Träna din modell för förståelse av konversationsspråk
När du har slutfört märkningen av dina yttranden kan du börja träna en modell. Träning är den process där modellen lär sig av dina märkta yttranden.
Om du vill träna en modell startar du ett träningsjobb. Endast slutförda jobb skapar en modell. Träningsjobb upphör att gälla efter sju dagar. Efter den här tiden kommer du inte längre att kunna hämta jobbinformationen. Om träningsjobbet har slutförts och en modell har skapats påverkas det inte av att jobbet upphör att gälla. Du kan bara ha ett träningsjobb i taget och du kan inte starta andra jobb i samma projekt.
Träningstiderna kan vara allt från några sekunder när du hanterar enkla projekt, upp till ett par timmar när du når den maximala gränsen för yttranden.
Modellutvärderingen utlöses automatiskt när träningen har slutförts. Utvärderingsprocessen börjar med att använda den tränade modellen för att köra förutsägelser på yttrandena i testuppsättningen och jämför de förutsagda resultaten med de angivna etiketterna (som fastställer en baslinje för sanning).
Förutsättningar
- Ett projekt som har skapats med ett konfigurerat Azure Blob Storage-konto
- Märkta yttranden
Balansera träningsdata
Du bör försöka att hålla schemat väl balanserat när det gäller träningsdata. Att inkludera stora mängder av en avsikt och mycket få av en annan kommer att resultera i en modell som är starkt partisk mot vissa avsikter.
För att åtgärda detta kan du behöva göra en nedsampling av träningsuppsättningen eller lägga till den. Downsampling kan göras antingen genom att:
- Bli av med en viss procentandel av träningsdata slumpmässigt.
- På ett mer systematiskt sätt genom att analysera datauppsättningen och ta bort överrepresenterade dubblettposter.
Du kan också lägga till i träningsuppsättningen genom att välja Föreslå yttranden på fliken Dataetiketter i Language Studio. Konversationsbaserade Language Understanding skickar ett anrop till Azure OpenAI för att generera liknande yttranden.

Du bör också leta efter oavsiktliga "mönster" i träningsuppsättningen. Om träningsuppsättningen för en viss avsikt till exempel bara är gemener eller börjar med en viss fras. I sådana fall kan modellen du tränar lära dig dessa oavsiktliga fördomar i träningsuppsättningen i stället för att kunna generalisera.
Vi rekommenderar att du introducerar mångfald av höljen och skiljetecken i träningsuppsättningen. Om din modell förväntas hantera variationer måste du ha en träningsuppsättning som också återspeglar den mångfalden. Ta till exempel med några yttranden i rätt hölje och vissa i gemener.
Datadelning
Innan du påbörjar träningsprocessen är märkta yttranden i projektet indelade i en träningsuppsättning och en testuppsättning. Var och en av dem har olika funktioner. Träningsuppsättningen används för att träna modellen. Det här är den uppsättning som modellen lär sig de märkta yttrandena från. Testuppsättningen är en blinduppsättning som inte introduceras i modellen under träningen utan bara under utvärderingen.
När modellen har tränats kan modellen användas för att göra förutsägelser från yttrandena i testuppsättningen. Dessa förutsägelser används för att beräkna utvärderingsmått. Vi rekommenderar att du ser till att alla dina avsikter och entiteter är korrekt representerade i både tränings- och testuppsättningen.
Förståelse för konversationsspråk stöder två metoder för datadelning:
- Dela automatiskt upp testuppsättningen från träningsdata: Systemet delar dina taggade data mellan tränings- och testuppsättningarna enligt de procentsatser du väljer. Den rekommenderade procentuella uppdelningen är 80 % för träning och 20 % för testning.
Anteckning
Om du väljer alternativet Dela upp testuppsättningen automatiskt från träningsdata delas endast de data som är tilldelade till träningsuppsättningen upp enligt de procentsatser som anges.
- Använd en manuell delning av tränings- och testdata: Med den här metoden kan användarna definiera vilka yttranden som ska tillhöra vilken uppsättning. Det här steget aktiveras bara om du har lagt till yttranden till testuppsättningen under etikettering.
Träningslägen
CLU stöder två lägen för träning av dina modeller
Standardträningen använder snabba maskininlärningsalgoritmer för att träna dina modeller relativt snabbt. Detta är för närvarande endast tillgängligt för engelska och är inaktiverat för alla projekt som inte använder engelska (USA) eller engelska (UK) som primärspråk. Det här utbildningsalternativet är kostnadsfritt. Med standardträning kan du lägga till yttranden och testa dem snabbt utan kostnad. Utvärderingspoängen som visas bör vägleda dig om var du kan göra ändringar i projektet och lägga till fler yttranden. När du har itererat några gånger och gjort stegvisa förbättringar kan du överväga att använda avancerad träning för att träna en annan version av din modell.
Avancerad träning använder det senaste inom maskininlärningsteknik för att anpassa modeller med dina data. Detta förväntas visa bättre prestandapoäng för dina modeller och gör att du även kan använda de flerspråkiga funktionerna i CLU. Avancerad utbildning prissätts på olika sätt. Mer information finns i prisinformationen .
Använd utvärderingspoängen för att vägleda dina beslut. Det kan finnas tillfällen då ett specifikt exempel förutsägs felaktigt i avancerad träning i stället för när du använde standardträningsläge. Men om de övergripande utvärderingsresultaten är bättre med hjälp av avancerat rekommenderar vi att du använder din slutliga modell. Om så inte är fallet och du inte vill använda flerspråkiga funktioner kan du fortsätta att använda en modell som tränats med standardläge.
Anteckning
Du bör förvänta dig att se en skillnad i beteenden i avsiktens förtroendepoäng mellan träningslägena när varje algoritm kalibrerar sina poäng på olika sätt.
Träningsmodell
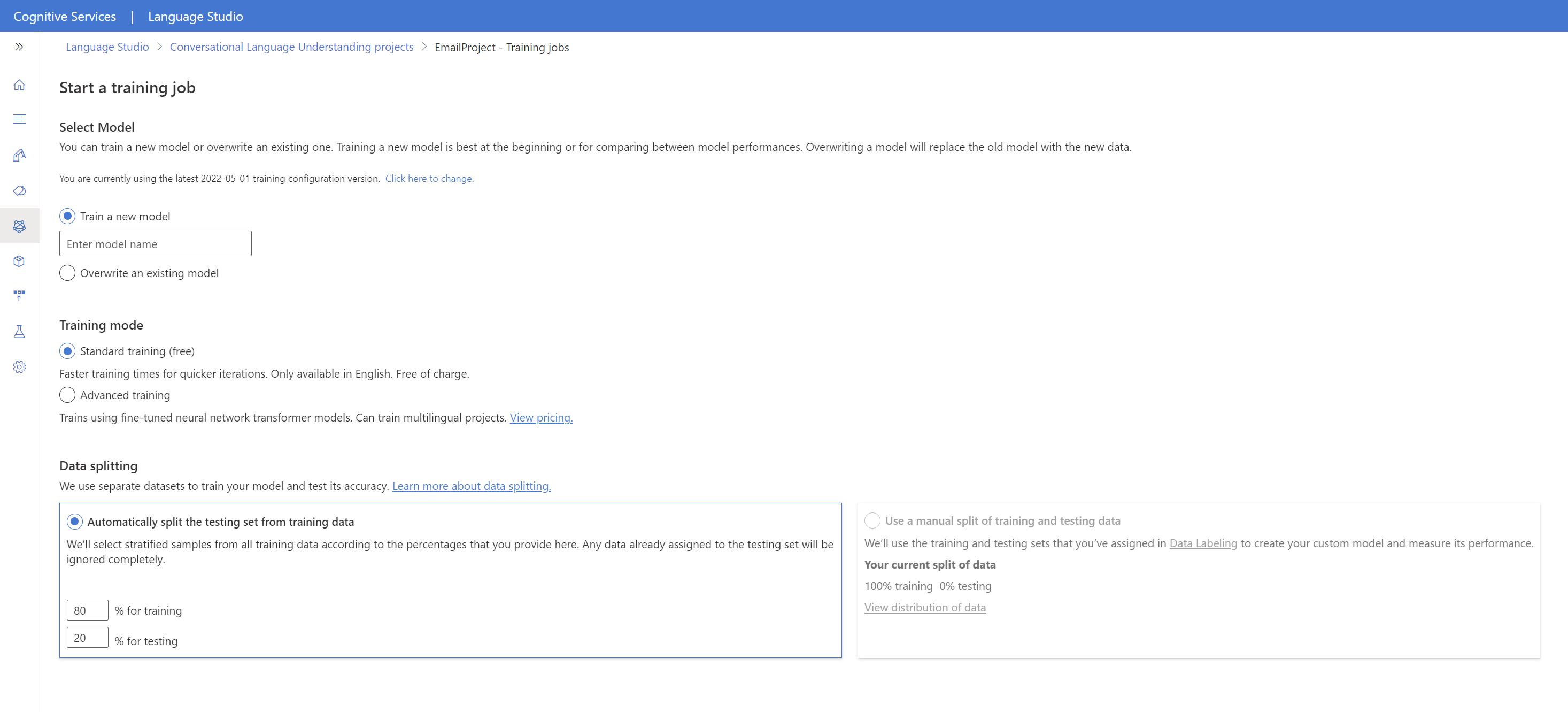
Så här börjar du träna din modell från Language Studio:
Välj Träna modell på menyn till vänster.
Välj Starta ett träningsjobb på den översta menyn.
Välj Träna en ny modell och ange ett nytt modellnamn i textrutan. Om du vill ersätta en befintlig modell med en modell som tränats på nya data väljer du Skriv över en befintlig modell och väljer sedan en befintlig modell. Det går inte att ångra att skriva över en tränad modell, men det påverkar inte dina distribuerade modeller förrän du distribuerar den nya modellen.
Välj träningsläge. Du kan välja Standardträning för snabbare träning, men det är bara tillgängligt för engelska. Eller så kan du välja Avancerad utbildning som stöds för andra språk och flerspråkiga projekt, men det innebär längre utbildningstider. Läs mer om träningslägen.
Välj en datadelningsmetod . Du kan välja Att automatiskt dela upp testuppsättningen från träningsdata där systemet delar dina yttranden mellan tränings- och testuppsättningarna, enligt de angivna procentsatserna. Eller så kan du använda en manuell delning av tränings- och testdata. Det här alternativet är bara aktiverat om du har lagt till yttranden i testuppsättningen när du har etiketterat dina yttranden.
Välj knappen Träna .
Välj träningsjobbets ID i listan. En panel visas där du kan kontrollera träningsförloppet, jobbstatusen och annan information för det här jobbet.
Anteckning
- Endast träningsjobb som har slutförts genererar modeller.
- Träningen kan ta lite tid mellan ett par minuter och ett par timmar baserat på antalet yttranden.
- Du kan bara köra ett träningsjobb i taget. Du kan inte starta andra träningsjobb i samma projekt förrän jobbet som körs har slutförts.
- Den maskininlärning som används för att träna modeller uppdateras regelbundet. Om du vill träna på en tidigare konfigurationsversion väljer du Välj här för att ändra från sidan Starta ett träningsjobb och välja en tidigare version.

Avbryt träningsjobb
Så här avbryter du ett träningsjobb från Language Studio
- På sidan Träna modell väljer du det träningsjobb som du vill avbryta och väljer Avbryt på den översta menyn.