Uporaba modelov, ki temeljijo na strojnem učenju Azure
Poenoteni podatki v Dynamics 365 Customer Insights podatkih so vir za izdelavo modelov Strojno učenje, ki lahko ustvarijo dodatne poslovne vpoglede. Customer Insights - Data se integrira s storitvijo Azure Strojno učenje za uporabo lastnih modelov po meri.
Zahteve
- Dostop do Customer Insights - Data
- Aktivna naročnina na storitev Azure Enterprise
- Poenoteni profili strank
- Izvoz tabele v konfigurirano shrambo zbirke dvojiških podatkov Azure
Nastavitev delovnega prostora za strojno učenje Azure
Glejte Ustvarjanje delovnega prostora Azure Strojno učenje za različne možnosti za ustvarjanje delovnega prostora . Za najboljšo zmogljivost ustvarite delovni prostor v območju Azure, ki je geografsko najbližje vašemu okolju Customer Insights.
Dostopajte do delovnega prostora prek studia Azure Strojno učenje Studio. Obstaja več načinov za interakcijo z delovnim prostorom.
Delo z oblikovalnikom za strojno učenje Azure
Azure Strojno učenje designer ponuja vizualno platno, kjer lahko povlečete in spustite nabore podatkov in module. Serijski cevovod, ki ga ustvari oblikovalec, se lahko integrira Customer Insights - Data , če so ustrezno konfigurirani.
Delo s SDK-jem za strojno učenje Azure
Podatkovni znanstveniki in razvijalci umetne inteligence uporabljajo SDK za Azure Strojno učenje za ustvarjanje potekov dela Strojno učenje. Trenutno modelov, usposobljenih s kompletom SDK, ni mogoče neposredno integrirati. Za integracijo je Customer Insights - Data potreben cevovod za sklepanje o seriji, ki porablja ta model.
Zahteve za serijski cevovod za integracijo z Customer Insights - Data
Konfiguracija nabora podatkov
Ustvarite nabore podatkov za uporabo podatkov tabele iz storitve Customer Insights za cevovod paketnega sklepanja. Registrirajte te nabore podatkov v delovnem prostoru. Trenutno podpiramo samo tabelarne nabore podatkov v .csv obliki. Nabore podatkov, ki ustrezajo podatkom tabele, parameterizirajte kot parameter cevovoda.
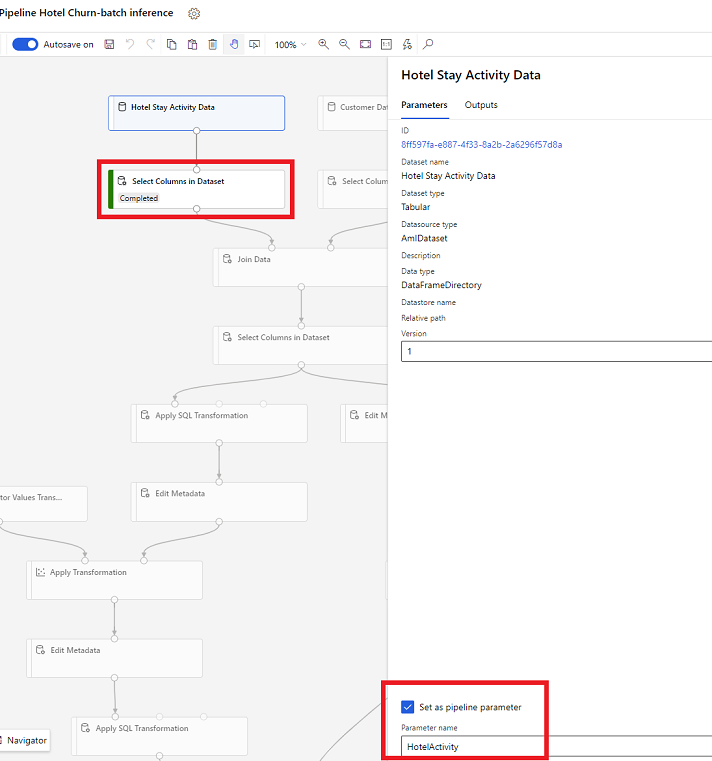
Parametri nabora podatkov v oblikovalniku
V oblikovalniku odprite Izberite stolpce v naboru podatkov in izberite Nastavi kot parameter cevovoda, kjer vnesete ime parametra.
Parameter nabora podatkov v SDK-ju (Python)
HotelStayActivity_dataset = Dataset.get_by_name(ws, name='Hotel Stay Activity Data') HotelStayActivity_pipeline_param = PipelineParameter(name="HotelStayActivity_pipeline_param", default_value=HotelStayActivity_dataset) HotelStayActivity_ds_consumption = DatasetConsumptionConfig("HotelStayActivity_dataset", HotelStayActivity_pipeline_param)
Prodajni lijak za sklepanje glede paketov
V oblikovalcu uporabite cevovod za usposabljanje, da ustvarite ali posodobite cevovod za sklepanje. Trenutno so podprti samo prodajni lijaki za sklepanje glede paketov.
S kompletom SDK objavite cevovod na končna točka. Trenutno Customer Insights - Data se integrira s privzetim cevovodom v paketnem cevovodu končna točka v delovnem prostoru Strojno učenje.
published_pipeline = pipeline.publish(name="ChurnInferencePipeline", description="Published Churn Inference pipeline") pipeline_endpoint = PipelineEndpoint.get(workspace=ws, name="ChurnPipelineEndpoint") pipeline_endpoint.add_default(pipeline=published_pipeline)
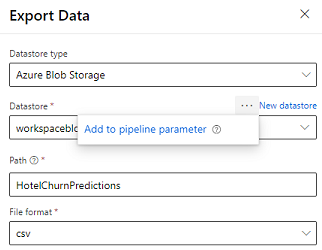
Uvoz podatkov cevovoda
Oblikovalnik ponuja modul Izvozi podatke, ki omogoča izvoz izhoda cevovoda v shrambo Azure. Trenutno mora modul uporabljati vrsto shrambe podatkov Shramba zbirke dvojiških podatkov Azure in parameterizirati shrambo podatkov in relativno pot. Sistem preglasi oba parametra med izvajanjem cevovoda s shrambo podatkov in potjo, ki je dostopna aplikaciji.
Ko zapisujete izhod sklepanja s kodo, naložite izhod na pot znotraj registrirane shrambe podatkov v delovnem prostoru. Če sta pot in shramba podatkov parametrizirani v cevovodu, lahko vpogledi v stranke preberejo in uvozijo izhodne podatke. Trenutno je podprt en sam niz tabelaričnih izhodnih podatkov v obliki zapisa csv. Pot mora vsebovati imenik in ime datoteke.
# In Pipeline setup script OutputPathParameter = PipelineParameter(name="output_path", default_value="HotelChurnOutput/HotelChurnOutput.csv") OutputDatastoreParameter = PipelineParameter(name="output_datastore", default_value="workspaceblobstore") ... # In pipeline execution script run = Run.get_context() ws = run.experiment.workspace datastore = Datastore.get(ws, output_datastore) # output_datastore is parameterized directory_name = os.path.dirname(output_path) # output_path is parameterized. # Datastore.upload() or Dataset.File.upload_directory() are supported methods to uplaod the data # datastore.upload(src_dir=<<working directory>>, target_path=directory_name, overwrite=False, show_progress=True) output_dataset = Dataset.File.upload_directory(src_dir=<<working directory>>, target = (datastore, directory_name)) # Remove trailing "/" from directory_name