Få ansiktsposition med viseme
Kommentar
Information om de nationella inställningar som stöds för viseme-ID och blandningsformer finns i listan över alla språk som stöds. Skalbar vektorgrafik (SVG) stöds endast för en-US nationella inställningar.
En viseme är den visuella beskrivningen av ett fonme på talat språk. Det definierar ansiktets och munnens position medan en person talar. Varje viseme visar de viktigaste ansiktsställningarna för en specifik uppsättning fonem.
Du kan använda visemes för att styra förflyttningen av 2D- och 3D-avatarmodeller, så att ansiktspositionerna bäst överensstämmer med syntetiskt tal. Du kan till exempel:
- Skapa en animerad virtuell röstassistent för intelligenta kiosker och skapa integrerade tjänster i flera lägen för dina kunder.
- Skapa uppslukande nyhetssändningar och förbättra publikens upplevelser med naturliga ansikts- och munrörelser.
- Generera mer interaktiva spelavatarer och seriefigurer som kan tala med dynamiskt innehåll.
- Gör effektivare språkundervisningsvideor som hjälper språkstövare att förstå munbeteendet för varje ord och fonetik.
- Personer med hörselnedsättning kan också plocka upp ljud visuellt och "läppläsning" talinnehåll som visar visemes på ett animerat ansikte.
Mer information om visemes finns i den här introduktionsvideon.
Övergripande arbetsflöde för att producera viseme med tal
Neural text till tal (Neural TTS) omvandlar indatatext eller SSML (Speech Synthesis Markup Language) till verklighetstroget syntetiserat tal. Talljudutdata kan åtföljas av viseme-ID, skalbar vektorgrafik (SVG) eller blandningsformer. Med en 2D- eller 3D-återgivningsmotor kan du använda dessa viseme-händelser för att animera din avatar.
Det övergripande arbetsflödet för viseme visas i följande flödesschema:
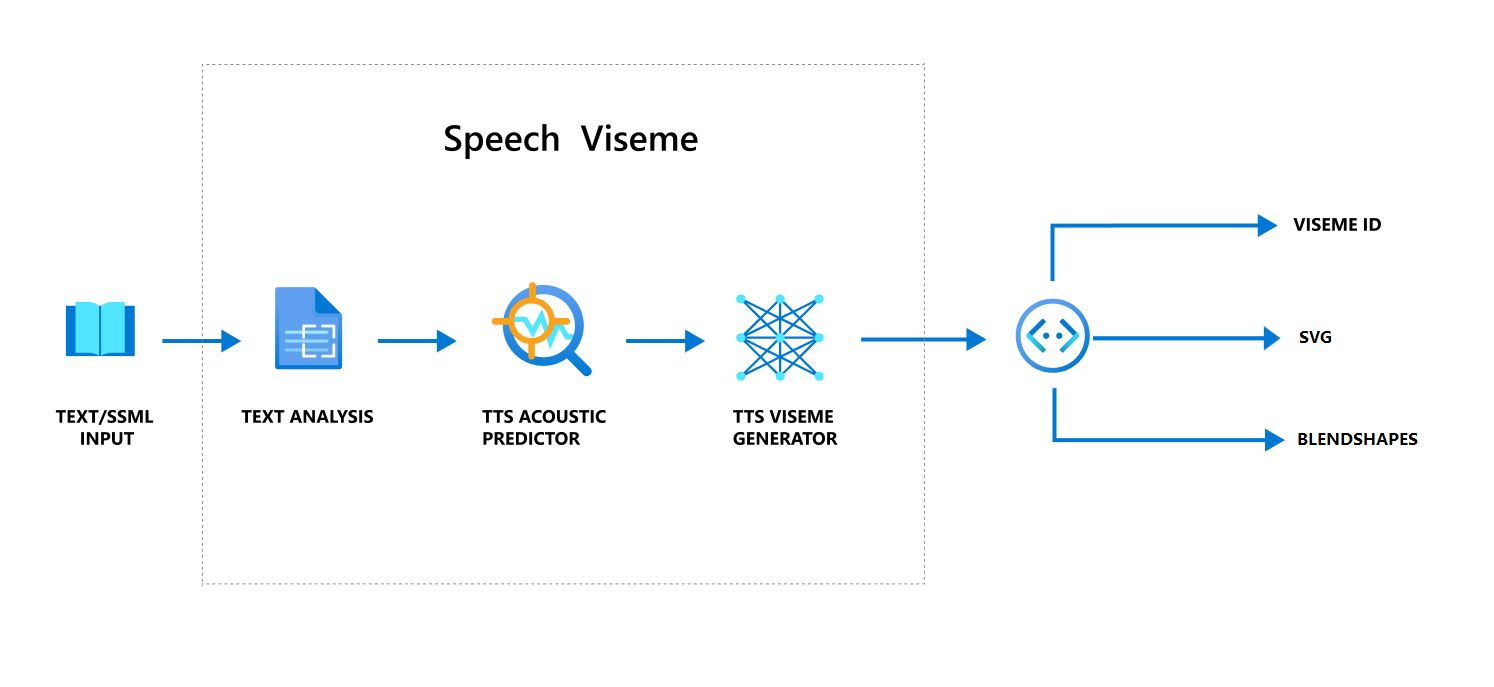
Viseme-ID
Viseme ID refererar till ett heltalsnummer som anger ett viseme. Vi erbjuder 22 olika visemes, var och en visar munpositionen för en specifik uppsättning fonem. Det finns ingen en-till-en-korrespondens mellan visemes och fonem. Ofta motsvarar flera fonem en enda viseme, eftersom de såg likadana ut på talarens ansikte när de produceras, till exempel s och z. Mer specifik information finns i tabellen för mappning av fonem till viseme-ID:er.
Talljudutdata kan åtföljas av viseme-ID:er och Audio offset. Audio offset Anger tidsstämpeln för offset som representerar starttiden för varje viseme, i fästingar (100 nanosekunder).
Mappa fonem till visemes
Visemes varierar beroende på språk och språk. Varje språk har en uppsättning visemes som motsvarar dess specifika fonem. Dokumentationen om SSML-fonetiska alfabet mappar viseme-ID:erna till motsvarande IPA-fonem (International Telefon tic Alphabet). Tabellen i det här avsnittet visar en mappningsrelation mellan viseme-ID:er och munpositioner, som visar typiska IPA-fonem för varje viseme-ID.
| Viseme-ID | IPA | Munläge |
|---|---|---|
| 0 | Tystnad |  |
| 1 | æ, , əʌ |
 |
| 2 | ɑ |
 |
| 3 | ɔ |
 |
| 4 | ɛ, ʊ |
 |
| 5 | ɝ |
 |
| 6 | j, , iɪ |
 |
| 7 | w, u |
 |
| 8 | o |
 |
| 9 | aʊ |
 |
| 10 | ɔɪ |
 |
| 11 | aɪ |
 |
| 12 | h |
 |
| 13 | ɹ |
 |
| 14 | l |
 |
| 15 | s, z |
 |
| 16 | ʃ, tʃ, , dʒʒ |
 |
| 17 | ð |
 |
| 18 | f, v |
 |
| 19 | d, t, , nθ |
 |
| 20 | k, , gŋ |
 |
| 21 | p, , bm |
 |
2D SVG-animering
För 2D-tecken kan du utforma ett tecken som passar ditt scenario och använda Skalbar vektorgrafik (SVG) för varje viseme-ID för att få en tidsbaserad ansiktsposition.
Med tidsmässiga taggar som tillhandahålls i en viseme-händelse bearbetas dessa väldesignade SVG:er med utjämningsändringar och ger användarna robust animering. Följande bild visar till exempel ett rödläppt tecken som är utformat för språkinlärning.

Animering av 3D-blandningsformer
Du kan använda blandningsformer för att driva ansiktsrörelserna i ett 3D-tecken som du har utformat.
JSON-strängen för blandningsformer representeras som en 2-dimensionell matris. Varje rad representerar en ram. Varje ram (i 60 FPS) innehåller en matris med 55 ansiktspositioner.
Hämta viseme-händelser med Speech SDK
Om du vill få viseme med ditt syntetiserade tal prenumererar du på VisemeReceived händelsen i Speech SDK.
Kommentar
Om du vill begära SVG- eller blandningsformers utdata bör du använda elementet mstts:viseme i SSML. Mer information finns i hur du använder viseme-element i SSML.
Följande kodfragment visar hur du prenumererar på viseme-händelsen:
using (var synthesizer = new SpeechSynthesizer(speechConfig, audioConfig))
{
// Subscribes to viseme received event
synthesizer.VisemeReceived += (s, e) =>
{
Console.WriteLine($"Viseme event received. Audio offset: " +
$"{e.AudioOffset / 10000}ms, viseme id: {e.VisemeId}.");
// `Animation` is an xml string for SVG or a json string for blend shapes
var animation = e.Animation;
};
// If VisemeID is the only thing you want, you can also use `SpeakTextAsync()`
var result = await synthesizer.SpeakSsmlAsync(ssml);
}
auto synthesizer = SpeechSynthesizer::FromConfig(speechConfig, audioConfig);
// Subscribes to viseme received event
synthesizer->VisemeReceived += [](const SpeechSynthesisVisemeEventArgs& e)
{
cout << "viseme event received. "
// The unit of e.AudioOffset is tick (1 tick = 100 nanoseconds), divide by 10,000 to convert to milliseconds.
<< "Audio offset: " << e.AudioOffset / 10000 << "ms, "
<< "viseme id: " << e.VisemeId << "." << endl;
// `Animation` is an xml string for SVG or a json string for blend shapes
auto animation = e.Animation;
};
// If VisemeID is the only thing you want, you can also use `SpeakTextAsync()`
auto result = synthesizer->SpeakSsmlAsync(ssml).get();
SpeechSynthesizer synthesizer = new SpeechSynthesizer(speechConfig, audioConfig);
// Subscribes to viseme received event
synthesizer.VisemeReceived.addEventListener((o, e) -> {
// The unit of e.AudioOffset is tick (1 tick = 100 nanoseconds), divide by 10,000 to convert to milliseconds.
System.out.print("Viseme event received. Audio offset: " + e.getAudioOffset() / 10000 + "ms, ");
System.out.println("viseme id: " + e.getVisemeId() + ".");
// `Animation` is an xml string for SVG or a json string for blend shapes
String animation = e.getAnimation();
});
// If VisemeID is the only thing you want, you can also use `SpeakTextAsync()`
SpeechSynthesisResult result = synthesizer.SpeakSsmlAsync(ssml).get();
speech_synthesizer = speechsdk.SpeechSynthesizer(speech_config=speech_config, audio_config=audio_config)
def viseme_cb(evt):
print("Viseme event received: audio offset: {}ms, viseme id: {}.".format(
evt.audio_offset / 10000, evt.viseme_id))
# `Animation` is an xml string for SVG or a json string for blend shapes
animation = evt.animation
# Subscribes to viseme received event
speech_synthesizer.viseme_received.connect(viseme_cb)
# If VisemeID is the only thing you want, you can also use `speak_text_async()`
result = speech_synthesizer.speak_ssml_async(ssml).get()
var synthesizer = new SpeechSDK.SpeechSynthesizer(speechConfig, audioConfig);
// Subscribes to viseme received event
synthesizer.visemeReceived = function (s, e) {
window.console.log("(Viseme), Audio offset: " + e.audioOffset / 10000 + "ms. Viseme ID: " + e.visemeId);
// `Animation` is an xml string for SVG or a json string for blend shapes
var animation = e.animation;
}
// If VisemeID is the only thing you want, you can also use `speakTextAsync()`
synthesizer.speakSsmlAsync(ssml);
SPXSpeechSynthesizer *synthesizer =
[[SPXSpeechSynthesizer alloc] initWithSpeechConfiguration:speechConfig
audioConfiguration:audioConfig];
// Subscribes to viseme received event
[synthesizer addVisemeReceivedEventHandler: ^ (SPXSpeechSynthesizer *synthesizer, SPXSpeechSynthesisVisemeEventArgs *eventArgs) {
NSLog(@"Viseme event received. Audio offset: %fms, viseme id: %lu.", eventArgs.audioOffset/10000., eventArgs.visemeId);
// `Animation` is an xml string for SVG or a json string for blend shapes
NSString *animation = eventArgs.Animation;
}];
// If VisemeID is the only thing you want, you can also use `SpeakText`
[synthesizer speakSsml:ssml];
Här är ett exempel på viseme-utdata.
(Viseme), Viseme ID: 1, Audio offset: 200ms.
(Viseme), Viseme ID: 5, Audio offset: 850ms.
……
(Viseme), Viseme ID: 13, Audio offset: 2350ms.
När du har hämtat viseme-utdata kan du använda dessa händelser för att driva teckenanimering. Du kan skapa egna tecken och automatiskt animera dem.