Artificiell intelligens erbjuder potential att transformera detaljhandeln som vi känner den idag. Det är rimligt att tro att återförsäljare kommer att utveckla en arkitektur för kundupplevelse som stöds av AI. Vissa förväntningar är att en plattform som utökas med AI kommer att ge en intäktsökning på grund av hyperanpassning. Den digitala handeln fortsätter att öka kundernas förväntningar, preferenser och beteende. Krav som realtidsengagemang, relevanta rekommendationer och hyperanpassning driver fart och bekvämlighet med ett klick på en knapp. Vi möjliggör intelligens i program genom naturligt tal, syn och så vidare. Den här informationen möjliggör förbättringar i detaljhandeln som ökar värdet och stör hur kunderna handlar.
Det här dokumentet fokuserar på AI-begreppet visuell sökning och innehåller några viktiga överväganden kring implementeringen. Det innehåller ett arbetsflödesexempel och mappar dess faser till relevanta Azure-tekniker. Konceptet bygger på att kunder kan utnyttja en bild som tas med deras mobila enhet eller som finns på Internet. De skulle göra en sökning av relevanta och liknande föremål, beroende på avsikten med upplevelsen. Det innebär att visuell sökning förbättrar hastigheten från textinmatning till en bild med flera metadatapunkter för att snabbt visa alla tillämpliga objekt som är tillgängliga.
Visuella sökmotorer
Visuella sökmotorer hämtar information med bilder som indata och ofta, men inte uteslutande, som utdata också.
Motorer blir allt vanligare inom detaljhandeln och av mycket goda skäl:
- Omkring 75 % av internetanvändarna söker efter bilder eller videor av en produkt innan de gör ett köp, enligt en Emarketer-rapport som publicerades 2017.
- 74 % av konsumenterna tycker också att textsökningar är ineffektiva, enligt en rapport från Slyce (ett visuellt sökföretag) från 2015.
Därför kommer bildigenkänningsmarknaden att vara värd mer än 25 miljarder dollar 2019, enligt forskning från Markets & Markets.
Tekniken har redan fått fäste med stora e-handelsvarumärken, som också har bidragit avsevärt till dess utveckling. De mest framstående tidiga adoptörerna är förmodligen:
- eBay med sina Image Search och "Hitta det på eBay" verktyg i sin app (detta är för närvarande bara en mobil upplevelse).
- Pinterest med sitt identifieringsverktyg för visuellt Lens-objekt.
- Microsoft med visuell Bing-sökning.
Anta och anpassa
Som tur är behöver du inte stora mängder databehandlingskraft för att dra nytta av visuell sökning. Alla företag med en avbildningskatalog kan dra nytta av Microsofts AI-expertis som är inbyggd i dess Azure-tjänster.
API för visuell sökning i Bing är ett sätt att extrahera kontextinformation från bilder, till exempel identifiera heminredning, mode, flera typer av produkter och så vidare.
Den returnerar också visuellt liknande bilder från sin egen katalog, produkter med relativa shoppingkällor, relaterade sökningar. Även om det är intressant kommer detta att vara av begränsad användning om ditt företag inte är en av dessa källor.
Bing kommer också att tillhandahålla:
- Taggar som gör att du kan utforska objekt eller begrepp som finns i bilden.
- Avgränsningslådor för områden av intresse för bilden (till exempel för kläder eller möbler).
Du kan ta den informationen för att minska sökutrymmet (och tiden) till ett företags produktkatalog avsevärt, vilket begränsar den till objekt som de i regionen och kategorin av intresse.
Implementera dina egna
Det finns några viktiga komponenter att tänka på när du implementerar visuell sökning:
- Mata in och filtrera bilder
- Lagrings- och hämtningstekniker
- Funktionalisering, kodning eller "hashing"
- Likhetsmått eller avstånd och rangordning
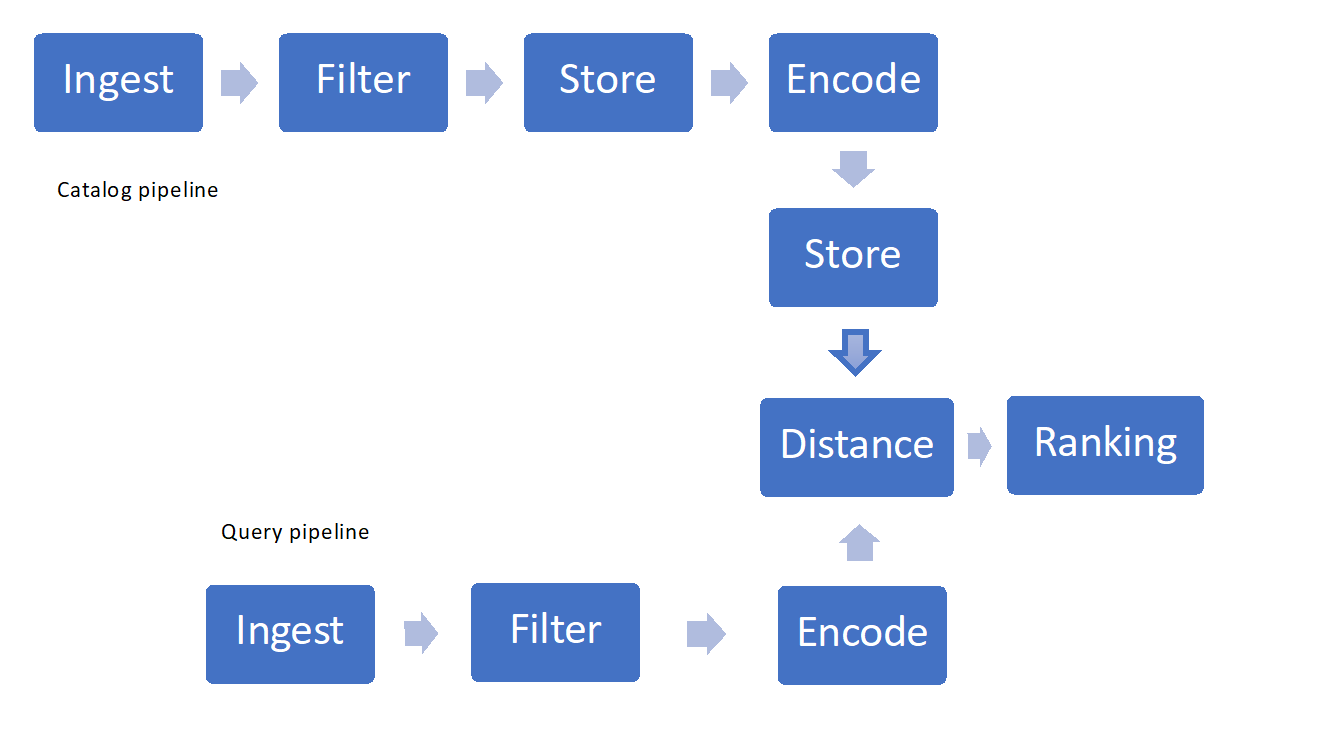
Bild 1: Exempel på pipeline för visuell sökning
Hämta bilderna
Om du inte äger en bildkatalog kan du behöva träna algoritmerna på öppet tillgängliga datauppsättningar, till exempel mode MNIST, djupmode och så vidare. De innehåller flera produktkategorier och används ofta för att jämföra bildkategorisering och sökalgoritmer.

Bild 2: Ett exempel från datauppsättningen DeepFashion
Filtrera bilderna
De flesta benchmark-datauppsättningar, till exempel de som nämnts tidigare, har redan bearbetats i förväg.
Om du skapar ett eget riktmärke vill du åtminstone att bilderna ska ha samma storlek, främst beroende på de indata som modellen tränas för.
I många fall är det bäst att också normalisera bildernas ljusstyrka. Beroende på detaljnivån för sökningen kan färgen också vara redundant information, så att minska till svartvitt hjälper till med bearbetningstiderna.
Sist men inte minst ska bilddatauppsättningen balanseras mellan de olika klasser som den representerar.
Avbildningsdatabas
Datalagret är en särskilt känslig komponent i din arkitektur. Den innehåller:
- Bilder
- Metadata om bilderna (storlek, taggar, produkt-SKU:er, beskrivning)
- Data som genereras av maskininlärningsmodellen (till exempel en numerisk vektor med 4 096 element per bild)
När du hämtar bilder från olika källor eller använder flera maskininlärningsmodeller för optimala prestanda ändras datastrukturen. Det är därför viktigt att välja en teknik eller kombination som kan hantera halvstrukturerade data och inget fast schema.
Du kanske också vill kräva ett minsta antal användbara datapunkter (till exempel en bildidentifierare eller nyckel, en produkt-SKU, en beskrivning eller ett taggfält).
Azure Cosmos DB erbjuder den flexibilitet som krävs och en mängd olika åtkomstmekanismer för program som bygger på den (vilket hjälper dig med katalogsökningen). Man måste dock vara noga med att driva det bästa priset/prestandan. Azure Cosmos DB tillåter att dokumentbilagor lagras, men det finns en total gräns per konto och det kan vara ett kostsamt förslag. Det är vanligt att lagra de faktiska avbildningsfilerna i blobar och infoga en länk till dem i databasen. När det gäller Azure Cosmos DB innebär detta att skapa ett dokument som innehåller katalogegenskaperna som är associerade med avbildningen (till exempel en SKU, tagg och så vidare) och en bifogad fil som innehåller URL:en för bildfilen (till exempel i Azure Blob Storage, OneDrive och så vidare).
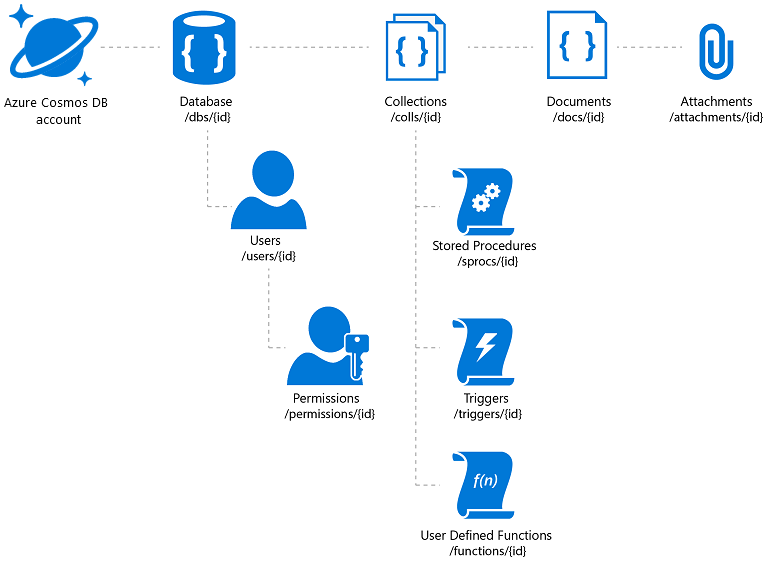
Bild 3: Hierarkisk resursmodell i Azure Cosmos DB
Om du planerar att dra nytta av den globala distributionen av Azure Cosmos DB bör du tänka på att den replikerar dokument och bifogade filer, men inte de länkade filerna. Du kanske vill överväga ett innehållsdistributionsnätverk för dem.
Andra tillämpliga tekniker är en kombination av Azure SQL Database (om ett fast schema är acceptabelt) och blobbar, eller till och med Azure-tabeller och blobbar för billig och snabb lagring och hämtning.
Extrahering av funktioner och kodning
Kodningsprocessen extraherar framträdande funktioner från bilder i databasen och mappar var och en av dem till en gles "funktionsvektor" (en vektor med många nollor) som kan ha tusentals komponenter. Den här vektorn är en numerisk representation av de funktioner (till exempel kanter och former) som kännetecknar bilden. Det liknar en kod.
Tekniker för extrahering av funktioner använder vanligtvis mekanismer för överföringsinlärning. Detta inträffar när du väljer ett förtränat neuralt nätverk, kör varje bild genom det och lagrar funktionsvektorn som skapas i avbildningsdatabasen. På så sätt "överför" du inlärningen från den som har tränat nätverket. Microsoft har utvecklat och publicerat flera förtränade nätverk som har använts i stor utsträckning för bildigenkänningsuppgifter, till exempel ResNet50.
Beroende på det neurala nätverket blir funktionsvektorn mer eller mindre lång och gles, och därför varierar kraven på minne och lagring.
Du kan också upptäcka att olika nätverk gäller för olika kategorier, och därför kan en implementering av visuell sökning faktiskt generera funktionsvektorer av varierande storlek.
Förtränade neurala nätverk är relativt enkla att använda, men kanske inte lika effektiva som en anpassad modell som tränats i avbildningskatalogen. Dessa förtränade nätverk är vanligtvis utformade för klassificering av benchmark-datauppsättningar i stället för att söka på din specifika samling av bilder.
Du kanske vill ändra och träna om dem så att de skapar både en kategoriförutsägelse och en tät (t.ex. mindre, inte gles) vektor, vilket är mycket användbart för att begränsa sökutrymmet, minska minnes- och lagringskraven. Binära vektorer kan användas och kallas ofta " semantisk hash" – en term som härleds från metoder för dokumentkodning och hämtning. Den binära representationen förenklar ytterligare beräkningar.
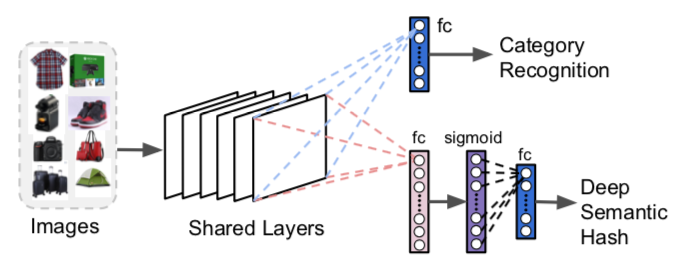
Bild 4: Ändringar i ResNet för visuell sökning – F. Yang et al., 2017
Oavsett om du väljer förtränade modeller eller utvecklar egna måste du fortfarande bestämma var du ska köra funktionaliseringen och/eller träningen av själva modellen.
Azure erbjuder flera alternativ: virtuella datorer, Azure Batch, Batch AI, Databricks-kluster. I samtliga fall ges dock bästa pris/prestanda med hjälp av GPU:er.
Microsoft har också nyligen meddelat tillgängligheten för FPGA för snabb beräkning till en bråkdel av GPU-kostnaden (projektet Brainwave). Men i skrivande stund är det här erbjudandet begränsat till vissa nätverksarkitekturer, så du måste utvärdera deras prestanda noga.
Likhetsmått eller avstånd
När bilderna representeras i funktionsvektorutrymmet blir det en fråga om att definiera ett avståndsmått mellan punkter i ett sådant utrymme att hitta likheter. När ett avstånd har definierats kan du beräkna kluster med liknande bilder och/eller definiera likhetsmatriser. Beroende på vilket avståndsmått som valts kan resultatet variera. Det vanligaste euklidiska avståndsmåttet över verkliga talvektorer är till exempel lätt att förstå: det fångar avståndets omfattning. Det är dock ganska ineffektivt när det gäller beräkning.
Cosinnavstånd används ofta för att fånga vektorns orientering snarare än dess storlek.
Alternativ som Hamming avstånd över binära representationer handel viss noggrannhet för effektivitet och hastighet.
Kombinationen av vektorstorlek och avståndsmått avgör hur beräkningsintensivt och minnesintensivt sökningen blir.
Sök och rangordning
När likheten har definierats måste vi utforma en effektiv metod för att hämta de närmaste N-objekten som skickas som indata och sedan returnera en lista med identifierare. Detta kallas även "bildrankning". I en stor datauppsättning är tiden för att beräkna varje avstånd oöverkomlig, så vi använder ungefärliga närmaste grannalgoritmer. Det finns flera bibliotek med öppen källkod för dessa, så du behöver inte koda dem från grunden.
Slutligen avgör kraven på minne och beräkning valet av distributionsteknik för den tränade modellen samt hög tillgänglighet. Vanligtvis partitioneras sökutrymmet och flera instanser av rangordningsalgoritmen körs parallellt. Ett alternativ som möjliggör skalbarhet och tillgänglighet är Azure Kubernetes-kluster . I så fall är det lämpligt att distribuera rangordningsmodellen över flera containrar (hantera en partition av sökutrymmet var och en) och flera noder (för hög tillgänglighet).
Deltagare
Den här artikeln underhålls av Microsoft. Det har ursprungligen skrivits av följande medarbetare.
Huvudsakliga författare:
- Giovanni Marchetti | Manager, Azure Solution Architects
- Mariya Zorotovich | Chef för kundupplevelse, HLS och ny teknik
Övriga medarbetare:
- Scott Seely | Programvaruarkitekt
Nästa steg
Implementering av visuell sökning behöver inte vara komplext. Du kan använda Bing eller skapa dina egna med Azure-tjänster, samtidigt som du drar nytta av Microsofts AI-forskning och verktyg.
Utveckla
- Information om hur du börjar skapa en anpassad tjänst finns i Översikt över API för visuell sökning i Bing
- Information om hur du skapar din första begäran finns i snabbstarterna: C# | Java | node.js Python |
- Bekanta dig med referensen för API för visuell sökning.
Bakgrund
- Segmentering av djupinlärningsbild: Microsoft-papper beskriver processen för att separera bilder från bakgrunder
- Visuell sökning på Ebay: Cornell University research
- Visual Discovery vid Pinterest Cornell University research
- Forskning vid Semantic Hashing University of Toronto