Övervaka Site Recovery med Azure Monitor-loggar
Den här artikeln beskriver hur du övervakar datorer som replikeras av Azure Site Recovery, med hjälp av Azure Monitor-loggar och Log Analytics.
Azure Monitor-loggar tillhandahåller en loggdataplattform som samlar in aktivitets- och resursloggar tillsammans med andra övervakningsdata. I Azure Monitor-loggar använder du Log Analytics för att skriva och testa loggfrågor och interaktivt analysera loggdata. Du kan visualisera och köra frågor mot loggresultat och konfigurera aviseringar för att vidta åtgärder baserat på övervakade data.
För Site Recovery kan du använda Azure Monitor-loggar för att göra följande:
- Övervaka Site Recovery hälsa och status. Du kan till exempel övervaka replikeringshälsa, redundanstestningsstatus, Site Recovery händelser, mål för återställningspunkter (RPO) för skyddade datorer och disk-/dataändringshastigheter.
- Konfigurera aviseringar för Site Recovery. Du kan till exempel konfigurera aviseringar för datorns hälsotillstånd, redundansteststatus eller Site Recovery jobbstatus.
Användning av Azure Monitor-loggar med Site Recovery stöds för Replikering från Azure till Azure och VMware VM/fysisk server till Azure-replikering.
Anteckning
För att hämta dataloggarna för dataomsättning och uppladdningshastigheten för VMware och fysiska datorer måste du installera en Microsoft-övervakningsagent på processervern. Den här agenten skickar loggarna för de replikerande datorerna till arbetsytan. Den här funktionen är endast tillgänglig för mobilitetsagentversionen 9.30 och senare.
Förutsättningar
Du behöver det här:
- Minst en dator skyddas i ett Recovery Services-valv.
- En Log Analytics-arbetsyta för att lagra Site Recovery loggar. Läs mer om hur du konfigurerar en arbetsyta.
- En grundläggande förståelse för hur du skriver, kör och analyserar loggfrågor i Log Analytics. Läs mer.
Vi rekommenderar att du granskar vanliga övervakningsfrågor innan du börjar.
Konfigurera Site Recovery för att skicka loggar
I valvet väljer du Diagnostikinställningar>Lägg till diagnostikinställning.
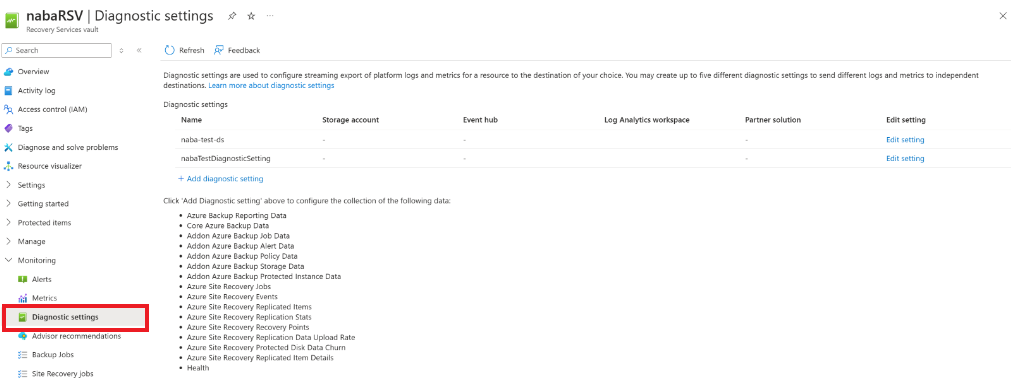
I Diagnostikinställningar anger du ett namn och markerar kryssrutan Skicka till Log Analytics.
Välj prenumerationen För Azure Monitor-loggar och Log Analytics-arbetsytan.
Välj Azure Diagnostics i växlingsknappen.
I logglistan väljer du alla loggar med prefixet AzureSiteRecovery. Välj sedan OK.
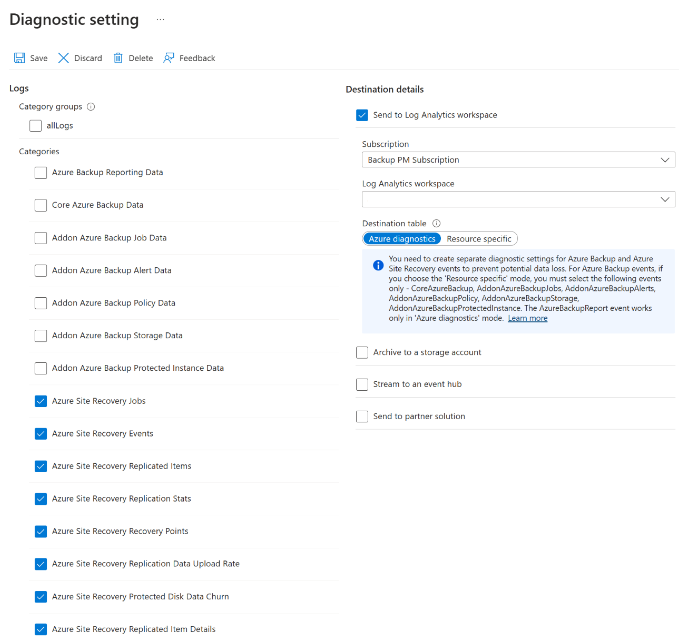
De Site Recovery loggarna börjar matas in i en tabell (AzureDiagnostics) på den valda arbetsytan.
Konfigurera Microsoft-övervakningsagenten på processervern för att skicka dataomsättnings- och uppladdningshastighetsloggar
Du kan samla in information om dataomsättningshastigheten och information om datauppladdningshastigheten för dina VMware/fysiska datorer lokalt. För att aktivera detta måste en Microsoft-övervakningsagent installeras på processervern.
Gå till Log Analytics-arbetsytan och välj Avancerade inställningar.
Välj sidan Anslutna källor och välj Windows-servrar.
Ladda ned Windows-agenten (64-bitars) på processervern.
Slutför agentinstallationen genom att ange det hämtade arbetsyte-ID:t och nyckeln.
När installationen är klar går du till Log Analytics-arbetsytan och väljer Hantering av äldre agenter. Gå till sidan Data och välj Prestandaräknare för Windows.
Välj "+" om du vill lägga till följande två räknare med ett urvalsintervall på 300 sekunder:
- ASRAnalytics(*)\SourceVmChurnRate
- ASRAnalytics(*)\SourceVmThrpRate
Data om omsättning och uppladdningshastighet börjar matas in på arbetsytan.
Fråga loggarna – exempel
Du hämtar data från loggar med hjälp av loggfrågor som skrivits med Kusto-frågespråket. Det här avsnittet innehåller några exempel på vanliga frågor som du kan använda för Site Recovery övervakning.
Anteckning
Några av exemplen använder replicationProviderName_s anges till A2A. Detta hämtar virtuella Azure-datorer som replikeras till en sekundär Azure-region med hjälp av Site Recovery. I de här exemplen kan du ersätta A2A med InMageRcm om du vill hämta lokala virtuella VMware-datorer eller fysiska servrar som replikeras till Azure med hjälp av Site Recovery.
Frågereplikeringshälsa
Den här frågan ritar ett cirkeldiagram för den aktuella replikeringshälsan för alla skyddade virtuella Azure-datorer, uppdelade i tre tillstånd: Normal, Varning eller Kritisk.
AzureDiagnostics
| where replicationProviderName_s == "A2A"
| where isnotempty(name_s) and isnotnull(name_s)
| summarize hint.strategy=partitioned arg_max(TimeGenerated, *) by name_s
| project name_s , replicationHealth_s
| summarize count() by replicationHealth_s
| render piechart
Fråga tjänsten Mobility version
Den här frågan ritar ett cirkeldiagram för virtuella Azure-datorer som replikeras med Site Recovery, uppdelat efter den version av Mobilitetsagenten som de kör.
AzureDiagnostics
| where replicationProviderName_s == "A2A"
| where isnotempty(name_s) and isnotnull(name_s)
| summarize hint.strategy=partitioned arg_max(TimeGenerated, *) by name_s
| project name_s , agentVersion_s
| summarize count() by agentVersion_s
| render piechart
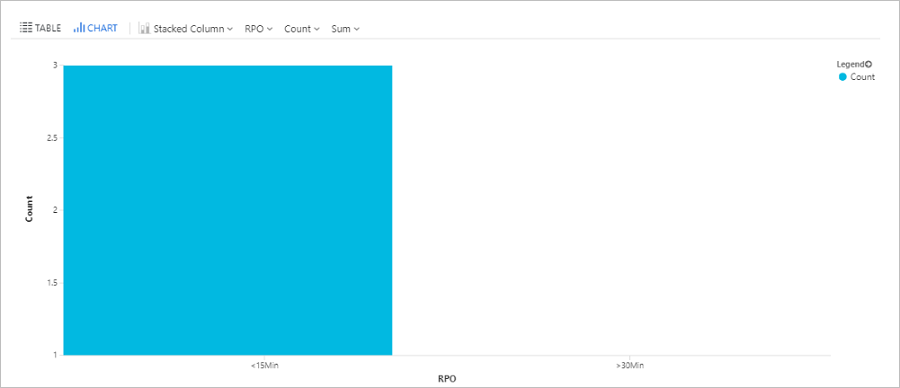
Fråga RPO-tid
Den här frågan ritar ett stapeldiagram över virtuella Azure-datorer som replikeras med Site Recovery, uppdelade efter mål för återställningspunkt (RPO): Mindre än 15 minuter, mellan 15 och 30 minuter, mer än 30 minuter.
AzureDiagnostics
| where replicationProviderName_s == "A2A"
| where isnotempty(name_s) and isnotnull(name_s)
| extend RPO = case(rpoInSeconds_d <= 900, "<15Min",
rpoInSeconds_d <= 1800, "15-30Min", ">30Min")
| summarize hint.strategy=partitioned arg_max(TimeGenerated, *) by name_s
| project name_s , RPO
| summarize Count = count() by RPO
| render barchart
Fråga Site Recovery jobb
Den här frågan hämtar alla Site Recovery jobb (för alla haveriberedskapsscenarier), som utlöses under de senaste 72 timmarna och deras slutförandetillstånd.
AzureDiagnostics
| where Category == "AzureSiteRecoveryJobs"
| where TimeGenerated >= ago(72h)
| project JobName = OperationName , VaultName = Resource , TargetName = affectedResourceName_s, State = ResultType
Fråga Site Recovery händelser
Den här frågan hämtar alla Site Recovery händelser (för alla haveriberedskapsscenarier) som har utlösts under de senaste 72 timmarna, tillsammans med deras allvarlighetsgrad.
AzureDiagnostics
| where Category == "AzureSiteRecoveryEvents"
| where TimeGenerated >= ago(72h)
| project AffectedObject=affectedResourceName_s , VaultName = Resource, Description_s = healthErrors_s , Severity = Level
Redundanstillstånd för frågetest (cirkeldiagram)
Den här frågan ritar ett cirkeldiagram för redundansteststatus för virtuella Azure-datorer som replikeras med Site Recovery.
AzureDiagnostics
| where replicationProviderName_s == "A2A"
| where isnotempty(name_s) and isnotnull(name_s)
| where isnotempty(failoverHealth_s) and isnotnull(failoverHealth_s)
| summarize hint.strategy=partitioned arg_max(TimeGenerated, *) by name_s
| project name_s , Resource, failoverHealth_s
| summarize count() by failoverHealth_s
| render piechart
Redundanstillstånd för frågetest (tabell)
Den här frågan ritar en tabell för redundansteststatus för virtuella Azure-datorer som replikeras med Site Recovery.
AzureDiagnostics
| where replicationProviderName_s == "A2A"
| where isnotempty(name_s) and isnotnull(name_s)
| where isnotempty(failoverHealth_s) and isnotnull(failoverHealth_s)
| summarize hint.strategy=partitioned arg_max(TimeGenerated, *) by name_s
| project VirtualMachine = name_s , VaultName = Resource , TestFailoverStatus = failoverHealth_s
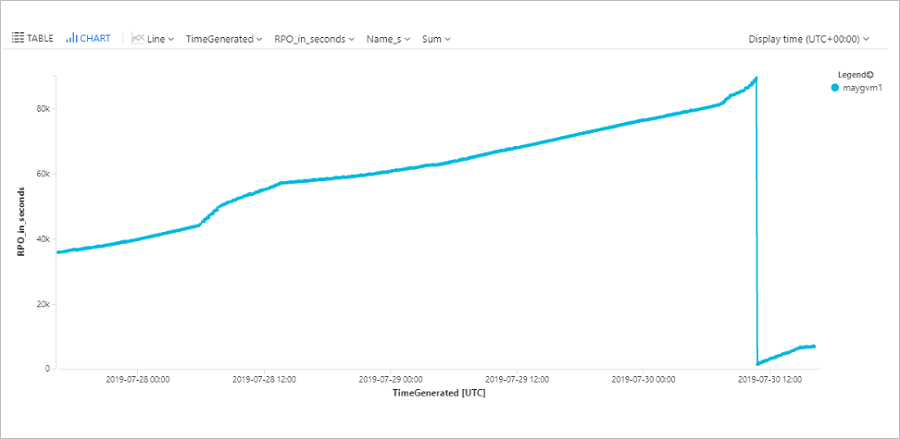
Frågemaskinens RPO
Den här frågan ritar ett trenddiagram som spårar RPO för en specifik virtuell Azure-dator (ContosoVM123) under de senaste 72 timmarna.
AzureDiagnostics
| where replicationProviderName_s == "A2A"
| where TimeGenerated > ago(72h)
| where isnotempty(name_s) and isnotnull(name_s)
| where name_s == "ContosoVM123"
| project TimeGenerated, name_s , RPO_in_seconds = rpoInSeconds_d
| render timechart
Ändringsfrekvens för frågedata (omsättning) och uppladdningshastighet för en virtuell Azure-dator
Den här frågan ritar ett trenddiagram för en specifik virtuell Azure-dator (ContosoVM123), som representerar dataändringshastigheten (skrivningsbyte per sekund) och datauppladdningshastigheten.
AzureDiagnostics
| where Category in ("AzureSiteRecoveryProtectedDiskDataChurn", "AzureSiteRecoveryReplicationDataUploadRate")
| extend CategoryS = case(Category contains "Churn", "DataChurn",
Category contains "Upload", "UploadRate", "none")
| extend InstanceWithType=strcat(CategoryS, "_", InstanceName_s)
| where TimeGenerated > ago(24h)
| where InstanceName_s startswith "ContosoVM123"
| project TimeGenerated , InstanceWithType , Churn_MBps = todouble(Value_s)/1048576
| render timechart
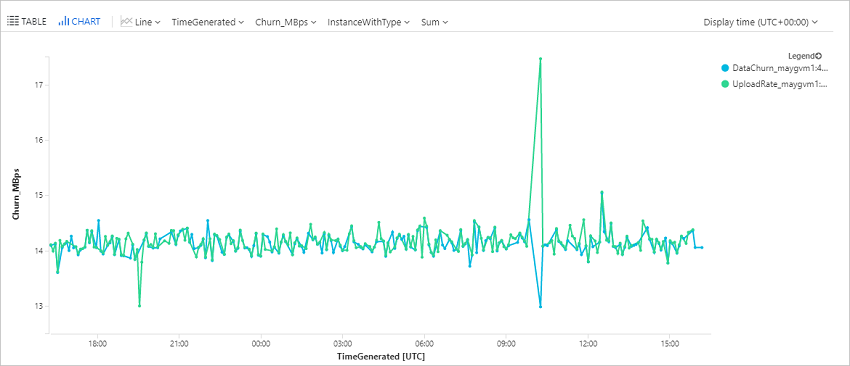
Ändringsfrekvens för frågedata (omsättning) och uppladdningshastighet för en VMware- eller fysisk dator
Anteckning
Se till att du konfigurerar övervakningsagenten på processervern för att hämta loggarna. Se stegen för att konfigurera övervakningsagenten.
Den här frågan ritar ett trenddiagram för en specifik disk, disk0, för ett replikerat objekt, win-9r7sfh9qlru, som representerar dataändringshastigheten (skrivbyte per sekund) och datauppladdningshastigheten. Du hittar disknamnet på bladet Diskar för det replikerade objektet i Recovery Services-valvet. Det instansnamn som ska användas i frågan är DNS-namnet på datorn följt av _ och disknamnet som i det här exemplet.
Perf
| where ObjectName == "ASRAnalytics"
| where InstanceName contains "win-9r7sfh9qlru_disk0"
| where TimeGenerated >= ago(4h)
| project TimeGenerated ,CounterName, Churn_MBps = todouble(CounterValue)/5242880
| render timechart
Processervern skickar dessa data var femte minut till Log Analytics-arbetsytan. Dessa datapunkter representerar genomsnittet som beräknats i 5 minuter.
Sammanfattning av haveriberedskap för frågor (Azure till Azure)
Den här frågan ritar en sammanfattningstabell för virtuella Azure-datorer som replikeras till en sekundär Azure-region. Den visar den virtuella datorns namn, replikering och skyddsstatus, RPO, redundansteststatus, mobilitetsagentversion, eventuella aktiva replikeringsfel och källplatsen.
AzureDiagnostics
| where replicationProviderName_s == "A2A"
| where isnotempty(name_s) and isnotnull(name_s)
| summarize hint.strategy=partitioned arg_max(TimeGenerated, *) by name_s
| project VirtualMachine = name_s , Vault = Resource , ReplicationHealth = replicationHealth_s, Status = protectionState_s, RPO_in_seconds = rpoInSeconds_d, TestFailoverStatus = failoverHealth_s, AgentVersion = agentVersion_s, ReplicationError = replicationHealthErrors_s, SourceLocation = primaryFabricName_s
Sammanfattning av haveriberedskap för frågor (VMware/fysiska servrar)
Den här frågan ritar en sammanfattningstabell för virtuella VMware-datorer och fysiska servrar som replikeras till Azure. Den visar datorns namn, replikerings- och skyddsstatus, RPO, redundansteststatus, mobilitetsagentversion, eventuella aktiva replikeringsfel och den relevanta processervern.
AzureDiagnostics
| where replicationProviderName_s == "InMageRcm"
| where isnotempty(name_s) and isnotnull(name_s)
| summarize hint.strategy=partitioned arg_max(TimeGenerated, *) by name_s
| project VirtualMachine = name_s , Vault = Resource , ReplicationHealth = replicationHealth_s, Status = protectionState_s, RPO_in_seconds = rpoInSeconds_d, TestFailoverStatus = failoverHealth_s, AgentVersion = agentVersion_s, ReplicationError = replicationHealthErrors_s, ProcessServer = processServerName_g
Konfigurera aviseringar – exempel
Du kan konfigurera Site Recovery aviseringar baserat på Azure Monitor-data. Läs mer om hur du konfigurerar loggaviseringar.
Anteckning
Några av exemplen använder replicationProviderName_s anges till A2A. Detta anger aviseringar för virtuella Azure-datorer som replikeras till en sekundär Azure-region. I de här exemplen kan du ersätta A2A med InMageRcm om du vill ange aviseringar för lokala virtuella VMware-datorer eller fysiska servrar som replikeras till Azure.
Flera datorer i ett kritiskt tillstånd
Konfigurera en avisering om fler än 20 replikerade virtuella Azure-datorer hamnar i ett kritiskt tillstånd.
AzureDiagnostics
| where replicationProviderName_s == "A2A"
| where replicationHealth_s == "Critical"
| where isnotempty(name_s) and isnotnull(name_s)
| summarize hint.strategy=partitioned arg_max(TimeGenerated, *) by name_s
| summarize count()
För aviseringen anger du Tröskelvärde till 20.
En dator i ett kritiskt tillstånd
Konfigurera en avisering om en specifik replikerad virtuell Azure-dator hamnar i ett kritiskt tillstånd.
AzureDiagnostics
| where replicationProviderName_s == "A2A"
| where replicationHealth_s == "Critical"
| where name_s == "ContosoVM123"
| where isnotempty(name_s) and isnotnull(name_s)
| summarize hint.strategy=partitioned arg_max(TimeGenerated, *) by name_s
| summarize count()
För aviseringen anger du Tröskelvärde till 1.
Flera datorer överskrider RPO
Konfigurera en avisering om återställningspunkten för mer än 20 virtuella Azure-datorer överskrider 30 minuter.
AzureDiagnostics
| where replicationProviderName_s == "A2A"
| where isnotempty(name_s) and isnotnull(name_s)
| where rpoInSeconds_d > 1800
| summarize hint.strategy=partitioned arg_max(TimeGenerated, *) by name_s
| project name_s , rpoInSeconds_d
| summarize count()
För aviseringen anger du Tröskelvärde till 20.
En enskild dator överskrider RPO
Konfigurera en avisering om återställningspunkten för en enskild virtuell Azure-dator överskrider 30 minuter.
AzureDiagnostics
| where replicationProviderName_s == "A2A"
| where isnotempty(name_s) and isnotnull(name_s)
| where name_s == "ContosoVM123"
| where rpoInSeconds_d > 1800
| summarize hint.strategy=partitioned arg_max(TimeGenerated, *) by name_s
| project name_s , rpoInSeconds_d
| summarize count()
För aviseringen anger du Tröskelvärde till 1.
Redundanstestet för flera datorer överskrider 90 dagar
Konfigurera en avisering om det senaste lyckade redundanstestet var mer än 90 dagar för fler än 20 virtuella datorer.
AzureDiagnostics
| where replicationProviderName_s == "A2A"
| where Category == "AzureSiteRecoveryReplicatedItems"
| where isnotempty(name_s) and isnotnull(name_s)
| where lastSuccessfulTestFailoverTime_t <= ago(90d)
| summarize hint.strategy=partitioned arg_max(TimeGenerated, *) by name_s
| summarize count()
För aviseringen anger du Tröskelvärde till 20.
Redundanstestet för en enskild dator överskrider 90 dagar
Konfigurera en avisering om det senaste lyckade redundanstestet för en specifik virtuell dator var för mer än 90 dagar sedan.
AzureDiagnostics
| where replicationProviderName_s == "A2A"
| where Category == "AzureSiteRecoveryReplicatedItems"
| where isnotempty(name_s) and isnotnull(name_s)
| where lastSuccessfulTestFailoverTime_t <= ago(90d)
| where name_s == "ContosoVM123"
| summarize hint.strategy=partitioned arg_max(TimeGenerated, *) by name_s
| summarize count()
För aviseringen anger du Tröskelvärde till 1.
Site Recovery jobbet misslyckas
Konfigurera en avisering om ett Site Recovery jobb (i det här fallet återaktiveringsjobbet) misslyckas för något Site Recovery scenario under den senaste dagen.
AzureDiagnostics
| where Category == "AzureSiteRecoveryJobs"
| where OperationName == "Reprotect"
| where ResultType == "Failed"
| summarize count()
För aviseringen anger du Tröskelvärde till 1 och Period till 1 440 minuter för att kontrollera fel under den senaste dagen.
Nästa steg
Läs mer om inbyggd Site Recovery övervakning.