL в Azure Synapse
Запрос на запись — сигнатура метода synapsesql
Сигнатура метода для версии Подключение or, созданной для Spark 2.4.8, имеет один меньше аргумента, чем примененная к версии Spark 3.1.2. Ниже приведены две сигнатуры метода:
- Версия для пула Spark 2.4.8
synapsesql(tableName:String,
tableType:String = Constants.INTERNAL,
location:Option[String] = None):Unit
- Версия для пула Spark 3.1.2
synapsesql(tableName:String,
tableType:String = Constants.INTERNAL,
location:Option[String] = None,
callBackHandle=Option[(Map[String, Any], Option[Throwable])=>Unit]):Unit
Запись с помощью проверки подлинности на основе идентификатора Microsoft Entra
В следующем комплексном шаблоне кода описывается использование соединителя для сценариев записи:
//Add required imports
import org.apache.spark.sql.DataFrame
import org.apache.spark.sql.SaveMode
import com.microsoft.spark.sqlanalytics.utils.Constants
import org.apache.spark.sql.SqlAnalyticsConnector._
//Define read options for example, if reading from CSV source, configure header and delimiter options.
val pathToInputSource="abfss://<storage_container_name>@<storage_account_name>.dfs.core.windows.net/<some_folder>/<some_dataset>.csv"
//Define read configuration for the input CSV
val dfReadOptions:Map[String, String] = Map("header" -> "true", "delimiter" -> ",")
//Initialize DataFrame that reads CSV data from a given source
val readDF:DataFrame=spark.
read.
options(dfReadOptions).
csv(pathToInputSource).
limit(1000) //Reads first 1000 rows from the source CSV input.
//Setup and trigger the read DataFrame for write to Synapse Dedicated SQL Pool.
//Fully qualified SQL Server DNS name can be obtained using one of the following methods:
// 1. Synapse Workspace - Manage Pane - SQL Pools - <Properties view of the corresponding Dedicated SQL Pool>
// 2. From Azure Portal, follow the bread-crumbs for <Portal_Home> -> <Resource_Group> -> <Dedicated SQL Pool> and then go to Connection Strings/JDBC tab.
//If `Constants.SERVER` is not provided, the value will be inferred by using the `database_name` in the three-part table name argument to the `synapsesql` method.
//Like-wise, if `Constants.TEMP_FOLDER` is not provided, the connector will use the runtime staging directory config (see section on Configuration Options for details).
val writeOptionsWithAADAuth:Map[String, String] = Map(Constants.SERVER -> "<dedicated-pool-sql-server-name>.sql.azuresynapse.net",
Constants.TEMP_FOLDER -> "abfss://<storage_container_name>@<storage_account_name>.dfs.core.windows.net/<some_temp_folder>")
//Setup optional callback/feedback function that can receive post write metrics of the job performed.
var errorDuringWrite:Option[Throwable] = None
val callBackFunctionToReceivePostWriteMetrics: (Map[String, Any], Option[Throwable]) => Unit =
(feedback: Map[String, Any], errorState: Option[Throwable]) => {
println(s"Feedback map - ${feedback.map{case(key, value) => s"$key -> $value"}.mkString("{",",\n","}")}")
errorDuringWrite = errorState
}
//Configure and submit the request to write to Synapse Dedicated SQL Pool (note - default SaveMode is set to ErrorIfExists)
//Sample below is using AAD-based authentication approach; See further examples to leverage SQL Basic auth.
readDF.
write.
//Configure required configurations.
options(writeOptionsWithAADAuth).
//Choose a save mode that is apt for your use case.
mode(SaveMode.Overwrite).
synapsesql(tableName = "<database_name>.<schema_name>.<table_name>",
//For external table type value is Constants.EXTERNAL
tableType = Constants.INTERNAL,
//Optional parameter that is used to specify external table's base folder; defaults to `database_name/schema_name/table_name`
location = None,
//Optional parameter to receive a callback.
callBackHandle = Some(callBackFunctionToReceivePostWriteMetrics))
//If write request has failed, raise an error and fail the Cell's execution.
if(errorDuringWrite.isDefined) throw errorDuringWrite.get
Запись с использованием обычной проверки подлинности
Следующий фрагмент кода заменяет определение записи, описанное в разделе "Запись с помощью проверки подлинности на основе идентификатора Microsoft Entra", для отправки запроса на запись с помощью базового подхода проверки подлинности SQL:
//Define write options to use SQL basic authentication
val writeOptionsWithBasicAuth:Map[String, String] = Map(Constants.SERVER -> "<dedicated-pool-sql-server-name>.sql.azuresynapse.net",
//Set database user name
Constants.USER -> "<user_name>",
//Set database user's password
Constants.PASSWORD -> "<user_password>",
//Required only when writing to an external table. For write to internal table, this can be used instead of TEMP_FOLDER option.
Constants.DATA_SOURCE -> "<Name of the datasource as defined in the target database>"
//To be used only when writing to internal tables. Storage path will be used for data staging.
Constants.TEMP_FOLDER -> "abfss://<storage_container_name>@<storage_account_name>.dfs.core.windows.net/<some_temp_folder>")
//Configure and submit the request to write to Synapse Dedicated SQL Pool.
readDF.
write.
options(writeOptionsWithBasicAuth).
//Choose a save mode that is apt for your use case.
mode(SaveMode.Overwrite).
synapsesql(tableName = "<database_name>.<schema_name>.<table_name>",
//For external table type value is Constants.EXTERNAL
tableType = Constants.INTERNAL,
//Not required for writing to an internal table
location = None,
//Optional parameter.
callBackHandle = Some(callBackFunctionToReceivePostWriteMetrics))
При обычной проверке подлинности, чтобы считывать данные из исходного пути к хранилищу, требуются другие параметры конфигурации. В следующем фрагменте кода приведен пример для чтения из источника данных Azure Data Lake Storage 2-го поколения с помощью учетных данных субъекта-службы:
//Specify options that Spark runtime must support when interfacing and consuming source data
val storageAccountName="<storageAccountName>"
val storageContainerName="<storageContainerName>"
val subscriptionId="<AzureSubscriptionID>"
val spnClientId="<ServicePrincipalClientID>"
val spnSecretKeyUsedAsAuthCred="<spn_secret_key_value>"
val dfReadOptions:Map[String, String]=Map("header"->"true",
"delimiter"->",",
"fs.defaultFS" -> s"abfss://$storageContainerName@$storageAccountName.dfs.core.windows.net",
s"fs.azure.account.auth.type.$storageAccountName.dfs.core.windows.net" -> "OAuth",
s"fs.azure.account.oauth.provider.type.$storageAccountName.dfs.core.windows.net" ->
"org.apache.hadoop.fs.azurebfs.oauth2.ClientCredsTokenProvider",
"fs.azure.account.oauth2.client.id" -> s"$spnClientId",
"fs.azure.account.oauth2.client.secret" -> s"$spnSecretKeyUsedAsAuthCred",
"fs.azure.account.oauth2.client.endpoint" -> s"https://login.microsoftonline.com/$subscriptionId/oauth2/token",
"fs.AbstractFileSystem.abfss.impl" -> "org.apache.hadoop.fs.azurebfs.Abfs",
"fs.abfss.impl" -> "org.apache.hadoop.fs.azurebfs.SecureAzureBlobFileSystem")
//Initialize the Storage Path string, where source data is maintained/kept.
val pathToInputSource=s"abfss://$storageContainerName@$storageAccountName.dfs.core.windows.net/<base_path_for_source_data>/<specific_file (or) collection_of_files>"
//Define data frame to interface with the data source
val df:DataFrame = spark.
read.
options(dfReadOptions).
csv(pathToInputSource).
limit(100)
Поддерживаемые режимы сохранения кадра данных
При записи исходных данных в целевую таблицу в выделенном пуле SQL в Azure Synapse поддерживаются следующие режимы сохранения:
- ErrorIfExists (режим сохранения по умолчанию)
- Если целевая таблица существует, запись прерывается с исключением, возвращаемым вызываемому объекту. В противном случае создается новая таблица с данными из промежуточных папок.
- Игнорировать
- Если целевая таблица существует, операция записи игнорирует запрос на запись и не возвращает ошибку. В противном случае создается новая таблица с данными из промежуточных папок.
- Перезаписать
- Если целевая таблица существует, существующие данные в месте назначения заменяются данными из промежуточных папок. В противном случае создается новая таблица с данными из промежуточных папок.
- Добавить
- Если целевая таблица существует, к ней добавляются новые данные. В противном случае создается новая таблица с данными из промежуточных папок.
Дескриптор обратного вызова запроса на запись
В новом API пути записи представлена экспериментальная функция, предоставляющая клиенту соответствие между ключами и значениями для метрик после записи. Ключи для метрик определяются в новом определении объекта Constants.FeedbackConstants. Метрики можно получить в виде строки JSON, передав дескриптор обратного вызова (Scala Function). Следующий фрагмент кода является сигнатурой функции:
//Function signature is expected to have two arguments - a `scala.collection.immutable.Map[String, Any]` and an Option[Throwable]
//Post-write if there's a reference of this handle passed to the `synapsesql` signature, it will be invoked by the closing process.
//These arguments will have valid objects in either Success or Failure case. In case of Failure the second argument will be a `Some(Throwable)`.
(Map[String, Any], Option[Throwable]) => Unit
Ниже приведены некоторые важные метрики (в "верблюжьем" стиле):
WriteFailureCauseDataStagingSparkJobDurationInMillisecondsNumberOfRecordsStagedForSQLCommitSQLStatementExecutionDurationInMillisecondsrows_processed
Ниже приведен пример строки JSON с метриками после записи:
{
SparkApplicationId -> <spark_yarn_application_id>,
SQLStatementExecutionDurationInMilliseconds -> 10113,
WriteRequestReceivedAtEPOCH -> 1647523790633,
WriteRequestProcessedAtEPOCH -> 1647523808379,
StagingDataFileSystemCheckDurationInMilliseconds -> 60,
command -> "COPY INTO [schema_name].[table_name] ...",
NumberOfRecordsStagedForSQLCommit -> 100,
DataStagingSparkJobEndedAtEPOCH -> 1647523797245,
SchemaInferenceAssertionCompletedAtEPOCH -> 1647523790920,
DataStagingSparkJobDurationInMilliseconds -> 5252,
rows_processed -> 100,
SaveModeApplied -> TRUNCATE_COPY,
DurationInMillisecondsToValidateFileFormat -> 75,
status -> Completed,
SparkApplicationName -> <spark_application_name>,
ThreePartFullyQualifiedTargetTableName -> <database_name>.<schema_name>.<table_name>,
request_id -> <query_id_as_retrieved_from_synapse_dedicated_sql_db_query_reference>,
StagingFolderConfigurationCheckDurationInMilliseconds -> 2,
JDBCConfigurationsSetupAtEPOCH -> 193,
StagingFolderConfigurationCheckCompletedAtEPOCH -> 1647523791012,
FileFormatValidationsCompletedAtEPOCHTime -> 1647523790995,
SchemaInferenceCheckDurationInMilliseconds -> 91,
SaveModeRequested -> Overwrite,
DataStagingSparkJobStartedAtEPOCH -> 1647523791993,
DurationInMillisecondsTakenToGenerateWriteSQLStatements -> 4
}
Дополнительные примеры кода
Использование материализованных данных между ячейками
createOrReplaceTempView DataFrame Spark можно использовать для доступа к данным, извлекаемым в другой ячейке, регистрируя временное представление.
- Ячейка, в которой извлекаются данные (например, с использованием языковых параметров записной книжки
Scala)
//Necessary imports
import org.apache.spark.sql.DataFrame
import org.apache.spark.sql.SaveMode
import com.microsoft.spark.sqlanalytics.utils.Constants
import org.apache.spark.sql.SqlAnalyticsConnector._
//Configure options and read from Synapse Dedicated SQL Pool.
val readDF = spark.read.
//Set Synapse Dedicated SQL End Point name.
option(Constants.SERVER, "<synapse-dedicated-sql-end-point>.sql.azuresynapse.net").
//Set database user name.
option(Constants.USER, "<user_name>").
//Set database user's password.
option(Constants.PASSWORD, "<user_password>").
//Set name of the data source definition that is defined with database scoped credentials.
option(Constants.DATA_SOURCE,"<data_source_name>").
//Set the three-part table name from which the read must be performed.
synapsesql("<database_name>.<schema_name>.<table_name>").
//Optional - specify number of records the DataFrame would read.
limit(10)
//Register the temporary view (scope - current active Spark Session)
readDF.createOrReplaceTempView("<temporary_view_name>")
- Теперь измените языковые параметры записной книжки на
PySpark (Python)и извлеките данные из зарегистрированного представления<temporary_view_name>
spark.sql("select * from <temporary_view_name>").show()
Обработка ответов
Вызов synapsesql имеет два возможных конечных состояния: "Успешно" или "Сбой". В этом разделе рассматривается обработка ответа на запрос для каждого сценария.
Ответ на запрос чтения
По завершении фрагмент ответа чтения отображается в выходных данных ячейки. Сбой в текущей ячейке также отменяет последующие выполнения ячеек. Подробные сведения об ошибке доступны в журналах приложений Spark.
Ответ на запрос записи
По умолчанию ответ на запись выводится в выходные данные ячейки. При сбое текущая ячейка помечается как сбой, а последующие выполнения ячеек прерываются. Другой подход — передача параметра дескриптора обратного вызова методу synapsesql. Дескриптор обратного вызова предоставляет программный доступ к ответу на запись.
Дополнительные рекомендации
- При чтении из таблиц выделенного пула SQL Azure Synapse:
- Рассмотрите возможность применения необходимых фильтров к DataFrame, чтобы воспользоваться преимуществами функции обрезки столбцов соединителя.
- Сценарий чтения не поддерживает предложение
TOP(n-rows)при обрамлении операторов запросаSELECT. Для ограничения данных используйте предложение dataFrame limit(.).- См. пример в разделе Использование материализованных данных между ячейками.
- При записи в таблицы выделенного пула SQL Azure Synapse:
- Для внутренних типов таблиц:
- Таблицы создаются с распределением данных ROUND_ROBIN.
- Типы столбцов выводятся из DataFrame, который будет считывать данные из источника. Строковые столбцы сопоставляются с
NVARCHAR(4000).
- Для внешних типов таблиц:
- Начальный параллелизм DataFrame управляет организацией данных для внешней таблицы.
- Типы столбцов выводятся из DataFrame, который будет считывать данные из источника.
- Лучшего распределения данных между исполнителями можно добиться, настроив
spark.sql.files.maxPartitionBytesпараметр DataFramerepartition. - При записи больших наборов данных важно учитывать влияние параметра уровня производительности DWU, ограничивающего размер транзакции.
- Для внутренних типов таблиц:
- Отслеживайте тенденции использования Azure Data Lake Storage 2-го поколения, чтобы определить поведение регулирования, которое может повлиять на производительность чтения и записи.