Anpassade modeller: noggrannhets- och konfidenspoäng
Det här innehållet gäller för:![]() v4.0 (förhandsversion)
v4.0 (förhandsversion)![]() v3.1 (GA)
v3.1 (GA)![]() v3.0 (GA)
v3.0 (GA)![]() v2.1 (GA)
v2.1 (GA)
Kommentar
- Anpassade neurala modeller ger inte noggrannhetspoäng under träningen.
- Konfidenspoäng för tabeller, tabellrader och tabellceller är tillgängliga från och med API-versionen 2024-02-29-preview för anpassade modeller.
Anpassade mallmodeller genererar en uppskattad noggrannhetspoäng när de tränas. Dokument som analyseras med en anpassad modell skapar en förtroendepoäng för extraherade fält. I den här artikeln lär du dig att tolka noggrannhets- och konfidenspoäng och metodtips för att använda dessa poäng för att förbättra noggrannheten och konfidensresultaten.
Noggrannhetspoäng
Utdata från en build anpassad modellåtgärd (v3.0) eller train (v2.1) innehåller den uppskattade noggrannhetspoängen. Den här poängen representerar modellens möjlighet att korrekt förutsäga det märkta värdet i ett visuellt liknande dokument.
Noggrannhetsvärdeintervallet är en procentandel mellan 0 % (låg) och 100 % (hög). Den uppskattade noggrannheten beräknas genom att köra några olika kombinationer av träningsdata för att förutsäga de märkta värdena.
Document Intelligence Studio-tränad
anpassad modell (faktura)
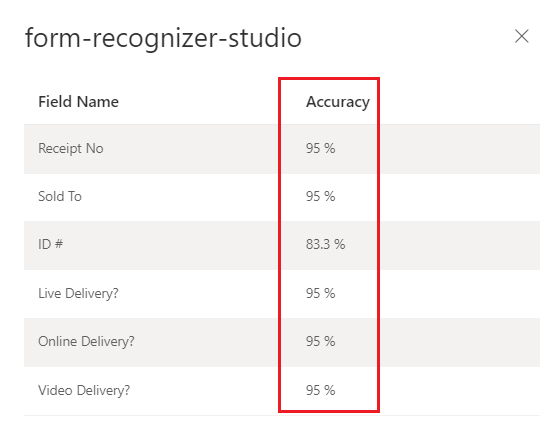
Konfidenspoäng
Kommentar
- Konfidenspoäng för tabell, rad och cell ingår nu i API-versionen 2024-02-29-preview.
- Konfidenspoäng för tabellceller från anpassade modeller läggs till i API:et från och med API:et 2024-02-29-preview.
Resultat av dokumentinformationsanalys returnerar en uppskattad konfidens för förutsagda ord, nyckel/värde-par, urvalsmarkeringar, regioner och signaturer. För närvarande returnerar inte alla dokumentfält en konfidenspoäng.
Fältförtroende anger en uppskattad sannolikhet mellan 0 och 1 att förutsägelsen är korrekt. Till exempel anger ett konfidensvärde på 0,95 (95 %) att förutsägelsen sannolikt är korrekt 19 av 20 gånger. För scenarier där noggrannheten är kritisk kan konfidens användas för att avgöra om förutsägelsen ska accepteras automatiskt eller flaggas för mänsklig granskning.
Document Intelligence Studio
Analyserade fakturamodell för fördefinierad faktura
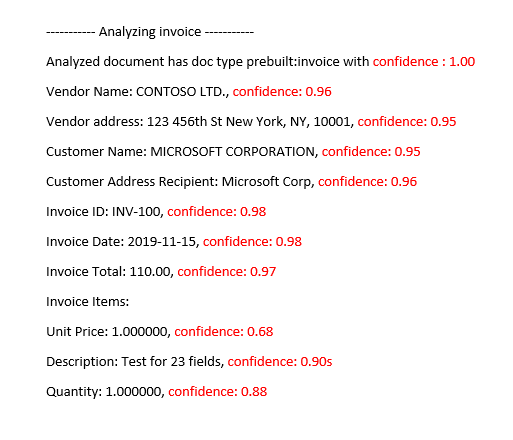
Tolka noggrannhets- och konfidenspoäng för anpassade modeller
När du tolkar konfidenspoängen från en anpassad modell bör du överväga alla konfidenspoäng som returneras från modellen. Vi börjar med en lista över alla konfidenspoäng.
- Konfidenspoäng för dokumenttyp: Förtroende för dokumenttyp är en indikator på att det analyserade dokumentet liknar dokument i träningsdatauppsättningen. När konfidensen för dokumenttypen är låg är det ett tecken på mallar eller strukturella variationer i det analyserade dokumentet. För att förbättra dokumenttypens förtroende kan du märka ett dokument med den specifika varianten och lägga till det i din träningsdatauppsättning. När modellen har tränats om bör den vara bättre utrustad för att hantera den variantklassen.
- Konfidens på fältnivå: Varje märkt fält som extraheras har en associerad konfidenspoäng. Den här poängen återspeglar modellens förtroende för positionen för det extraherade värdet. När du utvärderar konfidenspoäng bör du också titta på det underliggande extraheringsförtroendet för att generera ett omfattande förtroende för det extraherade resultatet.
OCRUtvärdera resultatet för textextrahering eller markeringsmarkeringar beroende på fälttyp för att generera en sammansatt konfidenspoäng för fältet. - Ordkonfidenspoäng Varje ord som extraheras i dokumentet har en associerad konfidenspoäng. Poängen representerar transkriptionens förtroende. Sidmatrisen innehåller en matris med ord och varje ord har ett associerat intervall och konfidenspoäng. Intervall från det anpassade fältet extraherade värden matchar intervallen för de extraherade orden.
- Konfidenspoäng för markeringsmarkering: Sidmatrisen innehåller också en matris med markeringsmarkeringar. Varje markeringsmärke har en konfidenspoäng som representerar konfidensen för markeringsmarkeringen och markeringstillståndsidentifieringen. När ett märkt fält har ett markeringsmärke är det anpassade fältvalet i kombination med markeringsmarkeringens konfidens en korrekt representation av den övergripande konfidensprecisionen.
I följande tabell visas hur du tolkar både noggrannhets- och konfidenspoängen för att mäta din anpassade modells prestanda.
| Noggrannhet | Konfidensbedömning | Result |
|---|---|---|
| Högt | Högt | • Modellen fungerar bra med de märkta nycklarna och dokumentformaten. • Du har en balanserad träningsdatauppsättning. |
| Högt | Låg | • Det analyserade dokumentet skiljer sig från träningsdatauppsättningen. • Modellen skulle ha nytta av omskolning med minst fem etiketterade dokument. • Dessa resultat kan också tyda på en formatvariation mellan träningsdatauppsättningen och det analyserade dokumentet. Överväg att lägga till en ny modell. |
| Låg | Hög | • Det här resultatet är högst osannolikt. • För poäng med låg noggrannhet lägger du till mer märkta data eller delar upp visuellt distinkta dokument i flera modeller. |
| Låg | Låg | • Lägg till mer märkta data. • Dela upp visuellt distinkta dokument i flera modeller. |
Konfidens för tabell, rad och cell
Med tillägg av tabell-, rad- och cellförtroende med API:et 2024-02-29-preview finns här några vanliga frågor som bör hjälpa dig att tolka tabell-, rad- och cellpoängen:
F: Är det möjligt att se en hög konfidenspoäng för celler, men en låg konfidenspoäng för raden?
S: Ja. De olika nivåerna av tabellförtroende (cell, rad och tabell) är avsedda att fånga korrektheten i en förutsägelse på den specifika nivån. En korrekt förutsagd cell som tillhör en rad med andra möjliga missar skulle ha hög cellförtroende, men radens konfidens bör vara låg. På samma sätt skulle en korrekt rad i en tabell med utmaningar med andra rader ha hög radförtroende medan tabellens övergripande förtroende skulle vara lågt.
F: Vad är den förväntade konfidenspoängen när celler sammanfogas? Eftersom en sammanslagning resulterar i antalet kolumner som identifieras att ändras, hur påverkas poängen?
S: Oavsett typ av tabell är förväntningarna på sammanfogade celler att de ska ha lägre konfidensvärden. Dessutom bör cellen som saknas (eftersom den sammanfogades med en intilliggande cell) också ha NULL ett värde med lägre konfidens. Hur mycket lägre dessa värden kan vara beror på träningsdatauppsättningen, den allmänna trenden för både sammanfogade och saknade celler med lägre poäng bör innehålla.
F: Vad är konfidenspoängen när ett värde är valfritt? Bör du förvänta dig en cell med ett NULL värde och en hög konfidenspoäng om värdet saknas?
S: Om din träningsdatauppsättning är representativ för cellernas valfrihet hjälper den modellen att veta hur ofta ett värde tenderar att visas i träningsuppsättningen och därmed vad som förväntas under slutsatsdragningen. Den här funktionen används när du beräknar konfidensen för antingen en förutsägelse eller för att inte göra någon förutsägelse alls (NULL). Du bör förvänta dig ett tomt fält med hög konfidens för saknade värden som till största delen är tomma även i träningsuppsättningen.
F: Hur påverkas konfidenspoäng om ett fält är valfritt och inte finns eller missas? Är förväntningarna på att förtroendepoängen svarar på den frågan?
S: När ett värde saknas från en rad har cellen ett NULL värde och en tilldelad konfidens. En hög konfidenspoäng här bör innebära att modellförutsägelse (att det inte finns något värde) är mer sannolikt korrekt. Däremot bör en låg poäng signalera mer osäkerhet från modellen (och därmed risken för ett fel, som det värde som missas).
F: Vad bör vara förväntningarna på cellförtroende och radförtroende när du extraherar en tabell med flera sidor med en rad uppdelad på sidor?
S: Förvänta dig att cellförtroendet är högt och att radförtroendet kan vara lägre än rader som inte delas. Andelen delade rader i träningsdatauppsättningen kan påverka konfidenspoängen. I allmänhet ser en delad rad annorlunda ut än de andra raderna i tabellen (därför är modellen mindre säker på att den är korrekt).
F: Är det korrekt att anta att konfidenspoängen är konsekventa mellan sidor för korssidestabeller med rader som slutar och börjar vid sidgränserna?
S: Ja. Eftersom rader ser likadana ut i form och innehåll, oavsett var de finns i dokumentet (eller på vilken sida), bör deras respektive konfidenspoäng vara konsekventa.
F: Vilket är det bästa sättet att använda de nya konfidenspoängen?
S: Titta på alla nivåer av tabellförtroende som börjar med en topp-till-botten-metod: börja med att kontrollera en tabells förtroende som helhet, öka detaljnivån till radnivån och titta på enskilda rader och titta slutligen på förtroenden på cellnivå. Beroende på vilken typ av tabell det finns några saker att tänka på:
För fasta tabeller samlar konfidensen på cellnivå redan in en hel del information om sakers korrekthet. Det innebär att det kan räcka att bara gå igenom varje cell och titta på dess förtroende för att avgöra kvaliteten på förutsägelsen. För dynamiska tabeller är nivåerna avsedda att byggas ovanpå varandra, så metoden från topp till botten är viktigare.
Säkerställa hög modellnoggrannhet
Varianser i den visuella strukturen i dina dokument påverkar modellens noggrannhet. Rapporterade noggrannhetspoäng kan vara inkonsekventa när de analyserade dokumenten skiljer sig från dokument som används i träningen. Tänk på att en uppsättning dokument kan se likadana ut när den de granskas av människor men ser olika ut i en AI-modell. Att följa är en lista över metodtipsen för träningsmodeller med högsta noggrannhet. Genom att följa dessa riktlinjer bör du skapa en modell med högre noggrannhet och konfidenspoäng under analysen och minska antalet dokument som flaggas för mänsklig granskning.
Se till att alla varianter av ett dokument ingår i träningsdatamängden. Variationerna omfattar olika format, till exempel digitala och skannade PDF-filer.
Lägg till minst fem exempel av varje typ i träningsdatauppsättningen om du förväntar dig att modellen ska analysera båda typerna av PDF-dokument.
Separera visuellt distinkta dokumenttyper för att träna olika modeller.
- Om du tar bort alla användarinmatningsvärden och dokumenten ser ut ungefär som en allmän regel måste du lägga till fler träningsdata i den befintliga modellen.
- Om dokumenten är olika delar du upp dina träningsdata i olika mappar och tränar en modell för varje variant. Sedan kan du kombinera olika varianterna till en enda modell.
Se till att du inte har några överflödiga etiketter.
Se till att etikettering av signaturer och regioner inte innehåller den omgivande texten.