Experimenty strojového učenia v službe Microsoft Fabric
Experiment strojového učenia je primárnou jednotkou organizácie a kontroly pre všetky súvisiace spustenia strojového učenia. Spustenie zodpovedá jednému vykonaniu kódu modelu. V toku MLflow je sledovanie založené na experimentoch a spusteniach.
Experimenty strojového učenia umožňujú dátovým vedcom zaznamenávať parametre, verzie kódu, metriky a výstupné súbory pri spúšťaní kódu strojového učenia. Experimenty tiež umožňujú vizualizovať, vyhľadávať a porovnávať spustenia, ako aj sťahovať spúšťané súbory a metaúdaje na analýzu v iných nástrojoch.
V tomto článku sa dozviete viac o tom, ako môžu dátoví vedci pracovať a používať experimenty strojového učenia na organizovanie procesu vývoja a sledovanie viacerých spustení.
Predpoklady
- Predplatné na Power BI Premium. Ak ho nemáte, pozrite si tému Ako kúpiť Power BI Premium.
- Pracovný priestor Power BI s priradenou kapacitou Premium.
Vytvorenie experimentu
Experiment strojového učenia môžete vytvoriť priamo z domovskej stránky Dátová veda v používateľskom rozhraní Power BI (UI) alebo napísaním kódu, ktorý používa rozhranie API toku údajov.
Vytvorenie experimentu pomocou používateľského rozhrania
Vytvorenie experimentu strojového učenia z používateľského rozhrania:
Vytvorte nový pracovný priestor dátovej vedy alebo vyberte existujúci.
V časti New vyberte položku Experimentovať .
Zadajte názov experimentu a vyberte položku Vytvoriť. Táto akcia vytvorí prázdny experiment v rámci vášho pracovného priestoru.
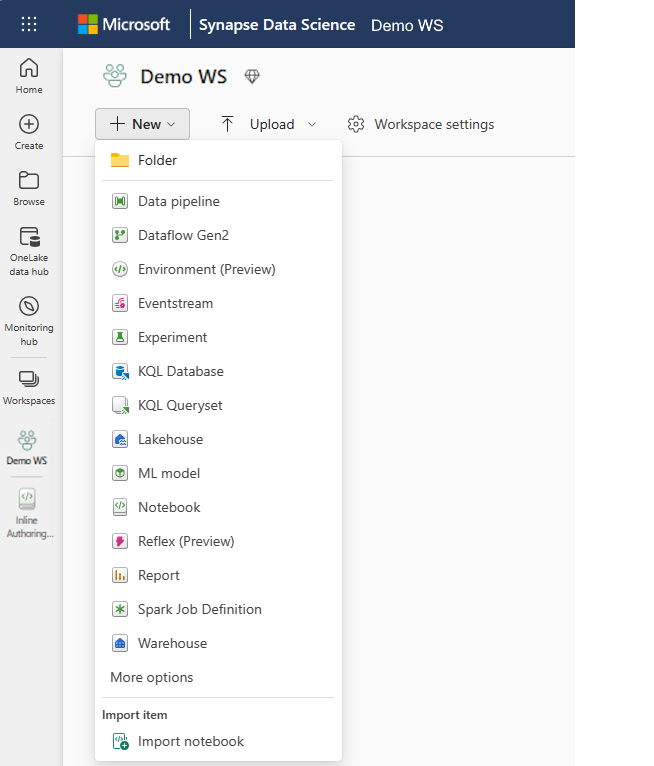

Po vytvorení experimentu môžete začať pridávať spustenia na sledovanie metrík spustenia a parametrov.
Vytvorenie experimentu pomocou rozhrania API toku MLflow
Môžete tiež vytvoriť experiment strojového učenia priamo z vašej tvorby pomocou mlflow.create_experiment() rozhraní alebo rozhraní API mlflow.set_experiment() . V nasledujúcom kóde nahraďte <EXPERIMENT_NAME> názov vášho experimentu.
import mlflow
# This will create a new experiment with the provided name.
mlflow.create_experiment("<EXPERIMENT_NAME>")
# This will set the given experiment as the active experiment.
# If an experiment with this name does not exist, a new experiment with this name is created.
mlflow.set_experiment("<EXPERIMENT_NAME>")
Správa spustení v rámci experimentu
Experiment strojového učenia obsahuje kolekciu spustení na zjednodušené sledovanie a porovnanie. V rámci experimentu môže dátový vedec prechádzať rôznymi spusteniami a skúmať základné parametre a metriky. Dátoví vedci tiež môžu porovnať spustenia v rámci experimentu strojového učenia, aby zistili, ktorá podmnožina parametrov prinesie požadovaný výkon modelu.
Spustenia na sledovanie
Spustenie strojového učenia zodpovedá jednému vykonaniu kódu modelu.

Každé spustenie obsahuje nasledujúce informácie:
- Zdroj: Názov poznámkového bloku, ktorý vytvoril spustenie.
- Registrovaná verzia: označuje, či sa spustenie uložilo ako model strojového učenia.
- Dátum začatia: čas spustenia.
- Stav: Priebeh spustenia.
- Hyperparametre: Hyperparametre uložené ako páry kľúč-hodnota. Kľúče aj hodnoty sú reťazce.
- Metriky: Spustenie metrík uložených ako páry kľúč-hodnota. Hodnota je numerická.
- Výstupné súbory: Výstupné súbory v ľubovoľnom formáte. Môžete napríklad zaznamenávať obrázky, prostredie, modely a údajové súbory.
Zobrazenie posledných spustení
Môžete tiež zobraziť nedávne spustenia experimentovania priamo v zobrazení zoznamu pracovných priestorov. Toto zobrazenie vám umožňuje mať prehľad o nedávnej aktivite, rýchlo prejsť na súvisiacu aplikáciu Spark a použiť filtre na základe stavu spustenia.

Porovnanie a spustenia filtra
Ak chcete porovnať a vyhodnotiť kvalitu spustení strojového učenia, môžete porovnať parametre, metriky a metaúdaje medzi vybratými spusteniami v rámci experimentu.
Vizuálne porovnanie spustení
Môžete vizuálne porovnať a filtrovať spustenia v rámci existujúceho experimentu. Porovnávanie vizuálov umožňuje jednoducho prechádzať medzi viacerými spusteniami a zoraďovať medzi nimi.

Porovnanie spustení:
- Vyberte existujúci experiment strojového učenia, ktorý obsahuje viacero spustení.
- Vyberte kartu Zobrazenie a potom prejdite na zobrazenie zoznamu Spustiť. Prípadne môžete vybrať možnosť Zobraziť zoznam spustení priamo v zobrazení Spustiť podrobnosti .
- Prispôsobte stĺpce v tabuľke rozbalením tably Prispôsobiť stĺpce . Tu môžete vybrať vlastnosti, metriky a hyperparametre, ktoré chcete zobraziť.
- Rozbaľte tablu Filter a zúžite výsledky na základe určitých vybratých kritérií.
- Vyberte viacero spustení na porovnanie svojich výsledkov na table porovnávania metrík. Na tejto table môžete prispôsobiť grafy zmenou názvu grafu, typu vizualizácie, osi x, osi y a ďalších možností.
Porovnanie spustení pomocou rozhrania API MLflow
Dátoví vedci môžu tiež použiť tok ML na dotazovanie a vyhľadávanie medzi spusteniami v rámci experimentu. Ďalšie rozhrania API toku MLflow môžete preskúmať na vyhľadávanie, filtrovanie a porovnávanie spustení navštívením dokumentácie k toku MLflow.
Získanie všetkých spustení
Rozhranie API mlflow.search_runs() vyhľadávania MLflow môžete použiť na získanie všetkých spustení v experimente, a to nahradením <EXPERIMENT_NAME> názvu experimentu alebo <EXPERIMENT_ID> ID experimentu nasledujúcim kódom:
import mlflow
# Get runs by experiment name:
mlflow.search_runs(experiment_names=["<EXPERIMENT_NAME>"])
# Get runs by experiment ID:
mlflow.search_runs(experiment_ids=["<EXPERIMENT_ID>"])
Prepitné
Môžete vyhľadávať v rôznych experimentoch tak, že do parametra zadáte zoznam ID experimentov experiment_ids . Podobne platí, že ak zadáte zoznam názvov experimentov do experiment_names parametra, MLflow umožní vyhľadávanie vo viacerých experimentoch. Môže to byť užitočné, ak chcete porovnať spustenia naprieč rôznymi experimentmi.
Spustenia poradia a obmedzenia
Pomocou parametra max_results z search_runs obmedzíte počet vrátených spustení. Parameter order_by umožňuje uviesť v zozname stĺpce, podľa ktoré sa má zoradiť, a môže obsahovať voliteľnú DESC hodnotu alebo ASC hodnotu. Nasledujúci príklad napríklad vráti posledné spustenie experimentu.
mlflow.search_runs(experiment_ids=[ "1234-5678-90AB-CDEFG" ], max_results=1, order_by=["start_time DESC"])
Porovnanie spustení v poznámkovom bloku služby Fabric
Miniaplikáciu na vytváranie toku strojového učenia v poznámkových blokoch služby Fabric môžete použiť na sledovanie spustení toku MLflow vygenerovaných v každej bunke poznámkového bloku. Miniaplikácia vám umožňuje sledovať spúšťania, súvisiace metriky, parametre a vlastnosti až na úroveň jednotlivých buniek.
Ak chcete získať porovnanie vizuálu, môžete prejsť aj do zobrazenia Porovnania spustenia. Toto zobrazenie predstavuje údaje graficky pomocou rýchlej identifikácie vzorov alebo odchýlok v rôznych spusteniach.

Uloženie spustenia ako modelu strojového učenia
Keď spustenie prinesie požadovaný výsledok, spustenie môžete uložiť ako model na vylepšené sledovanie modelu a na nasadenie modelu výberom položky Uložiť ako model strojového učenia.

Súvisiaci obsah
Pripomienky
Pripravujeme: V priebehu roka 2024 postupne zrušíme službu Problémy v službe GitHub ako mechanizmus pripomienok týkajúcich sa obsahu a nahradíme ju novým systémom pripomienok. Ďalšie informácie nájdete na stránke: https://aka.ms/ContentUserFeedback.
Odoslať a zobraziť pripomienky pre