Den här referensarkitekturen innehåller strategier för den partitioneringsmodell som händelseinmatningstjänster använder. Eftersom tjänster för händelseinmatning tillhandahåller lösningar för storskalig händelseströmning måste de bearbeta händelser parallellt och kunna upprätthålla händelseordningen. De måste också balansera belastningar och erbjuda skalbarhet. Partitioneringsmodeller uppfyller alla dessa krav.
Arkitektur

I mitten av diagrammet finns en ruta med namnet Kafka Cluster eller Event Hub Namespace. Tre mindre lådor sitter inuti lådan. Var och en är märkt ämne eller händelsehubb, och var och en innehåller flera rektanglar med etiketten Partition. Ovanför huvudrutan finns rektanglar märkta Producent. Pilarna pekar från producenterna till huvudrutan. Under huvudrutan finns rektanglar med etiketten Konsument. Pilar pekar från huvudrutan till konsumenterna och är märkta med olika förskjutningsvärden. En enda blå ram med etiketten Konsumentgrupp omger två av konsumenterna och grupperar dem tillsammans.
Ladda ned en Visio-fil med den här arkitekturen.
Dataflöde
Producenter publicerar data till inmatningstjänsten eller pipelinen. Event Hubs-pipelines består av namnområden. Kafka-motsvarigheterna är kluster.
Pipelinen distribuerar inkommande händelser mellan partitioner. I varje partition förblir händelserna i produktionsordning. Händelser förblir dock inte i sekvens över partitioner. Antalet partitioner kan påverka dataflödet eller mängden data som passerar genom systemet under en viss tidsperiod. Pipelines mäter vanligtvis dataflöde i bitar per sekund (bps) och ibland i datapaket per sekund (pps).
Partitioner finns i namngivna strömmar av händelser. Event Hubs anropar dessa streams-händelsehubbar. I Kafka är det ämnen.
Konsumenter är processer eller program som prenumererar på ämnen. Varje konsument läser en specifik delmängd av händelseströmmen. Den delmängden kan innehålla mer än en partition. Pipelinen kan dock tilldela varje partition till endast en konsument per konsumentgrupp i taget.
Flera konsumenter kan utgöra konsumentgrupper. När en grupp prenumererar på ett ämne har varje konsument i gruppen en separat vy över händelseströmmen. Programmen fungerar oberoende av varandra, i sin egen takt. Pipelinen kan också använda konsumentgrupper för belastningsdelning.
Konsumenter bearbetar flödet av publicerade händelser som de prenumererar på. Konsumenterna deltar också i kontrollpunkter. Genom den här processen använder prenumeranter förskjutningar för att markera sin position i en partitionshändelsesekvens. En förskjutning är en platshållare som fungerar som ett bokmärke för att identifiera den senaste händelsen som användaren läste.
Information om scenario
Mer specifikt beskrivs följande strategier i det här dokumentet:
- Tilldela händelser till partitioner.
- Hur många partitioner som ska användas.
- Så här tilldelar du partitioner till prenumeranter vid ombalansering.
Det finns många tekniker för inmatning av händelser, bland annat:
- Azure Event Hubs: En fullständigt hanterad plattform för stordataströmning.
- Apache Kafka: En dataströmbearbetningsplattform med öppen källkod.
- Event Hubs med Kafka: Ett alternativ till att köra ditt eget Kafka-kluster. Den här Event Hubs-funktionen tillhandahåller en slutpunkt som är kompatibel med Kafka-API:er.
Förutom att erbjuda partitioneringsstrategier pekar det här dokumentet också på skillnader mellan partitionering i Event Hubs och Kafka.
Rekommendationer
Tänk på följande rekommendationer när du utvecklar en partitioneringsstrategi.
Distribuera händelser till partitioner
En aspekt av partitioneringsstrategin är tilldelningsprincipen. En händelse som anländer till en inmatningstjänst går till en partition. Tilldelningsprincipen avgör partitionen.
Varje händelse lagrar sitt innehåll i sitt värde. Förutom värdet innehåller varje händelse också en nyckel, som följande diagram visar:

I mitten av diagrammet finns flera par rutor. En etikett under rutorna anger att varje par representerar ett meddelande. Varje meddelande innehåller en blå ruta med etiketten Nyckel och en svart ruta med etiketten Värde. Meddelandena ordnas vågrätt. Pilar mellan meddelanden som pekar från vänster till höger anger att meddelandena bildar en sekvens. Ovanför meddelandena finns etiketten Stream. Hakparenteser anger att sekvensen bildar en ström.
Ladda ned en Visio-fil med den här arkitekturen.
Nyckeln innehåller data om händelsen och kan också spela en roll i tilldelningsprincipen.
Det finns flera metoder för att tilldela händelser till partitioner:
- Som standard distribuerar tjänsterna händelser mellan partitioner på ett resursallokeringssätt.
- Producenter kan ange ett partitions-ID med en händelse. Händelsen går sedan till partitionen med det ID:t.
- Producenter kan ange ett värde för händelsenyckeln. När de gör det avgör en hash-baserad partitionerare ett hash-värde från nyckeln. Händelsen går sedan till partitionen som är associerad med det hash-värdet.
Tänk på följande rekommendationer när du väljer en tilldelningsprincip:
- Använd partitions-ID när konsumenter bara är intresserade av vissa händelser. När dessa händelser flödar till en enda partition kan konsumenten enkelt ta emot dem genom att prenumerera på partitionen.
- Använd nycklar när konsumenter behöver ta emot händelser i produktionsordning. Eftersom alla händelser med samma nyckel går till samma partition kan händelser med nyckelvärden behålla sin ordning under bearbetningen. Konsumenterna får dem sedan i den ordningen.
- Om händelsegruppering eller beställning inte krävs med Kafka bör du undvika nycklar. Producenten känner inte till statusen för målpartitionen i Kafka. Om en nyckel dirigerar en händelse till en partition som är nere kan fördröjningar eller förlorade händelser resultera. I Event Hubs passerar händelser med nycklar först genom en gateway innan de fortsätter till en partition. Den här metoden förhindrar att händelser går till otillgängliga partitioner.
- Dataformen kan påverka partitioneringsmetoden. Fundera på hur nedströmsarkitekturen distribuerar data när du bestämmer dig för tilldelningar.
- Om konsumenterna aggregerar data för ett visst attribut bör du också partitionera på det attributet.
- När lagringseffektivitet är ett problem kan partitionering på ett attribut som koncentrerar data för att påskynda lagringsåtgärderna.
- Inmatningspipelines shardar ibland data för att komma runt problem med resursflaskhalsar. I dessa miljöer justerar du partitioneringen med hur fragmenten delas i databasen.
Fastställa antalet partitioner
Använd dessa riktlinjer för att bestämma hur många partitioner som ska användas:
- Använd fler partitioner för att uppnå mer dataflöde. Varje konsument läser från sin tilldelade partition. Så med fler partitioner kan fler konsumenter ta emot händelser från ett ämne samtidigt.
- Använd minst lika många partitioner som värdet för ditt måldataflöde i megabyte.
- Använd minst lika många partitioner som konsumenter för att undvika svältande konsumenter. Anta till exempel att åtta partitioner har tilldelats åtta konsumenter. Alla ytterligare konsumenter som prenumererar måste vänta. Du kan också hålla en eller två konsumenter redo att ta emot händelser när en befintlig konsument misslyckas.
- Använd fler nycklar än partitioner. Annars tar vissa partitioner inte emot några händelser, vilket leder till obalanserade partitionsbelastningar.
- I både Kafka och Event Hubs på nivån Dedikerad nivå kan du ändra antalet partitioner i ett operativsystem. Undvik dock att göra den ändringen om du använder nycklar för att bevara händelseordningen. Orsaken omfattar följande fakta:
- Konsumenterna förlitar sig på vissa partitioner och ordningen på de händelser de innehåller.
- När antalet partitioner ändras kan mappningen av händelser till partitioner ändras. När till exempel partitionsantalet ändras kan den här formeln skapa en annan tilldelning:
partition assignment = hash key % number of partitions - Kafka och Event Hubs försöker inte omdistribuera händelser som anlände till partitioner före shuffle. Därför gäller inte längre garantin att händelser kommer till en viss partition i publiceringsordning.
Förutom dessa riktlinjer kan du också använda den här grova formeln för att fastställa antalet partitioner:
max(t/p, t/c)
Det har följande värden:
t: Måldataflödet.p: Produktionsdataflödet på en enda partition.c: Dataflödet för förbrukning på en enskild partition.
Tänk till exempel på den här situationen:
- Det idealiska dataflödet är 2 Mbit/s. För formeln
tär 2 Mbit/s. - En producent skickar händelser med en hastighet av 1 000 händelser per sekund, vilket gör
p1 Mbit/s. - En konsument tar emot händelser med en hastighet av 500 händelser per sekund och anger
ctill 0,5 Mbit/s.
Med dessa värden är antalet partitioner 4:
max(t/p, t/c) = max(2/1, 2/0.5) = max(2, 4) = 4
Tänk på följande när du mäter dataflödet:
Den långsammaste konsumenten avgör förbrukningsdataflödet. Ibland finns det dock ingen information om underordnade konsumentprogram. I det här fallet beräknar du dataflödet genom att börja med en partition som baslinje. (Använd endast den här konfigurationen i testmiljöer, inte i produktionssystem). Event Hubs med standardnivåpriser och en partition bör generera dataflöde mellan 1 Mbit/s och 20 Mbit/s.
Konsumenter kan endast använda händelser från en inmatningspipeline i hög takt om producenterna skickar händelser i en jämförbar takt. För att fastställa den totala kapacitet som krävs för inmatningspipelinen mäter du producentens dataflöde, inte bara konsumentens.
Tilldela partitioner till konsumenter vid ombalansering
När konsumenter prenumererar på eller avregistrerar sig balanserar pipelinen om tilldelningen av partitioner till konsumenter. Som standard använder Event Hubs och Kafka en resursallokeringsmetod för ombalansering. Den här metoden distribuerar partitioner jämnt mellan medlemmar.
Om du inte vill att pipelinen automatiskt ska balansera om tilldelningar med Kafka kan du statiskt tilldela partitioner till konsumenter. Men du måste se till att alla partitioner har prenumeranter och att belastningarna är balanserade.
Förutom standardstrategin för resursallokering erbjuder Kafka två andra strategier för automatisk ombalansering:
- Intervalltilldelare: Använd den här metoden för att sammanföra partitioner från olika ämnen. Den här tilldelningen identifierar ämnen som använder samma antal partitioner och samma logik för nyckelpartitionering. Sedan kopplas partitioner från dessa ämnen när du gör tilldelningar till konsumenter.
- Fäst tilldelare: Använd den här tilldelningen för att minimera partitionsflytten. Precis som resursallokering säkerställer den här strategin en enhetlig fördelning. Den bevarar dock även befintliga tilldelningar under ombalansering.
Att tänka på
Tänk på dessa saker när du använder en partitioneringsmodell.
Skalbarhet
Om du använder ett stort antal partitioner kan du begränsa skalbarheten:
I Kafka lagrar koordinatorer händelsedata och förskjutningar i filer. Ju fler partitioner du använder, desto mer öppna filhandtag har du. Om operativsystemet begränsar antalet öppna filer kan du behöva konfigurera om den inställningen.
I Event Hubs står användarna inte inför filsystembegränsningar. Varje partition hanterar dock sina egna Azure-blobfiler och optimerar dem i bakgrunden. Ett stort antal partitioner gör det dyrt att underhålla kontrollpunktsdata. Anledningen är att I/O-åtgärder kan vara tidskrävande och lagrings-API-anropen är proportionella mot antalet partitioner.
Varje producent för Kafka och Event Hubs lagrar händelser i en buffert tills en stor batch är tillgänglig eller tills en viss tid går. Sedan skickar producenten händelserna till inmatningspipelinen. Producenten har en buffert för varje partition. När antalet partitioner ökar utökas även minnesbehovet för klienten. Om konsumenter får händelser i batchar kan de också stöta på samma problem. När konsumenter prenumererar på ett stort antal partitioner men har begränsat minne för buffring kan det uppstå problem.
Tillgänglighet
Ett stort antal partitioner kan också påverka tillgängligheten negativt:
Kafka placerar vanligtvis partitioner på olika koordinatorer. När en asynkron meddelandekö misslyckas balanserar Kafka om partitionerna för att undvika att förlora händelser. Ju fler partitioner det finns för att balansera om, desto längre tid tar redundansen, vilket ökar otillgängligheten. Begränsa antalet partitioner till de låga tusentals för att undvika det här problemet.
Ju fler partitioner du använder, desto mer fysiska resurser används. Beroende på klientsvaret kan fler fel sedan inträffa.
Med fler partitioner måste belastningsutjämningsprocessen fungera med fler rörliga delar och mer stress. Tillfälliga undantag kan uppstå. Dessa fel kan uppstå när det finns tillfälliga störningar, till exempel nätverksproblem eller tillfälliga Internettjänster. De kan visas under en uppgradering eller belastningsutjämning när Event Hubs ibland flyttar partitioner till olika noder. Hantera tillfälligt beteende genom att införliva återförsök för att minimera fel. Använd EventProcessorClient i .NET- och Java-SDK:erna eller EventHubConsumerClient i Python- och JavaScript-SDK:erna för att förenkla den här processen.
Prestanda
I Kafka bekräftas händelser när pipelinen har replikerat dem över alla in-sync-repliker. Den här metoden säkerställer hög tillgänglighet för händelser. Eftersom konsumenter bara tar emot bekräftade händelser läggs replikeringsprocessen till i svarstiden. I inmatningspipelines refererar den här termen till tiden mellan när en producent publicerar en händelse och en konsument läser den. Enligt experiment som Confluent körde kan det ta cirka 20 millisekunder att replikera 1 000 partitioner från en asynkron meddelandekö till en annan. Svarstiden från slutpunkt till slutpunkt är då minst 20 millisekunder. När antalet partitioner ökar ytterligare växer även svarstiden. Den här nackdelen gäller inte för Event Hubs.
Säkerhet
I Event Hubs använder utgivare en SAS-token (Signatur för delad åtkomst) för att identifiera sig själva. Konsumenter ansluter via en AMQP 1.0-session. Den här tillståndsmedvetna dubbelriktade kommunikationskanalen ger ett säkert sätt att överföra meddelanden. Kafka erbjuder även funktioner för kryptering, auktorisering och autentisering, men du måste implementera dem själv.
Distribuera det här scenariot
Följande kodexempel visar hur du underhåller dataflödet, distribuerar till en viss partition och bevarar händelseordningen.
Underhålla dataflöde
Det här exemplet omfattar loggaggregering. Målet är inte att bearbeta händelser i ordning, utan snarare att upprätthålla ett specifikt dataflöde.
En Kafka-klient implementerar producent- och konsumentmetoderna. Eftersom ordningen inte är viktig skickar koden inte meddelanden till specifika partitioner. I stället används standardpartitioneringstilldelningen:
public static void RunProducer(string broker, string connectionString, string topic)
{
// Set the configuration values of the producer.
var producerConfig = new ProducerConfig
{
BootstrapServers = broker,
SecurityProtocol = SecurityProtocol.SaslSsl,
SaslMechanism = SaslMechanism.Plain,
SaslUsername = "$ConnectionString",
SaslPassword = connectionString,
};
// Set the message key to Null since the code does not use it.
using (var p = new ProducerBuilder<Null, string>(producerConfig).Build())
{
try
{
// Send a fixed number of messages. Use the Produce method to generate
// many messages in rapid succession instead of the ProduceAsync method.
for (int i=0; i < NumOfMessages; i++)
{
string value = "message-" + i;
Console.WriteLine($"Sending message with key: not-specified," +
$"value: {value}, partition-id: not-specified");
p.Produce(topic, new Message<Null, string> { Value = value });
}
// Wait up to 10 seconds for any in-flight messages to be sent.
p.Flush(TimeSpan.FromSeconds(10));
}
catch (ProduceException<Null, string> e)
{
Console.WriteLine($"Delivery failed with error: {e.Error.Reason}");
}
}
}
public static void RunConsumer(string broker, string connectionString, string consumerGroup, string topic)
{
var consumerConfig = new ConsumerConfig
{
BootstrapServers = broker,
SecurityProtocol = SecurityProtocol.SaslSsl,
SocketTimeoutMs = 60000,
SessionTimeoutMs = 30000,
SaslMechanism = SaslMechanism.Plain,
SaslUsername = "$ConnectionString",
SaslPassword = connectionString,
GroupId = consumerGroup,
AutoOffsetReset = AutoOffsetReset.Earliest
};
using (var c = new ConsumerBuilder<string, string>(consumerConfig).Build())
{
c.Subscribe(topic);
CancellationTokenSource cts = new CancellationTokenSource();
Console.CancelKeyPress += (_, e) =>
{
e.Cancel = true;
cts.Cancel();
};
try
{
while (true)
{
try
{
var message = c.Consume(cts.Token);
Console.WriteLine($"Consumed - key: {message.Message.Key}, "+
$"value: {message.Message.Value}, " +
$"partition-id: {message.Partition}," +
$"offset: {message.Offset}");
}
catch (ConsumeException e)
{
Console.WriteLine($"Error occured: {e.Error.Reason}");
}
}
}
catch(OperationCanceledException)
{
// Close the consumer to ensure that it leaves the group cleanly
// and that final offsets are committed.
c.Close();
}
}
}
Det här kodexemplet ger följande resultat:
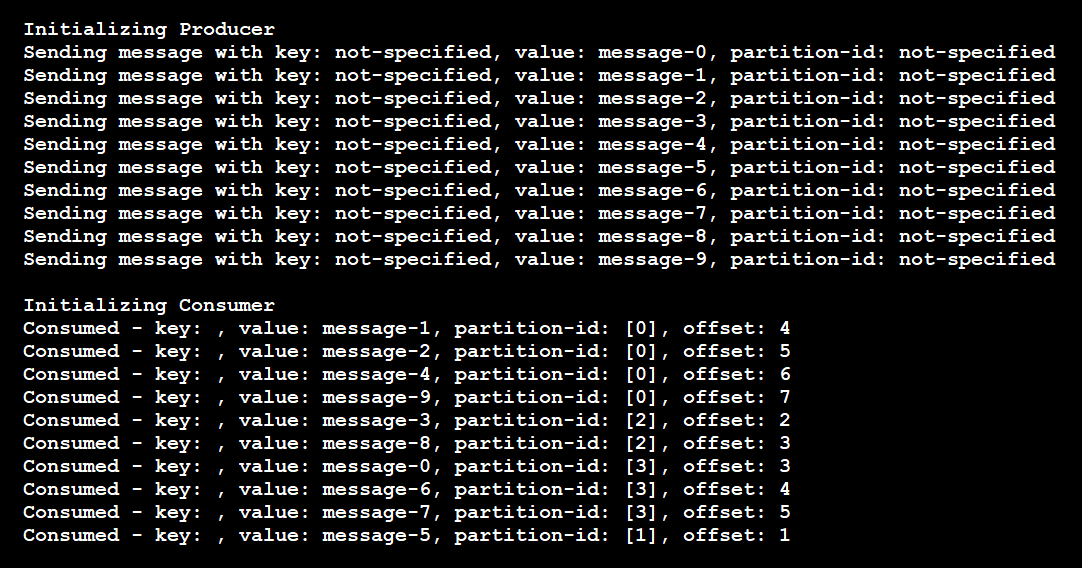
I det här fallet har ämnet fyra partitioner. Följande händelser inträffade:
- Producenten skickade 10 meddelanden, var och en utan en partitionsnyckel.
- Meddelandena kom till partitioner i slumpmässig ordning.
- En enskild konsument lyssnade på alla fyra partitionerna och tog emot meddelandena i fel ordning.
Om koden hade använt två instanser av konsumenten skulle varje instans ha prenumererat på två av de fyra partitionerna.
Distribuera till en specifik partition
Det här exemplet omfattar felmeddelanden. Anta att vissa program behöver bearbeta felmeddelanden, men alla andra meddelanden kan gå till en vanlig konsument. I det här fallet skickar producenten felmeddelanden till en specifik partition. Konsumenter som vill få felmeddelanden lyssnar på partitionen. Följande kod visar hur du implementerar det här scenariot:
// Producer code.
var topicPartition = new TopicPartition(topic, partition);
...
p.Produce(topicPartition, new Message<Null, string> { Value = value });
// Consumer code.
// Subscribe to one partition.
c.Assign(new TopicPartition(topic, partition));
// Use this code to subscribe to a list of partitions.
c.Assign(new List<TopicPartition> {
new TopicPartition(topic, partition1),
new TopicPartition(topic, partition2)
});
Som dessa resultat visar skickade producenten alla meddelanden till partition 2 och konsumenten läste bara meddelanden från partition 2:
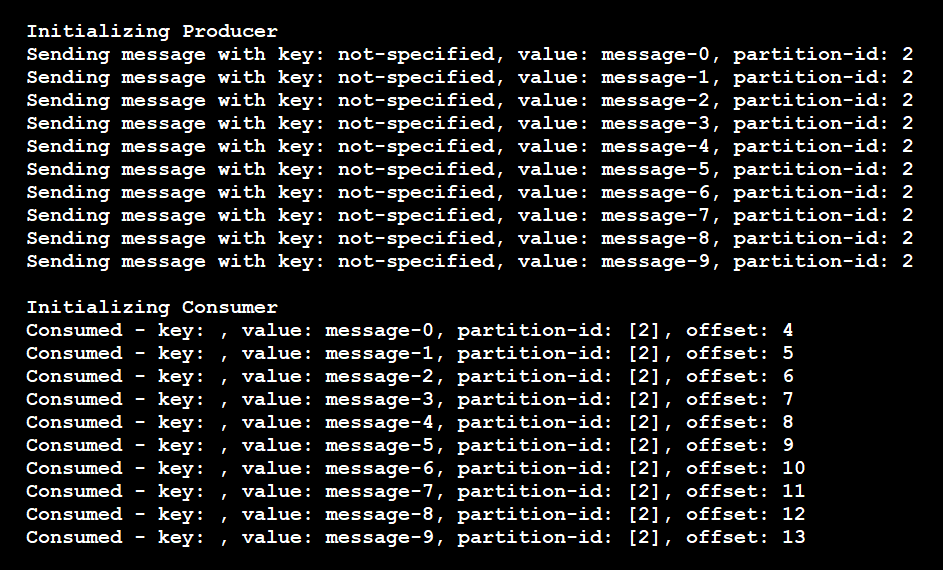
Om du i det här scenariot lägger till en annan konsumentinstans för att lyssna på det här avsnittet tilldelar pipelinen inga partitioner till den. Den nya konsumenten kommer att svälta tills den befintliga konsumenten stängs. Pipelinen tilldelar sedan en annan aktiv konsument som ska läsas från partitionen. Men pipelinen gör bara den tilldelningen om den nya konsumenten inte är dedikerad till en annan partition.
Bevara händelseordning
Det här exemplet omfattar banktransaktioner som en konsument behöver bearbeta i ordning. I det här scenariot kan du använda kund-ID för varje händelse som nyckel. För händelsevärdet använder du informationen om transaktionen. Följande kod visar en förenklad implementering av det här fallet:
Producer code
// This code assigns the key an integer value. You can also assign it any other valid key value.
using (var p = new ProducerBuilder<int, string>(producerConfig).Build())
...
p.Produce(topic, new Message<int, string> { Key = i % 2, Value = value });
Den här koden ger följande resultat:

Som dessa resultat visar använde producenten endast två unika nycklar. Meddelandena gick sedan bara till två partitioner i stället för alla fyra. Pipelinen garanterar att meddelanden med samma nyckel går till samma partition.
Deltagare
Den här artikeln underhålls av Microsoft. Det har ursprungligen skrivits av följande medarbetare.
Huvudförfattare:
- Rajasa Savant | Senior programvarutekniker
Om du vill se icke-offentliga LinkedIn-profiler loggar du in på LinkedIn.
Nästa steg
- Använda Azure Event Hubs från Apache Kafka-program
- Apache Kafka-utvecklarguide för Azure Event Hubs
- Snabbstart: Dataströmning med Event Hubs med kafka-protokollet
- Skicka händelser till och ta emot händelser från Azure Event Hubs – .NET (Azure.Messaging.EventHubs)
- Balansera partitionsbelastning över flera instanser av ditt program
- Lägg till partitioner dynamiskt i en händelsehubb (Apache Kafka-ämne) i Azure Event Hubs
- Tillgänglighet och konsekvens i Event Hubs
- Azure Event Hubs Event Processor-klientbibliotek för .NET
- Effektiva strategier för Kafka-ämnespartitionering
- Confluent-blogginlägg: Hur väljer du antalet ämnen/partitioner i ett Kafka-kluster?
Relaterade resurser
- Integrera Event Hubs med serverlösa funktioner i Azure
- Prestanda och skalning för Event Hubs och Azure Functions
- Händelsedriven arkitekturstil
- Dataströmbearbetning med fullständigt hanterade datamotorer med öppen källkod
- Mönster för Publisher-Subscriber
- Apache-scenarier med öppen källkod i Azure – Apache Kafka