Snabbstart: Identifiera avsikter med Language Understanding
Referensdokumentation | Paket (NuGet) | Ytterligare exempel på GitHub
I den här snabbstarten använder du tal- och språktjänster för att identifiera avsikter från ljuddata som hämtats från en mikrofon. Mer specifikt använder du speech-tjänsten för att känna igen tal och en CLU-modell (Conversational Language Understanding) för att identifiera avsikter.
Viktigt
Conversational Language Understanding (CLU) är tillgängligt för C# och C++ med Speech SDK version 1.25 eller senare.
Förutsättningar
- Azure-prenumeration – Skapa en kostnadsfritt
- Skapa en språkresurs i Azure Portal.
- Hämta språkresursnyckeln och slutpunkten. När språkresursen har distribuerats väljer du Gå till resurs för att visa och hantera nycklar. Mer information om Resurser för Azure AI-tjänster finns i Hämta nycklarna för din resurs.
- Skapa en Speech-resurs i Azure Portal.
- Hämta speech-resursnyckeln och -regionen. När speech-resursen har distribuerats väljer du Gå till resurs för att visa och hantera nycklar. Mer information om Resurser för Azure AI-tjänster finns i Hämta nycklarna för din resurs.
Konfigurera miljön
Speech SDK är tillgängligt som ett NuGet-paket och implementerar .NET Standard 2.0. Du installerar Speech SDK senare i den här guiden, men först kontrollerar du om det finns fler krav i SDK-installationsguiden .
Ange miljövariabler
Det här exemplet kräver miljövariabler med namnet LANGUAGE_KEY, LANGUAGE_ENDPOINT, SPEECH_KEYoch SPEECH_REGION.
Ditt program måste autentiseras för att få åtkomst till Azure AI-tjänstresurser. För produktion använder du ett säkert sätt att lagra och komma åt dina autentiseringsuppgifter. När du till exempel har hämtat en nyckel för skriver du den till en ny miljövariabel på den lokala dator som kör programmet.
Tips
Ta inte med nyckeln direkt i koden och publicera den aldrig offentligt. Mer information om autentiseringsalternativ som Azure Key Vault finns i säkerhetsartikeln om Azure AI-tjänster.
Om du vill ange miljövariablerna öppnar du ett konsolfönster och följer anvisningarna för operativsystemet och utvecklingsmiljön.
- Om du vill ange
LANGUAGE_KEYmiljövariabeln ersätteryour-language-keydu med en av nycklarna för resursen. - Om du vill ange
LANGUAGE_ENDPOINTmiljövariabeln ersätteryour-language-endpointdu med en av regionerna för din resurs. - Om du vill ange
SPEECH_KEYmiljövariabeln ersätteryour-speech-keydu med en av nycklarna för resursen. - Om du vill ange
SPEECH_REGIONmiljövariabeln ersätteryour-speech-regiondu med en av regionerna för din resurs.
setx LANGUAGE_KEY your-language-key
setx LANGUAGE_ENDPOINT your-language-endpoint
setx SPEECH_KEY your-speech-key
setx SPEECH_REGION your-speech-region
Anteckning
Om du bara behöver komma åt miljövariabeln i den aktuella konsolen som körs kan du ange miljövariabeln med set i stället för setx.
När du har lagt till miljövariablerna kan du behöva starta om alla program som körs och som behöver läsa miljövariabeln, inklusive konsolfönstret. Om du till exempel använder Visual Studio som redigeringsprogram startar du om Visual Studio innan du kör exemplet.
Skapa ett konversations-Language Understanding projekt
När du har skapat en språkresurs skapar du ett projekt för förståelse av konversationsspråk i Language Studio. Ett projekt är ett arbetsområde för att skapa dina anpassade ML-modeller baserat på dina data. Ditt projekt kan bara nås av dig och andra som har åtkomst till den språkresurs som används.
Gå till Language Studio och logga in med ditt Azure-konto.
Skapa ett projekt för förståelse av konversationsspråk
I den här snabbstarten kan du ladda ned det här exempelprojektet för hemautomatisering och importera det. Det här projektet kan förutsäga avsedda kommandon från användarindata, till exempel att tända och inaktivera lampor.
Under avsnittet Förstå frågor och konversationsspråk i Language Studio väljer du Förståelse för konversationsspråk.
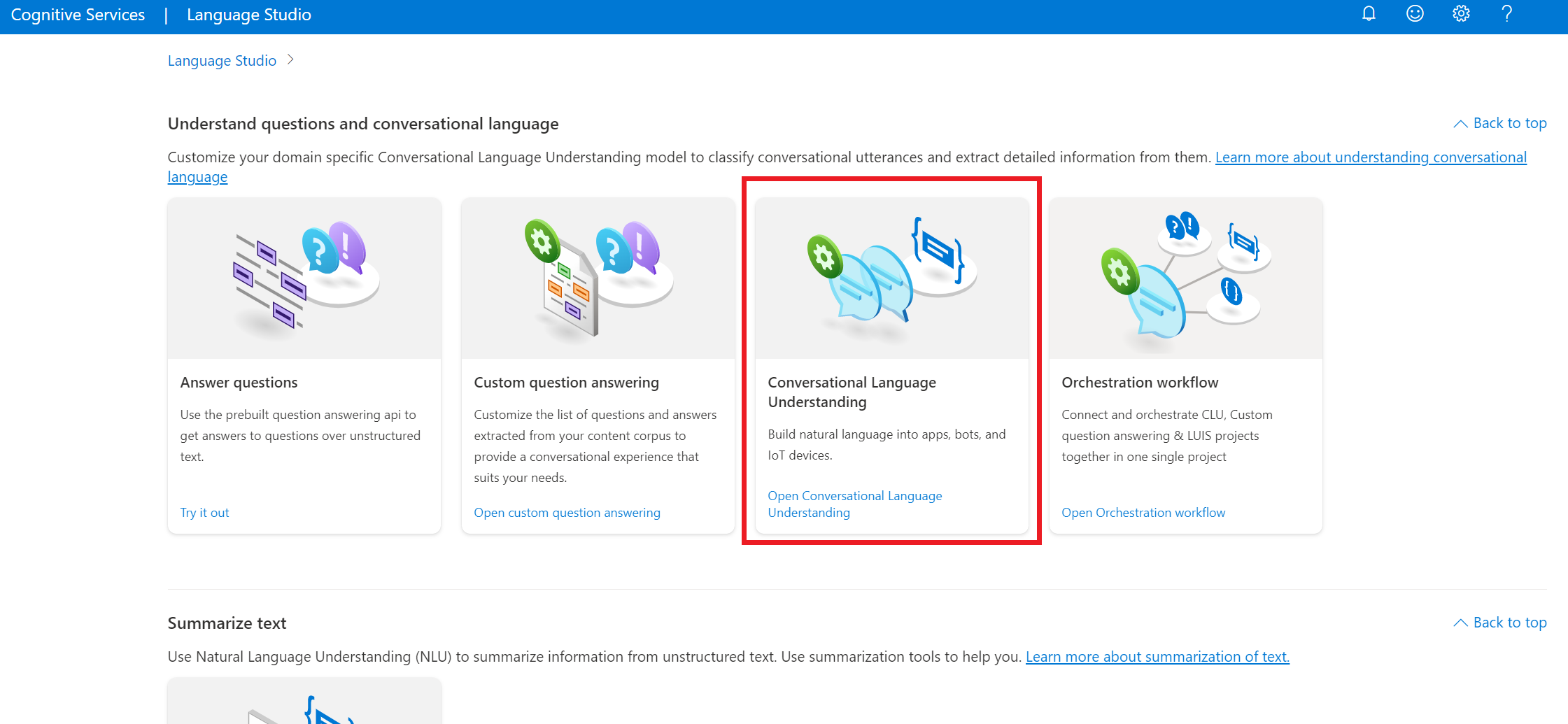
Då kommer du till projektsidan För förståelse av konversationsspråk . Bredvid knappen Skapa nytt projekt väljer du Importera.
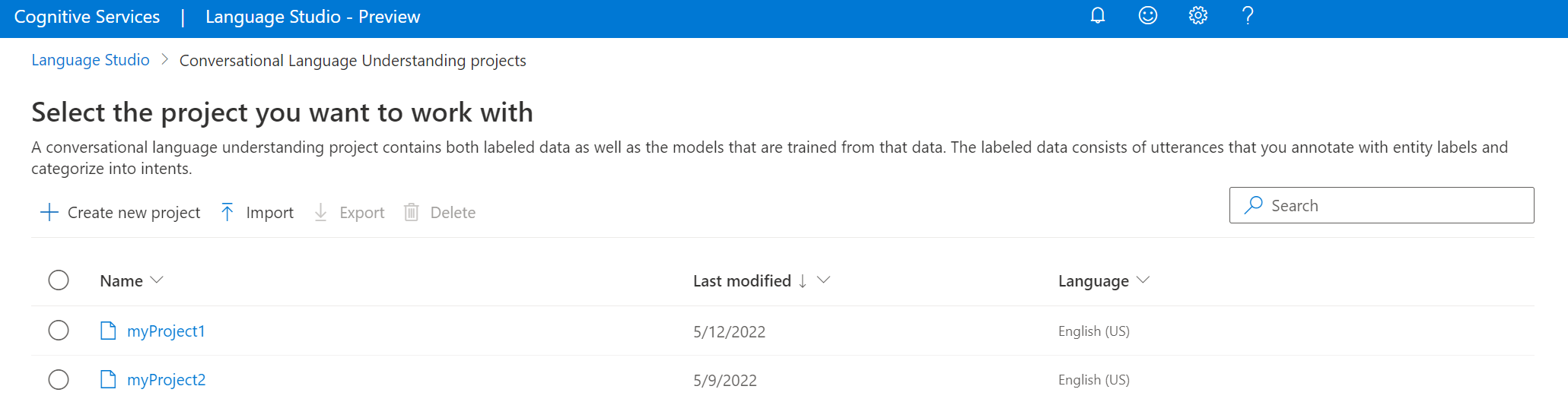
Ladda upp den JSON-fil som du vill importera i fönstret som visas. Kontrollera att filen följer JSON-formatet som stöds.


När uppladdningen är klar hamnar du på sidan Schemadefinition . För den här snabbstarten har schemat redan skapats och yttranden är redan märkta med avsikter och entiteter.
Träna modellen
När du har skapat ett projekt bör du vanligtvis skapa ett schema och etikettyttranden. I den här snabbstarten har vi redan importerat ett färdigt projekt med skapat schema och märkta yttranden.
Om du vill träna en modell måste du starta ett träningsjobb. Utdata från ett lyckat träningsjobb är din tränade modell.
Så här börjar du träna din modell från Language Studio:
Välj Träna modell på menyn till vänster.
Välj Starta ett träningsjobb på den översta menyn.
Välj Träna en ny modell och ange ett nytt modellnamn i textrutan. Om du vill ersätta en befintlig modell med en modell som tränats på nya data väljer du Skriv över en befintlig modell och väljer sedan en befintlig modell. Det går inte att ångra att skriva över en tränad modell, men det påverkar inte dina distribuerade modeller förrän du distribuerar den nya modellen.
Välj träningsläge. Du kan välja Standardträning för snabbare träning, men det är bara tillgängligt för engelska. Eller så kan du välja Avancerad utbildning som stöds för andra språk och flerspråkiga projekt, men det innebär längre utbildningstider. Läs mer om träningslägen.
Välj en datadelningsmetod . Du kan välja Att automatiskt dela upp testuppsättningen från träningsdata där systemet delar dina yttranden mellan tränings- och testuppsättningarna, enligt de angivna procentsatserna. Eller så kan du använda en manuell delning av tränings- och testdata. Det här alternativet är bara aktiverat om du har lagt till yttranden i testuppsättningen när du har etiketterat dina yttranden.
Välj knappen Träna .
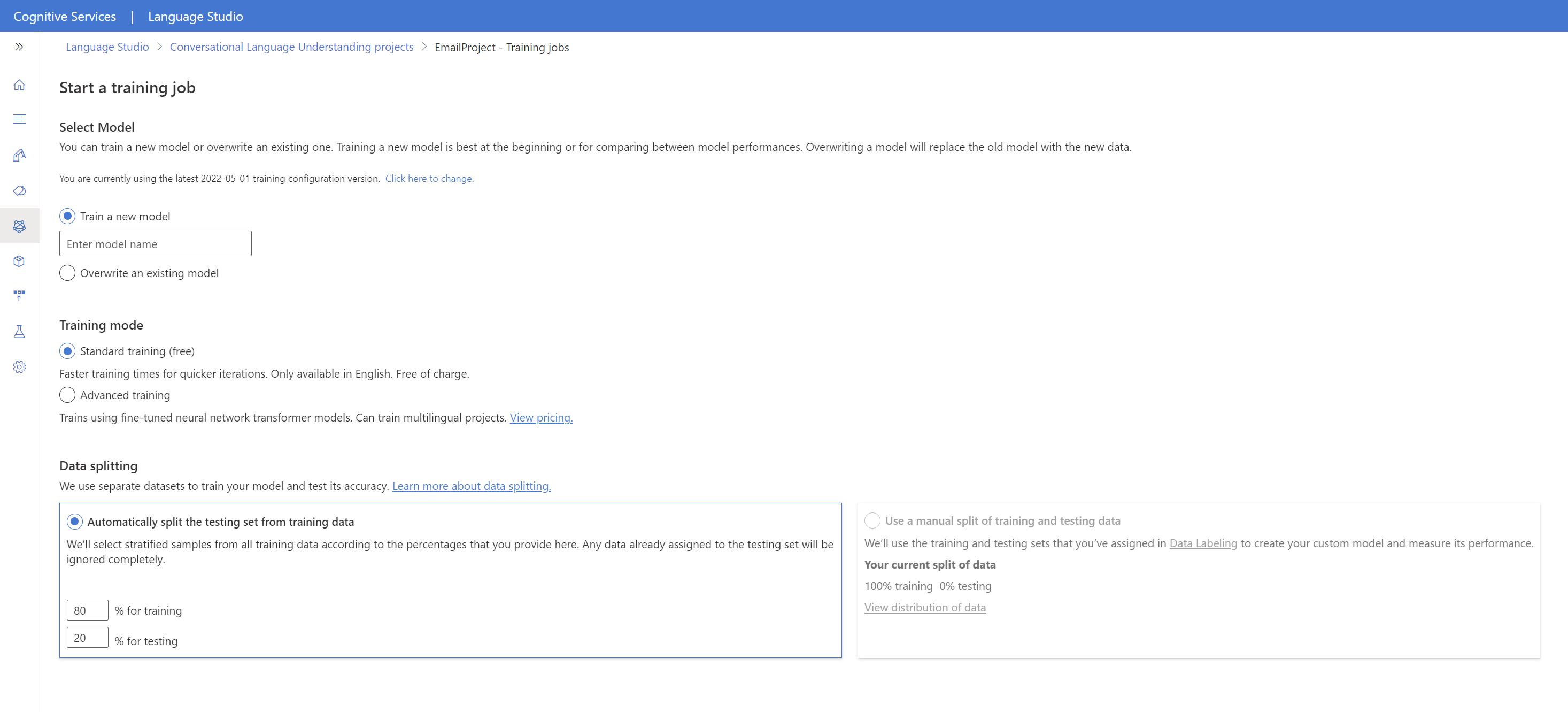
Välj träningsjobbets ID i listan. En panel visas där du kan kontrollera träningsförloppet, jobbstatusen och annan information för det här jobbet.
Anteckning
- Endast träningsjobb som har slutförts genererar modeller.
- Träningen kan ta lite tid mellan ett par minuter och ett par timmar baserat på antalet yttranden.
- Du kan bara köra ett träningsjobb i taget. Du kan inte starta andra träningsjobb i samma projekt förrän jobbet som körs har slutförts.
- Den maskininlärning som används för att träna modeller uppdateras regelbundet. Om du vill träna på en tidigare konfigurationsversion väljer du Välj här för att ändra från sidan Starta ett träningsjobb och välja en tidigare version.

Distribuera din modell
När du har tränat en modell granskar du vanligtvis utvärderingsinformationen. I den här snabbstarten distribuerar du bara din modell och gör den tillgänglig för dig att prova i Language Studio, eller så kan du anropa förutsägelse-API:et.
Så här distribuerar du din modell från Language Studio:
Välj Distribuera en modell på menyn till vänster.
Välj Lägg till distribution för att starta guiden Lägg till distribution .
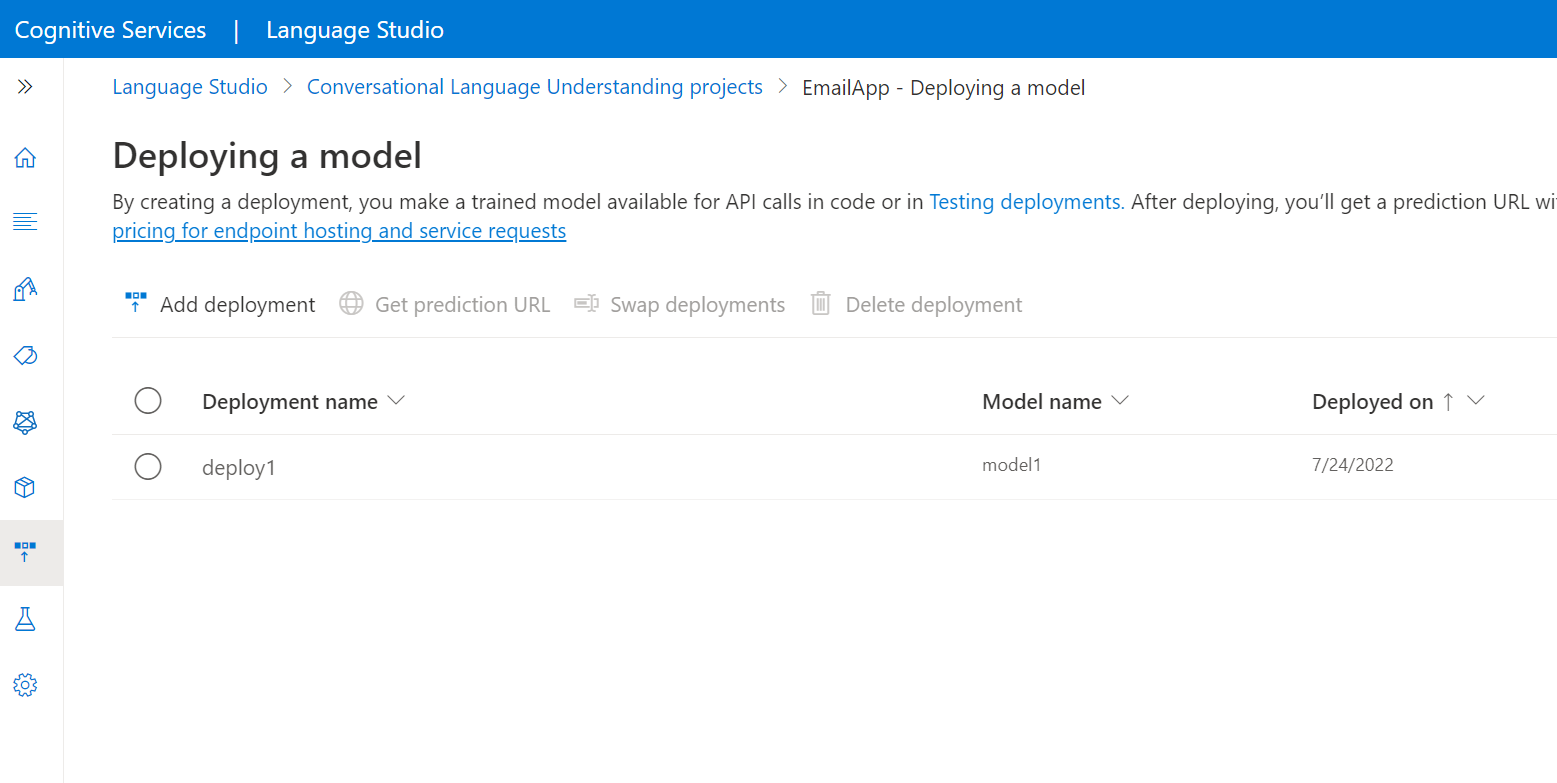
Välj Skapa ett nytt distributionsnamn för att skapa en ny distribution och tilldela en tränad modell från listrutan nedan. Annars kan du välja Skriv över ett befintligt distributionsnamn för att effektivt ersätta modellen som används av en befintlig distribution.
Anteckning
Att skriva över en befintlig distribution kräver inte ändringar i ditt Förutsägelse-API-anrop , men de resultat du får baseras på den nyligen tilldelade modellen.
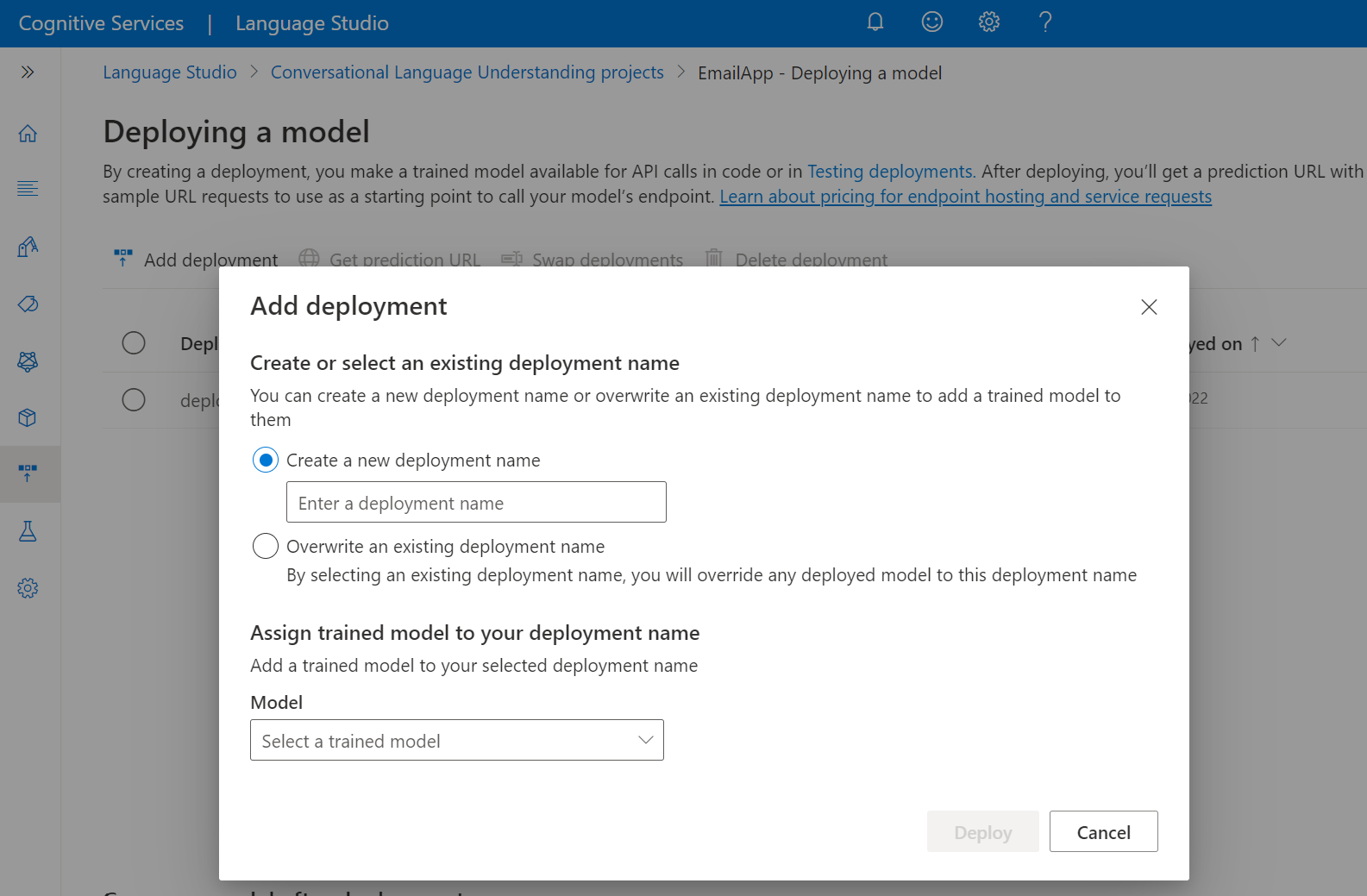
Välj en tränad modell i listrutan Modell .
Välj Distribuera för att starta distributionsjobbet.
När distributionen har slutförts visas ett förfallodatum bredvid den. Distributionen upphör att gälla när den distribuerade modellen inte är tillgänglig för förutsägelse, vilket vanligtvis sker tolv månader efter att en träningskonfiguration upphör att gälla.


Du använder projektnamnet och distributionsnamnet i nästa avsnitt.
Identifiera avsikter från en mikrofon
Följ de här stegen för att skapa ett nytt konsolprogram och installera Speech SDK.
Öppna en kommandotolk där du vill ha det nya projektet och skapa ett konsolprogram med .NET CLI. Filen
Program.csska skapas i projektkatalogen.dotnet new consoleInstallera Speech SDK i det nya projektet med .NET CLI.
dotnet add package Microsoft.CognitiveServices.SpeechErsätt innehållet i
Program.csmed följande kod.using Microsoft.CognitiveServices.Speech; using Microsoft.CognitiveServices.Speech.Audio; using Microsoft.CognitiveServices.Speech.Intent; class Program { // This example requires environment variables named: // "LANGUAGE_KEY", "LANGUAGE_ENDPOINT", "SPEECH_KEY", and "SPEECH_REGION" static string languageKey = Environment.GetEnvironmentVariable("LANGUAGE_KEY"); static string languageEndpoint = Environment.GetEnvironmentVariable("LANGUAGE_ENDPOINT"); static string speechKey = Environment.GetEnvironmentVariable("SPEECH_KEY"); static string speechRegion = Environment.GetEnvironmentVariable("SPEECH_REGION"); // Your CLU project name and deployment name. static string cluProjectName = "YourProjectNameGoesHere"; static string cluDeploymentName = "YourDeploymentNameGoesHere"; async static Task Main(string[] args) { var speechConfig = SpeechConfig.FromSubscription(speechKey, speechRegion); speechConfig.SpeechRecognitionLanguage = "en-US"; using var audioConfig = AudioConfig.FromDefaultMicrophoneInput(); // Creates an intent recognizer in the specified language using microphone as audio input. using (var intentRecognizer = new IntentRecognizer(speechConfig, audioConfig)) { var cluModel = new ConversationalLanguageUnderstandingModel( languageKey, languageEndpoint, cluProjectName, cluDeploymentName); var collection = new LanguageUnderstandingModelCollection(); collection.Add(cluModel); intentRecognizer.ApplyLanguageModels(collection); Console.WriteLine("Speak into your microphone."); var recognitionResult = await intentRecognizer.RecognizeOnceAsync().ConfigureAwait(false); // Checks result. if (recognitionResult.Reason == ResultReason.RecognizedIntent) { Console.WriteLine($"RECOGNIZED: Text={recognitionResult.Text}"); Console.WriteLine($" Intent Id: {recognitionResult.IntentId}."); Console.WriteLine($" Language Understanding JSON: {recognitionResult.Properties.GetProperty(PropertyId.LanguageUnderstandingServiceResponse_JsonResult)}."); } else if (recognitionResult.Reason == ResultReason.RecognizedSpeech) { Console.WriteLine($"RECOGNIZED: Text={recognitionResult.Text}"); Console.WriteLine($" Intent not recognized."); } else if (recognitionResult.Reason == ResultReason.NoMatch) { Console.WriteLine($"NOMATCH: Speech could not be recognized."); } else if (recognitionResult.Reason == ResultReason.Canceled) { var cancellation = CancellationDetails.FromResult(recognitionResult); Console.WriteLine($"CANCELED: Reason={cancellation.Reason}"); if (cancellation.Reason == CancellationReason.Error) { Console.WriteLine($"CANCELED: ErrorCode={cancellation.ErrorCode}"); Console.WriteLine($"CANCELED: ErrorDetails={cancellation.ErrorDetails}"); Console.WriteLine($"CANCELED: Did you update the subscription info?"); } } } } }Ange
Program.csvariablernacluProjectNameochcluDeploymentNametill namnen på projektet och distributionen. Information om hur du skapar ett CLU-projekt och en distribution finns i Skapa ett konversations-Language Understanding projekt.Om du vill ändra taligenkänningsspråket ersätter
en-USdu med ett annat språk som stöds. Till exempeles-ESför spanska (Spanien). Standardspråket ären-USom du inte anger något språk. Mer information om hur du identifierar ett av flera språk som kan talas finns i språkidentifiering.
Kör det nya konsolprogrammet för att starta taligenkänning från en mikrofon:
dotnet run
Viktigt
Se till att du anger LANGUAGE_KEYmiljövariablerna , LANGUAGE_ENDPOINT, SPEECH_KEYoch SPEECH_REGION enligt beskrivningen ovan. Om du inte anger dessa variabler misslyckas exemplet med ett felmeddelande.
Tala i mikrofonen när du uppmanas till det. Det du talar bör vara utdata som text:
Speak into your microphone.
RECOGNIZED: Text=Turn on the lights.
Intent Id: HomeAutomation.TurnOn.
Language Understanding JSON: {"kind":"ConversationResult","result":{"query":"turn on the lights","prediction":{"topIntent":"HomeAutomation.TurnOn","projectKind":"Conversation","intents":[{"category":"HomeAutomation.TurnOn","confidenceScore":0.97712576},{"category":"HomeAutomation.TurnOff","confidenceScore":0.8431633},{"category":"None","confidenceScore":0.782861}],"entities":[{"category":"HomeAutomation.DeviceType","text":"lights","offset":12,"length":6,"confidenceScore":1,"extraInformation":[{"extraInformationKind":"ListKey","key":"light"}]}]}}}.
Anteckning
Stöd för JSON-svaret för CLU via egenskapen LanguageUnderstandingServiceResponse_JsonResult har lagts till i Speech SDK version 1.26.
Avsikterna returneras i den mest sannolika sannolikhetsordningen. Här är en formaterad version av JSON-utdata där topIntent är HomeAutomation.TurnOn med en förtroendepoäng på 0,97712576 (97,71 %). Den näst mest sannolika avsikten kan vara HomeAutomation.TurnOff med en konfidenspoäng på 0,8985081 (84,31 %).
{
"kind": "ConversationResult",
"result": {
"query": "turn on the lights",
"prediction": {
"topIntent": "HomeAutomation.TurnOn",
"projectKind": "Conversation",
"intents": [
{
"category": "HomeAutomation.TurnOn",
"confidenceScore": 0.97712576
},
{
"category": "HomeAutomation.TurnOff",
"confidenceScore": 0.8431633
},
{
"category": "None",
"confidenceScore": 0.782861
}
],
"entities": [
{
"category": "HomeAutomation.DeviceType",
"text": "lights",
"offset": 12,
"length": 6,
"confidenceScore": 1,
"extraInformation": [
{
"extraInformationKind": "ListKey",
"key": "light"
}
]
}
]
}
}
}
Kommentarer
Nu när du har slutfört snabbstarten kan du tänka på följande:
- I det här exemplet används åtgärden
RecognizeOnceAsyncför att transkribera yttranden på upp till 30 sekunder eller tills tystnad identifieras. Information om kontinuerlig igenkänning för längre ljud, inklusive flerspråkiga konversationer, finns i Identifiera tal. - Om du vill känna igen tal från en ljudfil använder du
FromWavFileInputi stället förFromDefaultMicrophoneInput:using var audioConfig = AudioConfig.FromWavFileInput("YourAudioFile.wav"); - För komprimerade ljudfiler som MP4 installerar du GStreamer och använder
PullAudioInputStreamellerPushAudioInputStream. Mer information finns i Använda komprimerat indataljud.
Rensa resurser
Du kan använda Azure Portal- eller Azure-kommandoradsgränssnittet (CLI) för att ta bort de språk- och talresurser som du skapade.
Referensdokumentation | Paket (NuGet) | Ytterligare exempel på GitHub
I den här snabbstarten använder du tal- och språktjänster för att identifiera avsikter från ljuddata som hämtats från en mikrofon. Mer specifikt använder du speech-tjänsten för att känna igen tal och en CLU-modell (Conversational Language Understanding) för att identifiera avsikter.
Viktigt
Conversational Language Understanding (CLU) är tillgängligt för C# och C++ med Speech SDK version 1.25 eller senare.
Förutsättningar
- Azure-prenumeration – Skapa en kostnadsfritt
- Skapa en språkresurs i Azure Portal.
- Hämta språkresursnyckeln och slutpunkten. När språkresursen har distribuerats väljer du Gå till resurs för att visa och hantera nycklar. Mer information om Resurser för Azure AI-tjänster finns i Hämta nycklarna för din resurs.
- Skapa en Speech-resurs i Azure Portal.
- Hämta speech-resursnyckeln och -regionen. När speech-resursen har distribuerats väljer du Gå till resurs för att visa och hantera nycklar. Mer information om Resurser för Azure AI-tjänster finns i Hämta nycklarna för din resurs.
Konfigurera miljön
Speech SDK är tillgängligt som ett NuGet-paket och implementerar .NET Standard 2.0. Du installerar Speech SDK senare i den här guiden, men först kontrollerar du om det finns fler krav i SDK-installationsguiden .
Ange miljövariabler
Det här exemplet kräver miljövariabler med namnet LANGUAGE_KEY, LANGUAGE_ENDPOINT, SPEECH_KEYoch SPEECH_REGION.
Ditt program måste autentiseras för att få åtkomst till Azure AI-tjänstresurser. För produktion använder du ett säkert sätt att lagra och komma åt dina autentiseringsuppgifter. När du till exempel har hämtat en nyckel för skriver du den till en ny miljövariabel på den lokala dator som kör programmet.
Tips
Ta inte med nyckeln direkt i koden och publicera den aldrig offentligt. Mer information om autentiseringsalternativ som Azure Key Vault finns i säkerhetsartikeln om Azure AI-tjänster.
Om du vill ange miljövariablerna öppnar du ett konsolfönster och följer anvisningarna för operativsystemet och utvecklingsmiljön.
- Om du vill ange
LANGUAGE_KEYmiljövariabeln ersätteryour-language-keydu med en av nycklarna för resursen. - Om du vill ange
LANGUAGE_ENDPOINTmiljövariabeln ersätteryour-language-endpointdu med en av regionerna för din resurs. - Om du vill ange
SPEECH_KEYmiljövariabeln ersätteryour-speech-keydu med en av nycklarna för resursen. - Om du vill ange
SPEECH_REGIONmiljövariabeln ersätteryour-speech-regiondu med en av regionerna för din resurs.
setx LANGUAGE_KEY your-language-key
setx LANGUAGE_ENDPOINT your-language-endpoint
setx SPEECH_KEY your-speech-key
setx SPEECH_REGION your-speech-region
Anteckning
Om du bara behöver komma åt miljövariabeln i den aktuella konsolen som körs kan du ange miljövariabeln med set i stället för setx.
När du har lagt till miljövariablerna kan du behöva starta om alla program som körs och som behöver läsa miljövariabeln, inklusive konsolfönstret. Om du till exempel använder Visual Studio som redigeringsprogram startar du om Visual Studio innan du kör exemplet.
Skapa ett Language Understanding projekt för konversationer
När du har skapat en språkresurs skapar du ett projekt för att förstå konversationsspråk i Language Studio. Ett projekt är ett arbetsområde för att skapa anpassade ML-modeller baserat på dina data. Ditt projekt kan bara nås av dig och andra som har åtkomst till språkresursen som används.
Gå till Language Studio och logga in med ditt Azure-konto.
Skapa ett projekt för att förstå konversationsspråk
I den här snabbstarten kan du ladda ned det här exempelprojektet för hemautomatisering och importera det. Det här projektet kan förutsäga de avsedda kommandona från användarindata, till exempel att tända och stänga av lampor.
Under avsnittet Förstå frågor och konversationsspråk i Language Studio väljer du Konversationsspråkförstelse.
Då kommer du till projektsidan för projekt för konversationsspråkförstelse . Bredvid knappen Skapa nytt projekt väljer du Importera.
Ladda upp JSON-filen som du vill importera i fönstret som visas. Kontrollera att filen följer JSON-formatet som stöds.
När uppladdningen är klar hamnar du på sidan Schemadefinition . För den här snabbstarten har schemat redan skapats och yttranden är redan märkta med avsikter och entiteter.
Träna modellen
När du har skapat ett projekt bör du vanligtvis skapa ett schema och etikettyttranden. För den här snabbstarten har vi redan importerat ett färdigt projekt med skapat schema och märkta yttranden.
Om du vill träna en modell måste du starta ett träningsjobb. Utdata från ett lyckat träningsjobb är din tränade modell.
Så här börjar du träna din modell inifrån Language Studio:
Välj Träna modell på menyn till vänster.
Välj Starta ett träningsjobb på den översta menyn.
Välj Träna en ny modell och ange ett nytt modellnamn i textrutan. Om du vill ersätta en befintlig modell med en modell som tränats på nya data väljer du Skriv över en befintlig modell och väljer sedan en befintlig modell. Det går inte att ångra att skriva över en tränad modell, men det påverkar inte dina distribuerade modeller förrän du distribuerar den nya modellen.
Välj träningsläge. Du kan välja Standardträning för snabbare träning, men det är bara tillgängligt för engelska. Eller så kan du välja Avancerad utbildning som stöds för andra språk och flerspråkiga projekt, men det innebär längre utbildningstider. Läs mer om träningslägen.
Välj en datadelningsmetod . Du kan välja Att automatiskt dela upp testuppsättningen från träningsdata där systemet delar upp dina yttranden mellan tränings- och testuppsättningarna, enligt de angivna procentandelarna. Eller så kan du använda en manuell uppdelning av tränings- och testdata. Det här alternativet är bara aktiverat om du har lagt till yttranden i testuppsättningen när du har märkt dina yttranden.
Välj knappen Träna .
Välj träningsjobbets ID i listan. En panel visas där du kan kontrollera träningsförloppet, jobbstatusen och annan information för det här jobbet.
Anteckning
- Endast slutförda träningsjobb genererar modeller.
- Träningen kan ta lite tid mellan ett par minuter och ett par timmar baserat på antalet yttranden.
- Du kan bara köra ett träningsjobb i taget. Du kan inte starta andra träningsjobb i samma projekt förrän det pågående jobbet har slutförts.
- Maskininlärningen som används för att träna modeller uppdateras regelbundet. Om du vill träna på en tidigare konfigurationsversion väljer du Välj här om du vill ändra från sidan Starta ett träningsjobb och välja en tidigare version.
Distribuera din modell
När du har tränat en modell granskar du vanligtvis utvärderingsinformationen. I den här snabbstarten distribuerar du bara din modell och gör den tillgänglig för dig att prova i Language Studio, eller så kan du anropa förutsägelse-API:et.
Så här distribuerar du din modell inifrån Language Studio:
Välj Distribuera en modell på menyn till vänster.
Välj Lägg till distribution för att starta guiden Lägg till distribution .
Välj Skapa ett nytt distributionsnamn för att skapa en ny distribution och tilldela en tränad modell i listrutan nedan. Annars kan du välja Skriv över ett befintligt distributionsnamn för att effektivt ersätta den modell som används av en befintlig distribution.
Anteckning
Om du skriver över en befintlig distribution krävs inte ändringar i ditt Förutsägelse-API-anrop , men de resultat du får baseras på den nyligen tilldelade modellen.
Välj en tränad modell i listrutan Modell .
Välj Distribuera för att starta distributionsjobbet.
När distributionen har slutförts visas ett förfallodatum bredvid den. Distributionen upphör att gälla när den distribuerade modellen inte är tillgänglig för förutsägelse, vilket vanligtvis sker tolv månader efter att en träningskonfiguration upphör att gälla.
Du använder projektnamnet och distributionsnamnet i nästa avsnitt.
Identifiera avsikter från en mikrofon
Följ de här stegen för att skapa ett nytt konsolprogram och installera Speech SDK.
Skapa ett nytt C++-konsolprojekt i Visual Studio Community 2022 med namnet
SpeechRecognition.Installera Speech SDK i ditt nya projekt med NuGet-pakethanteraren.
Install-Package Microsoft.CognitiveServices.SpeechErsätt innehållet i
SpeechRecognition.cppmed följande kod:#include <iostream> #include <stdlib.h> #include <speechapi_cxx.h> using namespace Microsoft::CognitiveServices::Speech; using namespace Microsoft::CognitiveServices::Speech::Audio; using namespace Microsoft::CognitiveServices::Speech::Intent; std::string GetEnvironmentVariable(const char* name); int main() { // This example requires environment variables named: // "LANGUAGE_KEY", "LANGUAGE_ENDPOINT", "SPEECH_KEY", and "SPEECH_REGION" auto languageKey = GetEnvironmentVariable("LANGUAGE_KEY"); auto languageEndpoint = GetEnvironmentVariable("LANGUAGE_ENDPOINT"); auto speechKey = GetEnvironmentVariable("SPEECH_KEY"); auto speechRegion = GetEnvironmentVariable("SPEECH_REGION"); auto cluProjectName = "YourProjectNameGoesHere"; auto cluDeploymentName = "YourDeploymentNameGoesHere"; if ((size(languageKey) == 0) || (size(languageEndpoint) == 0) || (size(speechKey) == 0) || (size(speechRegion) == 0)) { std::cout << "Please set LANGUAGE_KEY, LANGUAGE_ENDPOINT, SPEECH_KEY, and SPEECH_REGION environment variables." << std::endl; return -1; } auto speechConfig = SpeechConfig::FromSubscription(speechKey, speechRegion); speechConfig->SetSpeechRecognitionLanguage("en-US"); auto audioConfig = AudioConfig::FromDefaultMicrophoneInput(); auto intentRecognizer = IntentRecognizer::FromConfig(speechConfig, audioConfig); std::vector<std::shared_ptr<LanguageUnderstandingModel>> models; auto cluModel = ConversationalLanguageUnderstandingModel::FromResource( languageKey, languageEndpoint, cluProjectName, cluDeploymentName); models.push_back(cluModel); intentRecognizer->ApplyLanguageModels(models); std::cout << "Speak into your microphone.\n"; auto result = intentRecognizer->RecognizeOnceAsync().get(); if (result->Reason == ResultReason::RecognizedIntent) { std::cout << "RECOGNIZED: Text=" << result->Text << std::endl; std::cout << " Intent Id: " << result->IntentId << std::endl; std::cout << " Intent Service JSON: " << result->Properties.GetProperty(PropertyId::LanguageUnderstandingServiceResponse_JsonResult) << std::endl; } else if (result->Reason == ResultReason::RecognizedSpeech) { std::cout << "RECOGNIZED: Text=" << result->Text << " (intent could not be recognized)" << std::endl; } else if (result->Reason == ResultReason::NoMatch) { std::cout << "NOMATCH: Speech could not be recognized." << std::endl; } else if (result->Reason == ResultReason::Canceled) { auto cancellation = CancellationDetails::FromResult(result); std::cout << "CANCELED: Reason=" << (int)cancellation->Reason << std::endl; if (cancellation->Reason == CancellationReason::Error) { std::cout << "CANCELED: ErrorCode=" << (int)cancellation->ErrorCode << std::endl; std::cout << "CANCELED: ErrorDetails=" << cancellation->ErrorDetails << std::endl; std::cout << "CANCELED: Did you update the subscription info?" << std::endl; } } } std::string GetEnvironmentVariable(const char* name) { #if defined(_MSC_VER) size_t requiredSize = 0; (void)getenv_s(&requiredSize, nullptr, 0, name); if (requiredSize == 0) { return ""; } auto buffer = std::make_unique<char[]>(requiredSize); (void)getenv_s(&requiredSize, buffer.get(), requiredSize, name); return buffer.get(); #else auto value = getenv(name); return value ? value : ""; #endif }Ange
SpeechRecognition.cppvariablernacluProjectNameochcluDeploymentNametill namnen på projektet och distributionen. Information om hur du skapar ett CLU-projekt och en distribution finns i Skapa ett konversations-Language Understanding projekt.Om du vill ändra taligenkänningsspråket ersätter du
en-USmed ett annat språk som stöds. Till exempeles-ESför spanska (Spanien). Standardspråket ären-USom du inte anger något språk. Mer information om hur du identifierar ett av flera språk som kan talas finns i språkidentifiering.
Skapa och kör det nya konsolprogrammet för att starta taligenkänning från en mikrofon.
Viktigt
Se till att du anger LANGUAGE_KEYmiljövariablerna , LANGUAGE_ENDPOINT, SPEECH_KEYoch SPEECH_REGION enligt beskrivningen ovan. Om du inte anger dessa variabler misslyckas exemplet med ett felmeddelande.
Tala i mikrofonen när du uppmanas till det. Det du talar bör vara utdata som text:
Speak into your microphone.
RECOGNIZED: Text=Turn on the lights.
Intent Id: HomeAutomation.TurnOn.
Language Understanding JSON: {"kind":"ConversationResult","result":{"query":"turn on the lights","prediction":{"topIntent":"HomeAutomation.TurnOn","projectKind":"Conversation","intents":[{"category":"HomeAutomation.TurnOn","confidenceScore":0.97712576},{"category":"HomeAutomation.TurnOff","confidenceScore":0.8431633},{"category":"None","confidenceScore":0.782861}],"entities":[{"category":"HomeAutomation.DeviceType","text":"lights","offset":12,"length":6,"confidenceScore":1,"extraInformation":[{"extraInformationKind":"ListKey","key":"light"}]}]}}}.
Anteckning
Stöd för JSON-svaret för CLU via egenskapen LanguageUnderstandingServiceResponse_JsonResult lades till i Speech SDK version 1.26.
Avsikterna returneras i sannolikhetsordningen som mest sannolikt är minst troligt. Här är en formaterad version av JSON-utdata där topIntent är HomeAutomation.TurnOn med en konfidenspoäng på 0,97712576 (97,71 %). Den näst mest sannolika avsikten kan vara HomeAutomation.TurnOff med en konfidenspoäng på 0,8985081 (84,31 %).
{
"kind": "ConversationResult",
"result": {
"query": "turn on the lights",
"prediction": {
"topIntent": "HomeAutomation.TurnOn",
"projectKind": "Conversation",
"intents": [
{
"category": "HomeAutomation.TurnOn",
"confidenceScore": 0.97712576
},
{
"category": "HomeAutomation.TurnOff",
"confidenceScore": 0.8431633
},
{
"category": "None",
"confidenceScore": 0.782861
}
],
"entities": [
{
"category": "HomeAutomation.DeviceType",
"text": "lights",
"offset": 12,
"length": 6,
"confidenceScore": 1,
"extraInformation": [
{
"extraInformationKind": "ListKey",
"key": "light"
}
]
}
]
}
}
}
Kommentarer
Nu när du har slutfört snabbstarten kan du tänka på följande:
- I det här exemplet används åtgärden
RecognizeOnceAsyncför att transkribera yttranden på upp till 30 sekunder eller tills tystnad identifieras. Information om kontinuerlig igenkänning för längre ljud, inklusive flerspråkiga konversationer, finns i Så här känner du igen tal. - Om du vill känna igen tal från en ljudfil använder du
FromWavFileInputi stället förFromDefaultMicrophoneInput:auto audioInput = AudioConfig::FromWavFileInput("YourAudioFile.wav"); - För komprimerade ljudfiler som MP4 installerar du GStreamer och använder
PullAudioInputStreamellerPushAudioInputStream. Mer information finns i Så här använder du komprimerat indataljud.
Rensa resurser
Du kan använda Azure Portal eller Azure Command Line Interface (CLI) för att ta bort språk- och talresurserna som du skapade.
Referensdokumentation | Ytterligare exempel på GitHub
Speech SDK för Java har inte stöd för avsiktsigenkänning med konversationell språktolkning (CLU). Välj ett annat programmeringsspråk eller Java-referensen och exempel som är länkade från början av den här artikeln.