Den här artikeln beskriver en arkitektur som använder Azure Machine Learning för att förutsäga delinquency och standardannolikheter för lånesökande. Modellens förutsägelser baseras på den sökandes skattebeteende. Modellen använder en enorm uppsättning datapunkter för att klassificera sökande och tillhandahålla en behörighetspoäng för varje sökande.
Apache®, Spark och flamlogotypen är antingen registrerade varumärken eller varumärken som tillhör Apache Software Foundation i USA och/eller andra länder. Inget godkännande från Apache Software Foundation underförstås av användningen av dessa märken.
Arkitektur

Ladda ned en Visio-fil med den här arkitekturen.
Dataflöde
Följande dataflöde motsvarar föregående diagram:
Lagring: Data lagras i en databas som en Azure Synapse Analytics-pool om den är strukturerad. Äldre SQL-databaser kan integreras i systemet. Halvstrukturerade och ostrukturerade data kan läsas in i en datasjö.
Inmatning och förbearbetning: Azure Synapse Analytics-bearbetningspipelines och ETL-bearbetning kan ansluta till data som lagras i Azure eller tredjepartskällor via inbyggda anslutningsappar. Azure Synapse Analytics stöder flera analysmetoder som använder SQL, Spark, Azure Data Explorer och Power BI. Du kan också använda befintlig Azure Data Factory-orkestrering för datapipelines.
Bearbetning: Azure Machine Learning används för att utveckla och hantera maskininlärningsmodellerna.
Inledande bearbetning: Under den här fasen bearbetas rådata för att skapa en kuraterad datauppsättning som ska träna en maskininlärningsmodell. Vanliga åtgärder är formatering av datatyper, imputation av saknade värden, funktionsutveckling, funktionsval och minskning av dimensionalitet.
Utbildning: Under träningsfasen använder Azure Machine Learning den bearbetade datamängden för att träna kreditriskmodellen och välja den bästa modellen.
Modellträning: Du kan använda en rad olika maskininlärningsmodeller, inklusive klassisk maskininlärning och djupinlärningsmodeller. Du kan använda hyperparameterjustering för att optimera modellprestanda.
Modellutvärdering: Azure Machine Learning utvärderar prestanda för varje tränad modell så att du kan välja den bästa för distribution.
Modellregistrering: Du registrerar den modell som presterar bäst i Azure Machine Learning. Det här steget gör modellen tillgänglig för distribution.
c. Ansvarsfull AI: Ansvarsfull AI är en metod för att utveckla, utvärdera och distribuera AI-system på ett säkert, tillförlitligt och etiskt sätt. Eftersom den här modellen härleder ett godkännande- eller avslagsbeslut för en lånebegäran måste du implementera principerna för Ansvarsfull AI.
Rättvisemått utvärderar effekten av orättvist beteende och aktiverar riskreduceringsstrategier. Känsliga funktioner och attribut identifieras i datamängden och i kohorter (delmängder) av data. Mer information finns i Modellprestanda och rättvisa.
Tolkning är ett mått på hur väl du kan förstå beteendet hos en maskininlärningsmodell. Den här komponenten i Ansvarsfull AI genererar begripliga beskrivningar av modellens förutsägelser. Mer information finns i Modelltolkning.
Distribution av maskininlärning i realtid: Du måste använda modellinferens i realtid när begäran måste granskas omedelbart för godkännande.
- Slutpunkt för hanterad maskininlärning online. För realtidsbedömning måste du välja ett lämpligt beräkningsmål.
- Online-begäranden om lån använder realtidsbedömning baserat på indata från ansökningsformuläret eller låneansökan.
- Beslutet och indata som används för modellbedömning lagras i beständig lagring och kan hämtas för framtida referens.
Distribution av batchmaskininlärning: För offlinelånebearbetning är modellen schemalagd att utlösas med jämna mellanrum.
- Hanterad batchslutpunkt. Batch-slutsatsdragning schemaläggs och resultatdatauppsättningen skapas. Besluten grundas på sökandens kreditvärdighet.
- Resultatuppsättningen för bedömning från batchbearbetning sparas i databasen eller Azure Synapse Analytics-informationslagret.
Gränssnitt för data om sökandes verksamhet: De uppgifter som sökanden har inmatat, den interna kreditprofilen och modellens beslut mellanlagras och lagras i lämpliga datatjänster. Den här informationen används i beslutsmotorn för framtida bedömning, så de dokumenteras.
- Lagring: All information om kreditbearbetning behålls i beständig lagring.
- Användargränssnitt: Godkännande- eller avslagsbeslutet presenteras för den sökande.
Rapportering: Realtidsinformation om antalet program som bearbetas och godkänner eller nekar resultat presenteras kontinuerligt för chefer och ledarskap. Exempel på rapportering är rapporter i nära realtid om godkända belopp, den låneportfölj som skapats och modellprestanda.
Komponenter
- Azure Blob Storage tillhandahåller skalbar objektlagring för ostrukturerade data. Den är optimerad för lagring av filer som binära filer, aktivitetsloggar och filer som inte följer ett visst format.
- Azure Data Lake Storage är lagringsgrunden för att skapa kostnadseffektiva datasjöar i Azure. Den ger bloblagring med en hierarkisk mappstruktur och förbättrad prestanda, hantering och säkerhet. Den betjänar flera petabyte med information samtidigt som hundratals gigabit dataflöde bibehålls.
- Azure Synapse Analytics är en analystjänst som samlar det bästa av SQL- och Spark-tekniker och en enhetlig användarupplevelse för Azure Synapse Data Explorer och pipelines. Den integreras med Power BI, Azure Cosmos DB och Azure Machine Learning. Tjänsten stöder både dedikerade och serverlösa resursmodeller och möjligheten att växla mellan dessa modeller.
- Azure SQL Database är en alltid uppdaterad, fullständigt hanterad relationsdatabas som har skapats för molnet.
- Azure Machine Learning är en molntjänst för att hantera livscykeln för maskininlärningsprojekt. Den tillhandahåller en integrerad miljö för datautforskning, modellskapande och hantering samt distribution och stöder kodinlärning och metoder med låg kod/ingen kod för maskininlärning.
- Power BI är ett visualiseringsverktyg som ger enkel integrering med Azure-resurser.
- Med Azure App Service kan du skapa och vara värd för webbappar, mobila serverdelar och RESTful-API:er utan att hantera infrastrukturen. Språk som stöds är .NET, .NET Core, Java, Ruby, Node.js, PHP och Python.
Alternativ
Du kan använda Azure Databricksför att utveckla, distribuera och hantera maskininlärningsmodeller och analysarbetsbelastningar. Tjänsten tillhandahåller en enhetlig miljö för modellutveckling.
Information om scenario
Organisationer i finansbranschen måste förutsäga kreditrisken för individer eller företag som begär kredit. Den här modellen utvärderar lånsökandes brottslighet och standardannolikhet.
Kreditriskförutsägelse omfattar djupgående analys av populationens beteende och klassificering av kundbasen i segment baserat på skatteansvar. Andra variabler är marknadsfaktorer och ekonomiska förhållanden, som har en betydande inverkan på resultaten.
Utmaningar. Indata innehåller tiotals miljoner kundprofiler och data om kundkreditbeteende och utgiftsvanor som baseras på miljarder poster från olika system, till exempel interna kundaktivitetssystem. Uppgifter från tredje part om ekonomiska förhållanden och landets/regionens marknadsanalys kan komma från månatliga eller kvartalsvisa ögonblicksbilder som kräver inläsning och underhåll av hundratals GB-filer. Kreditbyråinformation om den sökande eller halvstrukturerade rader med kunddata och korskopplingar mellan dessa datauppsättningar och kvalitetskontroller för att verifiera dataintegriteten behövs.
Data består vanligtvis av breda kolumntabeller med kundinformation från kreditbyråer tillsammans med marknadsanalys. Kundaktiviteten består av poster med dynamisk layout som kanske inte är strukturerade. Data finns också i fritext från kundtjänstanteckningarna och formulären för interaktion mellan sökande och användare.
Bearbetning av dessa stora datavolymer och säkerställande av att resultaten är aktuella kräver effektiv bearbetning. Du behöver en lagrings- och hämtningsprocess med låg latens. Datainfrastrukturen bör kunna skalas för att stödja olika datakällor och ge möjlighet att hantera och skydda dataperimetern. Maskininlärningsplattformen måste stödja komplex analys av de många modeller som tränas, testas och valideras i många populationssegment.
Datakänslighet och sekretess. Databehandlingen för den här modellen omfattar personuppgifter och demografisk information. Du måste undvika profilering av populationer. Direkt synlighet för alla personuppgifter måste begränsas. Exempel på personuppgifter är kontonummer, kreditkortsinformation, personnummer, namn, adresser och postnummer.
Kreditkorts- och bankkontonummer måste alltid döljas. Vissa dataelement måste vara maskerade och alltid krypterade, vilket inte ger någon åtkomst till den underliggande informationen, men är tillgängliga för analys.
Data måste krypteras i vila, under överföring och under bearbetning via säkra enklaver. Åtkomst till dataobjekt loggas i en övervakningslösning. Produktionssystemet måste konfigureras med lämpliga CI/CD-pipelines med godkännanden som utlöser modelldistributioner och processer. Granskning av loggarna och arbetsflödet bör ge interaktioner med data för eventuella efterlevnadsbehov.
Bearbetas. Den här modellen kräver hög beräkningskraft för analys, kontextualisering och modellträning och distribution. Modellbedömning verifieras mot slumpmässiga exempel för att säkerställa att kreditbeslut inte inkluderar någon ras, kön, etnisk eller geografisk platsförskjutning. Beslutsmodellen måste dokumenteras och arkiveras för framtida referens. Varje faktor som ingår i beslutsresultaten lagras.
Databearbetning kräver hög CPU-användning. Den innehåller SQL-bearbetning av strukturerade data i DB- och JSON-format, Spark-bearbetning av dataramarna eller stordataanalys på terabyte med information i olika dokumentformat. Elt-/ETL-jobb för data schemaläggs eller utlöses med jämna mellanrum eller i realtid, beroende på värdet för de senaste data.
Efterlevnad och regelverk. Varje detalj i lånebearbetningen måste dokumenteras, inklusive det inskickade programmet, de funktioner som används i modellbedömning och modellens resultatuppsättning. Modellträningsinformation, data som används för träning och träningsresultat bör registreras för framtida referens- och gransknings- och efterlevnadsbegäranden.
Batch- och realtidsbedömning. Vissa uppgifter är proaktiva och kan bearbetas som batchjobb, till exempel förgodkända saldoöverföringar. Vissa begäranden, till exempel ökningar av onlinekreditlinjen, kräver godkännande i realtid.
Realtidsåtkomst till statusen för begäranden om onlinelån måste vara tillgänglig för den sökande. Det långivande finansinstitutet övervakar kontinuerligt kreditmodellens resultat och behöver insyn i mått som status för godkännande av lån, antal godkända lån, utfärdade dollarbelopp och kvaliteten på nya lån.
Ansvarig AI
Instrumentpanelen ansvarsfull AI innehåller ett enda gränssnitt för flera verktyg som kan hjälpa dig att implementera ansvarsfull AI. Den ansvarsfulla AI-standarden baseras på sex principer:
Rättvisa och inkludering i Azure Machine Learning. Den här komponenten i instrumentpanelen ansvarsfull AI hjälper dig att utvärdera orättvisa beteenden genom att undvika skador på allokering och skador på tjänstkvalitet. Du kan använda den för att bedöma rättvisa mellan känsliga grupper som definieras när det gäller kön, ålder, etnicitet och andra egenskaper. Under utvärderingen kvantifieras rättvisa via olika mått. Du bör implementera åtgärdsalgoritmerna i Fairlearn-paketet med öppen källkod, som använder paritetsbegränsningar.
Tillförlitlighet och säkerhet i Azure Machine Learning. Komponenten för felanalys i Ansvarsfull AI kan hjälpa dig:
- Få en djup förståelse för hur fel distribueras för en modell.
- Identifiera kohorter av data som har en högre felfrekvens än det övergripande riktmärket.
Transparens i Azure Machine Learning. En viktig del av transparensen är att förstå hur funktioner påverkar maskininlärningsmodellen.
- Modelltolkning hjälper dig att förstå vad som påverkar modellens beteende. Den genererar begripliga beskrivningar av modellens förutsägelser. Den här förståelsen hjälper dig att säkerställa att du kan lita på modellen och hjälper dig att felsöka och förbättra den. InterpretML kan hjälpa dig att förstå strukturen för glaslådemodeller eller relationen mellan funktioner i svarta rutor med djupa neurala nätverksmodeller.
- Kontrafaktisk konsekvens kan hjälpa dig att förstå och felsöka en maskininlärningsmodell när det gäller hur den reagerar på funktionsändringar och störningar.
Sekretess och säkerhet i Azure Machine Learning. Maskininlärningsadministratörer måste skapa en säker konfiguration för att utveckla och hantera distributionen av modeller. Säkerhets- och styrningsfunktioner kan hjälpa dig att följa organisationens säkerhetsprinciper. Andra verktyg kan hjälpa dig att utvärdera och skydda dina modeller.
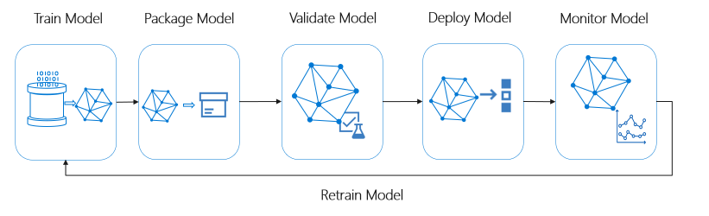
Ansvar i Azure Machine Learning. Maskininlärningsåtgärder (MLOps) baseras på DevOps-principer och metoder som ökar effektiviteten i AI-arbetsflöden. Azure Machine Learning kan hjälpa dig att implementera MLOps-funktioner:
- Registrera, paketera och distribuera modeller
- Få meddelanden och aviseringar om ändringar i modeller
- Samla in styrningsdata för livscykeln från slutpunkt till slutpunkt
- Övervaka program för driftsproblem
Det här diagrammet illustrerar MLOps-funktionerna i Azure Machine Learning:
Potentiella användningsfall
Du kan använda den här lösningen i följande scenarier:
- Ekonomi: Få ekonomisk analys av kunder eller analys över försäljning av kunder för riktade marknadsföringskampanjer.
- Sjukvård: Använd patientinformation som indata för att föreslå behandlingserbjudanden.
- Gästfrihet: Skapa en kundprofil för att föreslå erbjudanden för hotell, flyg, kryssningspaket och medlemskap.
Överväganden
Dessa överväganden implementerar grundpelarna i Azure Well-Architected Framework, som är en uppsättning vägledande grundsatser som du kan använda för att förbättra kvaliteten på en arbetsbelastning. Mer information finns i Microsoft Azure Well-Architected Framework.
Säkerhet
Säkerhet ger garantier mot avsiktliga attacker och missbruk av dina värdefulla data och system. Mer information finns i Översikt över säkerhetspelare.
Azure-lösningar ger skydd på djupet och en Nolltillit metod.
Överväg att implementera följande säkerhetsfunktioner i den här arkitekturen:
- Distribuera dedikerade Azure-tjänster till virtuella nätverk
- Säkerhetsfunktioner i Azure SQL Database
- Skydda autentiseringsuppgifterna i datafabriken med hjälp av Key Vault
- Företagssäkerhet och styrning för Azure Machine Learning
- Azure-säkerhetsbaslinje för Synapse Analytics-arbetsyta
Kostnadsoptimering
Kostnadsoptimering handlar om att minska onödiga utgifter och förbättra drifteffektiviteten. Mer information finns i Översikt över kostnadsoptimeringspelare.
Om du vill beräkna kostnaden för att implementera den här lösningen använder du priskalkylatorn för Azure.
Tänk också på följande resurser:
- Planera och hantera kostnader för Azure Synapse Analytics
- Planera och hantera kostnader för Azure Machine Learning
Driftsäkerhet
Driftskvalitet omfattar de driftsprocesser som distribuerar ett program och håller det igång i produktion. Mer information finns i Översikt över grundpelare för driftskvalitet.
Maskininlärningslösningar måste vara skalbara och standardiserade för enklare hantering och underhåll. Se till att din lösning stöder pågående slutsatsdragning med omträningscykler och automatiserade omdistributioner av modeller.
Mer information finns i Lösningsacceleratorn för Azure MLOps (v2).
Prestandaeffektivitet
Prestandaeffektivitet handlar om att effektivt skala arbetsbelastningen baserat på användarnas behov. Mer information finns i Översikt över grundpelare för prestandaeffektivitet.
- Mer information om hur du utformar skalbara lösningar finns i checklista för prestandaeffektivitet.
- Information om reglerade branscher finns i Skala AI- och maskininlärningsinitiativ i reglerade branscher.
- Hantera din Azure Synapse Analytics-miljö med SQL-, Spark- eller serverlösa SQL-pooler .
Deltagare
Den här artikeln underhålls av Microsoft. Det har ursprungligen skrivits av följande medarbetare.
Huvudförfattare:
- Charitha Basani | Senior Cloud Solution Architect
Annan deltagare:
- Mick Alberts | Teknisk författare
Om du vill se icke-offentliga LinkedIn-profiler loggar du in på LinkedIn.
Nästa steg
- Azures säkerhetsbaslinje för Azure Machine Learning
- Azure Synapse Analytics
- Distribuera maskininlärningsmodeller till Azure
- Vad är ansvarsfull AI?