Používajte modely založené na strojovom učení platformy Azure
Zjednotené údaje v Dynamics 365 Customer Insights údajoch sú zdrojom pre vytváranie strojové učenie modelov, ktoré môžu generovať ďalšie obchodné poznatky. Customer Insights - Data integruje sa s Azure strojové učenie a používa vlastné modely.
Požiadavky
- Prístup k Customer Insights - Data
- Aktívne predplatné Azure Enterprise
- Zjednotené profily zákazníkov
- Nakonfigurovaný export tabuľky do ukladacieho priestoru objektu BLOB platformy Azure
Nastavte pracovný priestor strojového učenia platformy Azure
Pozrite si tému Vytvorenie pracovného priestoru Azure strojové učenie pre rôzne možnosti vytvorenia pracovného priestoru. S cieľom dosiahnuť čo najlepší výkon vytvorte pracovný priestor v oblasti platformy Azure, ktorá je geograficky najbližšie k vášmu prostrediu služby Customer Insights.
Získajte prístup k svojmu pracovnému priestoru prostredníctvom Azure strojové učenie Studio. Existuje niekoľko spôsobov interakcie s pracovným priestorom.
Spolupracujte s návrhárom služby strojového učenia platformy Azure
Azure strojové učenie designer poskytuje vizuálne plátno, kde môžete presúvať množiny údajov a moduly. Dávkový kanál vytvorený návrhárom môže byť integrovaný Customer Insights - Data , ak je zodpovedajúcim spôsobom nakonfigurovaný.
Práca so súpravou SDK služby strojového učenia platformy Azure
Vedci údajov a vývojári umelej inteligencie používajú súpravu Azure strojové učenie SDK na vytváranie pracovných postupov strojové učenie. V súčasnosti nie je možné modely trénované pomocou súpravy SDK integrovať priamo. Dávkový inferenčný kanál, ktorý spotrebúva tento model, je potrebný na integráciu Customer Insights - Data.
Požiadavky na dávkové potrubie na integráciu s Customer Insights - Data
Konfigurácia množiny údajov
Vytvorte množiny údajov na používanie údajov tabuľky zo Customer Insights pre váš dávkový inferenčný kanál. Zaregistrujte tieto množiny údajov v pracovnom priestore. V súčasnosti podporujeme tabuľkové množiny údajov iba v .csv formáte. Parametrizujte množiny údajov, ktoré zodpovedajú údajom tabuľky, ako parameter kanála.
Parametre množiny údajov v Návrhárovi
V návrhárovi otvorte položku Vybrať stĺpce v množine údajov a vyberte položku Nastaviť ako parameter kanála, kde zadáte názov parametra.

Parameter množiny údajov v súprave SDK (Python)
HotelStayActivity_dataset = Dataset.get_by_name(ws, name='Hotel Stay Activity Data') HotelStayActivity_pipeline_param = PipelineParameter(name="HotelStayActivity_pipeline_param", default_value=HotelStayActivity_dataset) HotelStayActivity_ds_consumption = DatasetConsumptionConfig("HotelStayActivity_dataset", HotelStayActivity_pipeline_param)
Kanál hromadnej predikcie
V návrhárovi použite tréningový kanál na vytvorenie alebo aktualizáciu inferenčného kanála. V súčasnosti sú podporované iba kanály hromadnej predikcie.
Pomocou súpravy SDK publikujte kanál do koncového bodu. V súčasnosti Customer Insights - Data sa integruje s predvoleným kanálom v koncovom bode dávkového kanála v pracovnom priestore strojové učenie.
published_pipeline = pipeline.publish(name="ChurnInferencePipeline", description="Published Churn Inference pipeline") pipeline_endpoint = PipelineEndpoint.get(workspace=ws, name="ChurnPipelineEndpoint") pipeline_endpoint.add_default(pipeline=published_pipeline)
Import údajov kanála
Návrhár poskytuje modul Exportovať údaje, ktorý umožňuje exportovať výstup kanála do úložiska Azure. V súčasnosti musí modul používať ukladací priestor údajov typu Azure Blob Storage a parametrizovať ukladací priestorúdajov a relatívnucestu. Systém prepíše oba tieto parametre počas vykonávania kanála pomocou dátového úložiska a cesty, ktorá je prístupná aplikácii.
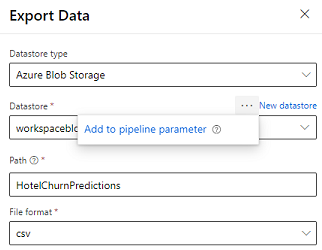
Pri zápise výstupu inferencie pomocou kódu nahrajte výstup na cestu v rámci registrovaného úložiska údajov v pracovnom priestore. Ak sú cesta a ukladací priestor údajov parametrizované v kanáli, Customer Insights môže čítať a importovať výstup odvodenia. V súčasnosti je podporovaný jeden tabuľkový výstup vo formáte .csv. Postup musí obsahovať adresár a názov súboru.
# In Pipeline setup script OutputPathParameter = PipelineParameter(name="output_path", default_value="HotelChurnOutput/HotelChurnOutput.csv") OutputDatastoreParameter = PipelineParameter(name="output_datastore", default_value="workspaceblobstore") ... # In pipeline execution script run = Run.get_context() ws = run.experiment.workspace datastore = Datastore.get(ws, output_datastore) # output_datastore is parameterized directory_name = os.path.dirname(output_path) # output_path is parameterized. # Datastore.upload() or Dataset.File.upload_directory() are supported methods to uplaod the data # datastore.upload(src_dir=<<working directory>>, target_path=directory_name, overwrite=False, show_progress=True) output_dataset = Dataset.File.upload_directory(src_dir=<<working directory>>, target = (datastore, directory_name)) # Remove trailing "/" from directory_name