Träna en anpassad talmodell
I den här artikeln får du lära dig hur du tränar en anpassad modell för att förbättra igenkänningsprecisionen från Microsofts basmodell. Taligenkänningens noggrannhet och kvalitet för en anpassad talmodell förblir konsekvent, även när en ny basmodell släpps.
Kommentar
Du betalar för användning av anpassad talmodell och slutpunktsvärd. Du debiteras också för anpassad talmodellträning om basmodellen skapades den 1 oktober 2023 och senare. Du debiteras inte för träning om basmodellen skapades före oktober 2023. Mer information finns i Prissättning för Azure AI Speech och avsnittet Avgift för anpassning i migreringsguiden för tal till text 3.2.
Att träna en modell är vanligtvis en iterativ process. Först väljer du en basmodell som är startpunkten för en ny modell. Du tränar en modell med datauppsättningar som kan innehålla text och ljud, och sedan testar du. Om igenkänningskvaliteten eller noggrannheten inte uppfyller dina krav kan du skapa en ny modell med fler eller ändrade träningsdata och sedan testa igen.
Du kan använda en anpassad modell under en begränsad tid efter att den har tränats. Du måste regelbundet återskapa och anpassa din anpassade modell från den senaste basmodellen för att dra nytta av den förbättrade noggrannheten och kvaliteten. Mer information finns i Livscykel för modell och slutpunkt.
Viktigt!
Om du ska träna en anpassad modell med ljuddata väljer du en Speech-resursregion med dedikerad maskinvara för att träna ljuddata. När en modell har tränats kan du kopiera den till en Speech-resurs i en annan region efter behov.
I regioner med dedikerad maskinvara för anpassad talträning använder Speech-tjänsten upp till 20 timmar av dina ljudträningsdata och kan bearbeta cirka 10 timmars data per dag. I andra regioner använder Speech-tjänsten upp till 8 timmar av dina ljuddata och kan bearbeta cirka 1 timme data per dag. Mer information finns i fotnoter i regionstabellen.
Skapa en modell
När du har laddat upp träningsdatauppsättningar följer du de här anvisningarna för att börja träna din modell:
Logga in på Speech Studio.
Välj Anpassat tal> Projektnamnet >Träna anpassade modeller.
Välj Träna en ny modell.
På sidan Välj en baslinjemodell väljer du en basmodell och väljer sedan Nästa. Om du inte är säker väljer du den senaste modellen överst i listan. Namnet på basmodellen motsvarar det datum då den släpptes i YYYYMMDD-format. Anpassningsfunktionerna i basmodellen visas i parenteser efter modellnamnet i Speech Studio.
Viktigt!
Anteckna förfallodatumet för anpassning . Det här är det sista datumet som du kan använda basmodellen för träning. Mer information finns i Livscykel för modell och slutpunkt.
På sidan Välj data väljer du en eller flera datauppsättningar som du vill använda för träning. Om det inte finns några tillgängliga datauppsättningar avbryter du installationen och går sedan till menyn Taldatauppsättningar för att ladda upp datauppsättningar.
Ange ett namn och en beskrivning för din anpassade modell och välj sedan Nästa.
Du kan också markera kryssrutan Lägg till test i nästa steg . Om du hoppar över det här steget kan du köra samma tester senare. Mer information finns i Testigenkänningskvalitet och Testmodell kvantitativt.
Välj Spara och stäng för att starta bygget för din anpassade modell.
Gå tillbaka till sidan Träna anpassade modeller .
Viktigt!
Anteckna förfallodatumet . Det här är det sista datumet som du kan använda din anpassade modell för taligenkänning. Mer information finns i Livscykel för modell och slutpunkt.
Om du vill skapa en modell med datauppsättningar för träning använder du spx csr model create kommandot . Skapa begärandeparametrarna enligt följande instruktioner:
- Ange parametern
projecttill ID för ett befintligt projekt. Den här parametern rekommenderas så att du även kan visa och hantera modellen i Speech Studio. Du kan köraspx csr project listkommandot för att hämta tillgängliga projekt. - Ange den obligatoriska
datasetparametern till ID för en datauppsättning som du vill använda för träning. Om du vill ange flera datauppsättningar anger du parameterndatasets(plural) och separerar ID:n med ett semikolon. - Ange den obligatoriska
languageparametern. Datamängdens nationella inställningar måste matcha projektets nationella inställningar. Språkvarianten kan inte ändras senare. Parametern Speech CLIlanguagemotsvararlocaleegenskapen i JSON-begäran och -svaret. - Ange den obligatoriska
nameparametern. Den här parametern är namnet som visas i Speech Studio. Parametern Speech CLInamemotsvarardisplayNameegenskapen i JSON-begäran och -svaret. - Du kan också ange egenskapen
base. Exempel:--base 1aae1070-7972-47e9-a977-87e3b05c457d. Om du inte angerbaseanvänds standardbasmodellen för nationella inställningar. Parametern Speech CLIbasemotsvararbaseModelegenskapen i JSON-begäran och -svaret.
Här är ett exempel på ett Speech CLI-kommando som skapar en modell med datauppsättningar för träning:
spx csr model create --api-version v3.1 --project YourProjectId --name "My Model" --description "My Model Description" --dataset YourDatasetId --language "en-US"
Kommentar
I det här exemplet base anges inte, så standardbasmodellen för språkvarianten används. Basmodell-URI:n returneras i svaret.
Du bör få en svarstext i följande format:
{
"self": "https://eastus.api.cognitive.microsoft.com/speechtotext/v3.1/models/86c4ebd7-d70d-4f67-9ccc-84609504ffc7",
"baseModel": {
"self": "https://eastus.api.cognitive.microsoft.com/speechtotext/v3.1/models/base/1aae1070-7972-47e9-a977-87e3b05c457d"
},
"datasets": [
{
"self": "https://eastus.api.cognitive.microsoft.com/speechtotext/v3.1/datasets/69e46263-ab10-4ab4-abbe-62e370104d95"
}
],
"links": {
"manifest": "https://eastus.api.cognitive.microsoft.com/speechtotext/v3.1/models/86c4ebd7-d70d-4f67-9ccc-84609504ffc7/manifest",
"copyTo": "https://eastus.api.cognitive.microsoft.com/speechtotext/v3.1/models/86c4ebd7-d70d-4f67-9ccc-84609504ffc7:copyto"
},
"project": {
"self": "https://eastus.api.cognitive.microsoft.com/speechtotext/v3.1/projects/5d25e60a-7f4a-4816-afd9-783bb8daccfc"
},
"properties": {
"deprecationDates": {
"adaptationDateTime": "2023-01-15T00:00:00Z",
"transcriptionDateTime": "2024-07-15T00:00:00Z"
}
},
"lastActionDateTime": "2022-05-21T13:21:01Z",
"status": "NotStarted",
"createdDateTime": "2022-05-21T13:21:01Z",
"locale": "en-US",
"displayName": "My Model",
"description": "My Model Description"
}
Viktigt!
Anteckna datumet i egenskapen adaptationDateTime . Det här är det sista datumet som du kan använda basmodellen för träning. Mer information finns i Livscykel för modell och slutpunkt.
Anteckna datumet i egenskapen transcriptionDateTime . Det här är det sista datumet som du kan använda din anpassade modell för taligenkänning. Mer information finns i Livscykel för modell och slutpunkt.
Egenskapen på den översta nivån self i svarstexten är modellens URI. Använd den här URI:n för att få information om modellens projekt-, manifest- och utfasningsdatum. Du använder också den här URI:n för att uppdatera eller ta bort en modell.
För Hjälp med Speech CLI med modeller kör du följande kommando:
spx help csr model
Om du vill skapa en modell med datauppsättningar för träning använder du den Models_Create åtgärden för REST-API:et Tal till text. Skapa begärandetexten enligt följande instruktioner:
projectAnge egenskapen till URI för ett befintligt projekt. Den här egenskapen rekommenderas så att du även kan visa och hantera modellen i Speech Studio. Du kan göra en Projects_List begäran om att få tillgängliga projekt.- Ange den obligatoriska
datasetsegenskapen till URI:n för de datauppsättningar som du vill använda för träning. - Ange den obligatoriska
localeegenskapen. Modellspråket måste matcha språket för projektet och basmodellen. Språkvarianten kan inte ändras senare. - Ange den obligatoriska
displayNameegenskapen. Den här egenskapen är det namn som visas i Speech Studio. - Du kan också ange egenskapen
baseModel. Exempel:"baseModel": {"self": "https://eastus.api.cognitive.microsoft.com/speechtotext/v3.1/models/base/1aae1070-7972-47e9-a977-87e3b05c457d"}. Om du inte angerbaseModelanvänds standardbasmodellen för nationella inställningar.
Gör en HTTP POST-begäran med hjälp av URI:n enligt följande exempel. Ersätt YourSubscriptionKey med din Speech-resursnyckel, ersätt YourServiceRegion med resursregionen Speech och ange egenskaperna för begärandetexten enligt beskrivningen ovan.
curl -v -X POST -H "Ocp-Apim-Subscription-Key: YourSubscriptionKey" -H "Content-Type: application/json" -d '{
"project": {
"self": "https://eastus.api.cognitive.microsoft.com/speechtotext/v3.1/projects/5d25e60a-7f4a-4816-afd9-783bb8daccfc"
},
"displayName": "My Model",
"description": "My Model Description",
"baseModel": null,
"datasets": [
{
"self": "https://eastus.api.cognitive.microsoft.com/speechtotext/v3.1/datasets/69e46263-ab10-4ab4-abbe-62e370104d95"
}
],
"locale": "en-US"
}' "https://YourServiceRegion.api.cognitive.microsoft.com/speechtotext/v3.1/models"
Kommentar
I det här exemplet baseModel anges inte, så standardbasmodellen för språkvarianten används. Basmodell-URI:n returneras i svaret.
Du bör få en svarstext i följande format:
{
"self": "https://eastus.api.cognitive.microsoft.com/speechtotext/v3.1/models/86c4ebd7-d70d-4f67-9ccc-84609504ffc7",
"baseModel": {
"self": "https://eastus.api.cognitive.microsoft.com/speechtotext/v3.1/models/base/1aae1070-7972-47e9-a977-87e3b05c457d"
},
"datasets": [
{
"self": "https://eastus.api.cognitive.microsoft.com/speechtotext/v3.1/datasets/69e46263-ab10-4ab4-abbe-62e370104d95"
}
],
"links": {
"manifest": "https://eastus.api.cognitive.microsoft.com/speechtotext/v3.1/models/86c4ebd7-d70d-4f67-9ccc-84609504ffc7/manifest",
"copyTo": "https://eastus.api.cognitive.microsoft.com/speechtotext/v3.1/models/86c4ebd7-d70d-4f67-9ccc-84609504ffc7:copyto"
},
"project": {
"self": "https://eastus.api.cognitive.microsoft.com/speechtotext/v3.1/projects/5d25e60a-7f4a-4816-afd9-783bb8daccfc"
},
"properties": {
"deprecationDates": {
"adaptationDateTime": "2023-01-15T00:00:00Z",
"transcriptionDateTime": "2024-07-15T00:00:00Z"
}
},
"lastActionDateTime": "2022-05-21T13:21:01Z",
"status": "NotStarted",
"createdDateTime": "2022-05-21T13:21:01Z",
"locale": "en-US",
"displayName": "My Model",
"description": "My Model Description"
}
Viktigt!
Anteckna datumet i egenskapen adaptationDateTime . Det här är det sista datumet som du kan använda basmodellen för träning. Mer information finns i Livscykel för modell och slutpunkt.
Anteckna datumet i egenskapen transcriptionDateTime . Det här är det sista datumet som du kan använda din anpassade modell för taligenkänning. Mer information finns i Livscykel för modell och slutpunkt.
Egenskapen på den översta nivån self i svarstexten är modellens URI. Använd den här URI:n för att få information om modellens projekt-, manifest- och utfasningsdatum. Du använder också den här URI:n för att uppdatera eller ta bort modellen.
Kopiera en modell
Du kan kopiera en modell till ett annat projekt som använder samma nationella inställningar. När en modell till exempel har tränats med ljuddata i en region med dedikerad maskinvara för träning kan du kopiera den till en Speech-resurs i en annan region efter behov.
Följ dessa instruktioner för att kopiera en modell till ett projekt i en annan region:
- Logga in på Speech Studio.
- Välj Anpassat tal> Projektnamnet >Träna anpassade modeller.
- Välj Kopiera till.
- På sidan Kopiera talmodell väljer du en målregion där du vill kopiera modellen.

- Välj en Speech-resurs i målregionen eller skapa en ny Speech-resurs.
- Välj ett projekt där du vill kopiera modellen eller skapa ett nytt projekt.
- Välj kopiera.

När modellen har kopierats meddelas du och kan visa den i målprojektet.
Kopiering av en modell direkt till ett projekt i en annan region stöds inte med Speech CLI. Du kan kopiera en modell till ett projekt i en annan region med hjälp av REST-API:et Speech Studio eller Speech to text.
Om du vill kopiera en modell till en annan Speech-resurs använder du den Models_CopyTo åtgärden för REST-API:et Tal till text. Skapa begärandetexten enligt följande instruktioner:
- Ange den obligatoriska
targetSubscriptionKeyegenskapen till nyckeln för målresursen Tal.
Gör en HTTP POST-begäran med hjälp av URI:n enligt följande exempel. Använd regionen och URI:n för den modell som du vill kopiera från. Ersätt YourModelId med modell-ID:t, ersätt YourSubscriptionKey med din Speech-resursnyckel, ersätt YourServiceRegion med resursregionen Speech och ange egenskaperna för begärandetexten enligt beskrivningen ovan.
curl -v -X POST -H "Ocp-Apim-Subscription-Key: YourSubscriptionKey" -H "Content-Type: application/json" -d '{
"targetSubscriptionKey": "ModelDestinationSpeechResourceKey"
} ' "https://YourServiceRegion.api.cognitive.microsoft.com/speechtotext/v3.1/models/YourModelId:copyto"
Kommentar
Endast egenskapen targetSubscriptionKey i begärandetexten innehåller information om målresursen Tal.
Du bör få en svarstext i följande format:
{
"self": "https://eastus.api.cognitive.microsoft.com/speechtotext/v3.1/models/9df35ddb-edf9-4e91-8d1a-576d09aabdae",
"baseModel": {
"self": "https://eastus.api.cognitive.microsoft.com/speechtotext/v3.1/models/base/eb5450a7-3ca2-461a-b2d7-ddbb3ad96540"
},
"links": {
"manifest": "https://eastus.api.cognitive.microsoft.com/speechtotext/v3.1/models/9df35ddb-edf9-4e91-8d1a-576d09aabdae/manifest",
"copyTo": "https://eastus.api.cognitive.microsoft.com/speechtotext/v3.1/models/9df35ddb-edf9-4e91-8d1a-576d09aabdae:copyto"
},
"properties": {
"deprecationDates": {
"adaptationDateTime": "2023-01-15T00:00:00Z",
"transcriptionDateTime": "2024-07-15T00:00:00Z"
}
},
"lastActionDateTime": "2022-05-22T23:15:27Z",
"status": "NotStarted",
"createdDateTime": "2022-05-22T23:15:27Z",
"locale": "en-US",
"displayName": "My Model",
"description": "My Model Description",
"customProperties": {
"PortalAPIVersion": "3",
"Purpose": "",
"VadKind": "None",
"ModelClass": "None",
"UsesHalide": "False",
"IsDynamicGrammarSupported": "False"
}
}
Anslut en modell
Modeller kan ha kopierats från ett projekt med hjälp av Speech CLI eller REST API, utan att vara anslutna till ett annat projekt. Anslut en modell handlar om att uppdatera modellen med en referens till projektet.
Om du uppmanas att göra det i Speech Studio kan du ansluta dem genom att välja knappen Anslut.
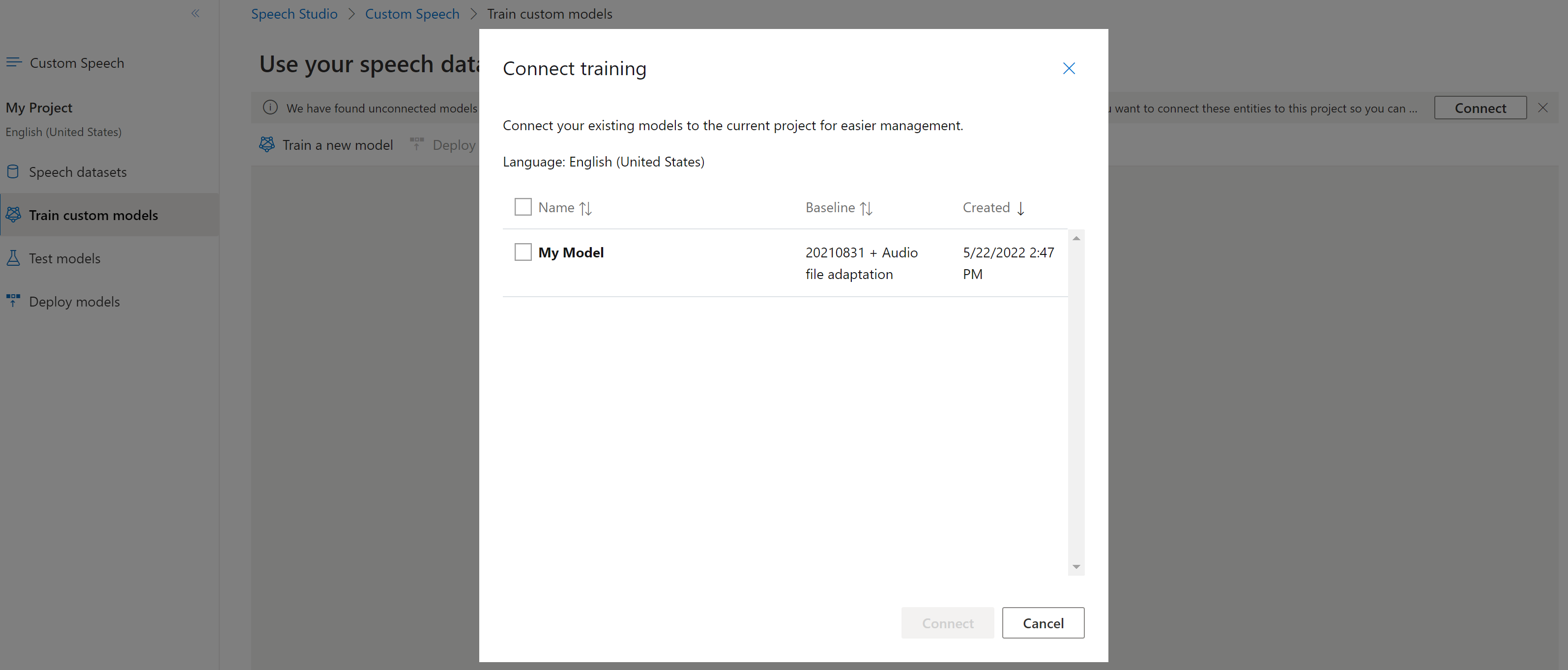
Om du vill ansluta en modell till ett projekt använder du spx csr model update kommandot . Skapa begärandeparametrarna enligt följande instruktioner:
- Ange parametern
projecttill URI för ett befintligt projekt. Den här parametern rekommenderas så att du även kan visa och hantera modellen i Speech Studio. Du kan köraspx csr project listkommandot för att hämta tillgängliga projekt. - Ange den obligatoriska
modelIdparametern till ID för den modell som du vill ansluta till projektet.
Här är ett exempel på ett Speech CLI-kommando som ansluter en modell till ett projekt:
spx csr model update --api-version v3.1 --model YourModelId --project YourProjectId
Du bör få en svarstext i följande format:
{
"project": {
"self": "https://eastus.api.cognitive.microsoft.com/speechtotext/v3.1/projects/e6ffdefd-9517-45a9-a89c-7b5028ed0e56"
},
}
För Hjälp med Speech CLI med modeller kör du följande kommando:
spx help csr model
Om du vill ansluta en ny modell till ett projekt för talresursen där modellen kopierades använder du den Models_Update åtgärden i REST API:et Tal till text. Skapa begärandetexten enligt följande instruktioner:
- Ange den obligatoriska
projectegenskapen till URI:n för ett befintligt projekt. Den här egenskapen rekommenderas så att du även kan visa och hantera modellen i Speech Studio. Du kan göra en Projects_List begäran om att få tillgängliga projekt.
Gör en HTTP PATCH-begäran med hjälp av URI:n enligt följande exempel. Använd URI:n för den nya modellen. Du kan hämta det nya modell-ID:t från self egenskapen för Models_CopyTo svarstext. Ersätt YourSubscriptionKey med din Speech-resursnyckel, ersätt YourServiceRegion med resursregionen Speech och ange egenskaperna för begärandetexten enligt beskrivningen ovan.
curl -v -X PATCH -H "Ocp-Apim-Subscription-Key: YourSubscriptionKey" -H "Content-Type: application/json" -d '{
"project": {
"self": "https://eastus.api.cognitive.microsoft.com/speechtotext/v3.1/projects/e6ffdefd-9517-45a9-a89c-7b5028ed0e56"
},
}' "https://YourServiceRegion.api.cognitive.microsoft.com/speechtotext/v3.1/models"
Du bör få en svarstext i följande format:
{
"project": {
"self": "https://eastus.api.cognitive.microsoft.com/speechtotext/v3.1/projects/e6ffdefd-9517-45a9-a89c-7b5028ed0e56"
},
}