En arkitektur för stordata är utformad för att hantera datainmatning, bearbetning och analys av data som är för omfattande eller för komplicerad för traditionella databassystem.

Stordatalösningar kännetecknas av en eller flera av följande typer av arbetsbelastningar:
- Satsvis bearbetning av vilande stordatakällor.
- Realtidsbearbetning av stordata i rörelse.
- Interaktiv utforskning av stordata.
- Förutsägelseanalys och Machine Learning.
De flesta arkitekturer för stordata innehåller några av eller samtliga av följande komponenter:
Datakällor: Alla stordatalösningar utgår från en eller flera datakällor. Exempel:
- Programdatalager, till exempel relationsdatabaser.
- Statiska filer som skapas av program, till exempel loggfiler för webbservrar.
- Datakällor för realtidsdata, till exempel IoT-enheter.
Datalagring: Data för satsvisa bearbetningsåtgärder lagras vanligtvis i ett distribuerat filarkiv som kan innehålla stora volymer av stora filer i olika format. Den här typen av lager kallas ofta för en Data Lake. Exempel på alternativ för att implementera en sådan lagringslösning är Azure Data Lake Store eller blob-containrar i Azure Storage.
Satsvis bearbetning: Eftersom datamängderna är så stora måste en stordatalösning ofta bearbeta datafilerna genom att använda långvariga batchjobb för att filtrera, samla och förbereda data på andra sätt för analys. Sådana jobb består ofta i att läsa källfiler, bearbeta dem och skriva utdata till nya filer. Det är också möjligt att köra U-SQL i Azure Data Lake Analytics med hjälp av Hive-, Pig- eller anpassade Map/Reduce-jobb i ett HDInsight Hadoop-kluster, eller att använda Java-, Scala- eller Python-program i ett HDInsight Spark-kluster.
Inmatning av realtidsmeddelanden: Om lösningen omfattar realtidskällor måste arkitekturen innehålla en metod för att fånga in och lagra realtidsmeddelanden för bearbetning av dataströmmen. Det kan vara ett enkelt datalager, där inkommande meddelanden hamnar i en mapp för bearbetning. Många lösningar kräver dock ett inmatningsarkiv för meddelanden för att kunna fungera som meddelandebuffert, men också för att stödja skalbar bearbetning, tillförlitlig leverans och annan semantik för meddelandeköer. Några exempel på alternativ är Azure-händelsehubbar, Azure IoT-hubbar och Kafka.
Bearbetning av dataströmmen: När du fångar in realtidsmeddelanden måste lösningen bearbeta dem genom att filtrera, samla in och förbereda data på andra sätt för analys. Den bearbetade dataströmmen skrivs sedan till en utdatamottagare. Azure Stream Analytics erbjuder en tjänst för hanterad bearbetning av dataströmmen baserad på kontinuerlig körning av SQL-frågor som körs på obegränsade strömmar. Du kan också använda öppen källkod Apache-strömningstekniker som Spark Streaming i ett HDInsight-kluster.
Analysdatalager: Många stordatalösningar förbereder data för analys och hanterar sedan bearbetade data i ett strukturerat format som kan ta emot frågor från analysverktyg. Analysdatalagret som används för att hantera dessa frågor kan vara ett relationellt informationslager i Kimball-format, som används i de flesta traditionella Business Intelligence-lösningar (BI). Data kan även presenteras med en NoSQL-teknik för låg latens som HBase, eller en interaktiv Hive-databas som skapar en abstraktion av metadata via datafiler i det distribuerade dataarkivet. Azure Synapse Analytics är en hanterad tjänst för storskalig, molnbaserade datalagring. HDInsight stöder interaktiv Hive, HBase och Spark SQL, som även kan användas för att hantera data för analys.
Analys och rapportering: Målet för de flesta stordatalösningar är att ge insikter om data genom analys och rapportering. Vill du erbjuda användarna möjligheten att analysera data kan arkitekturen innefatta ett lager för datamodellering, till exempel en flerdimensionell OLAP-kub eller tabelldatamodellen i Azure Analysis Services. Den kan också stödja Business Intelligence som självservice med hjälp av de modellerings- och visualiseringstekniker som ingår i Microsoft Power BI eller Microsoft Excel. Analys och rapportering kan också ske i form av interaktiv datagranskning som utförs av datavetare eller dataanalytiker. För sådana scenarier stödjer många Azure-tjänster analytiska anteckningsböcker, till exempel Jupyter, som ger användarna möjlighet att utnyttja sina befintliga kompetenser med Python eller R. För storskalig datagranskning kan du använda Microsoft R Server, antingen fristående eller med Spark.
Samordning: De flesta stordatalösningar består av upprepade åtgärder för databearbetning inkapslade i arbetsflöden som omvandlar källdata, flyttar data mellan flera källor och mottagare, läser in bearbetade data till ett analysdatalager eller skickar resultaten direkt till en rapport eller instrumentpanelen. Du kan använda en samordningsteknik som Azure Data Factory eller Apache Oozie och Sqoop för att automatisera dessa arbetsflöden.
Azure innehåller många tjänster som kan användas i en arkitektur för stordata. De kan grovt delas in i två kategorier:
- Hanterade tjänster, inklusive Azure Data Lake Store, Azure Data Lake Analytics, Azure Synapse Analytics, Azure Stream Analytics, Azure Event Hubs, Azure IoT Hub och Azure Data Factory.
- Tekniker med öppen källkod baserade på Apache Hadoop-plattformen, inklusive HDFS, HBase, Hive, Spark, Oozie, Sqoop och Kafka. Teknikerna är tillgängliga i Azure via Azure HDInsight-tjänsten.
De olika alternativen utesluter inte varandra, och många lösningar kombinerar tekniker för öppen källkod med Azure-tjänster.
När ska den här arkitekturen användas?
Överväg det här arkitekturformatet när du behöver:
- Lagra och bearbeta data i volymer som är för stora för en traditionell databas.
- transformera ostrukturerade data för analys och rapportering
- samla in, bearbeta och analysera obundna dataströmmar i realtid eller med låg latens.
- Använd Azure Machine Learning eller Azure Cognitive Services.
Förmåner
- Teknikval. Du kan blanda och matcha hanterade Azure-tjänster och Apache-tekniker i HDInsight-kluster för att utnyttja befintliga kunskaper eller teknikinvesteringar.
- Prestanda genom parallellitet. Stordatalösningar dra nytta av parallellitet och möjliggör lösningar med höga prestanda som kan skalas upp för stora datavolymer.
- Elastisk skalning. Alla komponenter i stordataarkitekturen stöder skalbar etablering, så att du kan anpassa din lösning efter små eller stora arbetsbelastningar och bara betala för de resurser som du förbrukar.
- Samverkan med befintliga lösningar. Komponenterna i stordataarkitekturen används även för IoT-bearbetning och BI-lösningar för företag, så att du kan skapa en integrerad lösning för flera dataarbetsbelastningar.
Utmaningar
- Komplexitet. Stordatalösningar kan vara mycket komplexa och omfatta ett stort antal komponenter för hantering av inmatade data från flera datakällor. Det kan vara en utmaning att bygga, testa och felsöka processer för stordata. Det kan också finnas ett stort antal konfigurationsinställningar fördelade på flera system som måste användas för att optimera prestanda.
- Kompetens. Många stordatatekniker är mycket specialiserade och använder ramverk och språk som inte är typiska för mer allmänna programarkitekturer. Å andra sidan utvecklar stordatatekniker nya API:er som bygger på mer etablerade språk. Till exempel baseras U-SQL-språket i Azure Data Lake Analytics på en kombination av Transact-SQL och C#. Det finns även SQL-baserade API:er för Hive, HBase och Spark.
- Teknikens mognad. Många av de tekniker som används för stordata är under utveckling. Kärntekniker från Hadoop som Hive och Pig har stabiliserats, medan nya tekniker som Spark lanserar omfattande ändringar och förbättringar med varje ny version. Hanterade tjänster som Azure Data Lake Analytics och Azure Data Factory är relativt unga jämfört med andra Azure-tjänster, och kommer troligen att utvecklas över tid.
- Säkerhet. Stordatalösningar bygger vanligtvis på att alla statiska data lagras i en centraliserad datasjö. Att skydda åtkomsten till dessa data kan vara svårt, i synnerhet när flera program och plattformar måste mata in och använda informationen.
Bästa praxis
Utnyttja parallellitet. De flesta bearbetningstekniker för stordata distribuerar arbetsbelastningen över flera bearbetningsenheter. Det här kräver att statiska datafiler skapas och lagras i ett delbart format. Distribuerade filsystem som HDFS kan optimera läs- och skrivprestanda och den faktiska bearbetningen utförs av flera klusternoder samtidigt, vilket minskar den sammanlagda jobbtiden.
Partitionera data. Batchbearbetning sker vanligtvis enligt ett återkommande schema , till exempel varje vecka eller månad. Partitionsdatafiler, och datastrukturer som tabeller, bygger på tidsbaserade perioder som matchar bearbetningsschemat. Det här förenklar datainmatning och schemaläggning av jobb och underlättar felsökningen. Partitionstabeller som används i Hive-, U-SQL- och SQL-frågor kan dessutom ge avsevärt bättre frågeprestanda.
Använd semantik för schema vid läsning. Med hjälp av en datasjö kan du kombinera lagring för filer i flera format, oavsett om de är strukturerade, halvstrukturerade eller ostrukturerade. Använd schema vid läsning-semantik, som projicerar ett schema på data medan data bearbetas, och inte när data lagras. Det här bygger in flexibilitet i lösningen och förhindrar flaskhalsar vid datainmatning orsakade av datavalidering och typkontroll.
Bearbeta data på plats. Traditionella BI-lösningar använder ofta en process för extrahering, transformering och inläsning (ETL) för att flytta data till ett datalager. Med större datavolymer och fler olika format använder stordatalösningar vanligtvis varianter av ETL, till exempel transformering, extrahering och inläsning (TEL). Med den här metoden bearbetas data i det distribuerade datalagret, där de omvandlas till nödvändig struktur. Transformerade data flyttas sedan till ett analysdatalager.
Balansera kostnader för utnyttjande och tid. Det finns två viktiga faktorer att ta hänsyn till med jobb för satsvis bearbetning: Kostnaden per enhet för beräkningsnoderna och kostnaden per minut för att använda dessa noder och slutföra jobbet. Batchjobb kan till exempel ta åtta timmar med fyra klusternoder. Det kan dock visa sig att jobbet bara använder alla fyra noderna under de två första timmarna, och att endast två noder krävs därefter. Att köra hela jobbet på två noder kan i sådana fall öka den totala jobbtiden men inte dubblera den, och den totala kostnaden skulle därmed bli lägre. I vissa affärsscenarier kan en längre bearbetningstid vara att föredra framför den högre kostnaden för att använda underutnyttade klusterresurser.
Avgränsa klusterresurser. När du distribuerar HDInsight-kluster uppnår du vanligtvis bättre prestanda genom att etablera avgränsade klusterresurser för varje typ av arbetsbelastning. Till exempel bör du överväga att distribuera avgränsade dedikerade Spark- och Hadoop-kluster om du behöver utföra omfattande bearbetning med både Hive och Spark, även om Hive ingår i Spark-kluster. På samma sätt bör du överväga separata kluster för Storm, HBase och Hadoop om du använder HBase och Storm för bearbetning av dataströmmar med låg latens, och Hive för satsvis bearbetning.
Samordna datainmatning. I vissa fall kan befintliga företagsprogram skriva datafiler för satsvis bearbetning direkt i blob-containrar för Azure-lagring, där de kan användas av HDInsight eller Azure Data Lake Analytics. Du kommer dock ofta att behöva samordna inmatningen av data från lokala eller externa datakällor till datasjön. Vill du göra samordningen mer förutsägbar och centralt hanterbar kan du använda ett arbetsflöde eller en pipeline för samordning, till exempel de som stöds av Azure Data Factory eller Oozie.
Skrubba känsliga data tidigt. Arbetsflödet för datainmatning ska skrubba känsliga data tidigt i processen för att undvika att de sparas i datasjön.
IoT-arkitektur
Sakernas Internet (IoT) är en specialiserad delmängd av stordatalösningar. I följande diagram visas en möjlig logisk arkitektur för IoT. Diagrammet betonar komponenterna för direktuppspelning av händelser i arkitekturen.
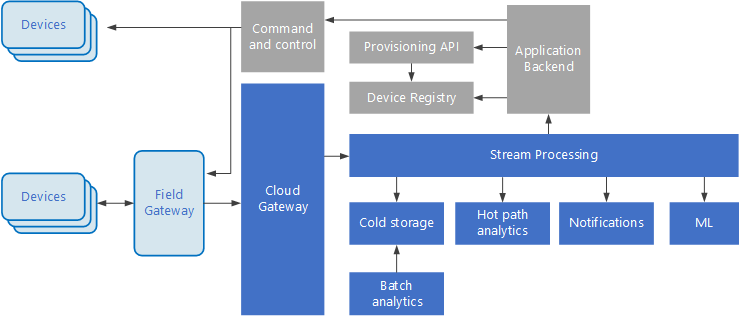
Molngatewayen matar in enhetshändelser vid molngränsen med hjälp av ett tillförlitligt meddelandesystem med kort svarstid.
Enheter kan skicka händelser direkt till molngatewayen eller via en fältgateway. En fältgateway är en särskild enhet eller programvara, vanligtvis samordnat med de enheter som tar emot händelser och vidarebefordrar dem till molngatewayen. Fältgatewayen kan också förbearbeta råa enhetshändelser och utföra funktioner, till exempel filtrering, aggregering eller omvandling av protokollet.
Efter inmatningen går händelserna igenom en eller flera strömprocessorer som kan dirigera data (till exempel för lagring) eller utföra analyser och annan bearbetning.
Här följer några vanliga bearbetningstyper. (Listan är inte komplett.)
Skriva händelsedata till kall lagring för arkivering eller batchanalyser.
Het sökvägsanalys kan analysera händelseströmmen i (nära) realtid, för att identifiera avvikelser, identifiera mönster över rullande tidsfönster eller utlösa aviseringar när ett specifikt villkor uppträder i dataströmmen.
Hantering av särskilda typer av icke-telemetrimeddelanden från enheter, till exempel meddelanden och larm.
Maskininlärning.
I rutorna som är skuggade grått visas komponenterna i ett IoT-system som inte är direkt relaterade till händelseströmning, utan inkluderas här för fullständighetens skull.
Enhetsregistret är en databas med etablerade enheter, inklusive enhets-ID:n och vanligtvis enhetsmetadata, till exempel plats.
Etablerings-API är ett gemensamt externt gränssnitt för etablering och registrering av nya enheter.
I vissa IoT-lösningar kan kommando- och styrningsmeddelanden skickas till enheter.
I det här avsnittet visas en översikt på mycket hög nivå över IoT och det finns många nyanser och utmaningar att tänka på. En mer detaljerad referensarkitektur och beskrivning finns i referensarkitekturen för Microsoft Azure IoT (PDF-nedladdning).
Nästa steg
- Läs mer om stordataarkitekturer.
- Läs mer om arkitekturdesign för Sakernas Internet (IoT).