Självstudie: Använda Azure Functions och Python för att bearbeta lagrade dokument
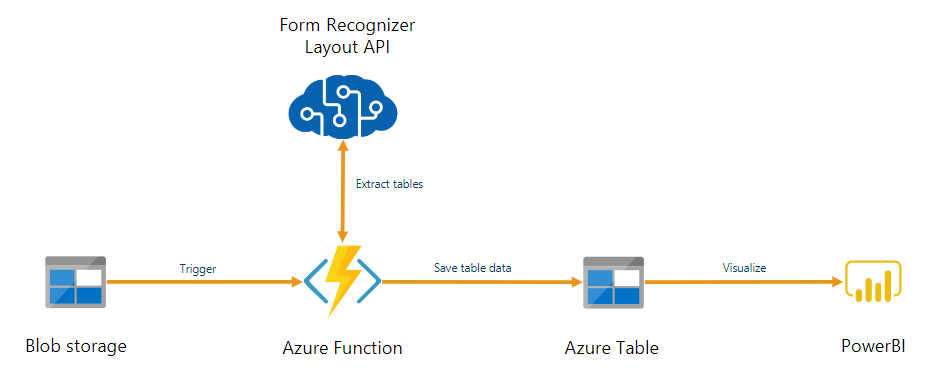
Dokumentinformation kan användas som en del av en pipeline för automatiserad databearbetning som skapats med Azure Functions. Den här guiden visar hur du använder Azure Functions för att bearbeta dokument som laddas upp till en Azure Blob Storage-container. Det här arbetsflödet extraherar tabelldata från lagrade dokument med hjälp av layoutmodellen dokumentinformation och sparar tabelldata i en .csv fil i Azure. Du kan sedan visa data med Hjälp av Microsoft Power BI (beskrivs inte här).
I den här guiden får du lära dig att:
- skapa ett Azure Storage-konto
- Skapa ett Azure Functions projekt.
- Extrahera layoutdata från uppladdade formulär.
- Ladda upp extraherade layoutdata till Azure Storage.
Förutsättningar
Azure-prenumeration - Skapa en kostnadsfritt
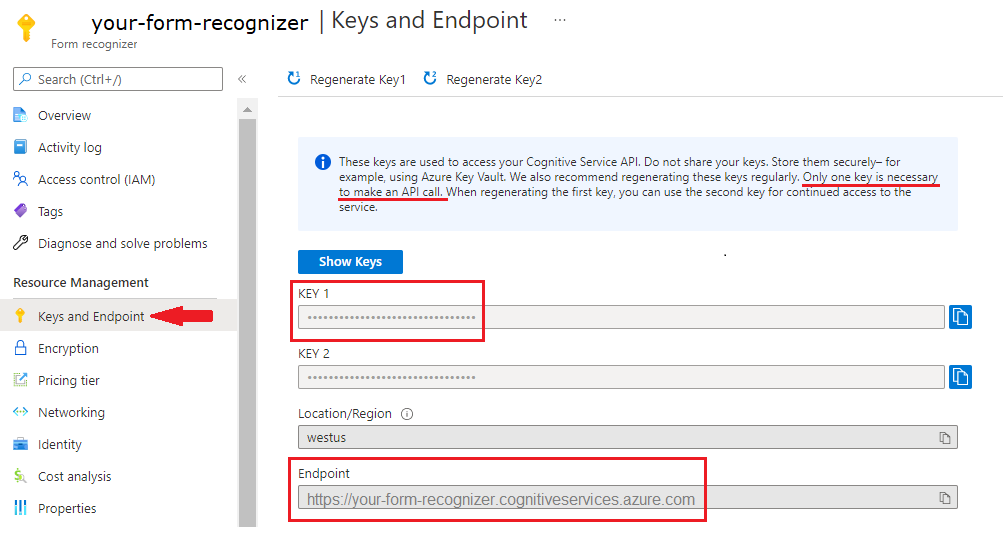
En dokumentinformationsresurs. När du har din Azure-prenumeration skapar du en dokumentinformationsresurs i Azure Portal för att hämta din nyckel och slutpunkt. Du kan använda den kostnadsfria prisnivån (
F0) för att prova tjänsten och uppgradera senare till en betald nivå för produktion.När resursen har distribuerats väljer du Gå till resurs. Du behöver nyckeln och slutpunkten från resursen som du skapar för att ansluta programmet till API:et för dokumentinformation. Du klistrar in nyckeln och slutpunkten i koden nedan senare i självstudien:
Python 3.6.x, 3.7.x, 3.8.x eller 3.9.x (Python 3.10.x stöds inte för det här projektet).
Den senaste versionen av Visual Studio Code (VS Code) med följande tillägg installerade:
Azure Functions tillägg. När den har installerats bör du se Azure-logotypen i det vänstra navigeringsfönstret.
Azure Functions Core Tools version 3.x (version 4.x stöds inte för det här projektet).
Python-tillägg för Visual Studio-kod. Mer information finns iKomma igång med Python i VS Code
Azure Storage Explorer installerat.
Ett lokalt PDF-dokument att analysera. Du kan använda vårt pdf-exempeldokument för det här projektet.
Skapa ett Azure Storage-konto
Skapa ett Azure Storage-konto för generell användning v2 i Azure Portal. Om du inte vet hur du skapar ett Azure Storage-konto med en lagringscontainer följer du dessa snabbstarter:
- Skapa ett lagringskonto. När du skapar ditt lagringskonto väljer du Standardprestanda i fältetPrestanda för instansinformation>.
- Skapa en container. När du skapar containern anger du Offentlig åtkomstnivå till Container (anonym läsåtkomst för containrar och filer) i fönstret Ny container .
I den vänstra rutan väljer du fliken Resursdelning (CORS) och tar bort den befintliga CORS-principen om den finns.
När lagringskontot har distribuerats skapar du två tomma bloblagringscontainrar med namnet input och output.
Skapa ett Azure Functions-projekt
Skapa en ny mapp med namnet functions-app som ska innehålla projektet och välj Välj.
Öppna Visual Studio Code och öppna kommandopaletten (Ctrl+Skift+P). Sök efter och välj Python:Välj tolk → välja en installerad Python-tolk som är version 3.6.x, 3.7.x, 3.8.x eller 3.9.x. Det här valet lägger till den Python-tolksökväg som du har valt i projektet.
Välj Azure-logotypen i det vänstra navigeringsfönstret.
Du ser dina befintliga Azure-resurser i vyn Resurser.
Välj den Azure-prenumeration som du använder för det här projektet och nedan bör du se Azure-funktionsappen.
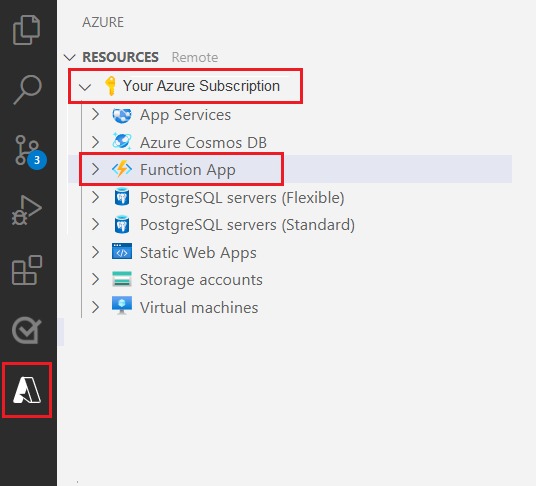
Välj avsnittet Arbetsyta (lokal) nedanför dina angivna resurser. Välj plussymbolen och välj knappen Skapa funktion .

När du uppmanas till det väljer du Skapa nytt projekt och navigerar till katalogen function-app . Välj Välj.
Du uppmanas att konfigurera flera inställningar:
Välj ett språk → välja Python.
Välj en Python-tolk för att skapa en virtuell miljö → välja tolken som du angav som standard tidigare.
Välj en mall → välja Azure Blob Storage utlösare och ge utlösaren ett namn eller acceptera standardnamnet. Tryck på Retur för att bekräfta.
Välj inställning → välj ➕Skapa ny lokal appinställning i listrutan.
Välj prenumeration → välja din Azure-prenumeration med det lagringskonto som du skapade → välj ditt lagringskonto → välj sedan namnet på lagringsindatacontainern (i det här fallet
input/{name}). Tryck på Retur för att bekräfta.Välj hur du vill öppna projektet → välj Öppna projektet i det aktuella fönstret i listrutan.
När du har slutfört de här stegen lägger VS Code till ett nytt Azure-funktionsprojekt med ett __init__.py Python-skript. Det här skriptet utlöses när en fil laddas upp till lagringscontainern för indata :
import logging
import azure.functions as func
def main(myblob: func.InputStream):
logging.info(f"Python blob trigger function processed blob \n"
f"Name: {myblob.name}\n"
f"Blob Size: {myblob.length} bytes")
Testa funktionen
Tryck på F5 för att köra den grundläggande funktionen. VS Code uppmanar dig att välja ett lagringskonto att interagera med.
Välj det lagringskonto som du skapade och fortsätt.
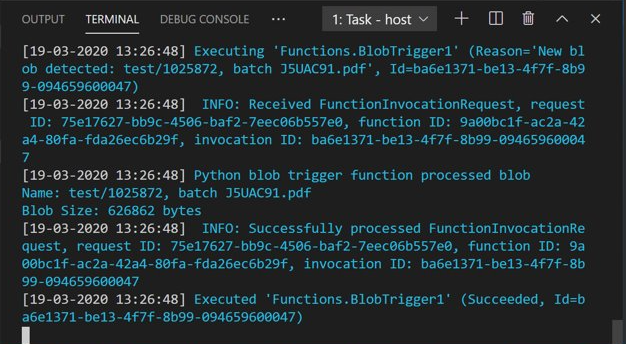
Öppna Azure Storage Explorer och ladda upp PDF-exempeldokumentet till indatacontainern. Kontrollera sedan VS Code-terminalen. Skriptet bör logga att det utlöstes av PDF-uppladdningen.
Stoppa skriptet innan du fortsätter.
Lägga till kod för dokumentbearbetning
Sedan lägger du till din egen kod i Python-skriptet för att anropa document intelligence-tjänsten och parsa de uppladdade dokumenten med hjälp av layoutmodellen Dokumentinformation.
I VS Code navigerar du till funktionens requirements.txt-fil . Den här filen definierar beroenden för skriptet. Lägg till följande Python-paket i filen:
cryptography azure-functions azure-storage-blob azure-identity requests pandas numpyÖppna sedan skriptet __init__.py . Lägg till följande
import-uttryck:import logging from azure.storage.blob import BlobServiceClient import azure.functions as func import json import time from requests import get, post import os import requests from collections import OrderedDict import numpy as np import pandas as pdDu kan lämna den genererade
mainfunktionen som den är. Du lägger till din anpassade kod i den här funktionen.# This part is automatically generated def main(myblob: func.InputStream): logging.info(f"Python blob trigger function processed blob \n" f"Name: {myblob.name}\n" f"Blob Size: {myblob.length} bytes")Följande kodblock anropar API:et Document Intelligence Analyze Layout i det uppladdade dokumentet. Fyll i slutpunkten och nyckelvärdena.
# This is the call to the Document Intelligence endpoint endpoint = r"Your Document Intelligence Endpoint" apim_key = "Your Document Intelligence Key" post_url = endpoint + "/formrecognizer/v2.1/layout/analyze" source = myblob.read() headers = { # Request headers 'Content-Type': 'application/pdf', 'Ocp-Apim-Subscription-Key': apim_key, } text1=os.path.basename(myblob.name)Viktigt
Kom ihåg att ta bort nyckeln från koden när du är klar och publicera den aldrig offentligt. För produktion använder du ett säkert sätt att lagra och komma åt dina autentiseringsuppgifter som Azure Key Vault. Mer information finns iSäkerhet för Azure AI-tjänster.
Lägg sedan till kod för att fråga tjänsten och hämta returnerade data.
resp = requests.post(url=post_url, data=source, headers=headers) if resp.status_code != 202: print("POST analyze failed:\n%s" % resp.text) quit() print("POST analyze succeeded:\n%s" % resp.headers) get_url = resp.headers["operation-location"] wait_sec = 25 time.sleep(wait_sec) # The layout API is async therefore the wait statement resp = requests.get(url=get_url, headers={"Ocp-Apim-Subscription-Key": apim_key}) resp_json = json.loads(resp.text) status = resp_json["status"] if status == "succeeded": print("POST Layout Analysis succeeded:\n%s") results = resp_json else: print("GET Layout results failed:\n%s") quit() results = resp_jsonLägg till följande kod för att ansluta till Azure Storage-utdatacontainern . Fyll i dina egna värden för lagringskontots namn och nyckel. Du kan hämta nyckeln på fliken Åtkomstnycklar för lagringsresursen i Azure Portal.
# This is the connection to the blob storage, with the Azure Python SDK blob_service_client = BlobServiceClient.from_connection_string("DefaultEndpointsProtocol=https;AccountName="Storage Account Name";AccountKey="storage account key";EndpointSuffix=core.windows.net") container_client=blob_service_client.get_container_client("output")Följande kod parsar det returnerade document intelligence-svaret, skapar en .csv-fil och laddar upp den till utdatacontainern .
Viktigt
Du behöver förmodligen redigera den här koden för att matcha strukturen för dina egna dokument.
# The code below extracts the json format into tabular data. # Please note that you need to adjust the code below to your form structure. # It probably won't work out-of-the-box for your specific form. pages = results["analyzeResult"]["pageResults"] def make_page(p): res=[] res_table=[] y=0 page = pages[p] for tab in page["tables"]: for cell in tab["cells"]: res.append(cell) res_table.append(y) y=y+1 res_table=pd.DataFrame(res_table) res=pd.DataFrame(res) res["table_num"]=res_table[0] h=res.drop(columns=["boundingBox","elements"]) h.loc[:,"rownum"]=range(0,len(h)) num_table=max(h["table_num"]) return h, num_table, p h, num_table, p= make_page(0) for k in range(num_table+1): new_table=h[h.table_num==k] new_table.loc[:,"rownum"]=range(0,len(new_table)) row_table=pages[p]["tables"][k]["rows"] col_table=pages[p]["tables"][k]["columns"] b=np.zeros((row_table,col_table)) b=pd.DataFrame(b) s=0 for i,j in zip(new_table["rowIndex"],new_table["columnIndex"]): b.loc[i,j]=new_table.loc[new_table.loc[s,"rownum"],"text"] s=s+1Slutligen laddar det sista kodblocket upp den extraherade tabellen och textdata till bloblagringselementet.
# Here is the upload to the blob storage tab1_csv=b.to_csv(header=False,index=False,mode='w') name1=(os.path.splitext(text1)[0]) +'.csv' container_client.upload_blob(name=name1,data=tab1_csv)
Kör funktionen
Tryck på F5 för att köra funktionen igen.
Använd Azure Storage Explorer för att ladda upp ett PDF-exempelformulär till lagringscontainern för indata. Den här åtgärden ska utlösa att skriptet körs, och du bör sedan se den resulterande .csv filen (visas som en tabell) i utdatacontainern .
Du kan ansluta den här containern till Power BI för att skapa omfattande visualiseringar av de data som den innehåller.
Nästa steg
I den här självstudien har du lärt dig hur du använder en Azure-funktion som skrivits i Python för att automatiskt bearbeta uppladdade PDF-dokument och mata ut innehållet i ett mer datavänligt format. Lär dig sedan hur du använder Power BI för att visa data.
- Vad är dokumentinformation?
- Läs mer om layoutmodellen