Процесс индексирования в Windows Search
В этом разделе описываются три этапа процесса индексирования и основные компоненты, участвующие в каждом из них, объясняется время выполнения индексирования и приводятся некоторые заметки для сторонних разработчиков, которым требуется индексировать хранилища данных или форматы файлов.
Эта тема организована следующим образом:
- Обзор
- Этап 1. Очередные URL-адреса для индексирования
- Этап 2. Обход URL-адресов
- Этап 3. Обновление индекса
- Планирование индексирования
- Примечания для тех, кто реализует этот метод
- Связанные темы
Общие сведения
Поиск Windows поддерживает индексирование свойств и содержимого из файлов разных форматов файлов, таких как форматы .doc или JPEG, а также хранилищ данных, таких как файловая система или почтовые ящики Windows Outlook. Существует два типа индексов: индексы значений, которые позволяют фильтровать и сортировать по целому значению свойства, и инвертированные индексы, которые индексируют слова в текстовых свойствах или содержимом. Если у вас есть пользовательский формат файла или хранилище данных, необходимо понять, как windows Search индексирует, чтобы правильно индексировать элементы.
Процесс индексирования выполняется в три этапа, контролируемых компонентом Windows Search, который называется сборщиком. На первом этапе средство сбора данных добавляет URL-адреса в очереди. URL-адреса определяют элементы для индексирования, а очереди — это просто приоритетные списки URL-адресов. На втором этапе сборщик координирует другие компоненты Windows Search и сторонние компоненты для доступа к элементам и сбора данных о них. Наконец, на третьем этапе собранные данные добавляются в индекс.
На следующей схеме показаны основные компоненты и поток данных в процессе индексирования. В сборе данных для индекса участвует ряд компонентов. Некоторые из них являются частью Windows Search, а некоторые — из сторонних приложений. Если у вас есть пользовательское хранилище данных или формат файлов, Windows Search использует обработчик протокола и фильтр для доступа к URL-адресам и создания свойств для индексирования. Компоненты Windows Search отображаются синим цветом, а компоненты сторонних производителей — зеленым цветом.

Этап 1. Очередные URL-адреса для индексирования
На первом этапе индексирования сборщик собирает сведения об обновлениях хранилищ данных, сравнивает эти сведения с известными область обхода, а затем создает очередь URL-адресов для обхода для сбора данных для индекса. Для источников, не основанных на уведомлениях, таких как диски FAT, сборщик периодически инициирует полный обход область обхода, чтобы данные в индексе были актуальными. Для таких источников, как NTFS, существует только один обход контента, а все остальное обрабатывается уведомлениями из журнала изменений USN. Кроме того, не существует обхода Microsoft Outlook. На следующей схеме показано общее представление процесса постановки в очередь для индексирования без обхода контента.

В оставшейся части этого раздела объясняется, как Поиск Windows определяет URL-адреса для обхода, а также определяет некоторые важные термины на этом пути.
Область обхода контента Область обхода — это набор URL-адресов, которые windows Search просматривает для сбора данных об элементах, которые пользователь хочет индексировать для ускорения поиска. Windows Search добавляет некоторые URL-адреса в область обхода контента по умолчанию, например пути к папкам "Документы" и "Изображения" пользователей. Другие URL-адреса могут добавляться сторонними приложениями, пользователями и групповая политика. Наконец, как пользователи, так и групповая политика могут явно исключать URL-адреса. Windows Search принимает все добавленные URL-адреса и удаляет исключенные URL-адреса, чтобы определить область обхода контента. Это рабочий набор URL-адресов, с которых средство сбора данных начинает свою работу.
Собирателей Средство сбора данных — это компонент Windows Search, который собирает сведения об URL-адресах в область обхода и создает очередь URL-адресов для обхода индексатора. Когда элемент в область обхода добавляется, удаляется или обновляется, сборщик получает уведомление от поставщика уведомлений хранилища данных. Существует начальный обход контента, где средство сбора данных начинается с корневого область обхода контента. URL-адрес передается обработчику протокола, а затем в соответствующий IFilter. Фильтр обычно представляет собой перечисление каталогов, которое создает дополнительные URL-адреса. Уведомления являются устойчивым состоянием. Как правило, каждое хранилище данных имеет собственный обработчик протокола, который предоставляет эти уведомления. Например, в локальной файловой системе журнал изменений USN выступает в качестве поставщика уведомлений для всех URL-адресов по протоколу file://. Аналогичным образом Microsoft Outlook выступает в качестве поставщика уведомлений для всех URL-адресов по протоколу mapi://. Когда пользователь получает, перемещает или удаляет электронную почту, Outlook уведомляет сборщика об изменении состояния сообщения электронной почты. На основе этих уведомлений средство сбора данных создает очереди индексирования URL-адресов для обхода контента.
Очереди индексирования Очереди индексирования — это списки URL-адресов, которые определяют элементы, которые необходимо проиндексировать или переиндексировать. Средство сбора данных сравнивает URL-адреса, получаемые от поставщиков уведомлений, с URL-адресами в область обхода контента. Каждый URL-адрес от поставщиков уведомлений, которые попадают в область обхода контента, добавляется в очередь, которую средство сбора данных использует для определения приоритетов, какие URL-адреса следует обрабатывать далее.
Существует три очереди: уведомления с высоким приоритетом, обычные уведомления и периодические обходы контента. Очередь с высоким приоритетом используется для уведомлений, которые должны обрабатываться немедленно. Например, когда пользователь изменяет свойство заголовка элемента в Windows Обозреватель, представление Обозреватель Windows необходимо обновить сразу после изменения. Обычная очередь уведомлений для всех оставшихся уведомлений об изменениях. Очереди уведомлений обрабатываются до очереди обхода контента, так как измененные элементы, скорее всего, представляют интерес для пользователя. Сборщик обращается к данным для URL-адресов в каждой очереди в порядке fifo.
Дополнительные сведения об определении приоритетов и API-интерфейсах обработки событий, представленных в Windows 7, см. в разделе Индексирование приоритетов и событий набора строк в Windows 7. Дополнительные сведения об управлении область обхода контента и уведомлениях см. в разделах Предоставление уведомлений об изменениях и Использование диспетчера области обхода контента.
Этап 2. Обход URL-адресов
На втором этапе индексирования средство сбора выполняет обход очередей, получая доступ к хранилищам данных и извлекая потоки элементов. Сначала средство сбора данных находит соответствующий обработчик протокола для каждого URL-адреса. Затем средство сбора данных передает URL-адрес обработчику протокола. Обработчик протокола обращается к элементу и передает метаданные элемента обратно средству сбора данных. Средство сбора данных использует метаданные для определения правильного фильтра.
На следующей схеме показано общее представление процесса обхода URL-адресов. Этот этап включает в себя значительную координацию и взаимодействие между компонентами.
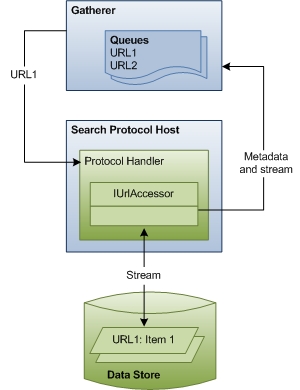
В оставшейся части этого раздела описывается, как Windows Search обращается к элементам для индексирования, и описываются роли каждого из задействованных компонентов.
Собирателей На этапе 2, этапе обхода, сборщик обрабатывает URL-адреса в очередях, начиная с очереди с высоким приоритетом. Каждый URL-адрес проверяется для определения протокола. Затем средство сбора данных ищет обработчик протокола, зарегистрированный для этого протокола, и создает его экземпляр в процессе узла протокола поиска.
Узел протокола поиска Узел протокола поиска — это просто упакованный хост-процесс для обработчиков протоколов. Как правило, Windows Search создает два таких хост-процесса: один из них выполняется в контексте безопасности системы, а второй — в контексте безопасности пользователя. Такое разделение гарантирует, что данные, относящиеся к пользователю, никогда не будут выполняться в контексте системы.
Windows Search также использует хост-процесс для изоляции экземпляра обработчика протокола от других процессов или приложений. Таким образом, никакое внешнее приложение не сможет получить доступ к этому конкретному экземпляру обработчика протокола, и в случае неожиданного сбоя обработчика протокола затрагивается только процесс индексирования. Так как ведущем процессе выполняется сторонний код (обработчики протоколов), Поиск Windows периодически перезапускает процесс, чтобы свести к минимуму время, необходимое для успешной атаки для использования информации в процессе. Кроме того, узел протокола поиска не влияет на обход URL-адресов или индексирование элементов.
Обработчики протоколов Обработчики протоколов предоставляют доступ к элементам в хранилище данных с помощью протокола хранилища данных. Например, обработчик протокола NTFS предоставляет доступ к файлам на локальном диске с помощью протокола file://. Обработчик протокола знает, как просматривать хранилище данных, определять новые или обновленные элементы и уведомлять сборщика. Затем, когда начинается обход контента, обработчик протокола предоставляет объект IUrlAccessor средству сбора данных для привязки к базовому потоку элемента и возврата метаданных элемента, таких как ограничения безопасности и время последнего изменения.
Примечание
Обработчики протоколов не являются компонентами Windows Search; они являются компонентами конкретного протокола и хранилища данных, к которые они предназначены для доступа. Если у вас есть пользовательское хранилище данных, которое требуется индексировать, необходимо реализовать обработчик протокола. Дополнительные сведения об обработчиках протоколов и их реализации см. в статье Разработка обработчиков протоколов.
Метаданные и поток Используя метаданные, возвращаемые объектом IUrlAccessor обработчика протокола, средство сбора определяет правильный фильтр для URL-адреса. Средство сбора анализирует расширение имени файла элемента и ищет фильтр, зарегистрированный для этого расширения. Если средству сбора данных не удается найти фильтр, Поиск Windows использует метаданные для получения минимального набора сведений о свойствах системы (например, System.ItemName) и обновляет индекс. В противном случае, если средство сбора данных находит фильтр, начинается третий этап индексирования.
Этап 3. Обновление индекса
На третьем этапе индексирования средство сбора создает правильный фильтр для URL-адреса и инициализирует фильтр потоком из объекта IUrlAccessor . Затем фильтр обращается к элементу и возвращает содержимое для индекса. Если у вас есть пользовательский формат файла, Windows Search использует фильтр для доступа к URL-адресам и выдачи содержимого и свойств для индексирования.
На следующей схеме показано общее представление процесса доступа к данным. Этот этап включает значительную координацию и взаимодействие между компонентами.

В оставшейся части этого раздела описывается, как Windows Search обращается к данным элементов для индексирования, и описываются роли каждого из задействованных компонентов.
Собирателей В начале этого этапа роль средства сбора данных заключается в создании экземпляра правильного фильтра для элемента и передаче его в поток элементов. В конце этого этапа средство сбора данных принимает содержимое и свойства, созданные обработчиком фильтра и свойств, и обновляет индекс.
Узел фильтрации Узел фильтра — это просто процесс узла для фильтров и обработчиков свойств и служит цели, аналогичной узлу протокола поиска. Процесс узла изолирует фильтры и обработчики свойств от остальной части системы по тем же причинам безопасности и стабильности, по которым процессы узла поиска изолируют обработчики протокола. Хост-процесс выполняется с минимальными правами (он даже не может получить доступ к файловой системе) и иногда перезапускается для защиты от атак безопасности. Windows Search также отслеживает использование ресурсов, чтобы, если фильтр потребляет слишком много ресурсов, главный процесс перезапускается.
Фильтры Фильтры являются критически важными компонентами в процессе индексирования, которые выдают сведения об элементах для средства сбора данных. Фильтры называются в честь основного интерфейса, используемого в их реализации, интерфейса IFilter и, следовательно, иногда называются IFilters. Существует два типа фильтров: один взаимодействует с отдельными элементами, такими как файлы, и один , который взаимодействует с контейнерами, такими как папки. Оба предоставляют данные для индекса.
Используя метаданные, возвращаемые объектом IUrlAccessor обработчика протокола, средство сбора определяет правильный фильтр для определенного URL-адреса и передает его в поток. Средство сбора данных определяет правильный фильтр с помощью обработчика протокола или по расширению имени файла, типу MIME или идентификатору класса (CLSID). Если URL-адрес указывает на контейнер, фильтр выдает свойства контейнера и перечисляет элементы в контейнере (дочерние URL-адреса). Если URL-адрес указывает на элемент, фильтр возвращает текстовое содержимое, если какое-либо чтение свойств и является более сложным, чем обработчики свойств. Как правило, рекомендуется, чтобы фильтры предоставляли содержимое элемента, а обработчики свойств — свойства элементов. Однако если фильтру необходимо работать с более старыми приложениями, которые не распознают обработчики свойств, можно также реализовать фильтр для создания свойств.
Примечание
Фильтры не являются компонентами Windows Search; они являются компонентами, связанными с определенным форматом файла или контейнером, к который они предназначены для доступа. Дополнительные сведения о фильтрах и их реализации для пользовательского формата файлов или контейнера см. в статье Рекомендации по созданию обработчиков фильтров в Windows Search.
В следующей таблице перечислены результаты, которые средство сбора данных получает от фильтра (IFilter) и обработчика свойств (IPropertyStore) в процессе индексирования.
| Ifilter | IPropertyStore | |
|---|---|---|
| Разрешить запись | Нет | Да |
| Сочетание содержимого и свойств | Да | Нет |
| Многоязычных | Да | Нет |
| Выдача ссылок | Да | Нет |
| MIME | Да | Нет |
| Границы текста | Предложение, абзац, глава | Нет |
| Клиент или сервер | Оба | клиент |
| Реализация | Complex | Простота |
Обработчики свойств Обработчики свойств — это компоненты, которые считывают и записывают свойства для определенного формата файла. Они получают доступ к элементам и выдают свойства для средства сбора данных так же, как фильтры для содержимого. Обработчики свойств проще реализовать, чем фильтры. Если текстовый формат файла очень прост или файлы должны быть очень маленькими, обработчик свойств может выдавать как свойства, так и содержимое.
Примечание
Обработчики свойств не являются компонентами Windows Search; они являются компонентами, связанными с определенным форматом файлов, для доступа к ним. Дополнительные сведения об обработчиках свойств и о том, как реализовать их для пользовательского формата файлов, см. в статье Разработка обработчиков свойств для Поиска Windows.
Вариантов размещения Windows Search предоставляет систему свойств , которая включает в себя большую библиотеку свойств. Любое свойство может отображаться в любом элементе в соответствии с определением в обработчике фильтра или свойства. Если у вас есть пользовательский формат файла, можно сопоставить свойства формата файла с этими системным свойствами и создать новые настраиваемые свойства. Когда фильтр или обработчик свойств выдает эти свойства, средство сбора обновляет индекс, чтобы пользователи могли выполнять поиск по вашим свойствам. Дополнительные сведения о создании и регистрации настраиваемых свойств для формата файла см. в разделе Система свойств.
SystemIndex Индекс, называемый SystemIndex, хранит индексированные данные и состоит из хранилища свойств и индексов по свойствам и содержимому для свойств элемента, а также инвертированного индекса для текстового содержимого и свойств. После обновления индекса средство сбора данных может запрашивать его в Windows Search и других приложениях. Дополнительные сведения о способах запроса индекса см. в статье Запрос индекса программным способом.
Примечание
Помните, что при повторной регистрации схемы изменения, внесенные в атрибуты ранее определенных свойств, могут не учитываться индексатором. Решение состоит в том, чтобы перестроить индекс или ввести новые свойства, которые отражают изменения, а не обновлять старые (не рекомендуется). Дополнительные сведения см. в разделе Примечание для разработчиков в разделе Общие сведения о системе свойств.
Планирование индексирования
При первой установке Windows Search выполняет полное индексирование область обхода контента, приостанавливая в периоды высокой активности операций ввода-вывода и активности пользователей. Область обхода контента по умолчанию состоит из расположений библиотек по умолчанию, таких как "Документы", "Музыка", "Изображения" и "Видео". Уведомления обрабатываются еще до завершения начального обхода контента. Иногда средство сбора данных выполняет обход URL-адресов из полного область обхода контента. Эти полные обходы гарантируют, что данные в индексе являются свежими. Например, если поставщику уведомлений не удается отправить уведомления или если служба Windows неожиданно завершается, средство сбора данных не будет знать о новых или измененных элементах и не будет индексировать эти элементы. Существует два типа источников: только уведомления и уведомления включены. В обоих источниках средство сбора данных изначально выполняет обход индекса. После первоначального обхода источники, доступные только для уведомлений, никогда не будут выполнять полный обход контента, если не произойдет сбой, такой как переворачивая журнал изменений USN . Источники с поддержкой уведомлений выполняют добавочный обход контента при запуске индексатора, но затем прослушивают уведомления во время работы. NTFS и Microsoft Outlook являются только уведомлениями. Уведомления включены Обозреватель Интернета и FAT.
Примечания для тех, кто реализует этот метод
Качество данных в индексе и эффективность процесса индексирования во многом зависят от реализации фильтра и обработчика свойств. Так как фильтр вызывается каждый раз, когда URL-адрес идентифицирует формат файла, процесс индексирования может значительно замедлиться, если фильтр неэффективен. Если обработчик свойств неправильно сопоставляет все свойства файла с системными свойствами или неправильно выдает эти свойства, данные в индексе будут неправильными, а последующие поиски этих свойств будут возвращать неверные результаты. Если фильтр или обработчик свойств завершается сбоем, индексатор не сможет индексировать данные.
Приложения и процессы, отличные от Windows Search, используют обработчики протоколов, фильтры и обработчики свойств. Ваши реализации могут повлиять на эти приложения так, как вы не ожидаете. Руководство по разработке в Windows Search содержит рекомендации по выбору дизайна и тестированию каждого из этих компонентов.
Связанные темы
Индексирование, запросы и уведомления в Windows Search
Процесс запросов в Windows Search
Обратная связь
Ожидается в ближайшее время: в течение 2024 года мы постепенно откажемся от GitHub Issues как механизма обратной связи для контента и заменим его новой системой обратной связи. Дополнительные сведения см. в разделе https://aka.ms/ContentUserFeedback.
Отправить и просмотреть отзыв по