Klustringspunktdata i webb-SDK
När det finns många datapunkter på kartan kan vissa överlappa varandra. Överlappningen kan göra att kartan blir oläslig och svår att använda. Klustringspunktdata är en process där du kombinerar punktdata som är nära varandra och representerar dem på kartan som en enda klustrad datapunkt. När användaren zoomar in på kartan delas klustren upp i sina enskilda datapunkter. När du arbetar med ett stort antal datapunkter kan klustringsprocesserna förbättra användarupplevelsen.
Aktivera klustring på en datakälla
Aktivera klustring i DataSource klassen genom att ange cluster alternativet till true. Ange clusterRadius för att välja närliggande punkter och kombinera dem till ett kluster. Värdet för clusterRadius är i bildpunkter. Använd clusterMaxZoom för att ange en zoomnivå där klustringslogik ska inaktiveras. Här är ett exempel på hur du aktiverar klustring i en datakälla.
//Create a data source and enable clustering.
var datasource = new atlas.source.DataSource(null, {
//Tell the data source to cluster point data.
cluster: true,
//The radius in pixels to cluster points together.
clusterRadius: 45,
//The maximum zoom level in which clustering occurs.
//If you zoom in more than this, all points are rendered as symbols.
clusterMaxZoom: 15
});
Tips
Om två datapunkter är nära varandra på marken är det möjligt att klustret aldrig bryts isär, oavsett hur nära användaren zoomar in. För att åtgärda detta kan du ange clusterMaxZoom alternativet för att inaktivera klustringslogik och helt enkelt visa allt.
Klassen DataSource innehåller även följande metoder relaterade till klustring.
| Metod | Returtyp | Description |
|---|---|---|
| getClusterChildren(clusterId: number) | Promise<Array<Feature<Geometry, any> | Form>> | Hämtar underordnade till det angivna klustret på nästa zoomnivå. Dessa underordnade objekt kan vara en kombination av former och underkluster. Underkluster är funktioner med egenskaper som matchar ClusteredProperties. |
| getClusterExpansionZoom(clusterId: number) | Löftesnummer<> | Beräknar en zoomnivå där klustret börjar expandera eller brytas isär. |
| getClusterLeaves(clusterId: number, limit: number, offset: number) | Promise<Array<Feature<Geometry, any> | Form>> | Hämtar punkterna i ett kluster. Som standard returneras de första 10 punkterna. Om du vill bläddra igenom punkterna använder limit du för att ange antalet punkter som ska returneras och offset för att gå igenom indexet med punkter. Om du vill returnera alla punkter anger du limit till Infinity och anger offsetinte . |
Visa kluster med ett bubbellager
Ett bubbellager är ett bra sätt att återge klustrade punkter. Använd uttryck för att skala radien och ändra färgen baserat på antalet punkter i klustret. Om du visar kluster med ett bubbellager bör du använda ett separat lager för att rendera olustererade datapunkter.
Om du vill visa klustrets storlek ovanpå bubblan använder du ett symbolskikt med text och använder inte en ikon.
Ett fullständigt arbetsexempel på hur du implementerar visning av kluster med ett bubbellager finns i Punktkluster i bubbellager i Azure Maps exempel. Källkoden för det här exemplet finns i Point Clusters in Bubble Layer source code (Punktkluster i bubbelskiktets källkod).

Visa kluster med hjälp av ett symbolskikt
När du visualiserar datapunkter döljer symbolskiktet automatiskt symboler som överlappar varandra för att säkerställa ett renare användargränssnitt. Det här standardbeteendet kan vara oönskat om du vill visa datapunkternas densitet på kartan. Dessa inställningar kan dock ändras. Om du vill visa alla symboler anger du allowOverlap alternativet för egenskapen Symbolskikt iconOptions till true.
Använd klustring för att visa datapunkternas densitet samtidigt som du behåller ett rent användargränssnitt. Följande exempel visar hur du lägger till anpassade symboler och representerar kluster och enskilda datapunkter med hjälp av symbolskiktet.
Ett fullständigt arbetsexempel på hur du implementerar visning av kluster med hjälp av ett symbolskikt finns i Visa kluster med ett symbollager i Azure Maps exempel. Källkoden för det här exemplet finns i Visa kluster med källkoden symbolskikt.
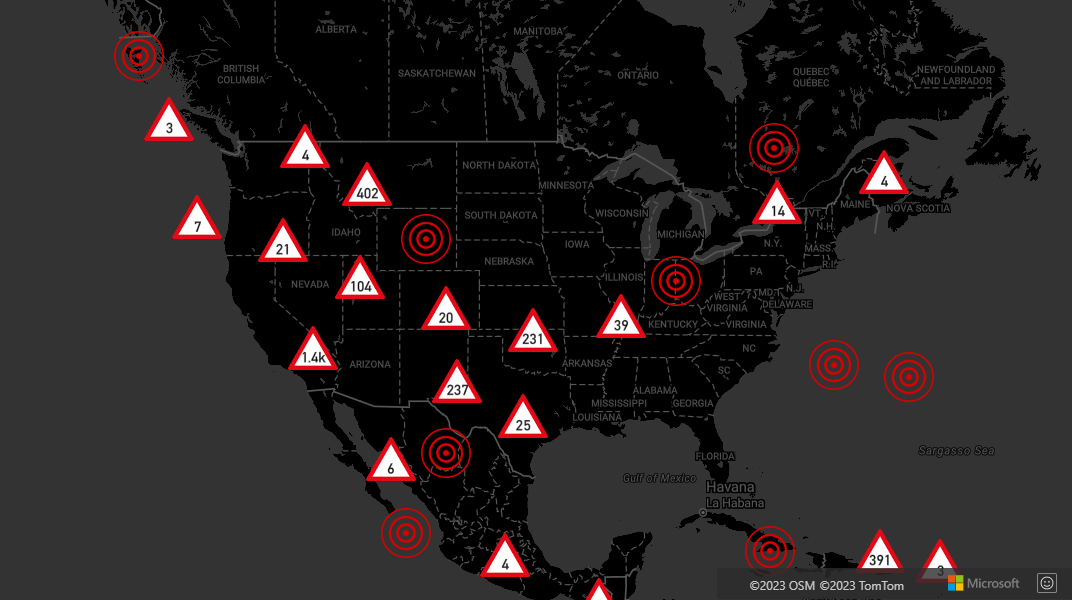
Klustring och skiktet för termiska kartor
Termiska kartor är ett bra sätt att visa densiteten för data på kartan. Den här visualiseringsmetoden kan hantera ett stort antal datapunkter på egen hand. Om datapunkterna är klustrade och klusterstorleken används som vikten på värmekartan kan värmekartan hantera ännu mer data. För att uppnå det här alternativet anger du weight alternativet för termisk kartskiktet till ['get', 'point_count']. När klusterradien är liten ser värmekartan nästan identisk ut som en termisk karta med hjälp av de olustererade datapunkterna, men den fungerar bättre. Ju mindre klusterradie, desto mer exakt är värmekartan, men med färre prestandafördelar.
Ett fullständigt arbetsexempel som visar hur du skapar en termisk karta som använder klustring i datakällan finns i Klusterviktad termisk karta i Azure Maps-exemplen. Källkoden för det här exemplet finns i Klusterviktad termisk karta källkod.
Mushändelser på klustrade datapunkter
När mushändelser inträffar på ett lager som innehåller klustrade datapunkter återgår den klustrade datapunkten till händelsen som ett GeoJSON-punktfunktionsobjekt. Den här punktfunktionen har följande egenskaper:
| Egenskapsnamn | Typ | Description |
|---|---|---|
cluster |
boolean | Anger om funktionen representerar ett kluster. |
cluster_id |
sträng | Ett unikt ID för klustret som kan användas med metoderna DataSource getClusterExpansionZoom, getClusterChildrenoch getClusterLeaves . |
point_count |
antal | Antalet punkter som klustret innehåller. |
point_count_abbreviated |
sträng | En sträng som förkortar värdet point_count om det är långt. (till exempel blir 4 000 4 000) |
Punktkluster i bubbelskiktsexemplet tar ett bubbellager som renderar klusterpunkter och lägger till en klickhändelse. När klickhändelsen utlöses beräknar och zoomar koden kartan till nästa zoomnivå, där klustret bryts isär. Den här funktionen implementeras med hjälp getClusterExpansionZoom av metoden för DataSource klassen och cluster_id egenskapen för den klickade klustrade datapunkten.
Följande kodfragment visar koden i exemplet punktkluster i bubbellager som lägger till funktionen klicka händelse till klustrade datapunkter:
//Add a click event to the layer so we can zoom in when a user clicks a cluster.
map.events.add('click', clusterBubbleLayer, clusterClicked);
//Add mouse events to change the mouse cursor when hovering over a cluster.
map.events.add('mouseenter', clusterBubbleLayer, function () {
map.getCanvasContainer().style.cursor = 'pointer';
});
map.events.add('mouseleave', clusterBubbleLayer, function () {
map.getCanvasContainer().style.cursor = 'grab';
});
function clusterClicked(e) {
if (e && e.shapes && e.shapes.length > 0 && e.shapes[0].properties.cluster) {
//Get the clustered point from the event.
var cluster = e.shapes[0];
//Get the cluster expansion zoom level. This is the zoom level at which the cluster starts to break apart.
datasource.getClusterExpansionZoom(cluster.properties.cluster_id).then(function (zoom) {
//Update the map camera to be centered over the cluster.
map.setCamera({
center: cluster.geometry.coordinates,
zoom: zoom,
type: 'ease',
duration: 200
});
});
}
}
Visa klusterområde
Punktdata som ett kluster representerar är spridda över ett område. I det här exemplet när musen hovras över ett kluster uppstår två huvudsakliga beteenden. För det första används de enskilda datapunkterna i klustret för att beräkna ett konvext skrov. Sedan visas det konvexa skrovet på kartan för att visa ett område. Ett konvext skrov är en polygon som omsluter en uppsättning punkter som ett elastiskt band och kan beräknas med hjälp av atlas.math.getConvexHull metoden . Alla punkter i ett kluster kan hämtas från datakällan med hjälp av getClusterLeaves metoden .
Ett fullständigt arbetsexempel som visar hur du gör detta finns i Visa klusterområde med Convex Hull i Azure Maps-exemplen. Källkoden för det här exemplet finns i Visa klusterområde med Convex Hull-källkod.
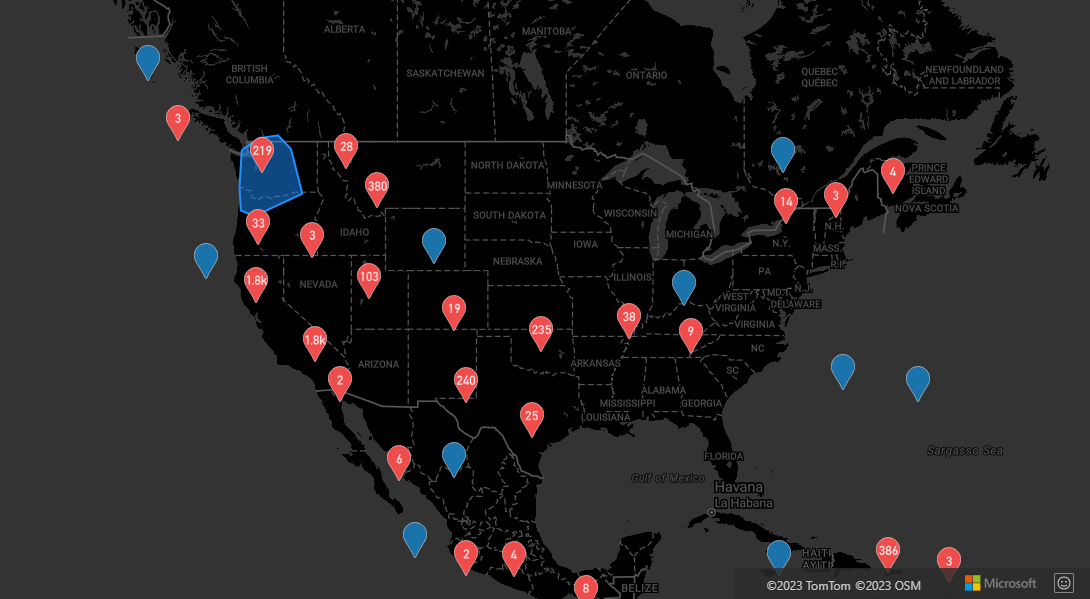
Aggregera data i kluster
Kluster representeras ofta med hjälp av en symbol med antalet punkter som finns i klustret. Men ibland är det önskvärt att anpassa klusterformatet med fler mått. Med klusteraggregeringar kan anpassade egenskaper skapas och fyllas i med hjälp av en beräkning av mängduttryck . Klusteraggregeringar kan definieras i clusterProperties alternativet för DataSource.
Exemplet klusteraggregeringar använder ett aggregeringsuttryck. Koden beräknar ett antal baserat på entitetstypens egenskap för varje datapunkt i ett kluster. När en användare väljer ett kluster visas ett popup-fönster med ytterligare information om klustret. Källkoden för det här exemplet finns i Klusteraggregeringar källkod.

Nästa steg
Läs mer om de klasser och metoder som används i den här artikeln:
Se kodexempel för att lägga till funktioner i din app: