Používateľom definované agregácie
Agregácie v službe Power BI môžu zlepšiť výkon dotazov vo veľkých sémantických modeloch DirectQuery. Pomocou agregácií ukladáte údaje do vyrovnávacej pamäte na agregovanej úrovni v pamäti. Agregácie v službe Power BI je možné nakonfigurovať manuálne v dátovom modeli, ako sa popisuje v tomto článku. Pri predplatnom Premium sa automaticky povolí funkcia Automatické agregácie v modeli Nastavenia.
Vytváranie agregačných tabuliek
V závislosti od typu zdroja údajov je možné v zdroji údajov vytvoriť tabuľku agregácií ako tabuľku alebo zobraziť natívny dotaz. Na najväčší výkon je možné vytvoriť tabuľku agregácií ako tabuľku importu vytvorenú v Power Query. Potom môžete v aplikácii Power BI Desktop použiť dialógové okno Spravovať agregácie na definovanie agregácií pre agregačné stĺpce so sumarizáciami, tabuľkami podrobností a vlastnosťami stĺpcov s podrobnosťami.
Dimenzionálne zdroje údajov, ako sú napríklad sklady údajov a trhy údajov, môžu využívať agregácie založené na vzťahoch. Zdroje veľkých objemov údajov založené na serveri Hadoop často zakladajú agregácie na stĺpcoch GroupBy. Tento článok popisuje typické rozdiely v modelovaní údajov v službe Power BI pre jednotlivé typy zdrojov údajov.
Spravovanie agregácií
Na table Údaje v ľubovoľnom zobrazení aplikácie Power BI Desktop kliknite pravým tlačidlom myši na tabuľku agregácií a potom vyberte položku Spravovať agregácie.
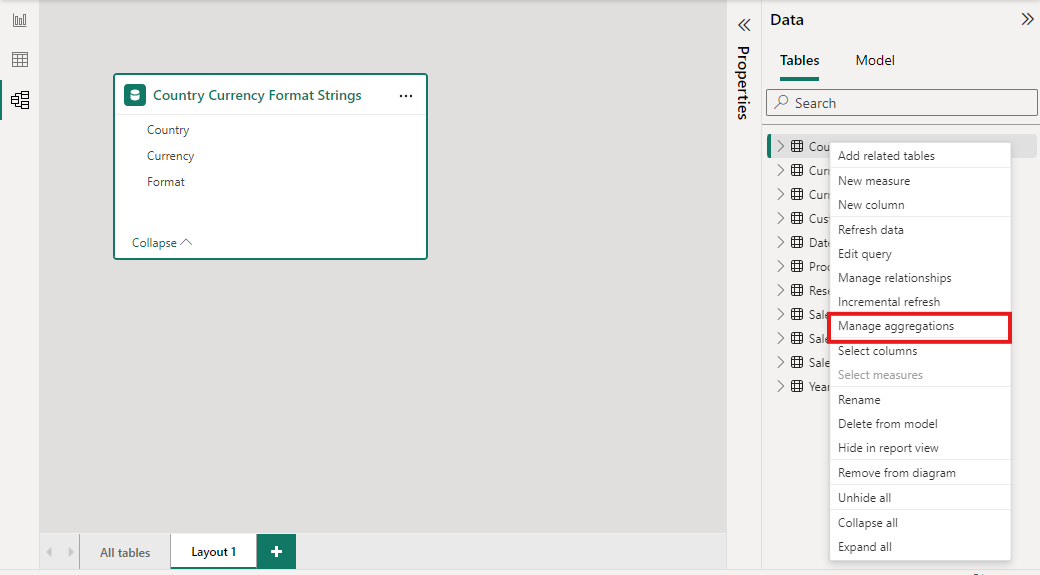
V dialógovom okne Spravovať agregácie sa pre každý stĺpec v tabuľke zobrazí riadok, kde môžete zadať správanie agregácie. V nasledujúcom príklade sa dotazy na tabuľku podrobností Sales (Predaj ) interne presmerujú na tabuľku agregácie Sales Agg (Agregácia predaja).
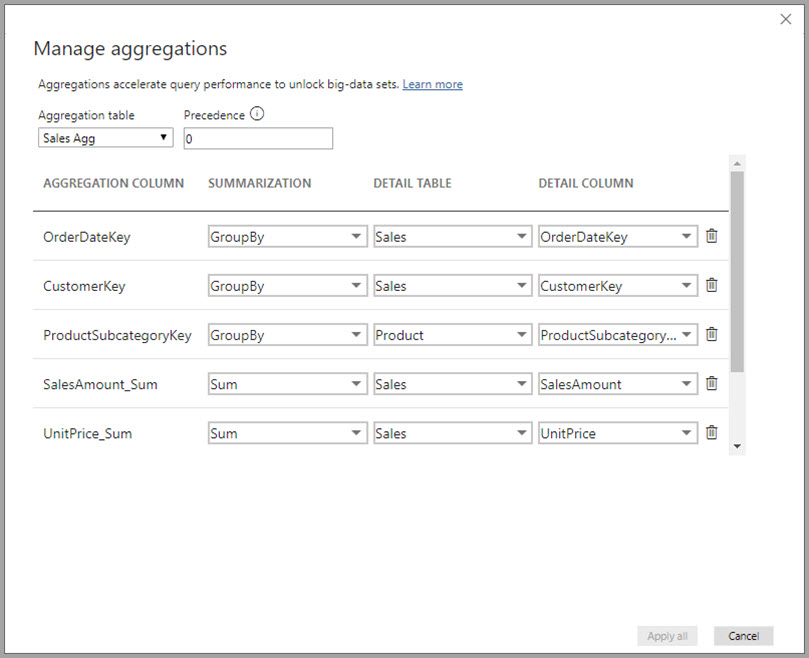
V tomto príklade agregácie založenej na vzťahoch sú položky GroupBy voliteľné. Okrem funkcie DISTINCTCOUNT nemajú vplyv na správanie agregácie a sú primárne určené na účely čitateľnosti. Bez položiek GroupBy by sa agregácie aj tak zasiahli, a to v závislosti od vzťahov. To sa líši od príkladu veľkého objemu údajov ďalej v tomto článku, kde sa položky GroupBy vyžadujú.
Overenia
Dialógové okno Spravovať agregácie vynucuje overenia:
- Typ údajov stĺpca podrobností musí byť rovnaký ako agregačný stĺpec s výnimkou funkcií súhrnu Počet a Počet riadkov tabuľky. Funkcie Počet a Počet riadkov v tabuľke sú dostupné iba pre celočíselné agregačné stĺpce a nevyžadujú zodpovedajúci typ údajov.
- Z reťazcové agregácie týkajúce sa troch alebo viacerých tabuliek nie sú povolené. Agregácie v Tabuľke A napríklad nemôžu odkazovať na Tabuľku B, ktorá má agregácie s odkazom na Tabuľku C.
- Duplicitné agregácie, kde dve položky používajú rovnakú funkciu súhrnu a odkazujú na rovnakú tabuľku podrobností a stĺpec podrobností, nie sú povolené.
- Tabuľka podrobností musí používať režim úložiska režimu DirectQuery, nie Import.
- Zoskupovanie podľa stĺpca cudzieho kľúča používaného neaktívnym vzťahom a spoliehanie sa na funkciu USERELATIONSHIP pre výsledky agregácie sa nepodporuje.
- Agregácie založené na stĺpcoch GroupBy môžu používať vzťahy medzi agregačnými tabuľkami, ale vytváranie vzťahov medzi agregačnými tabuľkami nie je v aplikácii Power BI Desktop podporované. Ak je to potrebné, môžete vytvoriť vzťahy medzi agregačnými tabuľkami pomocou nástroja tretej strany alebo riešenia skriptovania prostredníctvom koncových bodov XML for Analysis (XMLA).
Väčšina overení sa vynúti vypnutím hodnôt rozbaľovacieho zoznamu a zobrazením vysvetľujúceho textu v popise.
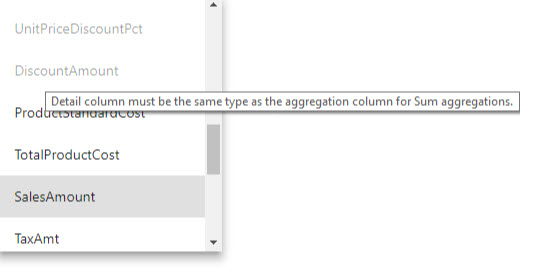
Tabuľky agregácie sú skryté
Používatelia s prístupom iba na čítanie do modelu nemôžu vytvoriť dotaz na agregačné tabuľky. Prístup iba na čítanie zabraňuje bezpečnostným problémom pri použití so zabezpečením na úrovni riadkov (RLS). Používatelia a dotazy odkazujú na tabuľku podrobností, nie na tabuľku agregácie, a nemusia vedieť o tabuľke agregácie.
Z tohto dôvodu sú tabuľky agregácie v zobrazení Zostava skryté. Ak tabuľka ešte nie je skrytá, dialógové okno Spravovať agregácie ju nastaví na skrytú po výbere položky Použiť všetko.
Režimy úložiska
Agregačná funkcia pracuje s režimami úložiska na úrovni tabuľky. Tabuľky služby Power BI môžu používať režimy úložiska DirectQuery, Import alebo Dual . DirectQuery odosiela dotazy priamo na koncový server, zatiaľ čo režim Import ukladá údaje vo vyrovnávacej pamäti a odosiela dotazy do údajov vo vyrovnávacej pamäti. Všetky zdroje údajov importu a nemultenzionálne zdroje DirectQuery služby Power BI dokážu pracovať s agregáciami.
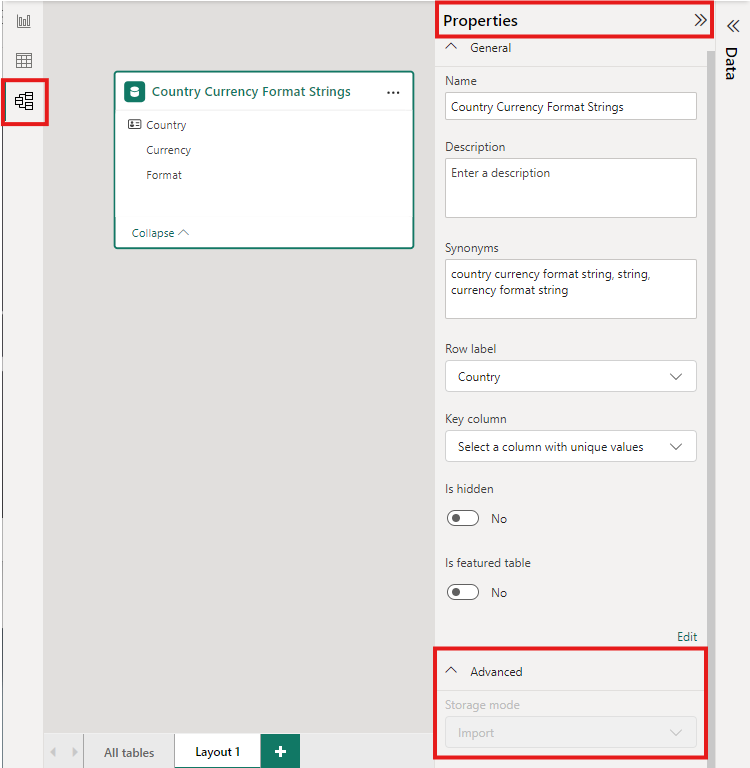
Ak chcete nastaviť režim úložiska agregovanej tabuľky na Import a tak urýchliť dotazy, vyberte agregovanú tabuľku v zobrazení Model aplikácie Power BI Desktop. Na table Vlastnosti rozbaľte položku Rozšírené, rozbaľte ponuku v časti Režim úložiska a vyberte položku Importovať. Zmena importu je nevratná.
Ďalšie informácie o režimoch úložiska tabuliek nájdete v téme Spravovanie režimu úložiska v aplikácii Power BI Desktop.
Zabezpečenie na úrovni riadkov (RLS) pre agregácie
Ak chcete, aby výrazy zabezpečenia na úrovni riadkov (RLS) fungovali pre agregácie správne, mali by filtrovať tabuľku agregácie a tabuľku podrobností.
V nasledujúcom príklade výraz zabezpečenia na úrovni riadkov v tabuľke Geography (Geografia ) funguje pre agregácie, pretože tabuľka Geography (Geografia) sa nachádza na strane filtrovania vzťahov s tabuľkou Sales (Predaj ) a tabuľkou Sales Agg (Agregácia predaja). Dotazy, ktoré zasiahli tabuľku agregácie a dotazy, v ktorých nie je úspešne použité zabezpečenie na úrovni riadkov.
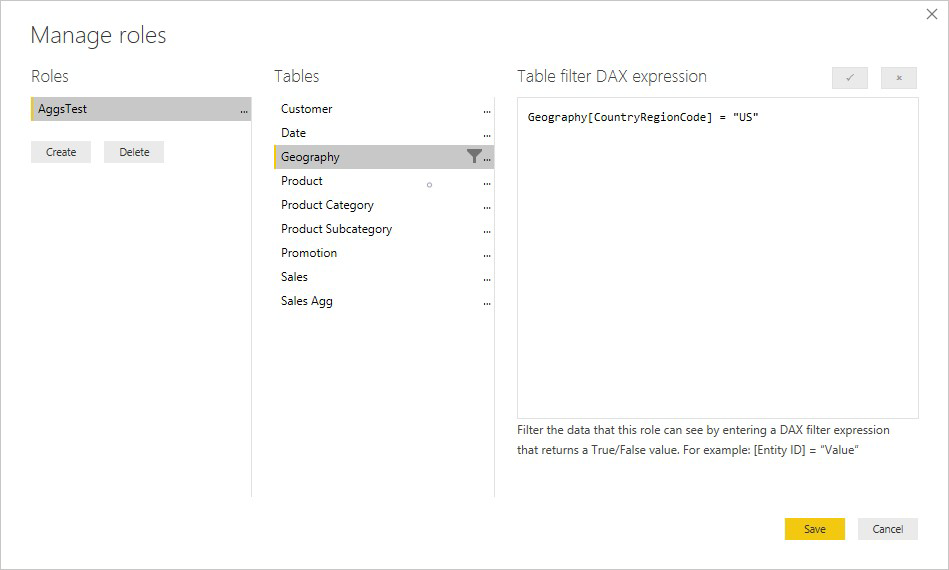
Výraz zabezpečenia na úrovni riadkov v tabuľke Product (Produkt ) filtruje iba tabuľku podrobností Sales (Predaj ), nie agregovanú tabuľku Sales Agg (Agregácia predaja). Keďže agregačná tabuľka je iným zobrazením údajov v tabuľke podrobností, bolo by neisté odpovedať na dotazy z agregačnej tabuľky, ak by sa filter zabezpečenia na úrovni riadkov nedá použiť. Neodporúča sa filtrovať len tabuľku podrobností, pretože dotazy používateľov z tejto roly nemajú prospech z výsledkov agregácie.
Výraz zabezpečenia na úrovni riadkov, ktorý filtruje iba tabuľku agregácie Sales Agg (Agregácia predaja) a nie tabuľku podrobností Sales (Predaj ), nie je povolený.
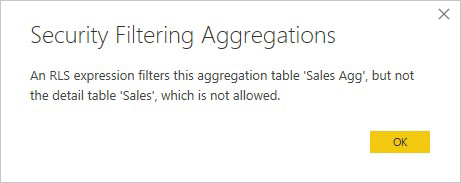
V prípade agregácií založených na stĺpcoch GroupBy je možné výraz zabezpečenia na úrovni riadkov použitý v tabuľke podrobností použiť na filtrovanie tabuľky agregácie, pretože všetky stĺpce GroupBy v tabuľke agregácie sú obsiahnuté v tabuľke podrobností. Na druhej strane, filter zabezpečenia na úrovni riadkov použitý na tabuľku agregácie nie je možné použiť na tabuľku podrobností, takže je zakázaný.
Agregácia na základe vzťahov
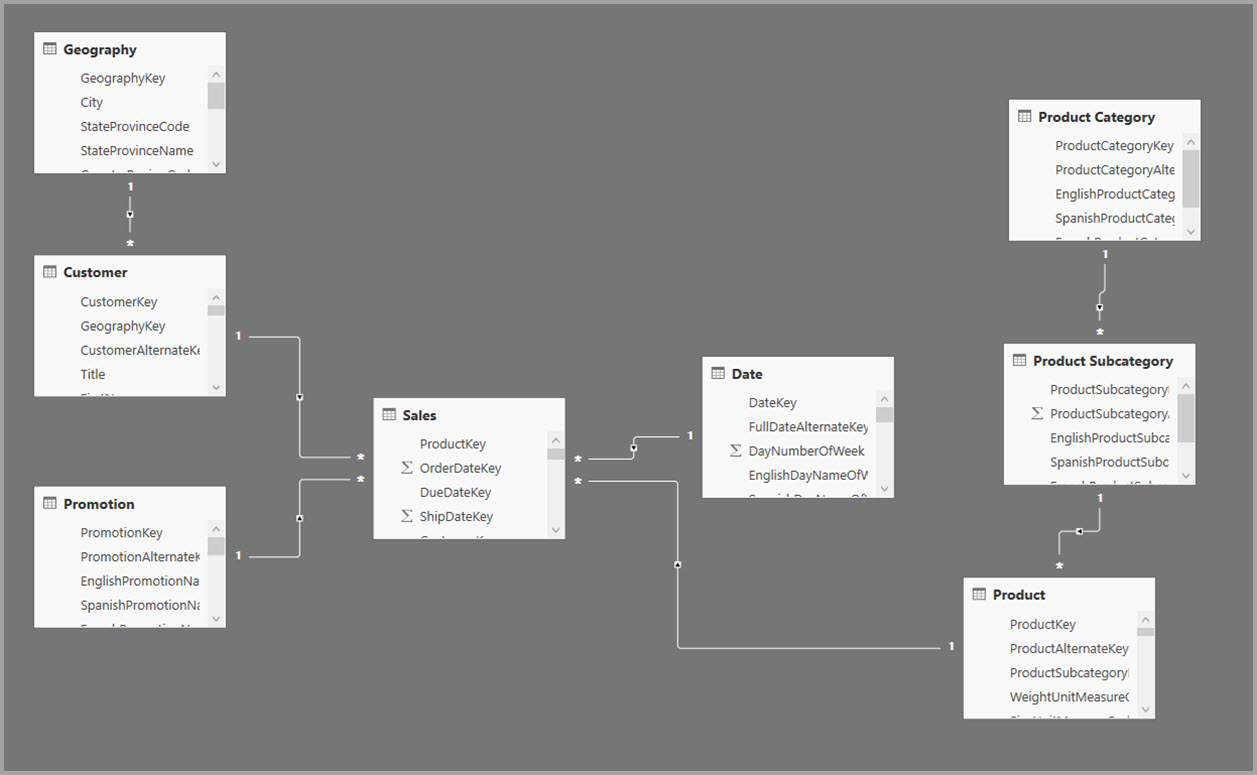
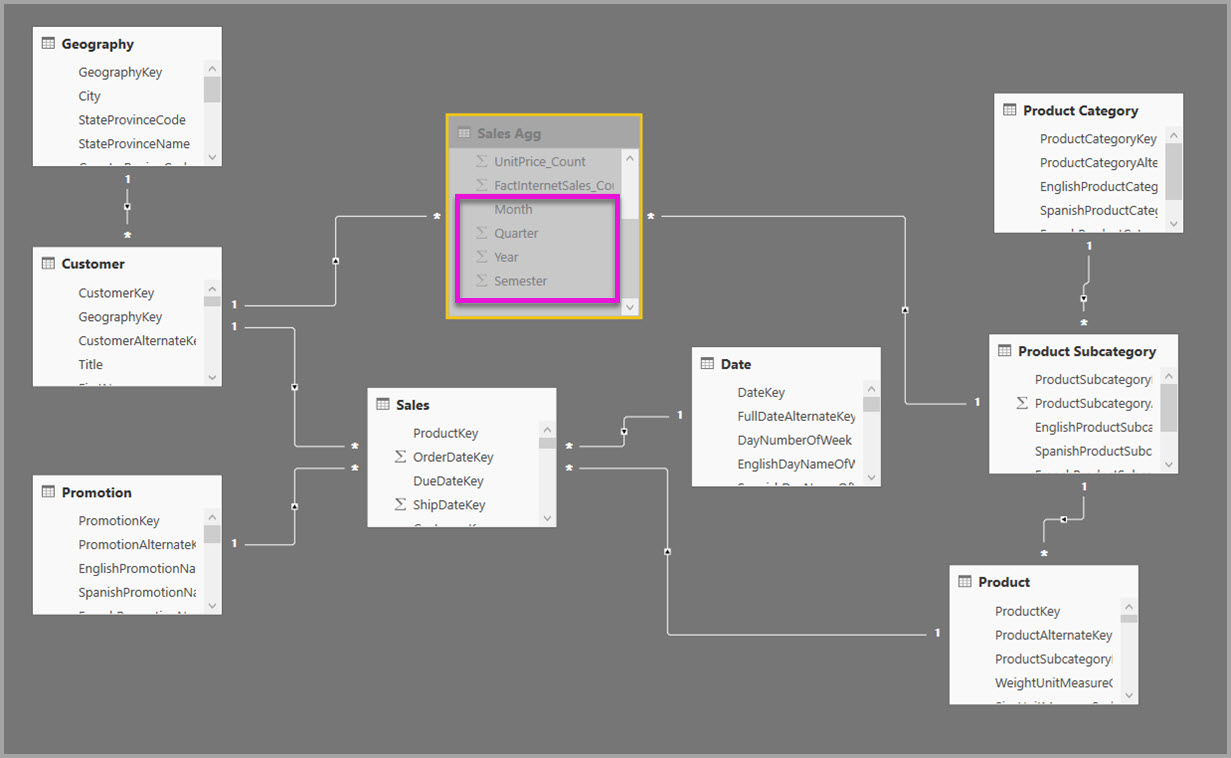
Dimenzionálne modely zvyčajne používajú agregácie na základe vzťahov. Modely služby Power BI zo skladov údajov a trhy údajov pripomínajú schému hviezdy/vločky so vzťahmi medzi tabuľkami dimenzií a tabuľkami faktov.
V nasledujúcom príklade model získa údaje z jedného zdroja údajov. Tabuľky používajú režim úložiska DirectQuery. Tabuľka faktov Sales obsahuje miliardy riadkov. Nastavenie režimu ukladacieho priestoru Sales na Import na ukladanie do vyrovnávacej pamäte by využívalo značný objem pamäte a prostriedkov.
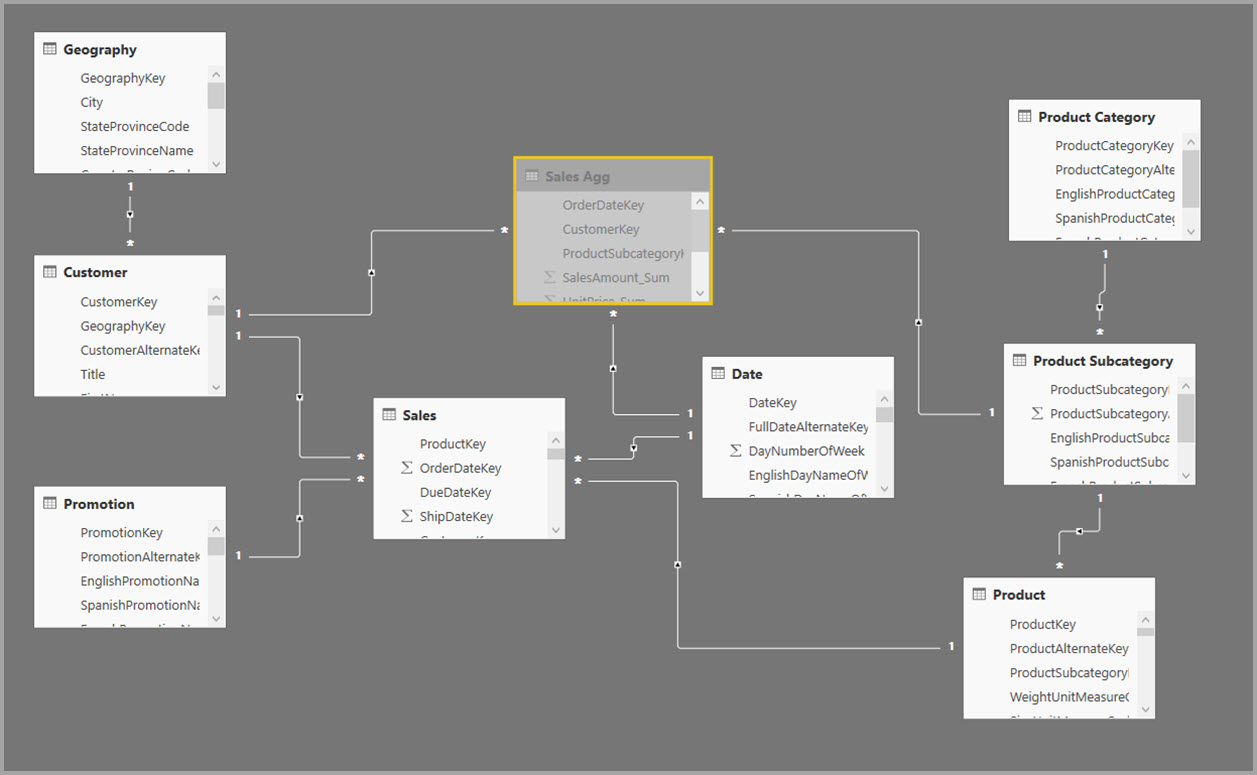
Namiesto toho vytvorte tabuľku agregácie Sales Agg (Agregácia predaja). Počet riadkov v tabuľke Sales Agg (Agregácia predaja) sa rovná súčtu tabuľky SalesAmount (SumaPredaja) zoskupeného podľa kľúčov CustomerKey (KľúčZákazníka), DateKey (KľúčDátumu) a ProductSubcategoryKey (KľúčPodkategórieProduktu). Tabuľka Sales Agg (Agregácia predaja) má vyššiu granularitu než tabuľka Sales (Predaj), takže namiesto miliárd riadkov by mohla obsahovať milióny riadkov, ktoré sa dajú jednoduchšie spravovať.
Ak sa nasledujúce tabuľky dimenzií používajú najčastejšie pre dotazy s vysokou obchodnou hodnotou, môžu filtrovať tabuľku Sales Agg (Agregácia predaja) pomocou vzťahov One-to-many alebo Many-to-one.
- Geografia
- Zákazník
- Date (Dátum)
- Podkategória produktov
- Kategória produktu
Tento model je zobrazený na nasledujúcom obrázku.
V nasledujúcej tabuľke sú zobrazené agregácie pre tabuľku Sales Agg .

Poznámka
Tabuľka Sales Agg (Agregácia predaja), podobne ako iné tabuľky, má flexibilitu načítania rôznymi spôsobmi. Agregácia sa môže vykonávať v zdrojovej databáze pomocou procesov ETL/ELT alebo pomocou výrazu M pre tabuľku. Tabuľka agregácie môže používať režim úložiska Import buď s prírastkovým obnovením pre sémantické modely, alebo bez neho, alebo môže používať režim DirectQuery a optimalizovať sa tak pre rýchle dotazy pomocou indexov columnstore. Táto flexibilita umožňuje vyvážené architektúry, ktoré môžu rozložiť zaťaženie dotazu, aby sa zabránilo kritickým miestam.
Zmenou režimu úložiska tabuľky agregácie Sales Agg (Agregácia predaja) na režim Import sa otvorí dialógové okno s textom, že súvisiace tabuľky dimenzií je možné nastaviť na režim úložiska Dual.
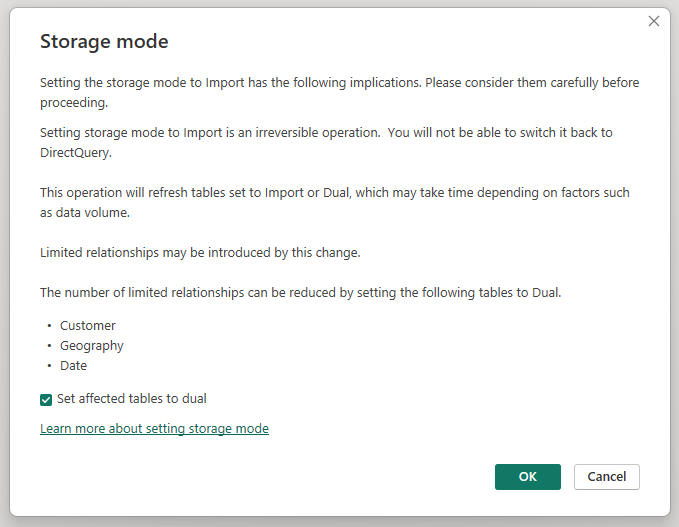
Nastavenie súvisiacich tabuliek dimenzií na režim Dual im umožňuje správať sa ako v režime Import alebo DirectQuery v závislosti od poddotazu. V príklade:
- Dotazy, ktoré agregujú metriky z tabuľky Sales Agg v režime Import, a zoskupujú podľa atribútov zo súvisiacich tabuliek Dual, je možné vrátiť z vyrovnávacej pamäte v pamäti.
- Dotazy, ktoré agregujú metriky z tabuľky Sales v režime DirectQuery, a zoskupujú podľa atribútov zo súvisiacich tabuliek Dual, je možné vrátiť v režime DirectQuery. Logika dotazu vrátane operácie GroupBy sa odovzdáva ďalej do zdrojovej databázy.
Ďalšie informácie o režime úložiska Dual nájdete v téme Spravovanie režimu úložiska v aplikácii Power BI Desktop.
Pravidelné vs. obmedzené vzťahy
Prístupy agregácie na základe vzťahov vyžadujú pravidelné vzťahy.
Pravidelné vzťahy zahŕňajú nasledujúce kombinácie režimov úložiska, kde obe tabuľky pochádzajú z jedného zdroja:
| Tabuľka na stranách many | Tabuľka na strane 1 |
|---|---|
| Dual | Dual |
| Importovať | Importovať alebo Duálne |
| DirectQuery, | DirectQuery alebo Dual |
Vzťah zo krížového zdroja sa považuje za pravidelný len v tom prípade, ak sú obe tabuľky nastavené na typ Import. Vzťahy typu many-to-many sa vždy považujú za obmedzené.
Informácie o prístupoch agregácie zo krížového zdroja , ktoré nie sú závislé od vzťahov, nájdete v téme Agregácie založené na stĺpcoch GroupBy.
Príklady dotazov agregácie založených na vzťahoch
Nasledujúci dotaz zachytí agregáciu, pretože stĺpce v tabuľke Date majú granularitu, ktorá dokážete agregáciu zasiahnuť. Stĺpec SalesAmount (SumaPredaja) používa agregáciu Sum.

Nasledujúci dotaz agregáciu nezachytí. Napriek vyžiadaniu súčtu stĺpca SalesAmount (SumaPredaja) dotaz vykonáva operáciu GroupBy na stĺpci v tabuľke Product (Produkt ), ktorá nemá granularitu umožňujúcu zasiahnuť agregáciu. Ak dodržíte vzťahy v modeli, podkategória produktov môže mať viacero riadkov Product (Produkt ). Dotaz by nebol schopný určiť, ktorý produkt sa má agregovať. V tomto prípade sa dotaz vráti do režimu DirectQuery a odošle dotaz SQL do zdroja údajov.

Agregácie nie sú len pre jednoduché výpočty, ktoré vykonávajú jednoduchý súčet. Môžu sa využiť aj pri zložitých výpočtoch. Koncepčne sa zložitý výpočet rozdeľuje do poddotazov pre každú funkciu SUM, MIN, MAX a COUNT. Každý poddotaz sa vyhodnotí a určí, či dokáže agregáciu zasiahnuť. Táto logika nie je vo všetkých prípadoch pravdivá z dôvodu optimalizácie plánu dotazu, ale vo všeobecnosti by mala platiť. Tento príklad agregáciu zachytí:

Funkcia COUNTROWS môže využívať agregácie. Nasledujúci dotaz zachytí agregáciu, pretože pre tabuľku Sales je určená agregácia riadkov tabuľky Count.

Funkcia AVERAGE môže využívať agregácie. Nasledujúci dotaz zachytí agregáciu, pretože funkcia AVERAGE sa interne včlení do funkcie SUM vydelenej funkciou COUNT. Keďže stĺpec UnitPrice má agregácie definované pre funkcie SUM aj COUNT, agregácia sa zachytí.

V niektorých prípadoch funkcia DISTINCTCOUNT môže využívať agregácie. Nasledujúci dotaz zachytí agregáciu, pretože pre CustomerKey existuje položka Zoskupovať podľa, ktorá zachová odlišnosti CustomerKey v tabuľke agregácie. Tento postup môže stále dosiahnuť prah výkonu, kde výkon dotazu môže ovplyvniť viac ako dva až päť miliónov jedinečných hodnôt. Môže to však byť užitočné v prípadoch, kde existujú miliardy riadkov v tabuľke podrobností, no dva až päť miliónov jedinečných hodnôt v stĺpci. V tomto prípade sa funkcia DISTINCTCOUNT môže vykonávať rýchlejšie než prehľadávanie tabuľky s miliardami riadkov, dokonca aj vtedy, ak boli uložené vo vyrovnávacej pamäti.

Funkcie časovej inteligencie jazyka Data Analysis Expressions (DAX) podporujú agregácie. Nasledujúci dotaz zachytí agregáciu, pretože funkcia DATESYTD vygeneruje hodnoty tabuľky CalendarDay a agregačná tabuľka má granularitu, ktorá je pokrytá pre stĺpce zoskupenia v tabuľke Date . Toto je príklad filtra s hodnotami z tabuliek na funkciu CALCULATE, ktorá môže pracovať s agregáciami.

Agregácia založená na stĺpcoch GroupBy
Modely založené na veľkých objemoch údajov Hadoop majú odlišné vlastnosti ako rozmerové modely. Ak sa chcete vyhnúť spojeniam medzi veľkými tabuľkami, dátové modely s veľkým objemom údajov často nepoužívajú vzťahy, ale denormalizujú atribúty dimenzií na tabuľky faktov. Takéto veľké dátové modely môžete odblokovať na interaktívnu analýzu pomocou agregácií založených na stĺpcoch GroupBy.
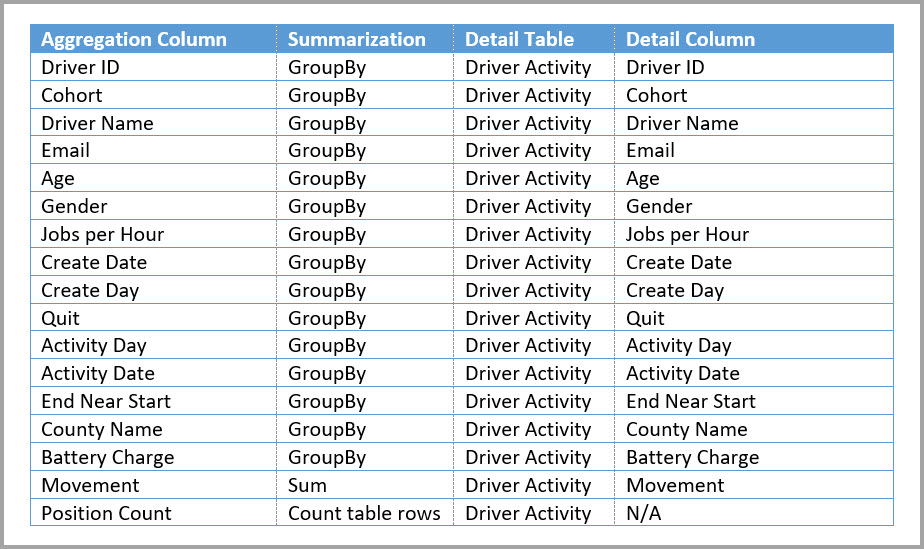
Nasledujúca tabuľka obsahuje číselný stĺpec Movement , ktorý sa má agregovať. Všetky ostatné stĺpce sú atribúty, podľa ktorých sa má zoskupiť. Tabuľka obsahuje údaje IoT a obrovský počet riadkov. Režim úložiska je DirectQuery. Dotazy na zdroj údajov, ktoré sa agregujú v celom modeli, sú pomalé z dôvodu pomalého objemu.
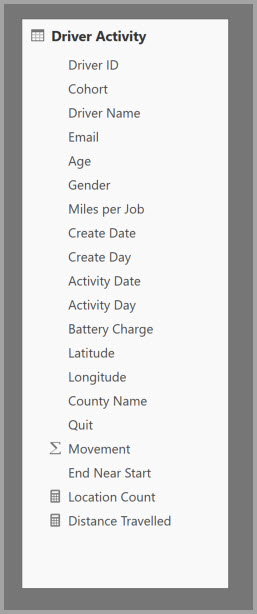
Ak chcete povoliť interaktívnu analýzu tohto modelu, môžete pridať tabuľku agregácie, ktorá zoskupuje väčšinu atribútov, ale vylučuje atribúty s vysokou kardinalitou ako zemepisnú šírku a dĺžku. Týmto sa výrazne zníži počet riadkov a tento počet je dostatočne malý na to, aby sa pohodlne zmestili do vyrovnávacej pamäte v pamäti.
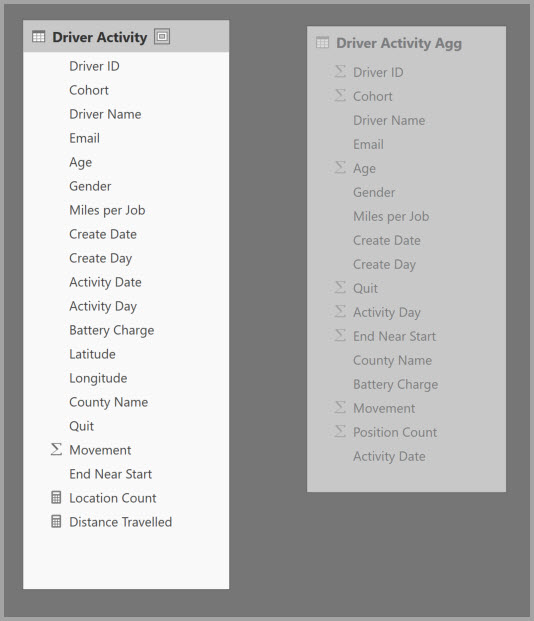
Mapovanie agregácie pre tabuľku Driver Activity Agg môžete definovať v dialógovom okne Spravovať agregácie .
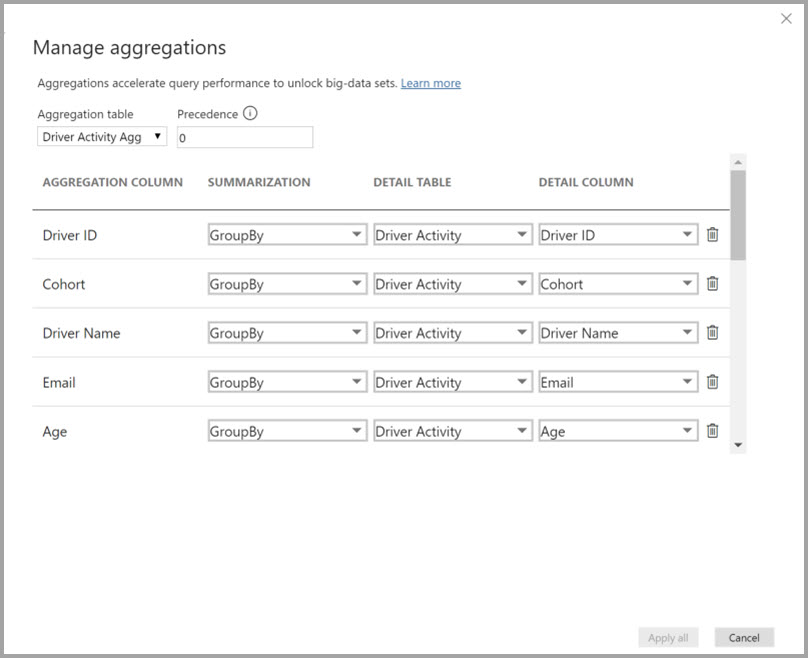
V agregáciách založených na stĺpcoch GroupBy nie sú položky GroupBy voliteľné. Bez nich by sa agregácie nezachytí. To sa líši od používania agregácií na základe vzťahov, kde sú položky GroupBy voliteľné.
V nasledujúcej tabuľke sú zobrazené agregácie pre tabuľku Driver Activity Agg .
Režim úložiska tabuľky agregácie Driver Activity Agg (Agregácia aktivít vodiča) môžete nastaviť na Import.
Príklad dotazu agregácie GroupBy
Tento dotaz zachytí agregáciu, pretože stĺpec Activity Date je pokrytý tabuľkou agregácie. Funkcia COUNTROWS používa agregáciu Spočítané riadky tabuľky.

Najmä pre modely, ktoré obsahujú atribúty filtra v tabuľkách faktov, je vhodné použiť agregácie riadkov tabuľky Count. Služba Power BI môže odoslať dotazy do modelu pomocou funkcie COUNTROWS v prípadoch, keď o to používateľ výslovne nežiada. Napríklad dialógové okno filtrov zobrazuje počet riadkov pre každú hodnotu.
Techniky kombinovania agregácie
V prípade agregácií môžete kombinovať techniky vzťahov a stĺpcov GroupBy. Agregácie založené na vzťahoch môžu vyžadovať, aby sa denormalizované tabuľky dimenzií rozdelili do viacerých tabuliek. Ak je to pre určité tabuľky dimenzií nákladné alebo nepraktické, potrebné atribúty môžete pre dané dimenzie replikovať v tabuľke agregácie a v prípade ostatných použiť vzťahy.
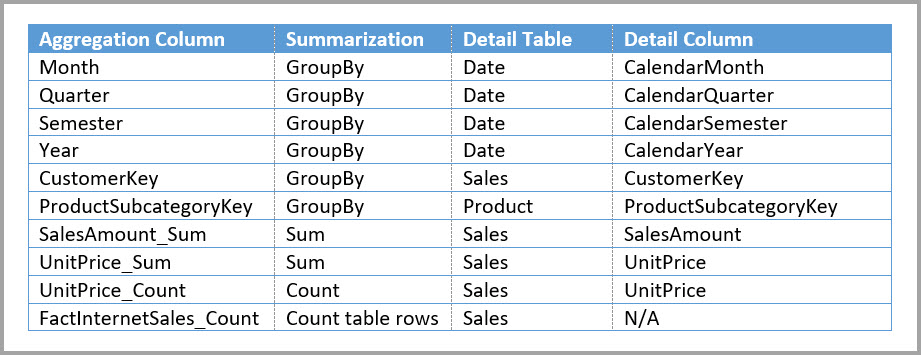
Nasledujúci model napríklad replikuje stĺpce Month (Mesiac), Quarter (Štvrťrok), Semester (Polrok) a Year (Rok) v tabuľke Sales Agg (Agregácia predaja). Medzi tabuľkou Sales Agg (Agregácia predaja) a Date (Dátum) neexistuje žiadny vzťah, ale medzi tabuľkou Customer (Zákazník) a Product Subcategory (Podkategória produktu) existujú vzťahy. Režim ukladacieho priestoru tabuľky Sales Agg je Import.
Nasledujúca tabuľka zobrazuje položky nastavené v dialógovom okne Spravovať agregácie pre tabuľku Sales Agg . Položky Zoskupiť podľa, pri ktorých je Date tabuľkou podrobností, musia zasiahnuť agregácie pre dotazy, ktoré sa zoskupujú podľa atribútov dátumu. Rovnako ako v predchádzajúcom príklade položky Zoskupiť podľa pre CustomerKey a ProductSubcategoryKey nemajú vplyv na prístupy agregácie, s výnimkou DISTINCTCOUNT, z dôvodu výskytu vzťahov.
Príklady dotazov kombinovanej agregácie
Nasledujúci dotaz zachytí agregáciu, pretože tabuľka agregácie zahŕňa položku CalendarMonth (KalendárnyMesiac), pričom položka CategoryName (NázovKategórie ) je prístupná prostredníctvom vzťahov One-to-many. SalesAmount (ObjemPredaja) používa agregáciu SUM.

Tento dotaz agregáciu nezachytí, pretože tabuľka agregácie nezahŕňa položku CalendarDay (KalendárnyDeň).

Nasledujúci dotaz časovej inteligencie agregáciu nezachytí, pretože funkcia DATESYTD vygeneruje tabuľku hodnôt CalendarDay (KalendárnyDeň ) a tabuľka agregácie nezahŕňa položku CalendarDay (KalendárnyDeň).

Priorita agregácie
Priorita agregácie umožňuje, aby jediný poddotaz posudzovať viaceré tabuľky agregácie.
V nasledujúcom príklade je zložený model , ktorý obsahuje viacero zdrojov:
- Tabuľka Driver Activity DirectQuery obsahuje viac ako jeden bilión riadkov s údajmi IoT, ktoré pochádzajú zo systému spracovania veľkého objemu údajov. Slúži podrobnej analýze dotazov na zobrazenie jednotlivých údajov IoT v kontextoch riadeného filtra.
- Tabuľka Driver Activity Agg je sprostredkú čiastková tabuľka agregácie v režime DirectQuery. Obsahuje viac ako miliardu riadkov v Azure Synapse Analytics (predtým SQL Data Warehouse) a je optimalizovaná na zdroji pomocou indexov columnstore.
- Tabuľka Import Driver Activity Agg2 má vysokú granularitu, pretože atribútov zoskupenia je málo a majú nízku kardinalitu. Počet riadkov môže byť nízky, teda v tisícoch, takže sa môžete jednoducho zmestiť do vyrovnávacej pamäte v pamäti. Tieto atribúty používajú výkonné tabule s vysokým profilom, takže dotazy, ktoré na ne odkazujú, by mali byť čo najrýchlejšie.
Poznámka
Agregačné tabuľky DirectQuery, ktoré používajú iný zdroj údajov ako tabuľka podrobností, sa podporujú iba v prípade, že agregačná tabuľka je zo zdroja servera SQL Server, Azure SQL alebo Azure Synapse Analytics (predtým SQL Data Warehouse).
Nároky na pamäť tohto modelu sú relatívne malé, odhaľuje však obrovský model. Predstavuje vyváženú architektúru, pretože rozkladá zaťaženie dotazu v rámci komponentov architektúry s ich využitím na základe ich silných stránok.
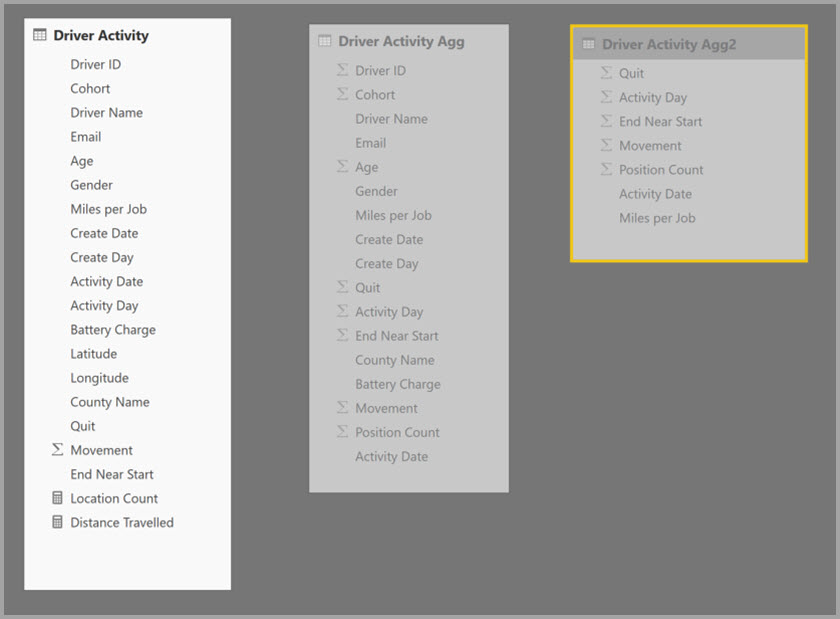
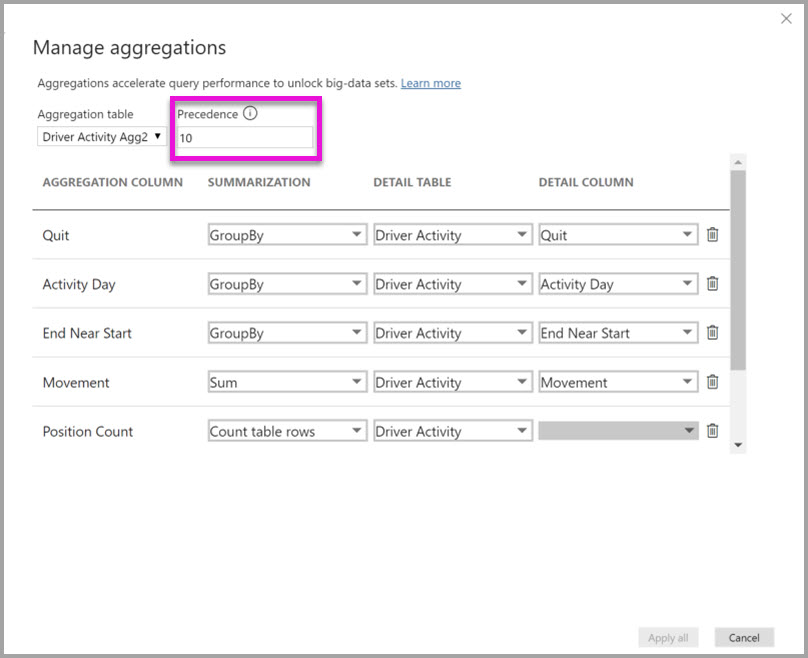
Dialógové okno Spravované agregácie pre Driver Activity Agg2 (Agregácia aktivít vodiča2) nastaví pole Priorita na hodnotu 10, čo je vyššia hodnota ako pre driver activity Agg (Agregácia aktivít vodiča). Nastavenie vyššej priority znamená, že dotazy, ktoré používajú agregácie, najskôr zvážia Driver Activity Agg2 (Agregácia aktivít vodiča2 ). Poddotazy, ktoré nemajú granularitu, ktorú môže zodpovedať Driver Activity Agg2 (Agregácia aktivít vodiča2 ), môžu namiesto toho zvážiť Driver Activity Agg (Agregácia aktivít vodiča). Podrobné dotazy, ktoré sa nedajú zodpovedať v žiadnej tabuľke agregácie, môžu smerovať na Driver Activity.
Tabuľka určená v stĺpci Detail Table (Tabuľka podrobností) je Driver Activity (Aktivita vodiča) a nie Driver Activity Agg (Agregácia aktivít vodiča), pretože z reťazcové agregácie nie sú povolené.
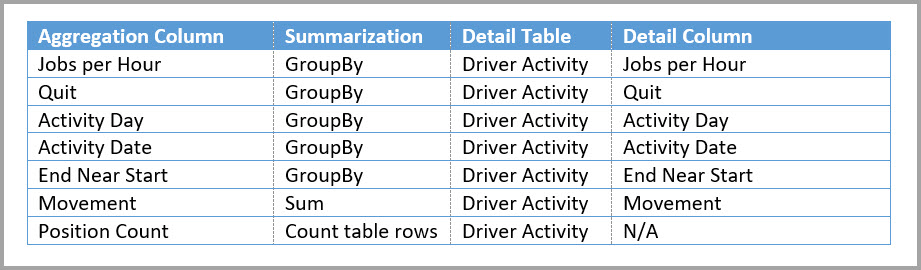
V nasledujúcej tabuľke sú zobrazené agregácie pre tabuľku Driver Activity Agg2 .
Zistenie, či dotazy zasiahli alebo nezasiahli agregácie
Nástroj SQL Profiler dokáže zistiť, či sa dotazy vracajú z nástroja úložiska vyrovnávacej pamäte v pamäti alebo sa presúvajú do zdroja údajov pomocou režimu DirectQuery. Ten istý proces môžete použiť aj na zistenie toho, či sa agregácie práve zasahujú. Ďalšie informácie nájdete v téme Dotazy, ktoré majú alebo nezasiahli vyrovnávaciu pamäť.
Nástroj SQL Profiler tiež poskytuje rozšírenú Query Processing\Aggregate Table Rewrite Query udalosť.
Nasledujúci zlomok JSON ukazuje príklad výstupu udalosti, keď sa používa agregácia.
- matchingResult ukazuje, že poddotaz použil agregáciu.
- dataRequest zobrazuje stĺpce GroupBy a agregované stĺpce, ktoré poddotaz použil,
- mapovanie zobrazuje stĺpce v tabuľke agregácie, ktoré boli namapované.

Synchronizácia vyrovnávacej pamäte
Agregácie, ktoré kombinujú režimy úložiska DirectQuery, Import alebo Dual, môžu vrátiť rôzne údaje, pokiaľ je vyrovnávacia pamäť v pamäti synchronizovaná so zdrojom údajov. Spustenie dotazu sa napríklad nepokúsi prekryť problémy údajov filtrovaním výsledkov režimu DirectQuery tak, aby sa zhodovali s hodnotami vyrovnávacej pamäte. Existujú zavedené techniky na riešenie takýchto problémov už od začiatku, ak je to potrebné. Optimalizácie výkonu by sa mali používať iba spôsobmi, ktoré neohrozujú vašu schopnosť spĺňať obchodné požiadavky. Vašou zodpovednosťou je poznať svoje toky údajov a podľa toho ich navrhovať.
Dôležité informácie a obmedzenia
Agregácie nepodporujú dynamické parametre dotazu jazyka M.
Od augusta 2022, kvôli zmenám vo funkciách, Power BI ignoruje agregačné tabuľky režimu importu pomocou zdrojov údajov s jediným prihlásením (SSO) z dôvodu možných rizík zabezpečenia. Ak chcete zabezpečiť optimálny výkon dotazu s agregáciami, odporúča sa pre tieto zdroje údajov zakázať jediné prihlásenie.
Komunita
Power BI je pulzujúca komunita, v ktorej poslanci, profesionáli v oblasti BI a rovesníci zdieľajú odborné znalosti v diskusných skupinách, videách, blogoch a ďalších. Pri učení sa o agregáciách si nezabudnite pozrieť tieto dodatočné zdroje:
Súvisiaci obsah
Pripomienky
Pripravujeme: V priebehu roka 2024 postupne zrušíme službu Problémy v službe GitHub ako mechanizmus pripomienok týkajúcich sa obsahu a nahradíme ju novým systémom pripomienok. Ďalšie informácie nájdete na stránke: https://aka.ms/ContentUserFeedback.
Odoslať a zobraziť pripomienky pre