Processen för maskininlärningsåtgärder
Modellutvecklingsprocessen
Utvecklingsprocessen bör ge följande resultat:
Träningen automatiseras och modeller verifieras, vilket innefattar testningsfunktioner och prestanda (till exempel med hjälp av noggrannhetsmått).
Distribution till infrastrukturen som används för slutsatsdragning (inklusive övervakning) automatiseras.
Mekanismer skapar en datagranskningslogg från slutpunkt till slutpunkt. Automatisk modellomträning sker när data växlar över tid, vilket är relevant för storskaliga maskininlärningsinfuserade system.
Följande diagram visar distributionslivscykeln för ett maskininlärningssystem:
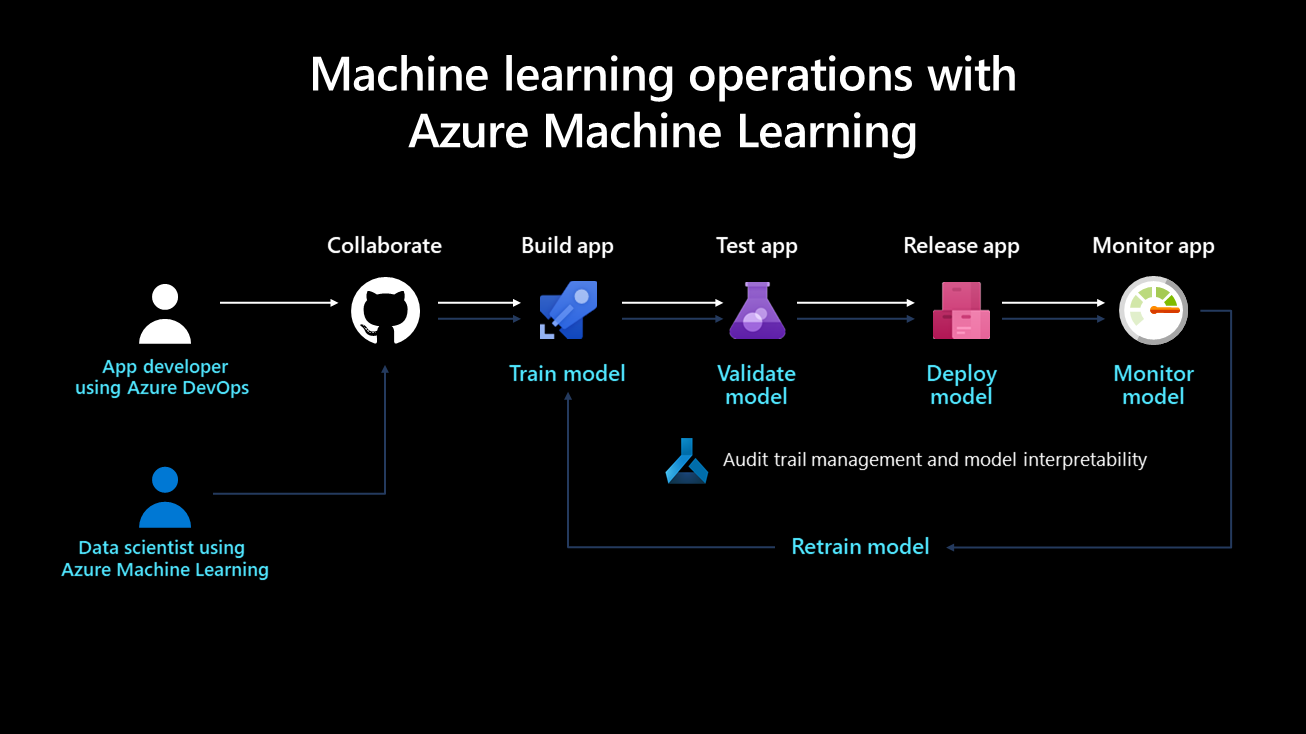
När den har utvecklats tränas, valideras, distribueras och övervakas en maskininlärningsmodell. Ur ett organisationsperspektiv och på chefs- och teknisk nivå är det viktigt att definiera vem som äger och implementerar den här processen. I större företag kan en dataexpert äga modelltränings- och valideringsstegen, och en maskininlärningstekniker kan tendera att utföra de återstående stegen. I mindre företag kan en dataexpert äga alla steg.
Träna modellen
I det här steget tränar en träningsdatauppsättning maskininlärningsmodellen. Träningskoden är versionskontrollerad och återanvändbar, och den här funktionen optimerar knappklick och händelseutlösare (till exempel en ny version av data som blir tillgänglig) för att automatisera hur modellen tränas.
Verifiera modellen
I det här steget används etablerade mått, till exempel ett noggrannhetsmått, för att automatiskt validera den nyligen tränade modellen och jämföra den med äldre. Ökade noggrannheten? Om ja, kan den här modellen registreras i modellregistret för att säkerställa att nästa steg kan använda den. Om den nya modellen presterar sämre kan en dataexpert aviseras för att undersöka varför eller ta bort den nytränade modellen.
Distribuera modellen
Distribuera modellen som en API-tjänst för webbprogram i distributionssteget. Med den här metoden kan modellen skalas och uppdateras oberoende av programmen. Alternativt kan modellen användas för att utföra batchbedömning där den används en gång eller regelbundet för att beräkna förutsägelser på nya datapunkter. Detta är användbart när stora mängder data behöver bearbetas asynkront. Mer information om distributionsmodeller finns på maskininlärningsslutsats under distributionssidan .
Övervaka modellen
Det är nödvändigt att övervaka modellen av två viktiga skäl. För det första hjälper övervakning av modellen till att säkerställa att den är tekniskt funktionell; kan till exempel generera förutsägelser. Detta är viktigt om en organisations program är beroende av modellen och använder den i realtid. Övervakning av modellen hjälper också organisationer att mäta om den kontinuerligt genererar användbara förutsägelser. Detta kanske inte är användbart när dataavvikelser inträffar, till exempel när de data som används för att träna modellen skiljer sig avsevärt från de data som skickas till modellen under förutsägelsefasen. En modell som tränats för att rekommendera produkter till ungdomar kan till exempel ge oönskade resultat när man rekommenderar produkter till personer från en annan åldersgrupp. Modellövervakning med dataavvikelser kan identifiera den här typen av matchningsfel, varna maskininlärningstekniker och automatiskt träna om modellen med mer relevanta eller nyare data.
Övervaka modeller
Eftersom dataavvikelser, säsongsvariationer eller nyare arkitektur som är anpassade för bättre prestanda kan leda till att modellprestandan avtar med tiden är det viktigt att upprätta en process för kontinuerlig distribution av modeller. Några metodtips är:
Ägande: En ägare bör tilldelas till modellens prestandaövervakningsprocess för att aktivt hantera dess prestanda.
Versionspipelines: Konfigurera en versionspipeline i Azure DevOps först och ställ in utlösaren på modellregistret. När en ny modell registreras i registret utlöses och signeras versionspipelinen på en distributionsprocess.
Förutsättningar för omträning av modeller
Att samla in data från modeller i produktion är en förutsättning för omträning av modeller i ett ramverk för kontinuerlig integrering/kontinuerlig utveckling, och den här processen använder indata från bedömningsbegäranden. Den här funktionen är för närvarande begränsad till tabelldata som kan parsas som JSON med minimal formatering och manipulering. video, ljud och bilder undantas. Den här funktionen är tillgänglig för modeller på Azure Kubernetes Service (AKS). Insamlade data lagras i en Azure-blob.
Så här förbereder du för omträning av en modell:
Övervaka dataavvikelser från indata som samlas in. För att konfigurera en övervakningsprocess krävs att tidsstämpeln extraheras från produktionsdata. Detta krävs för att jämföra produktionsdata och baslinjedata (träningsdata som används för att skapa modellen). Det bästa sättet att övervaka dataavvikelser är via Azure Monitor Application Insights. Den här funktionen ger en avisering som kan utlösa åtgärder som e-post, SMS-text, push-överföring eller Azure Functions. Du måste aktivera Application Insights för att logga data.
Analysera insamlade data. Se till att samla in data från modeller i produktion och inkludera resultaten i modellbedömningsskriptet. Samla in alla funktioner som används för modellbedömning, eftersom detta säkerställer att alla nödvändiga funktioner finns och kan användas som träningsdata.
Bestäm om omträning med insamlade data är nödvändigt. Många saker orsakar dataavvikelser, inklusive sensorproblem med säsongsvariationer, ändringar i användarbeteende och problem med datakvalitet som rör datakällan. Omträning av modeller krävs inte i alla fall, så vi rekommenderar att du undersöker och förstår orsaken till dataavvikelsen innan du fortsätter med detta.
Träna om modellen. Modellträningen bör redan vara automatiserad, och det här steget innebär att utlösa det aktuella träningssteget. Detta kan gälla när dataavvikelser har identifierats (och det inte är relaterat till ett dataproblem) eller när en datatekniker har publicerat en ny version av en datauppsättning. Beroende på användningsfallet kan de här stegen automatiseras helt eller övervakas av en människa. Till exempel, medan vissa användningsfall som produktrekommendationer kan köras självständigt i framtiden, skulle andra inom finans ta med standarder som modellrättvisa och transparens och kräva att en människa godkänner nyutbildade modeller.
Först är det vanligt att en organisation bara automatiserar en modells träning och distribution, men inte verifierings-, övervaknings- och omträningsstegen, som utförs manuellt. Så småningom kan automatiseringsstegen för de här uppgifterna fortsätta tills det önskade tillståndet har uppnåtts. DevOps och maskininlärning är begrepp som utvecklas över tid, och organisationer bör vara medvetna om sin utveckling.
Teamets Datavetenskap processlivscykel
Team Datavetenskap Process (TDSP) tillhandahåller en livscykel för att strukturera utvecklingen av dina datavetenskapsprojekt. Livscykeln beskriver de större faser som projekt vanligtvis kör, ofta iterativt:
- Förståelse för verksamheten
- Förvärv och förståelse av data
- Modellering
- Distribution
Målen, uppgifterna och dokumentationsartefakterna för varje steg i TDSP-livscykeln beskrivs i livscykeln för Team Datavetenskap Process.
Roller och aktiviteter inom maskininlärningsåtgärder
Enligt TDSP-livscykeln är nyckelrollerna i AI-projektet datatekniker, dataforskare och maskininlärningsdriftstekniker. De här rollerna är viktiga för projektets framgång och måste arbeta tillsammans mot korrekta, repeterbara, skalbara och produktionsklara lösningar.

Datatekniker: Den här rollen matar in, validerar och rensar data. När data har förfinats katalogiseras de och görs tillgängliga för dataexperter att använda. I det här skedet är det viktigt att utforska och analysera duplicerade data, ta bort extremvärden och identifiera data som saknas. Dessa aktiviteter bör definieras i pipelinestegen och köras eftersom träningspipelinen är förbearbetad. Unika och specifika namn ska tilldelas till kärnfunktioner och genererade funktioner.
Dataexpert (eller AI-tekniker): Den här rollen navigerar i pipelineprocessen för träning och utvärderar modeller. En dataexpert tar emot data från datateknikern och identifierar mönster och relationer i den, och kan eventuellt välja eller generera funktioner för experimentet. Eftersom funktionsframställning spelar en viktig roll när det gäller att skapa en sund generaliserad modell är det viktigt att den här fasen slutförs så noggrant som möjligt. Olika experiment kan utföras med olika algoritmer och hyperparametrar. Azure-verktyg som automatiserad maskininlärning kan automatisera den här uppgiften, vilket också kan hjälpa till med underanpassning eller överanpassning av en modell. En modell som tränats registreras sedan i modellregistret. Modellen bör ha ett unikt och specifikt namn, och en versionshistorik bör behållas för spårbarhet.
Maskininlärningstekniker: Den här rollen skapar pipelines från slutpunkt till slutpunkt för kontinuerlig integrering och leverans. Detta inkluderar att packa modellen i en Docker-avbildning, validera och profilera modellen, vänta på godkännande från en intressent och distribuera modellen i en containerorkestreringstjänst som AKS. Olika utlösare kan ställas in under kontinuerlig integrering, och modellens kod kan utlösa träningspipelinen och versionspipelinen efteråt.
Feedback
Kommer snart: Under hela 2024 kommer vi att fasa ut GitHub-problem som feedbackmekanism för innehåll och ersätta det med ett nytt feedbacksystem. Mer information finns i: https://aka.ms/ContentUserFeedback.
Skicka och visa feedback för