Sprievodný materiál k modelu DirectQuery v aplikácii Power BI Desktop
Tento článok je určený modelárov údajov, ktorí vyvíjajú modely DirectQuery služby Power BI, a to buď pomocou aplikácie Power BI Desktop, alebo služba Power BI. Popisuje prípady použitia režimu DirectQuery, obmedzenia a pokyny. Pokyny sú konkrétne navrhnuté tak, aby vám pomohli určiť, či je režim DirectQuery vhodný pre váš model a umožňuje zlepšiť výkon zostáv založených na modeloch DirectQuery. Tento článok sa vzťahuje na modely DirectQuery hosťované v služba Power BI alebo Power BI Report Serveri.
Cieľom tohto článku nie je poskytovať kompletné informácie o návrhu modelu DirectQuery. Úvodné informácie nájdete v článku Modely DirectQuery v aplikácii Power BI Desktop . Podrobnejšie informácie nájdete priamo v technickej dokumentácii Režim DirectQuery v službe SQL Server 2016 Analysis Services . Majte na pamäti, že technická dokumentácia popisuje použitie režimu DirectQuery v službe SQL Server Analysis Services. Veľká časť obsahu sa napriek tomu vzťahuje aj na modely služby Power BI DirectQuery.
Poznámka
Informácie týkajúce sa používania režimu úložiska DirectQuery pre funkciu Dataverse nájdete v téme Sprievodný materiál k modelovaniu v službe Power BI pre Power Platform.
Tento článok sa nezaoberá priamo zloženými modelmi. Zložený model sa skladá aspoň z jedného zdroja DirectQuery a možno aj viacerých. Sprievodný materiál popísaný v tomto článku je však stále aspoň sčasti relevantný pre návrh zloženého modelu. Dôsledky kombinovania tabuliek v režime Import s tabuľkami v režime DirectQuery však nie sú súčasťou tohto článku. Ďalšie informácie nájdete v téme Používanie zložených modelov v aplikácii Power BI Desktop.
Je dôležité pochopiť, že pracovné vyťaženie prostredia Power BI (služba Power BI alebo Power BI Report Servera) a tiež základných zdrojov údajov modelmi DirectQuery je rozdielne. Ak sa rozhodnete, že režim DirectQuery je vhodným prístupom k návrhu, odporúčame vám, aby ste do projektu zapojili správnych ľudí. Často vidieť, že úspešné nasadenie modelu DirectQuery je výsledkom tímu profesionálov v oblasti IT, ktorí úzko spolupracovali. Daný tím sa zvyčajne skladá z vývojárov modelov a správcov zdrojovej databázy. Jeho súčasťou môžu byť aj architekti údajov a vývojári skladov údajov a ETL. Ak chcete dosiahnuť dobré výsledky v oblasti výkonu, je často potrebné optimalizovať priamo zdroj údajov.
Optimalizácia výkonu zdroja údajov
Zdroj relačnej databázy je možné optimalizovať niekoľkými spôsobmi, ktoré sú popísané v nasledujúcom zozname.
Poznámka
Chápeme, že nie všetci modelári majú povolenia alebo zručnosti na optimalizáciu relačnej databázy. Hoci sa uprednostňuje príprava údajov pre model DirectQuery, niektoré optimalizácie je možné vykonať aj v návrhu modelu bez toho, aby sa upravila zdrojová databáza. Najlepšie výsledky v oblasti optimalizácie je však možné dosiahnuť optimalizáciou zdrojovej databázy.
Skontrolujte úplnosť integrity údajov: Je obzvlášť dôležité, aby tabuľky dimenzií obsahovali stĺpec jedinečných hodnôt (kľúč dimenzie), ktorý sa primapuje k tabuľkám faktov. Je tiež dôležité, aby stĺpce dimenzií faktového typu obsahovali platné hodnoty kľúča dimenzií. Umožní sa tým konfigurácia efektívnejších vzťahov modelu, ktoré očakávajú zhodné hodnoty na oboch stranách vzťahu. Ak zdrojovým údajom chýba integrita, odporúča sa pridanie neznámeho záznamu dimenzie, ktorý efektívne opraví údaje. Môžete napríklad pridať riadok do tabuľky Produkt , ktorý bude predstavovať neznámy produkt, a potom mu priradiť kľúč mimo rozsahu, napríklad s číslom -1. Ak riadky v tabuľke Sales (Predaj ) obsahujú chýbajúcu hodnotu Product Key, nahraďte ju hodnotou -1. Tým sa zabezpečí, aby každej hodnote Product Key tabuľky Sales (Predaj ) zodpovedal riadok v tabuľke Product (Produkt ).
Pridajte indexy: Definujte vhodné indexy, či už v tabuľkách alebo zobrazeniach, ako podporu efektívneho získavania údajov pre očakávané filtrovanie a zoskupenie vizuálov zostáv. V prípade zdrojov SQL Server, Databázy Azure SQL alebo Azure Synapse Analytics (predtým SQL Data Warehouse) nájdete v téme Sprievodný materiál k navrhovaniu a architektúre indexov servera SQL Server. V prípade nestálych zdrojov SQL Server a Databázy Azure SQL si prečítajte tému Začíname s supermarketmi Columnstore pre prevádzkovú analýzu v reálnom čase.
Navrhnite distribuované tabuľky: V prípade zdrojov Azure Synapse Analytics (predtým SQL Data Warehouse), ktoré používajú architektúru hromadného paralelného spracovania (MPP), zvážte konfiguráciu veľkých tabuliek faktov ako distribuovaných tabuliek s hodnotou hash a replikáciu tabuliek typu dimenzií vo všetkých výpočtových uzloch. Ďalšie informácie nájdete v téme Sprievodný materiál k navrhovaniu distribuovaných tabuliek v službe Azure Synapse Analytics (predtým SQL Data Warehouse).
Skontrolujte realizáciu požadovaných transformácií údajov: V prípade zdrojov relačnej databázy SQL Server (a iných zdrojov relačnej databázy) je možné pridať do tabuliek vypočítané stĺpce. Tieto stĺpce sú založené na výraze, ako je napríklad stĺpec Quantity vynásobený jednotkovoucenou. Vypočítané stĺpce môžu byť trvalé (realizované) a rovnako ako bežné stĺpce, môžu byť niekedy indexované. Ďalšie informácie nájdete v téme Indexy vo vypočítaných stĺpcoch.
Zvážte tiež indexované zobrazenia, ktoré môžu predbežne agregovať údaje tabuľky faktov vo vyššom množstve. Ak napríklad tabuľka Predaj ukladá údaje na úrovni riadkov objednávky, môžete vytvoriť zobrazenie na sumarizáciu týchto údajov. Zobrazenie môže byť založené na príkaze SELECT, ktorý zoskupuje údaje tabuľky Sales (Predaj ) podľa dátumu (na úrovni mesiaca), zákazníka, produktu a sumarizuje hodnoty mierky, ako napríklad predaj, množstvo atď. Zobrazenie je následne možné indexovať. V prípade zdrojov SQL Server alebo Databázy Azure SQL si prečítajte tému Vytvorenie indexovaných zobrazení.
Realizujte tabuľku dátumov: Požiadavka na bežné modelovanie zahŕňa aj pridanie tabuľky dátumov ako podporu filtrovania na základe času. Ak chcete v organizácii podporovať známe časové filtre, vytvorte tabuľku v zdrojovej databáze a zabezpečte, že sa načíta s rozsahom dátumov, ktorý zahŕňa dátumy tabuľky faktov. Tiež by ste mali uistiť, že zahŕňa stĺpce s užitočnými časovými obdobiami, ako sú napríklad rok, štvrťrok, mesiac, týždeň atď.
Optimalizácia návrhu modelu
Model DirectQuery je možné optimalizovať mnohými spôsobmi, ktoré sú popísané v nasledujúcom zozname.
Nepoužívajte komplexné dotazy Power Query: Efektívny návrh modelu dosiahnete, ak zabránite, aby dotazy Power Query používali všetky transformácie. Znamená to, že každý dotaz sa primapuje k jednej tabuľke zdroja relačnej databázy alebo zobrazeniu. Výberom možnosti Zobraziť natívny dotaz môžete zobraziť ukážku zobrazenia skutočného príkazu dotazu SQL pre krok použitý v Power Query.
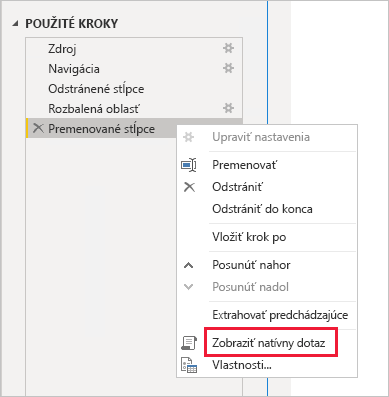
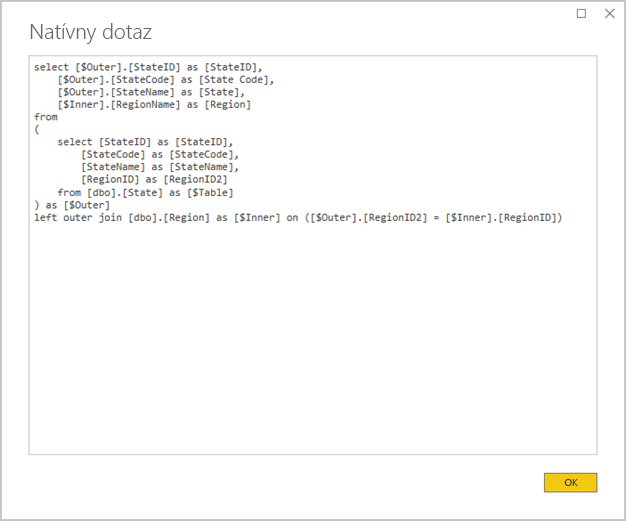
Skontrolujte použitie vypočítaných stĺpcov a zmeny typov údajov: Modely DirectQuery podporujú pridávanie výpočtov a krokov Power Query, ktoré slúžia na konverziu údajových typov. Pokiaľ je to možné, lepší výkon dosiahnete realizáciou výsledkov transformácie v zdroji relačnej databázy.
Nepoužívajte filtrovanie relatívnych dátumov Power Query: V dotaze Power Query je možné definovať filtrovanie relatívnych dátumov. Napríklad, ak ich chcete načítať do predajných objednávok, ktoré boli vytvorené minulý rok (vzhľadom na dnešný dátum). Tento typ filtra sa prekladá do neefektívneho natívneho dotazu takto:
… from [dbo].[Sales] as [_] where [_].[OrderDate] >= convert(datetime2, '2018-01-01 00:00:00') and [_].[OrderDate] < convert(datetime2, '2019-01-01 00:00:00'))Lepším prístupom k návrhu je zahrnúť do tabuľky dátumov relatívne stĺpce času. Tieto stĺpce ukladajú hodnoty posunu, ktoré sú relatívne vzhľadom na aktuálny dátum. Nulová hodnota v stĺpci RelativeYear (RelatívnyRok) napríklad predstavuje aktuálny rok, hodnota -1 predstavuje predchádzajúci rok atď. Podľa možnosti sa stĺpec RelativeYear realizuje v tabuľke dátumov. Menej efektívnym je pridať ho ako stĺpec vypočítaný modelom na základe výrazu , ktorý používajú funkcie DAX TODAY a DATE .
Používajte jednoduché mierky: Aspoň spočiatku sa odporúča obmedziť mierky na jednoduché agregácie. Agregačné funkcie zahŕňajú funkcie SUM, COUNT, MIN, MAX a AVERAGE. Ak sú však mierky dostatočne flexibilné, môžete následne experimentovať so zložitejšími mierkami, ale zároveň musíte venovať pozornosť výkonu každej z nich. Zatiaľ čo funkciu DAX CALCULATE je možné použiť na vytváranie sofistikovaných výrazov mierok, ktoré narábajú s kontextom filtra, môžu generovať aj rozsiahle natívne dotazy, ktoré nefungujú správne.
Nepoužívajte vzťahy vo vypočítaných stĺpcoch: Vzťahy modelu sa môžu týkať iba jedného stĺpca v jednej tabuľke a jedného stĺpca v inej tabuľke. Niekedy je však potrebné prepojiť tabuľky pomocou viacerých stĺpcov. Napríklad tabuľky Predaj a Geografia sú prepojené dvomi stĺpcami: CountryRegion (KrajinaOblasť ) a City (Mesto). Ak chcete vytvoriť vzťah medzi tabuľkami, vyžaduje sa jeden stĺpec a stĺpec v tabuľke Geografia musí obsahovať jedinečné hodnoty. Môžete to dosiahnuť zreťazením tabuľky krajina,oblasť a mesto pomocou spojovníka.
Kombinovaný stĺpec je možné vytvoriť buď pomocou vlastného stĺpca Power Query, alebo v modeli ako vypočítaný stĺpec. Tomu sa však treba vyhnúť, keďže vypočítaný výraz bude vložený do zdrojových dotazov. Nielenže je to neefektívne, ale často to aj bráni použitiu indexov. Namiesto toho pridajte do zdroja relačnej databázy realizované stĺpce a zvážte ich indexovanie. Taktiež môžete zvážiť pridanie náhradných kľúčových stĺpcov do tabuliek dimenzií, čo je bežnou praxou v návrhoch relačných skladov údajov.
Tieto pokyny majú jednu výnimku, ktorá sa týka použitia funkcie DAX COMBINEVALUES . Účelom tejto funkcie je podpora vzťahov modelov s viacerými stĺpcami. Namiesto vygenerovania výrazu, ktorý vzťah používa, sa vygeneruje viacstĺpcový predikát spojenia SQL.
Nepoužívajte vzťahy v stĺpcoch Jedinečný identifikátor: Služba Power BI natívne nepodporuje typ údajov jedinečného identifikátora (GUID). Pri definovaní vzťahu medzi stĺpcami tohto typu Power BI vygeneruje zdrojový dotaz so spojením zahŕňajúcim pretypovanie. Táto konverzia údajov času dotazu často vedie k nedostatočnému výkonu. Kým tento konkrétny prípad nebude optimalizovaný, jediným alternatívnym riešením je realizovať stĺpce alternatívneho typu údajov v základnej databáze.
Skryte stĺpec vzťahov na strane one: Stĺpec vzťahu na strane one by mal byť skrytý. (Zvyčajne ide o stĺpec primárneho kľúča v tabuľke dimenzií.) Keď je skrytý, nie je k dispozícii na table Polia, a preto ho nie je možné použiť na konfiguráciu vizuálu. Stĺpec na strane many môže byť viditeľný aj naďalej, ak je vhodný na filtrovanie zostáv podľa hodnôt stĺpcov. Uvažujme napríklad o modeli, v ktorom existuje vzťah medzi tabuľkami Sales (Predaj ) a Product (Produkt ). Stĺpce vzťahu obsahujú hodnoty skladovej jednotky SKU produktu (Stock-Keeping Unit). Ak sa musí skladová jednotka SKU produktu pridať do vizuálov, mala by byť viditeľná len v tabuľke Predaj . Keď sa tento stĺpec použije na filtrovanie alebo zoskupenie vo vizuáli, Power BI vygeneruje dotaz, ktorý nie je potrebné pripojiť k tabuľkám Predaj a Produkt .
Nastavte vzťahy na vynútenie integrity:Vlastnosť Predpokladať použitie referenčnej integrity vzťahov DirectQuery určuje, či služba Power BI generuje zdrojové dotazy skôr pomocou vnútorného spojenia alebo vonkajšieho spojenia. Hoci to závisí od konkrétnych detailov zdroja relačnej databázy, zvyčajne zlepší výkon dotazu. Ďalšie informácie nájdete v téme Predpoklad nastavení referenčnej integrity v aplikácii Power BI Desktop.
Nepoužívajte vo vzťahoch obojsmerné filtrovanie: Používaním obojsmerného filtrovania vzťahov môžu vznikať príkazy dotazov, ktoré nefungujú správne. Túto funkciu vzťahu použite iba v prípade potreby a zvyčajne ide o implementáciu vzťahu typu many-to-many v rámci premosťovcej tabuľky. Ďalšie informácie nájdete v téme Vzťahy s kardinalitou many-many v aplikácii Power BI Desktop.
Obmedzte paralelné dotazy: Môžete nastaviť maximálny počet pripojení DirectQuery, ktoré sa otvoria pre každý základný zdroj údajov. Určuje počet dotazov súbežne odoslaných do zdroja údajov.
- Toto nastavenie je povolené len vtedy, keď je v modeli aspoň jeden zdroj DirectQuery. Hodnota sa vzťahuje na všetky zdroje DirectQuery a na všetky nové zdroje DirectQuery pridané do modelu.
- Zväčšenie maximálnych Pripojenie ions na zdroj údajov zabezpečíte, že do základného zdroja údajov bude možné odoslať viac dotazov (až do zadaného maximálneho počtu). Je to užitočné, ak sa viaceré vizuály nachádzajú na jednej strane, alebo ak ku zostave pristupuje v rovnakom čase veľa používateľov. Po dosiahnutí maximálneho počtu pripojení sa ďalšie dotazy zaradia do frontu, kým nebude k dispozícii pripojenie. Zvýšenie tohto limitu má za následok väčšiu záťaž základného zdroja údajov, takže nie je zaručené, že toto nastavenie zlepší celkový výkon.
- Keď je model publikovaný v službe Power BI, maximálny počet súbežných dotazov odoslaných do základného zdroja údajov závisí aj od prostredia. Rôzne prostredia (ako napríklad Power BI, Power BI Premium alebo Power BI Report Server) si môžu stanoviť rôzne obmedzenia priepustnosť. Ďalšie informácie o obmedzeniach zdrojov kapacity nájdete v téme Licencie na kapacitu služby Microsoft Fabric a Konfigurácia a spravovanie kapacít v službe Power BI Premium.
Dôležité
V čase, keď sa tento článok týka služby Power BI Premium alebo jej predplatných kapacity (skladové jednotky SKU P). Spoločnosť Microsoft v súčasnosti konsoliduje možnosti nákupu a vyradí skladové jednotky SKU služby Power BI Premium na kapacitu. Noví a existujúci zákazníci by namiesto toho mali zvážiť zakúpenie predplatného kapacity služby Fabric (skladové jednotky F SKU).
Ďalšie informácie nájdete v téme Dôležitá aktualizácia pre licencie Power BI Premium a Power BI Premium: najčastejšie otázky.
Optimalizácia návrhov zostáv
Zostavy založené na sémantickom modeli DirectQuery (predtým známom ako množina údajov) možno optimalizovať mnohými spôsobmi, ako je to popísané v nasledujúcom zozname s odrážkami.
- Povoľte techniky znižovania počtu dotazov: Možnosti a Nastavenia aplikácie Power BI Desktop zahŕňajú stránku Zníženie počtu dotazov. Táto stránka obsahuje tri užitočné možnosti. Je možné predvolene zakázať krížové zvýraznenie a krížové filtrovanie, hoci môžu byť prepísané úpravou interakcií. Takisto je možné pri rýchlych filtroch a filtroch zobraziť tlačidlo Použiť. Možnosti rýchleho filtra alebo filtra sa nepouži budú používať, kým používateľ zostavy nesklikne na tlačidlo. Ak tieto možnosti povolíte, odporúčame, aby ste tak urobili pri prvom vytváraní zostavy.
- Najprv použite filtre: Pri prvom navrhovaní zostáv odporúčame použiť všetky použiteľné filtre, a to na úrovni zostavy, strany alebo vizuálu, ešte pred priradením polí do polí vizuálu. Napríklad, namiesto presunutie mierok CountryRegion (KrajinaOblasť) a Sales (Predaj ) a následné filtrovanie podľa konkrétneho roka, použite najskôr filter pre pole Year (Rok ). Každý krok pri vytváraní vizuálu totiž odosiela dotaz – a aj keď je možné ešte pred dokončením prvého dotazu vykonať zmeny – zbytočne to zaťažuje základný zdroj údajov. Ak filtre použijete už na začiatku, tieto prechodné dotazy budú menej nákladné a rýchlejšie. Neúspešné použitie filtrov tiež môže mať za následok prekročenie miliónového limitu riadkov, ako je popísané v článku o režime DirectQuery.
- Obmedzte počet vizuálov na strane: Po otvorení strany zostavy (a pri použití filtrov strany) sa obnovia všetky vizuály na strane. Existuje však obmedzenie počtu dotazov, ktoré je možné odoslať súbežne stanovené prostredím služby Power BI a nastavením Maximálny počet Pripojenie na zdroj údajov v modeli, ako je popísané vyššie. Takže so zvyšujúcim sa počtom vizuálov na strane sa zvyšuje aj šanca, že sa obnovia sériovo. Zvyšuje sa tým aj čas potrebný na obnovenie celej stránky a tiež pravdepodobnosť, že vizuály môžu zobrazovať nekonzistentné výsledky (nestále zdroje údajov). Preto sa odporúča obmedziť počet vizuálov na všetkých stranách a namiesto toho použiť viac jednoduchších strán. Nahradením viacerých vizuálov karty jedným vizuálom karty s viacerými riadkami môžete dosiahnuť podobné rozloženie strany.
- Vypnite interakcie medzi vizuálmi: Interakcie krížového zvýraznenia a krížového filtrovania vyžadujú, aby boli dotazy odoslané do základného zdroja. Ak nie sú tieto interakcie nevyhnutné, odporúča sa ich vypnutie, ak reagovanie na výbery používateľov trvá neprimerane dlho. Tieto interakcie možno vypnúť, a to buď pre celú zostavu (ako sa to popisuje v časti o možnostiach zníženia počtu dotazov vyššie), alebo pre jednotlivé prípady. Ďalšie informácie nájdete v téme Ako sa vizuály navzájom krížovo filtrujú v zostave Power BI.
Okrem vyššie uvedeného zoznamu techník optimalizácie môže k problémom s výkonom prispieť každá z nasledujúcich funkcií generovania zostáv:
Filtre mierok: Vizuály obsahujúce mierky (alebo zoskupenia stĺpcov) môžu mať v týchto mierkach použité filtre. Na nižšie uvedenom vizuáli sa napríklad zobrazuje predaj podľa kategórie, ale len pre kategórie s tržbou nad 15 miliónov USD.

V dôsledku toho sa na základný zdroj môžu odoslať dva dotazy:
- Prvý dotaz načíta kategórie, ktoré spĺňajú podmienku (Predaj > 15 miliónov USD)
- Druhý dotaz potom načíta údaje potrebné pre vizuál a pridá kategórie, ktoré spĺňajú podmienku, do klauzuly WHERE.
Ak existujú stovky alebo tisíce kategórií, tak ako v tomto príklade, zvyčajne to funguje dobre. Pokles výkonu je však možné vtedy, ak je počet kategórií oveľa vyšší (ak existuje viac ako milión kategórií, ktoré spĺňajú podmienku, dotaz zlyhá v dôsledku vyššie spomenutého obmedzenia jedného milióna riadkov).
Filtre TopN: Rozšírené filtre možno definovať tak, aby filtrovať iba prvých (alebo posledných) N hodnôt zoradených podľa mierky. Chcete napríklad zobraziť iba prvých päť kategórií vo vyššie uvedenom vizuáli. Podobne ako v prípade filtrov mierky, výsledkom budú dva dotazy odoslané do základného zdroja údajov. Prvý dotaz však zo základného zdroja vráti všetky kategórie a prvých N hodnôt sa určí až na základe vrátených výsledkov. V závislosti od kardinality daného stĺpca môžu narobiť problémy s výkonom (alebo zlyhania dotazov v dôsledku obmedzenia 1 milión riadkov).
Medián: Vo všeobecnosti sa do základného zdroja odosiela každá agregácia (Sum, Count Distinct atď.). To však neplatí pre medián, pretože túto agregáciu základný zdroj nepodporuje. V týchto prípadoch sa podrobné údaje získavajú zo základného zdroja a služba Power BI vyhodnotí medián z vrátených výsledkov. Je to v poriadku, ak sa má medián vypočítať z pomerne malého počtu výsledkov, ak je však kardinalita veľká, objavia sa problémy s výkonom (alebo zlyhanie dotazov v dôsledku obmedzenia 1 milión riadkov). Medián počtu obyvateľov krajiny alebo oblasti môže byť napríklad prijateľný, ale medián predajných cien už nie.
Rýchle filtre s viacnásobným výberom: Povolenie viacnásobného výberu v rýchlych filtroch a filtroch môže spôsobiť problémy s výkonom. Je to spôsobené tým, že používateľ vyberie ďalšie položky rýchleho filtra (napríklad pri vytváraní až 10 produktov, o ktoré sa zaujíma), pričom výsledkom každého nového výberu je odoslanie nového dotazu do základného zdroja. Aj keď používateľ môže vybrať ďalšiu položku ešte pred dokončením dotazu, znamená to zvýšenú záťaž základného zdroja. Tejto situácii sa dá predísť zobrazením tlačidla Použiť, ako je popísané vyššie v technikách na zníženie počtu dotazov.
Vizuálne súčty: V tabuľkách a maticiach sa predvolene zobrazujú súčty a medzisúčty. V mnohých prípadoch sa do základného zdroja musia na získanie hodnôt daných súčtov odosielať ďalšie dotazy. Platí to vždy, keď použijete agregáty Count Distinct alebo Median a pri použití režimu DirectQuery cez SAP Hana alebo SAP Business Warehouse vo všetkých prípadoch. Ak tieto súčty nie sú potrebné, mali by ste ich vypnúť (pomocou tably Formát).
Konverzia na zložený model
Výhody modelov importu a DirectQuery je možné skombinovať do jedného modelu nakonfigurovaním tabuliek modelov do režimu úložiska. Režim úložiska tabuliek môže byť režim Import alebo DirectQuery, prípadne o obe, známy ako Dual. Keď model obsahuje tabuľky s rôznymi režimami úložiska, označuje sa ako zložený model. Ďalšie informácie nájdete v téme Používanie zložených modelov v aplikácii Power BI Desktop.
Existuje mnoho vylepšení funkcií a výkonu, ktoré možno dosiahnuť konverziou modelu DirectQuery na zložený model. Zložený model môže integrovať viac ako jeden zdroj režimu DirectQuery a môže zahŕňať aj agregácie. Agregačné tabuľky je možné pridať do tabuliek DirectQuery, a tak importovať súhrnné zobrazenie tabuľky. Je možné dosiahnuť výrazné vylepšenia výkonu, ak vizuály dotazujú agregácie vyššej úrovne. Ďalšie informácie nájdete v téme Agregácie v aplikácii Power BI Desktop.
Vzdelávanie používateľov
Je dôležité, aby boli používatelia pouční o tom, ako efektívne pracovať so zostavami založenými na sémantických modeloch DirectQuery. Autori zostáv by mali byť poučení o obsahu popísanom v časti Optimalizácia návrhov zostáv.
Odporúčame, aby ste informovali používateľov zostáv o vašich zostavách, ktoré sú založené na sémantických modeloch DirectQuery. Môže im to pomôcť pochopiť všeobecnú architektúru údajov vrátane všetkých relevantných obmedzení popísaných v tomto článku. Dajte im vedieť, že môžu očakávať, že obnovovanie a interaktívne filtrovanie môže byť niekedy pomalé. Keď používatelia zostavy pochopia, prečo sa nižší výkon môže stať, je menej pravdepodobné, že zanechajú dôveru v zostavy a údaje.
Keď vytvárate zostavy na nestálych zdrojoch údajov, uistite sa, že ste používateľov zostáv informovali o použití tlačidla Obnoviť. Taktiež ich informujte, že je možné zobraziť nekonzistentné výsledky a že obnovením zostavy je možné vyriešiť všetky nezrovnalosti na strane zostavy.
Súvisiaci obsah
Ďalšie informácie o režime DirectQuery získate v nasledujúcich zdrojoch:
Pripomienky
Pripravujeme: V priebehu roka 2024 postupne zrušíme službu Problémy v službe GitHub ako mechanizmus pripomienok týkajúcich sa obsahu a nahradíme ju novým systémom pripomienok. Ďalšie informácie nájdete na stránke: https://aka.ms/ContentUserFeedback.
Odoslať a zobraziť pripomienky pre