Hodnoty klastra
Hodnoty klastra automaticky vytvoria skupiny s podobnými hodnotami pomocou približnej zhodného algoritmu a potom primapujú hodnoty každého stĺpca k najlepšie zladenej skupine. Táto transformácia je veľmi užitočná pri práci s údajmi s mnohými rôznymi variáciami rovnakej hodnoty a potrebujete hodnoty skombinovať do konzistentných skupín.
Predstavte si ukážkovú tabuľku so stĺpcom id , ktorý obsahuje množinu id a stĺpec Person (Osoba ) obsahujúci množinu rozličných hláskovaných a veľkých písmen mien Miguel, Mike, William a Bill.
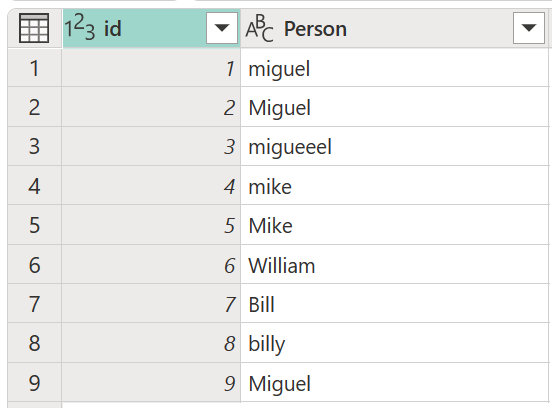
Výsledok, ktorý v tomto príklade hľadáte, je tabuľka s novým stĺpcom zobrazujúca správne skupiny hodnôt zo stĺpca Osoba a nie všetky odlišné variácie rovnakých slov.
Poznámka
Funkcia Hodnoty klastra je k dispozícii len pre Power Query Online.
Vytvorenie stĺpca klastra
Ak chcete hodnoty klastra, najprv vyberte stĺpec Osoba , na páse s nástrojmi prejdite na kartu Pridať stĺpec a potom vyberte možnosť Hodnoty klastra.
![]()
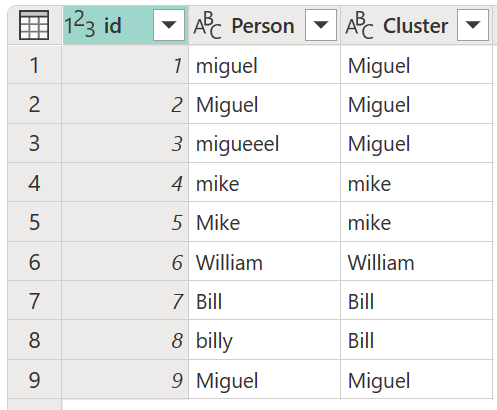
V dialógovom okne Hodnoty klastra potvrďte stĺpec, z ktorému chcete vytvoriť klastre, a zadajte nový názov stĺpca. V tomto prípade pomenujte tento nový stĺpec Cluster.
Výsledok tejto operácie vráti výsledok zobrazený na nasledujúcom obrázku.
Poznámka
Pre každý klaster hodnôt vyberie Power Query najčastejšie inštanciu z vybratého stĺpca ako "kanonickú" inštanciu. Ak sa vyskytujú viaceré inštancie s rovnakou frekvenciou, Power Query vyberie prvú inštanciu.
Použitie možností približného klastra
Pre hodnoty klastrovania v novom stĺpci sú k dispozícii nasledujúce možnosti:
- Prahová hodnota podobnosti (voliteľné): Táto možnosť označuje, ako musia byť podobné dve hodnoty zoskupené. Minimálnym nastavením hodnoty 0 sa zoskupia všetky hodnoty. Maximálne nastavenie 1 umožňuje zoskupiť hodnoty, ktoré sa presne zhodujú. Predvolená hodnota je 0,8.
- Ignorovať malé a veľké písmená: Pri porovnávaní textových reťazcov sa veľké a malé písmená ignorujú. Táto možnosť je predvolene zapnutá.
- Zoskupenie skombinovaním častí textu: Algoritmus sa snaží skombinovať textové časti (ako napríklad kombináciu mikro a mäkkej do spoločnosti Microsoft) a zoskupiť hodnoty.
- Zobraziť skóre podobnosti: zobrazí skóre podobnosti medzi vstupnými hodnotami a vypočítavaným reprezentatívnymi hodnotami po približnom klastrovaní.
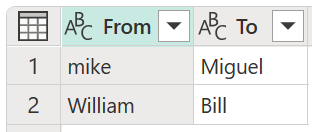
- Tabuľka transformácie (voliteľné): Môžete vybrať tabuľku transformácie, ktorá mapuje hodnoty (napríklad mapovanie MSFT do spoločnosti Microsoft) a zoskupí ich.
V tomto príklade sa na znázornenie spôsobu mapovania hodnôt použije nová tabuľka transformácie s názvom Moja tabuľka transformácie. Táto tabuľka transformácie má dva stĺpce:
- Od: Textový reťazec, ktorý sa má vyhľadať v tabuľke.
- Ak chcete: Textový reťazec, ktorý sa má použiť na nahradenie textového reťazca v stĺpci Od .
Dôležité
Je dôležité, aby mala tabuľka transformácií rovnaké názvy stĺpcov a stĺpcov ako na predchádzajúcom obrázku (musia mať názov "Od" a "Do"), v opačnom prípade Power Query túto tabuľku nerozpozná ako tabuľku transformácie a nedôjde k žiadnemu transformácii.
Pomocou predtým vytvoreného dotazu dvakrát kliknite na krok Skupinové hodnoty a potom v dialógovom okne Hodnoty klastra rozbaľte možnosti klastra Fuzzy. V časti Možnosti klastra Približné povoľte možnosť Zobraziť skóre podobnosti. V časti Tabuľka transformácie (voliteľné) vyberte dotaz obsahujúci tabuľku transformácie.
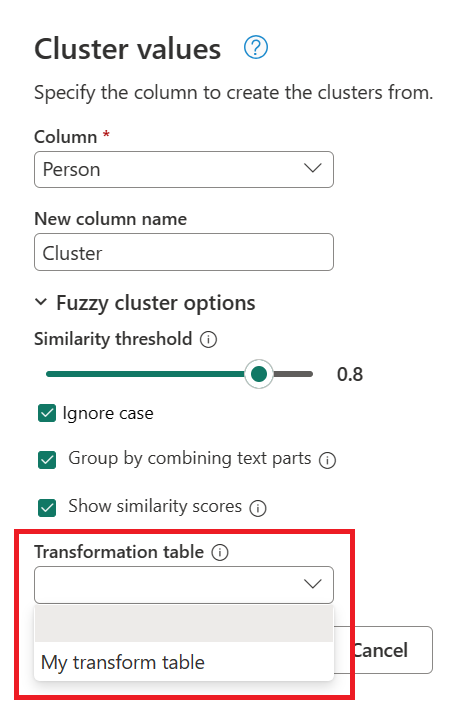
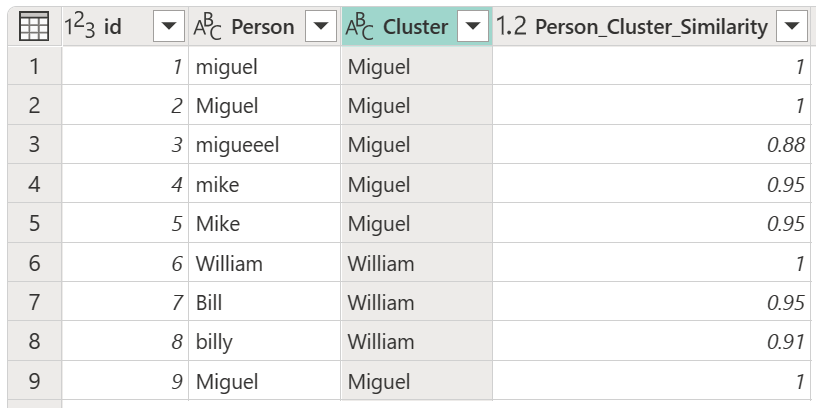
Po výbere tabuľky transformácie a povolení možnosti Zobraziť skóre podobnosti vyberte položku OK. Výsledkom tejto operácie bude tabuľka, ktorá obsahuje rovnaké ID a stĺpce Osoba ako pôvodná tabuľka, ale obsahuje aj dva nové stĺpce na pravej strane s názvom Klaster a Person_Cluster_Similarity. Stĺpec Cluster obsahuje správne napísané a veľké písmená mien Miguel pre verzie Miguel a Mike, a William pre verzie Bill, Billy a William. Stĺpec Person_Cluster_Similarity obsahuje skóre podobnosti pre každý z názvov.
Pripomienky
Pripravujeme: V priebehu roka 2024 postupne zrušíme službu Problémy v službe GitHub ako mechanizmus pripomienok týkajúcich sa obsahu a nahradíme ju novým systémom pripomienok. Ďalšie informácie nájdete na stránke: https://aka.ms/ContentUserFeedback.
Odoslať a zobraziť pripomienky pre