Konfidenspoängen för ett svar
När en användarfråga matchas mot en kunskapsbas returnerar QnA Maker relevanta svar, tillsammans med en konfidenspoäng. Den här poängen anger att svaret är rätt matchning för den angivna användarfrågan.
Konfidenspoängen är ett tal mellan 0 och 100. En poäng på 100 är sannolikt en exakt matchning, medan en poäng på 0 innebär att inget matchande svar hittades. Ju högre poäng desto större förtroende för svaret. För en viss fråga kan flera svar returneras. I så fall returneras svaren i ordning för att minska konfidenspoängen.
I exemplet nedan kan du se en QnA-entitet med två frågor.

I exemplet ovan kan du förvänta dig poäng som exempelpoängintervallet nedan för olika typer av användarfrågor:
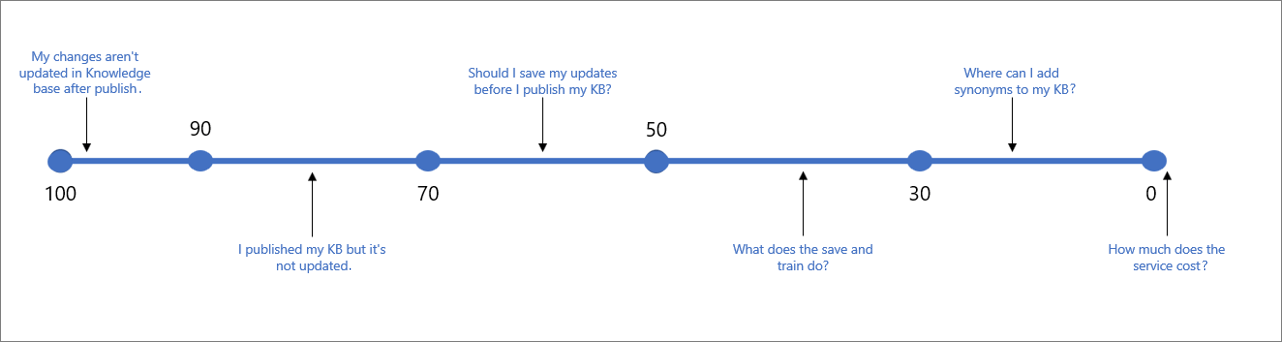
Följande tabell anger typiskt förtroende som är associerat för en viss poäng.
| Poängvärde | Poäng betydelse | Exempelfråga |
|---|---|---|
| 90 - 100 | En nästan exakt matchning av användarfråga och en KB-fråga | "Mina ändringar uppdateras inte i KB efter publiceringen" |
| > 70 | Hög konfidens – vanligtvis ett bra svar som helt besvarar användarens fråga | "Jag har publicerat min KB men den har inte uppdaterats" |
| 50 - 70 | Medelhög konfidens – vanligtvis ett ganska bra svar som bör besvara huvudsyftet med användarfrågan | "Ska jag spara mina uppdateringar innan jag publicerar min KB?" |
| 30 - 50 | Låg konfidens – vanligtvis ett relaterat svar som delvis svarar på användarens avsikt | "Vad gör spara och träna?" |
| < 30 | Mycket låg konfidens – svarar vanligtvis inte på användarens fråga, men har några matchande ord eller fraser | "Var kan jag lägga till synonymer i min KB" |
| 0 | Ingen matchning, så svaret returneras inte. | "Hur mycket kostar tjänsten" |
Välj ett poängtröskelvärde
Tabellen ovan visar de poäng som förväntas på de flesta KBs. Men eftersom varje KB är olika och har olika typer av ord, avsikter och mål rekommenderar vi att du testar och väljer det tröskelvärde som passar dig bäst. Som standard är tröskelvärdet inställt på 0, så att alla möjliga svar returneras. Det rekommenderade tröskelvärdet som bör fungera för de flesta KB är 50.
När du väljer tröskelvärdet bör du tänka på balansen mellan noggrannhet och täckning och justera tröskelvärdet baserat på dina krav.
Om Noggrannhet (eller precision) är viktigare för ditt scenario ökar du tröskelvärdet. På så sätt, varje gång du returnerar ett svar, blir det ett mycket mer självsäkert fall, och mycket mer sannolikt är det svar som användarna letar efter. I det här fallet kan det sluta med att du lämnar fler frågor obesvarade. Till exempel: om du gör tröskelvärdet 70 kan du missa några tvetydiga exempel som "vad är spara och träna?".
Om Täckning (eller återkallande) är viktigare och du vill svara på så många frågor som möjligt, även om det bara finns en partiell relation till användarens fråga, sänker du tröskelvärdet. Det innebär att det kan finnas fler fall där svaret inte svarar på användarens faktiska fråga, men ger ett annat något relaterat svar. Till exempel: om du gör tröskelvärdet 30 kan du ge svar på frågor som "Var kan jag redigera min KB?"
Kommentar
Nyare versioner av QnA Maker innehåller förbättringar av bedömningslogik och kan påverka ditt tröskelvärde. Varje gång du uppdaterar tjänsten måste du testa och justera tröskelvärdet om det behövs. Du kan kontrollera QnA-tjänstens version här och se hur du hämtar de senaste uppdateringarna här.
Ange tröskelvärde
Ange tröskelvärdet som en egenskap för JSON-brödtexten för GenerateAnswer API. Det innebär att du anger den för varje anrop till GenerateAnswer.
Från robotramverket anger du poängen som en del av alternativobjektet med C# eller Node.js.
Förbättra konfidenspoängen
För att förbättra konfidenspoängen för ett visst svar på en användarfråga kan du lägga till användarfrågan i kunskapsbas som en alternativ fråga om det svaret. Du kan också använda skiftlägesokänsliga ordändringar för att lägga till synonymer till nyckelord i din KB.
Liknande konfidenspoäng
När flera svar har en liknande konfidenspoäng är det troligt att frågan var för generisk och därför matchade med samma sannolikhet med flera svar. Försök att strukturera dina QnAs bättre så att varje QnA-entitet har en distinkt avsikt.
Skillnader i konfidenspoäng mellan test och produktion
Förtroendepoängen för ett svar kan variera något mellan testet och den publicerade versionen av kunskapsbasen även om innehållet är detsamma. Det beror på att innehållet i testet och den publicerade kunskapsbas finns i olika Azure AI Search-index.
Testindexet innehåller alla QnA-par i dina kunskapsbas. När du kör frågor mot testindexet gäller frågan för hela indexet och resultatet begränsas till partitionen för den specifika kunskapsbas. Om testfrågeresultaten påverkar din möjlighet att verifiera kunskapsbas negativt kan du:
- organisera din kunskapsbas med något av följande:
- 1 resurs som är begränsad till 1 KB: begränsa din enda QnA-resurs (och det resulterande Azure AI Search-testindexet) till en enda kunskapsbas.
- 2 resurser – 1 för test, 1 för produktion: har två QnA Maker-resurser, med en för testning (med egna test- och produktionsindex) och en för produkten (även med egna test- och produktionsindex)
- och använd alltid samma parametrar, till exempel top när du kör frågor mot både test- och produktions-kunskapsbas
När du publicerar en kunskapsbas flyttas innehållet i frågor och svar i kunskapsbas från testindexet till ett produktionsindex i Azure Search. Se hur publiceringsåtgärden fungerar.
Om du har en kunskapsbas i olika regioner använder varje region sitt eget Azure AI Search-index. Eftersom olika index används är poängen inte exakt desamma.
Ingen matchning hittades
När ingen bra matchning hittas av rankaren returneras konfidenspoängen 0,0 eller "Ingen" och standardsvaret är "Ingen bra matchning hittades i KB". Du kan åsidosätta det här standardsvaret i roboten eller programkoden som anropar slutpunkten. Alternativt kan du också ange åsidosättningssvaret i Azure och detta ändrar standardvärdet för alla kunskapsbas som distribueras i en viss QnA Maker-tjänst.