Najvhodnejšie postupy pri vytváraní dimenzionálneho modelu pomocou tokov údajov
Navrhovanie dimenzionálneho modelu je jednou z najčastejších úloh, ktoré môžete s tokom údajov vykonávať. V tomto článku sa zvýrazňujú niektoré z najlepších postupov pri vytváraní dimenzionálneho modelu pomocou toku údajov.
Pracovná pracovná toky údajov
Jedným z kľúčových bodov v každom systéme integrácie údajov je zníženie počtu prečítaných bodov zo zdrojového operačného systému. V tradičnej architektúre integrácie údajov sa toto zníženie vykoná vytvorením novej databázy, ktorá sa nazýva pracovná databáza. Účelom vnášanej databázy je načítať údaje zo zdroja údajov do vnášanej databázy pravidelne.
Zvyšok integrácie údajov potom použije fázovú databázu ako zdroj na ďalšiu transformáciu a skonvertuje ju na štruktúru dimenzionálneho modelu.
Odporúčame, aby ste postup mali rovnaký postup pri používaní tokov údajov. Vytvorenie množiny tokov údajov, ktoré zodpovedajú len za načítanie údajov zo zdrojového systému (a iba za tabuľky, ktoré potrebujete). Výsledok sa potom uloží do štruktúry úložiska toku údajov (buď Azure Data Lake Storage, alebo Dataverse). Táto zmena zabezpečí, že operácia čítania zo zdrojového systému je minimálna.
V ďalšom kroku môžete vytvoriť ďalšie toky údajov, ktoré získavajú ich údaje z pracovnej verzie tokov údajov. Medzi výhody tohto prístupu patria:
- Zníži počet operácií čítania zo zdrojového systému a zníži zaťaženie zdrojového systému.
- Zníženie zaťaženia brán údajov pri použití lokálneho zdroja údajov.
- Vytvorenie priebežnej kópie údajov na účely zosúladenia v prípade zmien zdrojových systémových údajov.
- Vytvorenie zdrojového zdroja transformácie tokov údajov.
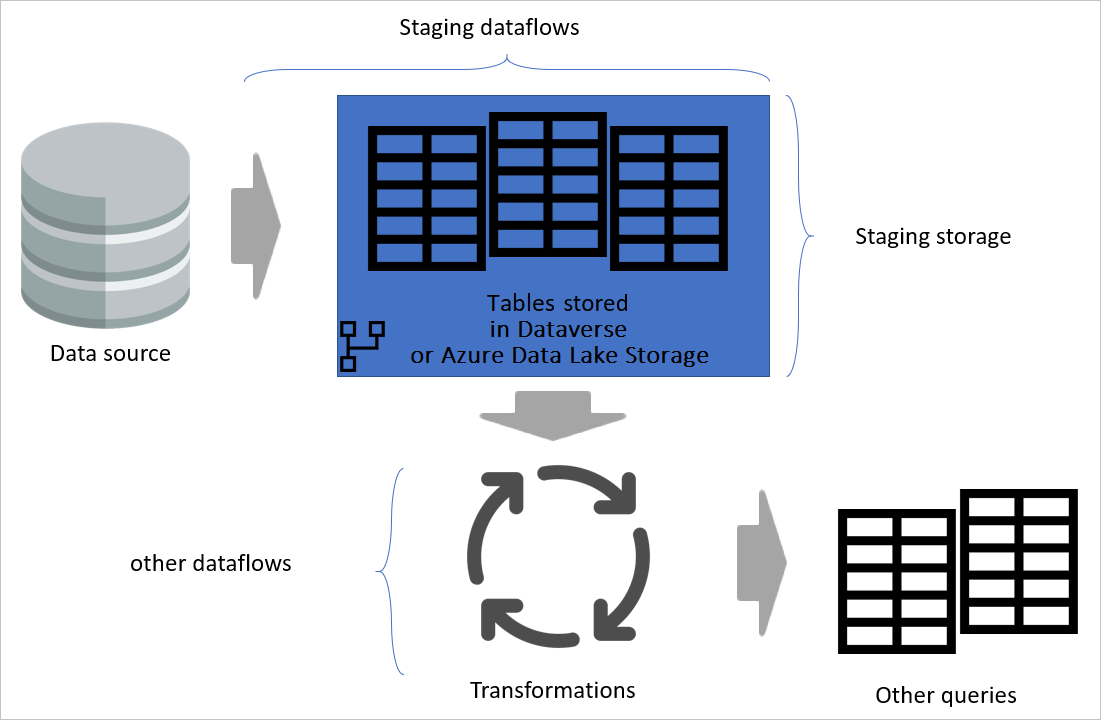
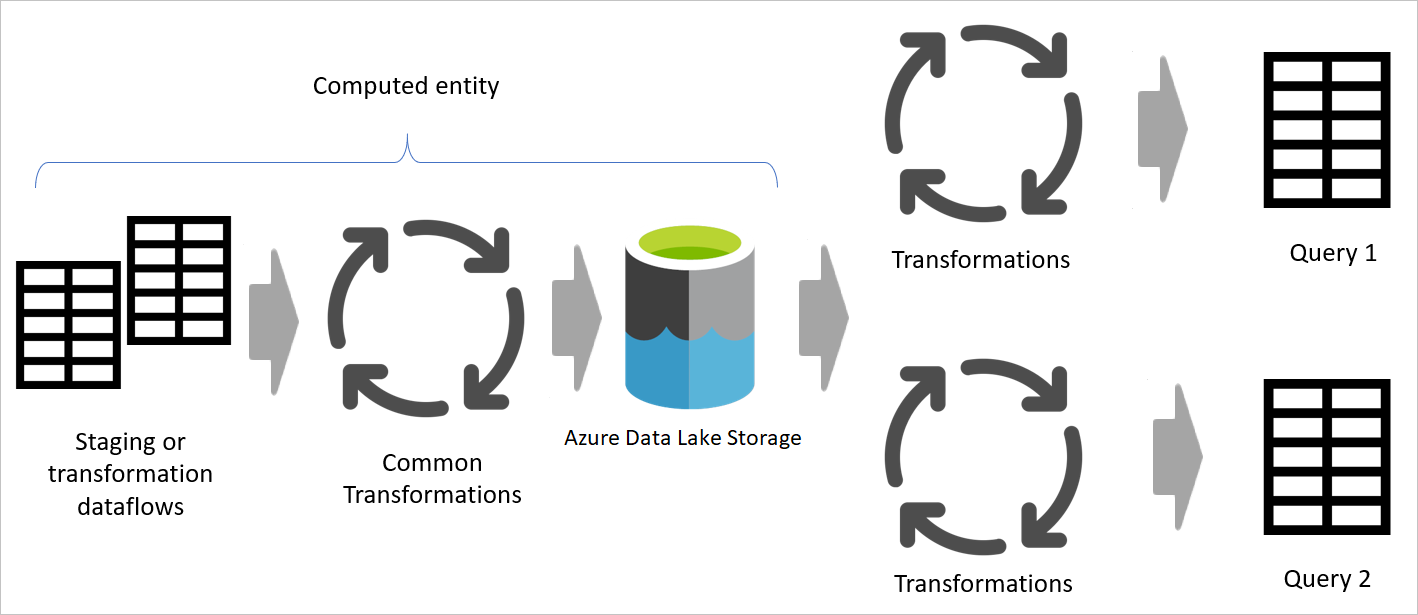
Obrázok s dôrazom na fázovanie tokov údajov a fázovanie úložiska a znázorňujúce údaje, ktoré sú prístupné zo zdroja údajov fázovaným tokom údajov, a tabuľky uložené v cadavers alebo Azure Data Lake Storage. Zobrazí sa transformácia tabuliek spolu s inými tokmi údajov, ktoré sa potom odosielajú ako dotazy.
Transformácia tokov údajov
Keď ste oddelili svoje transformačné toky údajov od fázových tokov údajov, transformácia bude od zdroja nezávislá. Toto oddelenie pomáha vtedy, keď migrujete zdrojový systém do nového systému. V takom prípade stačí zmeniť fázové toky údajov. Toky údajov transformácie budú pravdepodobne fungovať bez problémov, pretože pochádzajú len z pracovných tokov údajov.
Toto oddelenie pomáha aj v prípade, že zdrojové systémové pripojenie je pomalé. Tok údajov transformácie nebude musieť dlho čakať, kým sa budú načítavať záznamy, ktoré prechádzajú pomalým pripojením zo zdrojového systému. Fázový tok údajov už urobil túto časť a údaje budú pripravené na vrstvu transformácie.
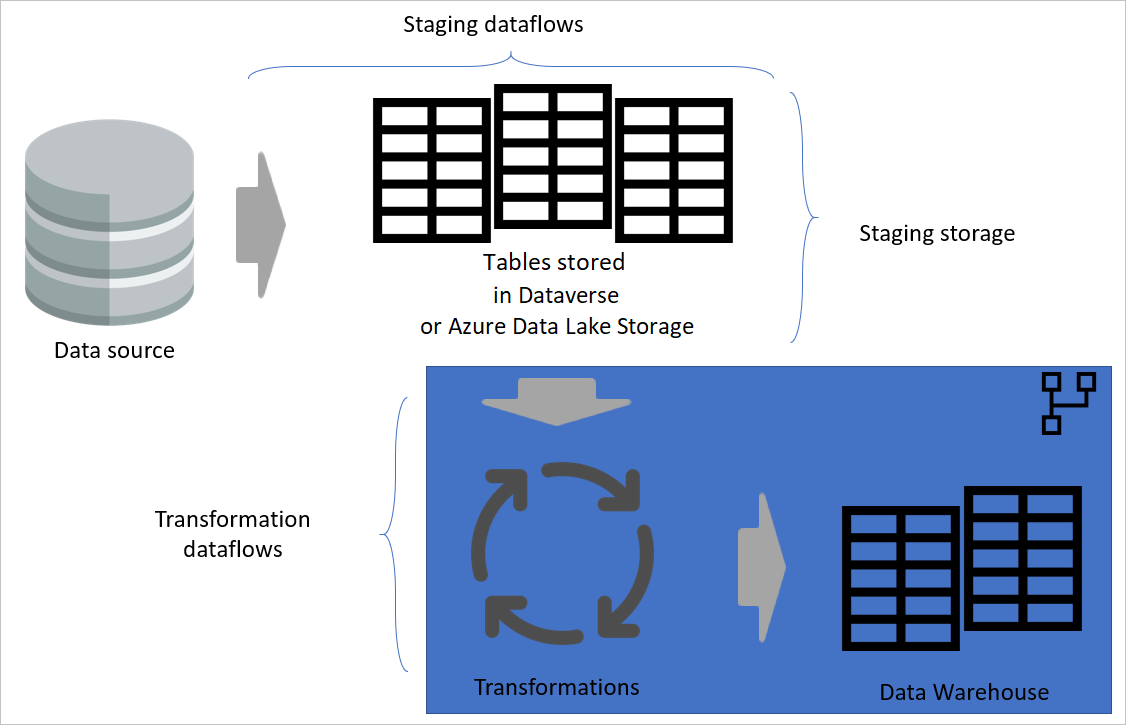
Vrstvená architektúra
Vrstvená architektúra je architektúra, v ktorej vykonávate akcie v samostatných vrstvách. Fázové a transformačné toky údajov môžu byť dve vrstvy viacvrstvovej architektúry toku údajov. Pokusom o činnosti vo vrstvách sa zabezpečí minimálna požadovaná údržba. Keď chcete niečo zmeniť, musíte to zmeniť len vo vrstve, v ktorej sa nachádza. Ostatné vrstvy by mali naďalej fungovať dobre.
Na nasledujúcom obrázku je znázornená viacvrstvová architektúra pre toky údajov, v ktorej sa ich tabuľky potom používajú v sémantických modeloch služby Power BI.
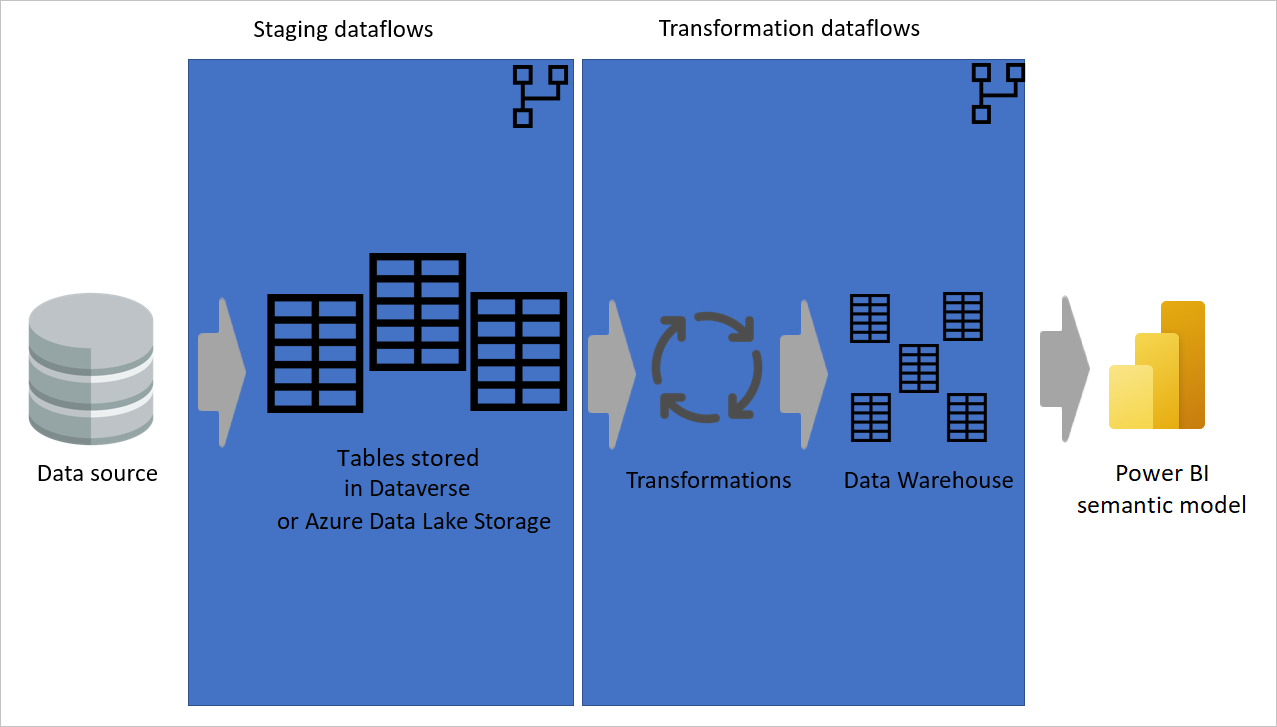
Použitie vypočítanej tabuľky v čo najväčšej možnej miere
Keď použijete výsledok toku údajov v inom toku údajov, používate koncept vypočítanej tabuľky, čo znamená získanie údajov z už spracovanej a uloženej tabuľky. To isté sa môže stať v rámci toku údajov. Keď odkazujete na tabuľku z inej tabuľky, môžete použiť vypočítanú tabuľku. Táto možnosť je užitočná, ak máte množinu transformácií, ktoré je potrebné vykonať vo viacerých tabuľkách a nazývajú sa bežné transformácie.
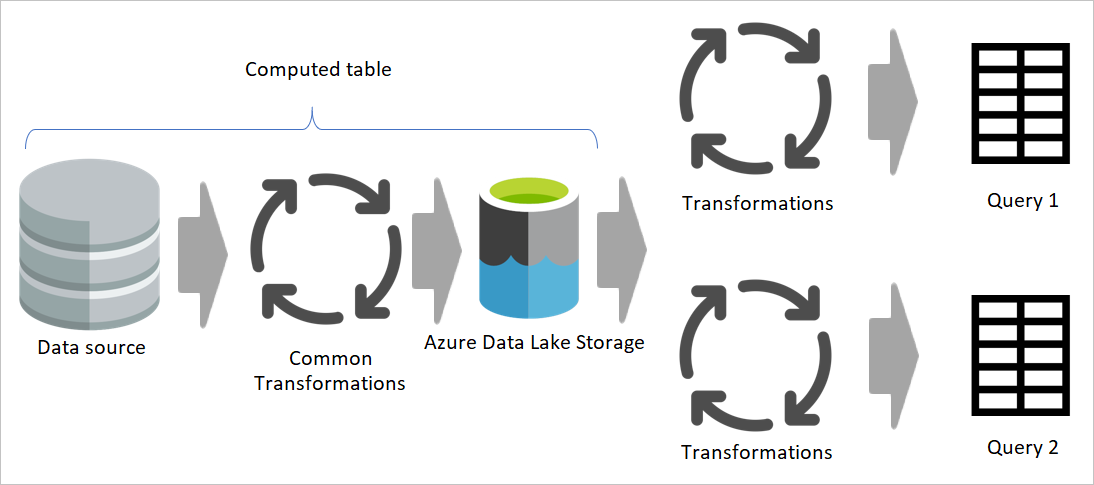
Na predchádzajúcom obrázku vypočítaná tabuľka načíta údaje priamo zo zdroja. V architektúre prechodu a transformácie tokov údajov je však pravdepodobné, že vypočítané tabuľky pochádzajú z prechodných tokov údajov.
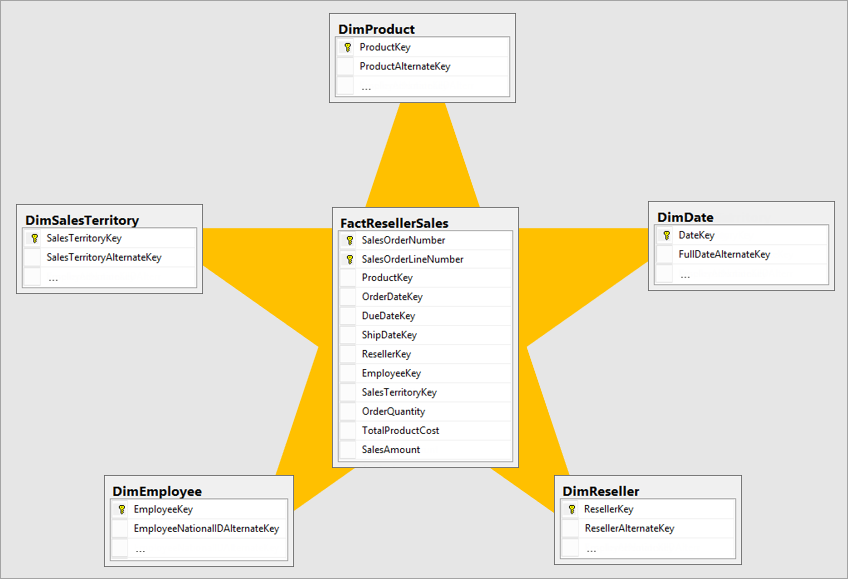
Vytvorenie hviezdicovej schémy
Najlepšie dimenzionálny model je model hviezdicovej schémy, ktorý má dimenzie a tabuľky faktov navrhnuté tak, aby sa minimalizovalo množstvo času na dotazovanie údajov z modelu, a tiež uľahčuje pochopenie pre vizualizáciu údajov.
Nie je ideálne preniesť údaje s rovnakým rozložením operačného systému do systému BI. Tabuľky údajov by sa mali rekonštruovať. Niektoré tabuľky by mali mať tvar tabuľky dimenzií, ktorá uchováva popisné informácie. Niektoré tabuľky by mali mať tvar tabuľky faktov, aby sa udržali agregovateľné údaje. Najlepšie rozloženie pre tabuľky faktov a tabuľky dimenzií, ktoré sa majú vytvoriť, je hviezdicová schéma. Ďalšie informácie: Informácie o hviezdicovej schéme a jej dôležitosti pre Power BI
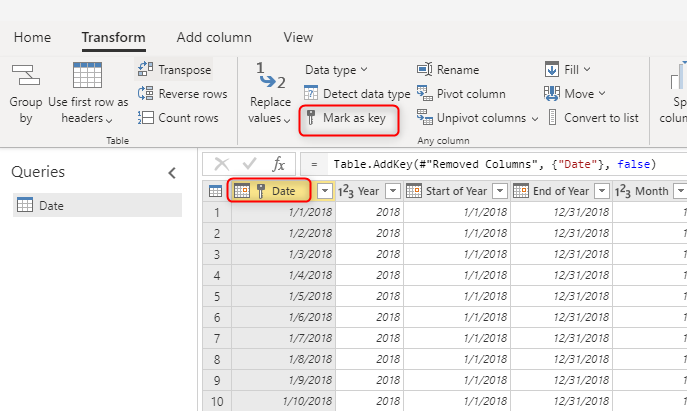
Použitie jedinečnej hodnoty kľúča pre dimenzie
Pri vytváraní tabuliek dimenzií sa uistite, že máte pre každú z nich kľúč. Tento kľúč zabezpečí, že medzi dimenziami neexistujú žiadne vzťahy typu many-to-many (alebo inými slovami "slabý"). Kľúč môžete vytvoriť použitím niektorých transformácií, aby ste sa uistili, že stĺpec alebo kombinácia stĺpcov vracia jedinečné riadky v dimenzii. Potom je možné túto kombináciu stĺpcov označiť ako kľúč v tabuľke v toku údajov.
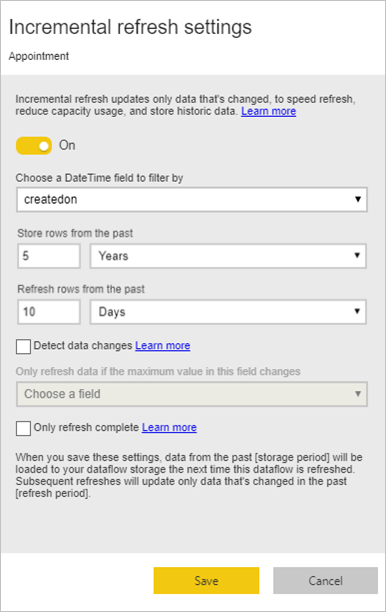
Vykonanie prírastkového obnovenia pre veľké tabuľky faktov
Tabuľky faktov sú vždy najväčšími tabuľkami v dimenzionálnom modeli. Odporúčame vám znížiť počet riadkov prenášaných pre tieto tabuľky. Ak máte veľmi veľkú tabuľku faktov, uistite sa, že pre danú tabuľku používate prírastkové obnovenie. Prírastkové obnovenie sa dá vykonať v sémantickom modeli služby Power BI a tiež v tabuľkách toku údajov.
Prírastkové obnovenie môžete použiť na obnovenie iba časti údajov, čiže časti, ktorá sa zmenila. Existuje viacero možností, ako vybrať, ktorá časť údajov sa má obnoviť a ktorá časť sa má zachovať. Ďalšie informácie: Použitie prírastkového obnovenia s tokmi údajov služby Power BI
Odkazovanie na vytvorenie dimenzií a tabuliek faktov
V zdrojovom systéme máte často tabuľku, ktorú používate na generovanie tabuliek faktov aj dimenzií v sklade údajov. Tieto tabuľky sú vhodnými kandidátmi na vypočítané tabuľky a aj priebežné toky údajov. Bežnú časť procesu, ako je napríklad čistenie údajov a odstránenie ďalších riadkov a stĺpcov, možno vykonať raz. Pomocou odkazu z výstupu týchto akcií môžete vytvoriť tabuľky dimenzií a faktov. Tento prístup použije vypočítanú tabuľku na bežné transformácie.
Pripomienky
Pripravujeme: V priebehu roka 2024 postupne zrušíme službu Problémy v službe GitHub ako mechanizmus pripomienok týkajúcich sa obsahu a nahradíme ju novým systémom pripomienok. Ďalšie informácie nájdete na stránke: https://aka.ms/ContentUserFeedback.
Odoslať a zobraziť pripomienky pre