Vad är Azure Chaos Studio?
Azure Chaos Studio är en hanterad tjänst som använder kaosteknik för att hjälpa dig att mäta, förstå och förbättra molnprograms- och tjänstresiliens. Chaos Engineering är en metod där du matar in verkliga fel i ditt program för att köra kontrollerade felinmatningsexperiment.
Motståndskraft är ett systems förmåga att hantera och återställa från störningar. Programstörningar kan orsaka fel och fel som kan påverka din verksamhet eller ditt uppdrag negativt. Oavsett om du utvecklar, migrerar eller använder Azure-program är det viktigt att verifiera och förbättra programmets motståndskraft.
Chaos Studio hjälper dig att undvika negativa konsekvenser genom att verifiera att programmet effektivt svarar på störningar och fel. Du kan använda Chaos Studio för att testa motståndskraft mot verkliga incidenter, till exempel avbrott eller hög CPU-användning på virtuella datorer .
Följande video ger mer bakgrund om Chaos Studio:
Chaos Studio-scenarier
Du kan använda kaosteknik för olika återhämtningsvalideringsscenarier som sträcker sig över livscykeln för tjänsteutveckling och drift. Det finns två typer av scenarier:
- Skifträtt: Dessa scenarier använder en produktions- eller förproduktionsmiljö. Vanligtvis utför du skift-rätt-scenarier med verklig kundtrafik eller simulerad belastning.
- Skift vänster: Dessa scenarier kan använda en utvecklingsmiljö eller en delad testmiljö. Du kan utföra skift-vänster-scenarier utan någon verklig kundtrafik.
Du kan använda Chaos Studio för följande vanliga scenarier för kaosteknik:
- Återskapa en incident som påverkade ditt program för att bättre förstå felet. Se till att reparationer efter incidenten förhindrar att incidenten upprepas.
- Förbered dig för ett större evenemang eller en större säsong med belastning, skalning, prestanda och återhämtningsverifiering på speldagen.
- Utför granskningar av affärskontinuitet och haveriberedskap för att säkerställa att programmet kan återställas snabbt och bevara kritiska data i en katastrof.
- Kör övningar med hög tillgänglighet för att testa programmets motståndskraft mot regionstopp, nätverkskonfigurationsfel, stresshändelser eller problem med bullriga grannar.
- Utveckla prestandamått för program.
- Planera kapacitetsbehov för produktionsmiljöer.
- Kör stresstester eller belastningstester.
- Se till att tjänster som migreras från en lokal eller annan molnmiljö förblir motståndskraftiga mot kända fel.
- Skapa förtroende för tjänster som bygger på molnbaserade arkitekturer.
- Kontrollera att realtidswebbplatsverktyg, observerbarhetsdata och jourprocesser fortfarande fungerar under oväntade förhållanden.
För många av dessa scenarier skapar du först motståndskraft med hjälp av ad hoc-kaosexperiment. Sedan verifierar du kontinuerligt att nya distributioner inte regressiliens. Du kan kontrollera att du kör kaosexperiment som distributionsportar i pipelines för kontinuerlig integrering/kontinuerlig distribution.
Så här fungerar Chaos Studio
Med Chaos Studio kan du orkestrera säker, kontrollerad felinmatning på dina Azure-resurser. Kaosexperiment är kärnan i Chaos Studio. Ett kaosexperiment beskriver de fel som ska köras och vilka resurser som ska köras mot. Du kan ordna fel som ska köras parallellt eller i sekvens, beroende på dina behov.
Chaos Studio stöder två typer av fel:
- Tjänstdirigering: Dessa fel körs direkt mot en Azure-resurs, utan någon installation eller instrumentation. Exempel är att starta om ett Azure Cache for Redis-kluster eller lägga till nätverksfördröjning i Azure Kubernetes Service-poddar.
- Agentbaserad: Dessa fel körs på virtuella datorer eller vm-skalningsuppsättningar för att göra gästfel. Exempel är att använda virtuellt minnestryck eller att döda en process.
Varje fel har specifika parametrar som du kan konfigurera, till exempel vilken process som ska avslutas eller hur mycket minnesbelastning som ska genereras.
När du skapar ett kaosexperiment definierar du ett eller flera steg som körs sekventiellt. Varje steg innehåller en eller flera grenar som körs parallellt i steget. Varje gren innehåller en eller flera åtgärder, till exempel att mata in ett fel eller vänta en viss tid.
Du ordnar resursmål för att köra fel mot i grupper som kallas väljare så att du enkelt kan referera till en grupp resurser i varje åtgärd.
Följande diagram visar layouten för ett kaosexperiment i Chaos Studio:
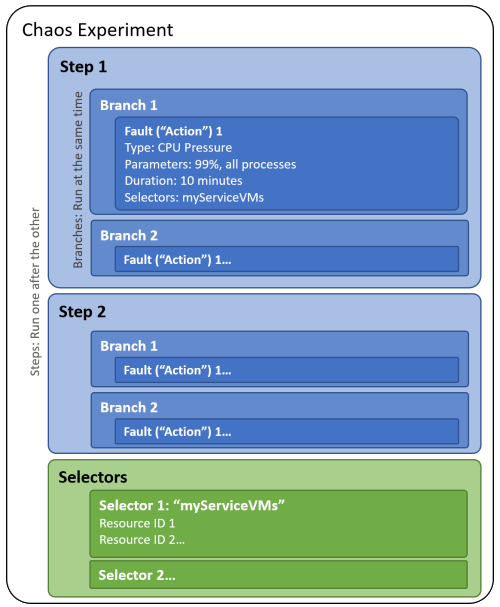
Ett kaosexperiment är en Azure-resurs i en prenumeration och resursgrupp. Du kan använda Azure-portalen eller Chaos Studio REST API för att skapa, uppdatera, starta, avbryta och visa status för experiment.
Nästa steg
Nu när du förstår hur du använder kaosteknik är du redo att: