Kör ett N-nivåprogram i flera Azure Stack Hub-regioner för hög tillgänglighet
Den här referensarkitekturen visar en uppsättning beprövade metoder för att köra i ett N-nivåprogram i flera Azure Stack Hub-regioner för att uppnå tillgänglighet och en robust infrastruktur för haveriberedskap. I det här dokumentet används Traffic Manager för att uppnå hög tillgänglighet, men om Traffic Manager inte är ett föredraget val i din miljö kan ett par lastbalanserare med hög tillgänglighet också ersättas i.
Anteckning
Observera att Traffic Manager som används i arkitekturen nedan måste konfigureras i Azure och de slutpunkter som används för att konfigurera Traffic Manager-profilen måste vara offentligt dirigerbara IP-adresser.
Arkitektur
Den här arkitekturen bygger på den som visas i N-nivåprogrammet med SQL Server.
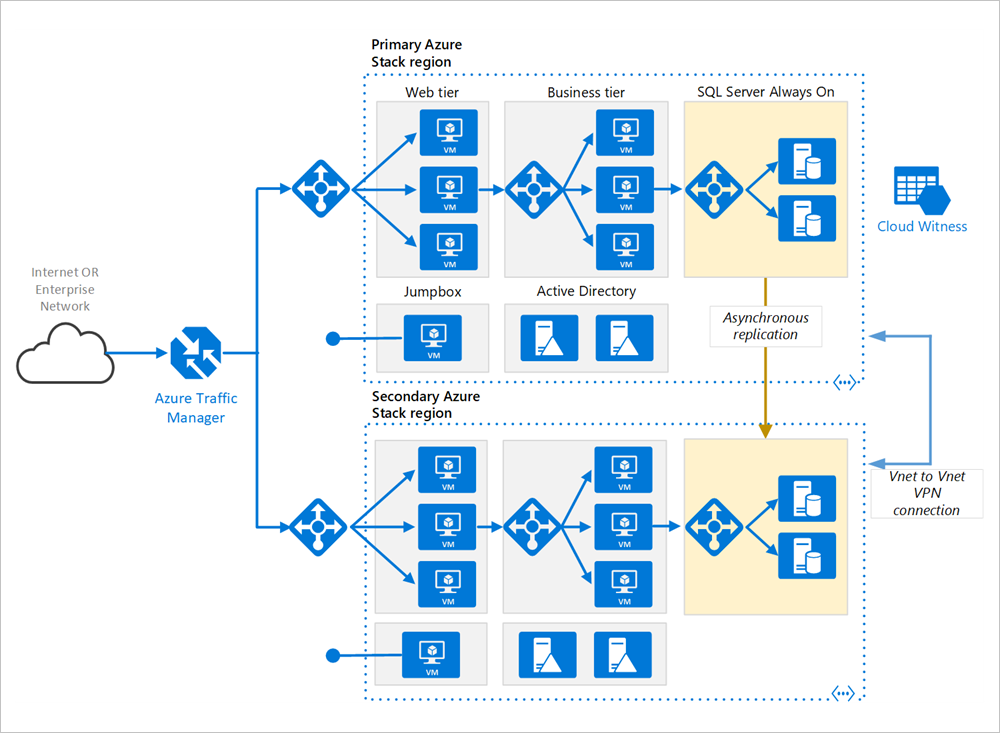
Primära och sekundära regioner. Använd två regioner för att få en högre tillgänglighet. En är den primära regionen. Den andra regionen är för redundans.
Azure Traffic Manager. Traffic Manager dirigerar inkommande begäranden till en av regionerna. Vid normal drift dirigerar den begäranden till den primära regionen. Om den regionen blir otillgänglig, redundansväxlar Traffic Manager till den sekundära regionen. Mer information finns i avsnittet om konfiguration av Traffic Manager.
Resursgrupper. Skapa separata resursgrupper för den primära regionen, den sekundära regionen. Detta ger dig flexibiliteten att hantera varje region som en enskild samling resurser. Du kan till exempel omdistribuera en region utan att den andra påverkas. Länka resursgrupperna så att du kan köra en fråga för att skapa en lista över alla resurser för programmet.
Virtuella nätverk. Skapa ett separat virtuellt nätverk för varje region. Kontrollera att adressutrymmena inte överlappar varandra.
SQL Server AlwaysOn-tillgänglighetsgrupp. Om du använder SQL Server, rekommenderar vi SQL AlwaysOn-tillgänglighetsgrupper för hög tillgänglighet. Skapa en enda tillgänglighetsgrupp som innehåller SQL Server-instanser i båda regionerna.
VPN-anslutning mellan virtuella nätverk och virtuella nätverk. Eftersom VNET-peering ännu inte är tillgängligt på Azure Stack Hub använder du VNET-till-VNET VPN-anslutning för att ansluta de två virtuella nätverken. Mer information finns i VNET till VNET i Azure Stack Hub .
Rekommendationer
En arkitektur med flera regioner kan ge högre tillgänglighet än att distribuera till en enskild region. Om ett regionalt strömavbrott påverkar den primära regionen, kan du använda Traffic Manager för att växla över till den sekundära regionen. Den här arkitekturen kan också hjälpa om ett enskilt undersystem i programmet misslyckas.
Det finns flera sätt att uppnå hög tillgänglighet över regioner:
Aktiv/passiv med hett vänteläge. Trafiken går till en region medan den andra väntar på hett vänteläge. Hett vänteläge innebär de virtuella datorerna i den sekundära regionen är allokerade och körs hela tiden.
Aktiv/passiv med kallt vänteläge. Trafiken går till en region medan den andra väntar på kallt vänteläge. Kallt vänteläge innebär att de virtuella datorerna i den sekundära regionen inte allokeras förrän de behövs vid redundans. Den här metoden kostar mindre att köra, men tar vanligtvis längre tid att ansluta vid fel.
Aktiv/aktiv. Båda regionerna är aktiva och begärandena belastningsutjämnas mellan dem. Om en region blir otillgänglig tas den bort från rotationen.
Denna referensarkitektur fokuserar på aktiv/passiv med hett vänteläge, och använder Traffic Manager vid redundans. Du kan distribuera ett litet antal virtuella datorer för hett vänteläge och sedan skala ut efter behov.
Konfigurera Traffic Manager
Tänk på följande när du konfigurerar Traffic Manager:
Routing. Traffic Manager stöder flera algoritmer för routning. Det scenario som beskrivs i den här artikeln använder prioritetsroutning (kallades tidigare redundansroutning). Med den här inställningen skickar Traffic Manager alla begäranden till den primära regionen, såvida inte den primära regionen blir oåtkomlig. Då flyttas processen automatiskt över till den sekundära regionen. Se Konfigurera routningsmetod vid redundans.
Hälsoavsökning. Traffic Manager använder en HTTP-avsökning (eller HTTPS) för att övervaka tillgängligheten för varje region. Avsökningen söker efter ett HTTP 200-svar för en angiven URL-sökväg. Bästa praxis är att skapa en slutpunkt som rapporterar programmets övergripande hälsa och att använda den här slutpunkten för hälsoavsökningen. Annars kan avsökningen rapportera en felfri slutpunkt när kritiska delar av programmet faktiskt har feltillstånd. Mer information finns i Hälsoslutpunktsövervakningsmönster.
När Traffic Manager redundansväxlar kan klienter inte komma åt programmet på en stund. Varaktigheten påverkas av följande faktorer:
Hälsoavsökningen måste upptäcka att den primära regionen har blivit onåbar.
DNS-servrar måste uppdatera cachelagrade DNS-poster för IP-adressen, som är beroende av TTL för DNS (Time to live). Standard-TTL är 300 sekunder (fem minuter), men du kan konfigurera det här värdet när du skapar Traffic Manager-profilen.
Mer information finns i About Traffic Manager Monitoring (Om Traffic Manager-övervakning).
Om Traffic Manager redundansväxlar rekommenderar vi att en manuell återställning utförs efter fel i stället för att implementera en automatisk felåterställning. Annars skapar du en situation där programmet hoppar fram och tillbaka mellan regioner. Kontrollera att alla programmets undersystem är felfria före felåterställning.
Observera att Traffic Manager som standard återställs automatiskt efter fel. Om du vill förhindra detta sänker du prioriteten för den primära regionen efter en redundansväxling manuellt. Anta exempelvis att den primära regionen har prioritet 1 och sekundära har prioritet 2. Ange den primära regionen till prioritet 3 efter en redundansväxling, för att förhindra automatisk återställning efter ett fel. När du är redo att växla tillbaka uppdaterar du prioriteten till 1.
Följande Azure CLI-kommando uppdaterar prioriteten:
az network traffic-manager endpoint update --resource-group <resource-group> --profile-name <profile>
--name <endpoint-name> --type externalEndpoints --priority 3
En annan metod är att tillfälligt inaktivera slutpunkten tills du är redo att återställa efter felet:
az network traffic-manager endpoint update --resource-group <resource-group> --profile-name <profile>
--name <endpoint-name> --type externalEndpoints --endpoint-status Disabled
Beroende på felorsaken kan du behöver omdistribuera resurserna i en region. Före återställningen utför du ett test av den operativa beredskapen. Testet bör exempelvis verifiera följande:
Att virtuella datorer är korrekt konfigurerade. (Att all nödvändig programvara är installerad, IIS körs osv.)
Att programmets delsystem är felfria.
Funktionell testning. (Databasnivån kan exempelvis nås från webbnivån.)
Konfigurera SQL Server AlwaysOn-tillgänglighetsgrupper
Före Windows Server 2016 kräver SQL Server AlwaysOn-tillgänglighetsgrupper en domänkontrollant, och alla noder i tillgänglighetsgruppen måste ingå i samma AD-domän (Active Directory).
Så här konfigurerar du tillgänglighetsgruppen:
Placera minst två domänkontrollanter i varje region.
Ge varje domänkontrollant en statisk IP-adress.
Skapa VPN för att aktivera kommunikation mellan två virtuella nätverk.
För varje virtuellt nätverk lägger du till IP-adresserna för domänkontrollanterna (från båda regionerna) i DNS-serverlistan. Du kan använda följande CLI-kommando. Mer information finns i Ändra DNS-servrar.
az network vnet update --resource-group <resource-group> --name <vnet-name> --dns-servers "10.0.0.4,10.0.0.6,172.16.0.4,172.16.0.6"Skapa ett kluster med Windows Server-redundansklustring (WSFC) som innehåller SQL Server-instanser i båda regionerna.
Skapa en SQL Server AlwaysOn-tillgänglighetsgrupp som innehåller SQL Server-instanserna i både de primära och sekundära regionerna. Anvisningar finns i Utöka AlwaysOn-tillgänglighetsgrupp till fjärranslutna Azure-datacenter (PowerShell) (Extending Always On Availability Group to Remote Azure Datacenter (PowerShell)).
Placera den primära repliken i den primära regionen.
Placera en eller flera sekundära repliker i den primära regionen. Konfigurera dessa så att synkront genomförande med automatisk redundans används.
Placera en eller flera sekundära repliker i den sekundära regionen. Konfigurera dessa så att asynkront genomförande används av prestandaskäl. (Annars måste alla T-SQL-transaktioner vänta på att kommunikationen skickas tur och retur via nätverket till den sekundära regionen.)
Anteckning
Asynkrona incheckningsrepliker stöder inte automatisk redundans.
Överväganden för tillgänglighet
Med en komplex app på N-nivå behöver du kanske inte replikera hela programmet i den sekundära regionen. I stället kanske du bara kan replikera ett kritiskt undersystem som behövs för affärskontinuiteten.
Traffic Manager är en möjlig felpunkt i systemet. Om Traffic Manager-tjänsten misslyckas kan klienter inte komma åt ditt program under driftstoppet. Kontrollera serviceavtalet för Traffic Manager, och avgör om enbart Traffic Manager uppfyller företagets krav på hög tillgänglighet eller inte. Om det inte räcker bör du överväga att lägga till en ytterligare trafikhanteringslösning för återställning efter fel. Om Azure Traffic Manager-tjänsten slutar att fungera ändrar du CNAME-posterna i DNS så att de pekar mot den andra trafikhanteringstjänsten. (Det här steget måste utföras manuellt och programmet blir otillgängligt tills DNS-ändringarna har spridits.)
Det finns två redundansscenarier att tänka på för SQL Server-klustret:
Alla repliker för SQL Server-databasen i den primära regionen har fel. Detta kan t.ex. inträffa under ett regionalt strömavbrott. I så fall måste du manuellt redundansväxla tillgänglighetsgruppen, även om Traffic Manager automatiskt redundansväxlar i klientdelen. Följ stegen i Perform a Forced Manual Failover of a SQL Server Availability Group (Utför en framtvingad manuell redundansväxling för en SQL Server-tillgänglighetsgrupp), där det beskrivs hur du utför en framtvingad redundansväxling med SQL Server Management Studio, Transact-SQL eller PowerShell i SQL Server 2016.
Varning
Det finns en risk för dataförlust vid forcerad redundans. När den primära regionen är online igen tar du en ögonblicksbild av databasen och använder tablediff för att hitta skillnaderna.
Traffic Manager redundansväxlas till den sekundära regionen, men den primära SQL Server-databasrepliken är fortfarande tillgänglig. Till exempel kan nivån i klientdelen misslyckas utan att SQL Server-VM:ar påverkas. I så fall dirigeras internettrafik till den sekundära regionen och den regionen kan fortfarande ansluta till den primära repliken. Det uppstår ökad latens eftersom SQL Server-anslutningarna görs över regioner. I det här fallet bör du utföra en manuell växling på följande sätt:
Växla tillfälligt en SQL Server-databasreplik i den sekundära regionen till synkron incheckning. Det säkerställer att data inte förloras under redundansen.
Växla över till den repliken.
När du växlar tillbaka till den primära regionen återställer du inställningen för asynkron incheckning.
Överväganden för hantering
När du uppdaterar din distribution, uppdatera en region i taget för att minska risken för ett globalt fel från en felaktig konfiguration eller ett fel i programmet.
Testa systemets återhämtningskapacitet efter fel. Här är några vanliga felscenarier du kan testa:
Stäng av VM-instanser.
Belasta resurser, till exempel processor och minne.
Frånkoppla/fördröj nätverket.
Krascha processer.
Upphäv certifikat.
Simulera maskinvarufel.
Stäng av DNS-tjänsten på domänkontrollanterna.
Mät återställningstiderna och säkerställ att de uppfyller affärskraven. Testa även kombinationer av feltillstånd.
Nästa steg
- Mer information om Azure Cloud Patterns finns i Cloud Design Patterns (Molndesignmönster).
Feedback
Kommer snart: Under hela 2024 kommer vi att fasa ut GitHub-problem som feedbackmekanism för innehåll och ersätta det med ett nytt feedbacksystem. Mer information finns i: https://aka.ms/ContentUserFeedback.
Skicka och visa feedback för