Partitionering i Azure Cosmos DB för Apache Cassandra
GÄLLER FÖR:![]() Cassandra
Cassandra
Den här artikeln beskriver hur partitionering fungerar i Azure Cosmos DB för Apache Cassandra.
API för Cassandra använder partitionering för att skala enskilda tabeller i ett nyckelområde för att uppfylla programmets prestandabehov. Partitioner bildas baserat på värdet för en partitionsnyckel som är associerad med varje post i en tabell. Alla poster i en partition har samma partitionsnyckelvärde. Azure Cosmos DB hanterar transparent och automatiskt placeringen av partitioner över de fysiska resurserna för att effektivt uppfylla tabellens skalbarhets- och prestandabehov. I takt med att dataflödet och lagringskraven för ett program ökar flyttar och balanserar Azure Cosmos DB data över ett större antal fysiska datorer.
Ur utvecklarperspektiv fungerar partitionering på samma sätt för Azure Cosmos DB för Apache Cassandra som i inbyggda Apache Cassandra. Det finns dock vissa skillnader bakom kulisserna.
Skillnader mellan Apache Cassandra och Azure Cosmos DB
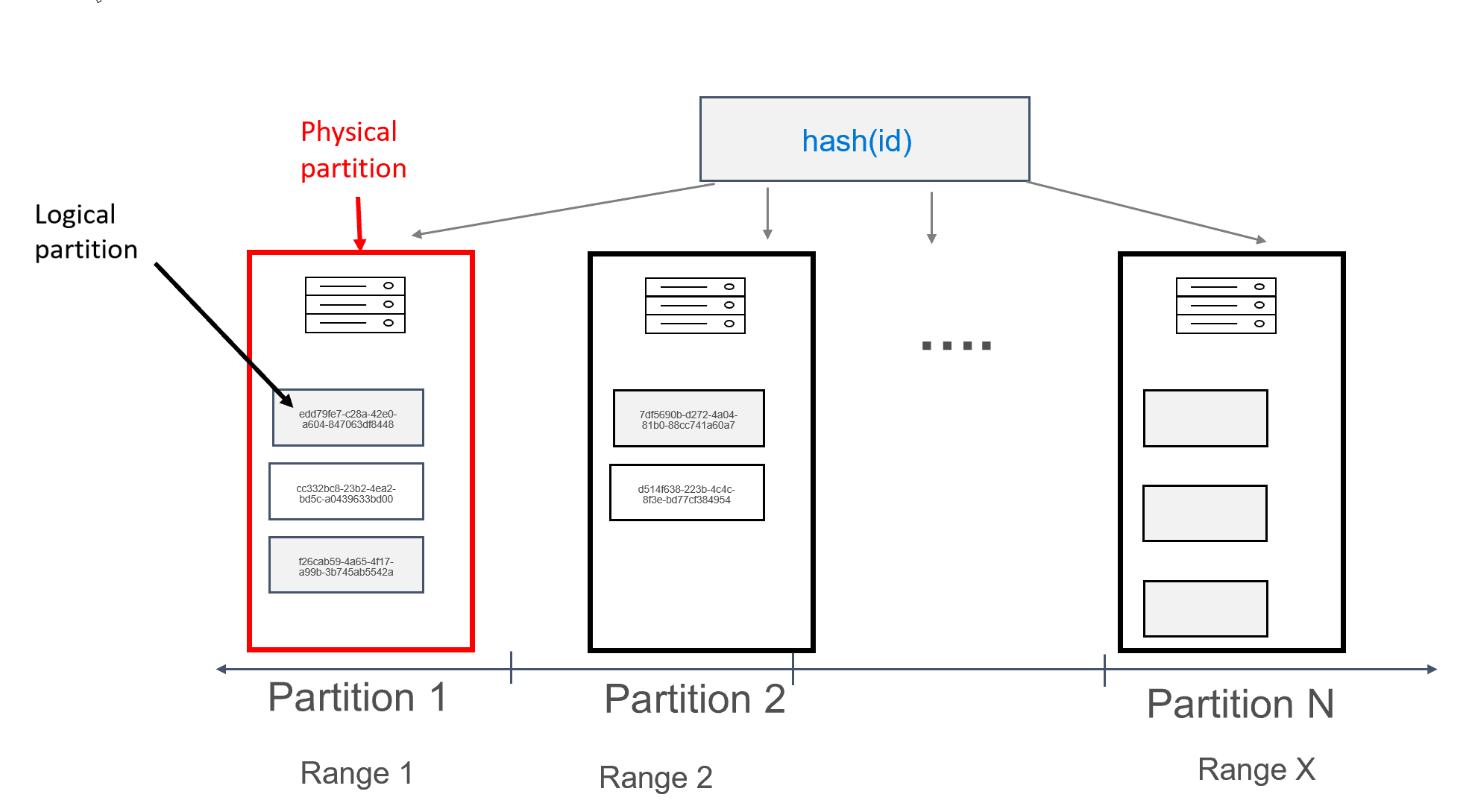
I Azure Cosmos DB kallas varje dator där partitioner lagras i sig en fysisk partition. Den fysiska partitionen liknar en virtuell dator. en dedikerad beräkningsenhet eller en uppsättning fysiska resurser. Varje partition som lagras på den här beräkningsenheten kallas en logisk partition i Azure Cosmos DB. Om du redan är bekant med Apache Cassandra kan du tänka på logiska partitioner på samma sätt som du tänker på vanliga partitioner i Cassandra.
Apache Cassandra rekommenderar en gräns på 100 MB för storleken på data som kan lagras i en partition. API:et för Cassandra för Azure Cosmos DB tillåter upp till 20 GB per logisk partition och upp till 30 GB data per fysisk partition. I Azure Cosmos DB, till skillnad från Apache Cassandra, uttrycks beräkningskapaciteten som är tillgänglig i den fysiska partitionen med hjälp av ett enda mått som kallas enheter för begäranden, vilket gör att du kan tänka på din arbetsbelastning när det gäller begäranden (läsningar eller skrivningar) per sekund, i stället för kärnor, minne eller IOPS. Detta kan göra kapacitetsplaneringen mer rak, när du förstår kostnaden för varje begäran. Varje fysisk partition kan ha upp till 1 0000 RU:er för beräkning tillgängliga för den. Du kan lära dig mer om skalbarhetsalternativ genom att läsa vår artikel om elastisk skalning i API för Cassandra.
I Azure Cosmos DB består varje fysisk partition av en uppsättning repliker, även kallade replikuppsättningar, med minst 4 repliker per partition. Detta står i kontrast till Apache Cassandra, där det är möjligt att ange en replikeringsfaktor på 1. Detta leder dock till låg tillgänglighet om den enda noden med data går ned. I API för Cassandra finns alltid en replikeringsfaktor på 4 (kvorum på 3). Azure Cosmos DB hanterar automatiskt replikuppsättningar, medan dessa måste underhållas med hjälp av olika verktyg i Apache Cassandra.
Apache Cassandra har ett koncept med token, som är hashvärden för partitionsnycklar. Token baseras på en murmur3 64 byte hash, med värden från -2^63 till -2^63 - 1. Det här intervallet kallas ofta "tokenring" i Apache Cassandra. Tokenringen distribueras till tokenintervall och dessa intervall är uppdelade mellan noderna som finns i ett inbyggt Apache Cassandra-kluster. Partitionering för Azure Cosmos DB implementeras på liknande sätt, förutom att den använder en annan hash-algoritm och har en större intern tokenring. Externt exponerar vi dock samma tokenintervall som Apache Cassandra, dvs. -2^63 till -2^63 - 1.
Primärnyckel
Alla tabeller i API för Cassandra måste ha en primary key definierad. Syntaxen för en primärnyckel visas nedan:
column_name cql_type_definition PRIMARY KEY
Anta att vi vill skapa en användartabell som lagrar meddelanden för olika användare:
CREATE TABLE uprofile.user (
id UUID PRIMARY KEY,
user text,
message text);
I den här designen har vi definierat fältet id som primärnyckel. Den primära nyckeln fungerar som identifierare för posten i tabellen och används också som partitionsnyckel i Azure Cosmos DB. Om primärnyckeln definieras på det tidigare beskrivna sättet finns det bara en enda post i varje partition. Detta resulterar i en perfekt vågrät och skalbar distribution när du skriver data till databasen och är perfekt för uppslagsanvändningsfall med nyckelvärde. Programmet bör tillhandahålla primärnyckeln när du läser data från tabellen för att maximera läsprestanda.
Sammansatt primärnyckel
Apache Cassandra har också begreppet compound keys. En förening primary key består av mer än en kolumn. Den första kolumnen är partition key, och eventuella ytterligare kolumner är clustering keys. Syntaxen för en compound primary key visas nedan:
PRIMARY KEY (partition_key_column_name, clustering_column_name [, ...])
Anta att vi vill ändra ovanstående design och göra det möjligt att effektivt hämta meddelanden för en viss användare:
CREATE TABLE uprofile.user (
user text,
id int,
message text,
PRIMARY KEY (user, id));
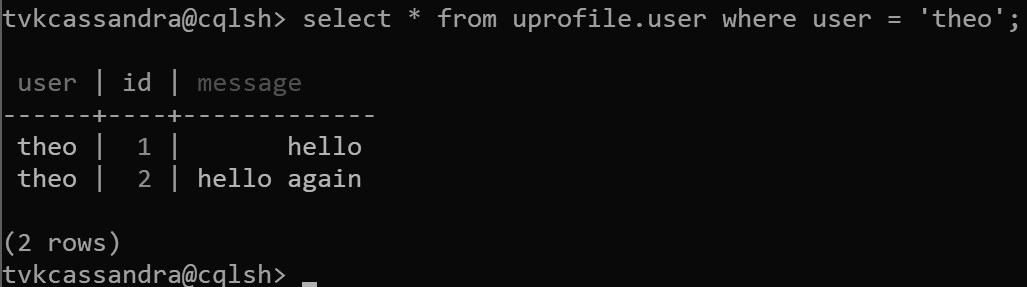
I den här designen definierar user vi nu som partitionsnyckel och id som klustringsnyckel. Du kan definiera så många klustringsnycklar som du vill, men varje värde (eller en kombination av värden) för klustringsnyckeln måste vara unikt för att resultera i att flera poster läggs till i samma partition, till exempel:
insert into uprofile.user (user, id, message) values ('theo', 1, 'hello');
insert into uprofile.user (user, id, message) values ('theo', 2, 'hello again');
När data returneras sorteras de efter klustringsnyckeln, som förväntat i Apache Cassandra:
Varning
När du frågar efter data i en tabell som har en sammansatt primärnyckel ska du, om du vill filtrera på partitionsnyckeln och andra icke-indexerade fält förutom klustringsnyckeln, se till att du uttryckligen lägger till ett sekundärt index på partitionsnyckeln:
CREATE INDEX ON uprofile.user (user);
Azure Cosmos DB för Apache Cassandra tillämpar inte index på partitionsnycklar som standard, och indexet i det här scenariot kan avsevärt förbättra frågeprestandan. Läs vår artikel om sekundär indexering för mer information.
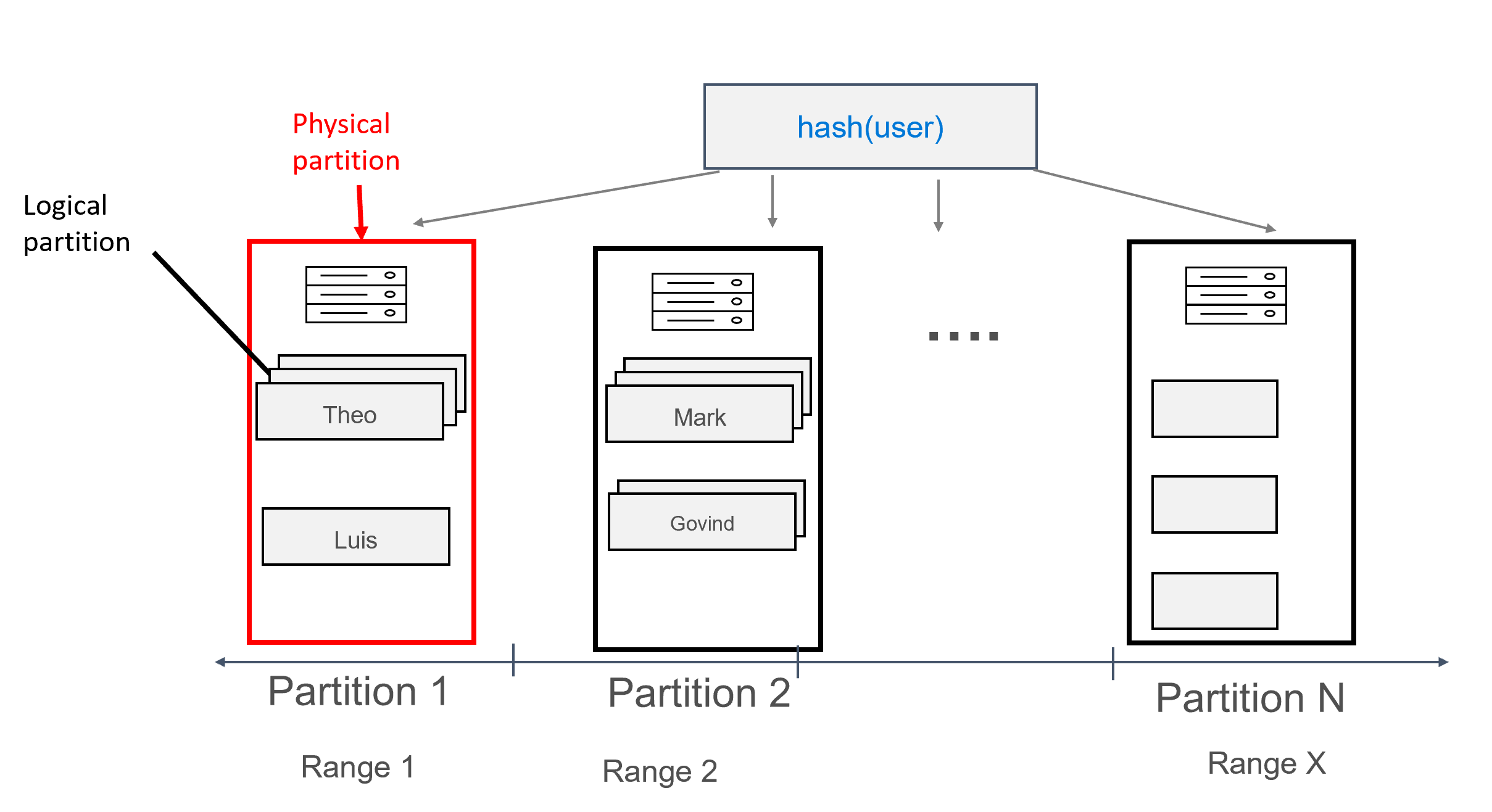
Med data modellerade på det här sättet kan flera poster tilldelas till varje partition, grupperade efter användare. Vi kan därför utfärda en fråga som dirigeras effektivt av partition key (i det här fallet user) för att hämta alla meddelanden för en viss användare.
Sammansatt partitionsnyckel
Sammansatta partitionsnycklar fungerar i stort sett på samma sätt som sammansatta nycklar, förutom att du kan ange flera kolumner som en sammansatt partitionsnyckel. Syntaxen för sammansatta partitionsnycklar visas nedan:
PRIMARY KEY (
(partition_key_column_name[, ...]),
clustering_column_name [, ...]);
Du kan till exempel ha följande, där den unika kombinationen av firstname och lastname skulle utgöra partitionsnyckeln och id är klustringsnyckeln:
CREATE TABLE uprofile.user (
firstname text,
lastname text,
id int,
message text,
PRIMARY KEY ((firstname, lastname), id) );
Nästa steg
- Lär dig mer om partitionering och horisontell skalning i Azure Cosmos DB.
- Läs mer om etablerat dataflöde i Azure Cosmos DB.
- Lär dig mer om global distribution i Azure Cosmos DB.